IndexR:速度最快的大数据存储格式介绍(与在spark上的使用)
摘要
IndexR实现了一种可部署于分布式环境,可并行化处理,带索引的,列式的结构化数据格式。基于这种数据格式,IndexR构建了一个数据仓库系统(Data Warehouse),它基于Hadoop生态,可以对海量数据集做快速统计分析(OLAP),数据可实时导入并且对于查询零延迟。IndexR 为解决大数据场景下分析缓慢、数据延迟、系统复杂等问题而设计。本文描述了IndexR的设计思想,系统架构,以及核心的技术细节。
:
- 超大数据集,低查询延时。查询模式无法预测,无法预计算;表数据量普遍超过1亿,甚至上百亿千亿,过滤条件有可能会命中大量数据;数据在查询的同时还会有大量的更新,每秒入库几万的数据。要保证较低的查询延时,一般情况下查询延时要求在5s以内,常用高频查询要求1s以内。
- 准实时。数据从产生到体现在分析结果延时几秒以内。时效性对于某些业务至关重要,并且越实时的数据,价值越大。
- 可靠性,一致性,高可用。这些数据是公司最重要的数据之一,任何错误和不一致可能会直接体现在客户报表中,对公司的业务和品牌形象产生影响,至关重要。
- 可扩展,低成本,易维护。业务会快速发展,会产生新的数据源,加入新的表,旧的数据不能删除,这带来巨大的成本压力,和运维压力。典型的更新如加列、列值更新等操作不能影响线上服务,不能带来入库或者查询延迟。
- SQL支持。全面支持SQL,要像Mysql一样好用,功能强大。不仅仅支持常见的多维分析,还需要支持复杂的分析查询,如JOIN,子查询等,支持自定义函数(UDF,UDFA)。
- 与Hadoop生态整合。Hadoop生态的蓬勃发展给大数据处理带来越来越强的处理能力,如果能与它的工具链深度结合,会极大扩展系统的价值。
它最早是为了解决互联网广告业务产生的海量数据进行实时、在线分析而研发的分析型数据库,目前使用十几台一般配置服务器,支撑了舜飞科技包含多条业务线,每日近千亿数据的实时入库、在线多维分析系统。
IndexR开源至今,获得了国内外的许多团队的认可,从调研、测试到最后部署于生产环境,包括广告、电商、AI等领域的大型互联网公司和创业团队,以及政府,咨询,物流等有超大数据集,对数据质量有极高要求的行业。
开源地址:shunfei/indexr
<-----------------------------------------------
在Spark中使用IndexR
当前IndexR版本为-0.6.1, 从IndexR-0.6.0 开始,支持Spark 2.1.0+。您可以使用Spark以IndexR文件格式管理和查询表。IndexR文件格式支持所有Spark支持的操作,如Parquet。
由于Spark的运行架构,IndexR节点在Spark中不支持实时提取。
按照这里的说明在Spark中设置IndexR文件格式。
下面为建表格式。
IndexR模式:
{
"schema":{
"columns":
[
{"name": "date", "dataType": "int"},
{"name": "d1", "dataType": "string"},
{"name": "m1", "dataType": "int"},
{"name": "m2", "dataType": "bigint"},
{"name": "m3", "dataType": "float", "default": "-0.1"},
{"name": "m4", "dataType": "double"}
]
},
"location": "/indexr/segment/test",
"mode": "vlt",
"agg":{
"grouping": true,
"dims": [
"date",
"d1"
],
"metrics": [
{"name": "m1", "agg": "sum"},
{"name": "m2", "agg": "min"},
{"name": "m3", "agg": "max"},
{"name": "m4", "agg": "first"}
]
}
}
Hive模式:
CREATE EXTERNAL TABLE IF NOT EXISTS test (
`date` int,
`d1` string,
`m1` int,
`m2` bigint,
`m3` float,
`m4` double
)
PARTITIONED BY (`dt` string)
ROW FORMAT SERDE 'io.indexr.hive.IndexRSerde'
STORED AS INPUTFORMAT 'io.indexr.hive.IndexRInputFormat'
OUTPUTFORMAT 'io.indexr.hive.IndexROutputFormat'
LOCATION '/indexr/segment/test'
TBLPROPERTIES (
'indexr.segment.mode'='vlt',
'indexr.index.columns'='d1',
'indexr.agg.grouping'='true',
'indexr.agg.dims'='date,d1',
'indexr.agg.metrics'='m1:sum,m2:min,m3:max,m4:first'
)
;
Spark模式:
CREATE TABLE test_spark (
`date` int,
`d1` string,
`m1` int,
`m2` bigint,
`m3` float,
`m4` double,
`dt` string
)
USING org.apache.spark.sql.execution.datasources.indexr.IndexRFileFormat
OPTIONS (
'path'='/indexr/segment/test' ,
'indexr.segment.mode'='vlt',
'indexr.index.columns'='d1',
'indexr.agg.grouping'='true',
'indexr.agg.dims'='date,d1',
'indexr.agg.metrics'='m1:sum,m2:min,m3:max,m4:first'
)
PARTITIONED BY (dt)
;
创建spark表
> CREATE TABLE test_spark (
`date` int,
`d1` string,
`m1` int,
`m2` bigint,
`m3` float,
`m4` double,
`dt` string
)
USING org.apache.spark.sql.execution.datasources.indexr.IndexRFileFormat
OPTIONS (
'path'='/indexr/segment/test' ,
'indexr.segment.mode'='vlt',
'indexr.index.columns'='d1',
'indexr.agg.grouping'='true',
'indexr.agg.dims'='date,d1',
'indexr.agg.metrics'='m1:sum,m2:min,m3:max,m4:first'
)
PARTITIONED BY (dt)
;
> msck repair table test_spark;
> select * from test_spark limit 10;
> insert into table test_spark partition (dt=20160702) values(20160702,'mac',100,192444,1.55,-331.43555);
<-----------------------------------------------
架构
IndexR可与Hadoop生态的各个系统互相配合,以下是一个典型系统的示意图。
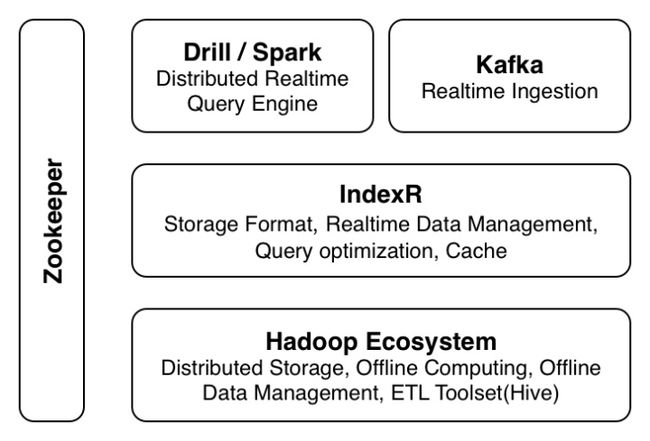
- IndexR为上层计算引擎提供数据,相当于对IO层做了整体性能加速,提升系统的分析能力。
- IndexR实时拉取Kafka的数据流,并打包上传到HDFS。整个数据层对于计算层是透明的,IndexR会把实时数据和历史数据结合,保证分析实时性。
- 这套体系不仅能解决在线分析的问题,同时也解决了实时和历史数据的分割问题。
- 数据存放于HDFS,方便于不同的分析工具分析同一份数据。
- 利用Hadoop,Drill,Spark等分布式、高可用、可扩展的特点,解决海量数据场景的分析问题。
IndexR的特点
-
存储格式自带索引。
IndexR包含三层索引,粗糙集索引(Rough Set Index),内索引(Inner Index)和可选的外索引(Outer Index)。
目前的On Hadoop存储格式如ORC,Parquet等都没有真正的索引,只有靠分区和利用一些简单的统计特征如最大最小值,可以大概满足离线分析的需求,但是在服务在线业务的时候就非常力不从心,需要从磁盘读取有大量无用数据。事实上并不是每次查询都需要获取全部数据,特别Ad-hoc类型的查询。IndexR通过多层索引设计,一方面极大的提高了IO效率,只读取有效数据,另一方面把索引的额外开销降到最低。
一般传统数据库系统的索引设计是通过索引直接命中具体的数据行,但是这样方式只适用于OLTP场景,即每次查询只获取少量数据。但是在OLAP场景下并不适合,每次查询可能要涉及上万甚至上亿行数据,这样的设计的索引开销极大(内存、IO、CPU),并且带来磁盘随机读的问题,很多时候还不如直接对原始数据扫描速度快。
IndexR的索引设计是分层的。打个比喻,如果要定位全国具体的某个街道,传统的方式是把“省市-街道”组成一个索引,而IndexR是通过把“街道”映射在相应的“省市”的集合(Pack)里,然后再在具体的集合了里做细致的索引。
- Rough Set Index - 粗糙集索引的工作方式类似于熟知的BloomFilter,它的特点是成本极低,速度超快,几乎不会对查询有性能损耗。IndexR数据格式通过粗糙集索引快速定位区域块,所以并不依赖分区。
- Outer Index - 外索引目前使用倒排索引+Bitmap,它的优点是支持丰富的过滤条件,并且非常适合做交、并运算。IndexR对倒排索引的使用方式做了优化,避免了在Scan场景下大量随机读或者巨大内存使用的问题,并且把Bitmap的merge操作做了加速处理,不会出现范围条件(大于、小于)下的大量merge问题。
- Inner Index - 内索引根据具体的Pack内部编码特性决定,支持在压缩状态下对数据进行过滤。
具体查询的时候,IndexR先进行粗糙集索引过滤,再对剩下的数据集进行倒排索引过滤。然后把命中的Pack直接加载入内存,对其进行高效的细致查询。这种方式解决了分布式架构、海量数据场景下索引困难的问题,避免了随机读问题,不管是在需要大范围扫描还是少量数据查询,效率都很高。
-
两种存储模式,适应不同场景
- vlt模式 - 默认模式,适用于绝大部分场景。特点是速度极快,遍历速度比Parquet快2~4倍,支持倒排索引,随机查询性能优越。默认情况下文件大小是Parquet的75%。
- basic模式 - 极高压缩率,可达10:1,一般文件大小是Parquet的1/3。并且仍然保持非常高的读取性能,优于其他开源格式。适用于存放超大量历史数据,并且需要随时快速访问。
-
支持流式导入,实时分析
目前的Hadoop生态对于实时的数据分析还是比较困难。比如Storm、Spark Streaming,这类型属于对数据进行预计算,在业务频繁改动,或者需要对原始数据进行启发式分析(Ad-hoc)的情况下没法满足需求。而Druid,Kudu等系统虽然支持实时写入,但是属于自成体系的,在我们的实际运用中遇到部署、整合甚至性能方面的问题。
IndexR支持实时数据写入,比如从Kafka导入,并且数据到达系统之后可以立刻被分析,它与Hadoop生态的无缝整合,使得对于业务设计非常灵活。目前IndexR单表单节点入库速度每秒超过3w条数据,入库速度随着节点数量线性增加,每个表使用一个单独的线程,互不影响。对于OLAP型多维分析场景,IndexR还支持实时、离线预聚合,让分析速度飞起!
-
速度超快
IndexR使用深度优化的编码方式,大大加快数据解析,甚至可以媲美一些内存数据库。它的数据组织形式根据向量化执行的特点定制,把全部数据存放于堆外内存,并且优化到个byte的组织方式,把JVM的GC和虚函数开销降到最低。
IndexR是基于Hadoop的数据格式,意味着文件存放于HDFS,这样可以非常方便的利用HDFS本身的高可用特性保证数据安全,并且可以方便的使用Hadoop生态上的所有分析工具。我们对基于HDFS的文件读取做了大量的优化工作,把计算尽量分发到离数据最近的本地节点,HDFS层的开销基本被剔除,与直接读取本地数据无异。
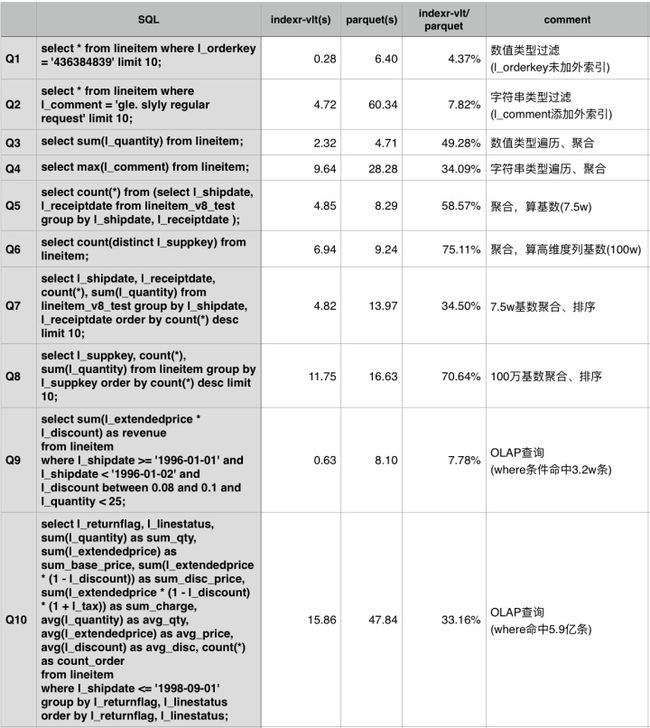
以下是使用TPC-H数据集,IndexR与Parquet格式在相同的Drill集群上做的一个性能对比。
最大表lineitem数据总量6亿,5个节点,节点配置 [Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz] x 2, RAM 64G(实际使用约12G), HDD SATA with 7200RPM。
- 单项性能对比
柱状图:
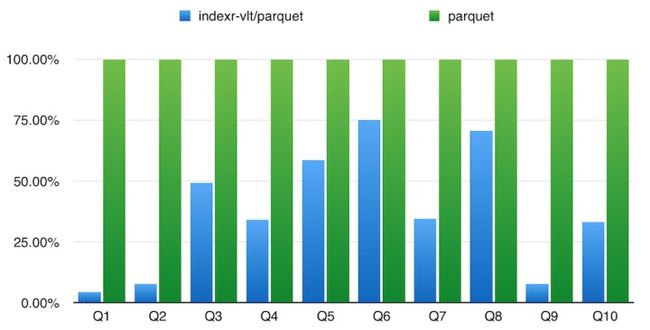
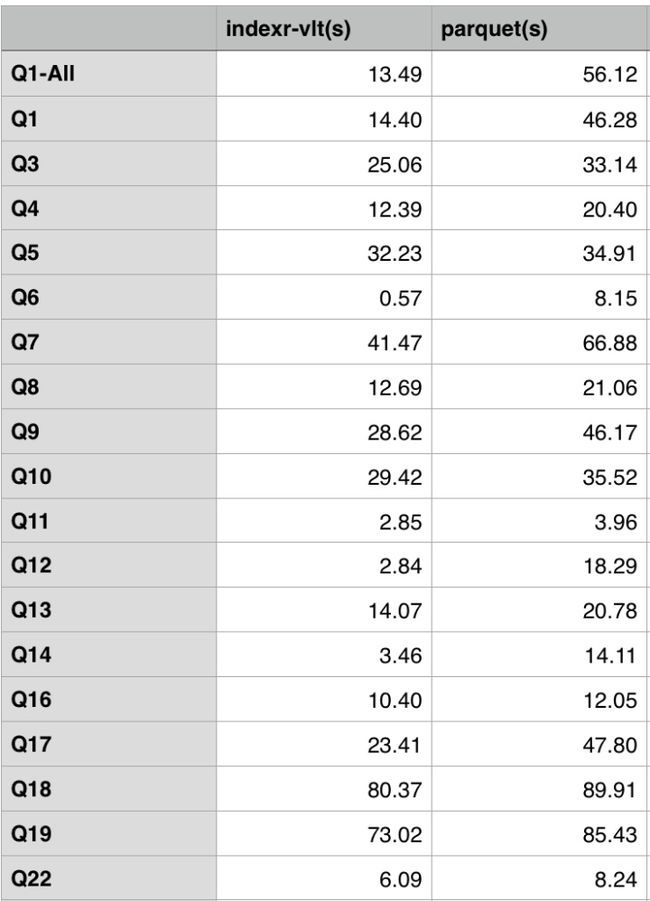
- 使用TPC-H标准测试SQL,SQL内容可以在TPC-H - Homepage获取(贴出来太长了),覆盖了包Join,子查询等常见统计分析查询SQL,where条件命中的数据量一般超过最大表的50%。其中Q2,Q15等SQL由于Drill不支持没有显示。
柱状图:

-
省资源
IndexR的数据结构经过精心设计,绝不多浪费任何内存空间。为了避免Java中对象和抽象的开销,IndexR的代码大量使用了Code C In Java的编程风格(调侃),通过内存结构而非接口进行解耦。紧凑的内存结构减少了寻址开销,且非常利于JVM的运行时优化。结果是IndexR保证了高性能、有效索引的同时非常省内存,与使用Parquet格式查询时的内存使用量差不多,不会出现CarbonData需要配置超大堆内存的情况。但是为什么不直接使用C或者C++呢?因为目前Hadoop生态最适合的开发语言还是基于JVM的语言,可与其他系统无缝集成,在工具链支持方面也是最全面的。
-
IndexR通过与Hadoop生态的深度整合,非常适合用来搭建海量数据场景下的数据仓库。
典型使用场景
IndexR从开源至今,经过不同的团队实践,积累了很多使用案例,下面介绍我们了解到的IndexR在不同公司的几个常见使用方式。
-
替换Parquet,利用IndexR的强大性能和索引优势,可以加速整个查询系统。
-
替换Druid等,做实时入库,多维分析。IndexR可以实现Druid的所有功能,并且有完整的SQL支持,包括Join,子查询,多数据源等。它没有时间窗口概念,不会主动丢弃过期数据,运维更加简单,数据存放于HDFS,可以使用同一份数据进行离线分析。大部分查询性能比Druid要好,即使没有SSD硬盘也能获得很好的性能,并且非常的省内存。
-
将IndexR与其他开源工具结合,如Drill,搭建OLAP查询系统。利用IndexR支持实时入库的特性和查询速度优势,并且基于Hadoop生态的特点,很容易满足实时分析、海量数据、线性扩展、高可用、功能丰富、业务灵活等当前和未来对于OLAP系统的需求。不再有纯预计算所带来的局限性所困扰,且在线分析和离线分析可以使用同一份数据,提高率用率,降低成本。
-
作为数据仓库的存储格式,存放海量历史数据,并且支持都有海量实时的数据入库,数据使用方式包括明细查询,在原始数据上做分析查询,和定期的预处理脚本。
-
MySQL、Oracle等业务数据库,或者ES、Solr等搜索引擎,把它们统计分析工作移交到IndexR系统,通过模块分离,提高服务能力。
-
-
IndexR适合的经典场景:
- 需要在海量数据之上做快速的统计分析查询。
- 要求入库速度非常快,并且需要实时分析。
- 存放超大量历史明细数据库。比如网站浏览信息,交易信息,安保数据,电力行业数据,物联网设备采集数据等。这类数据通常量非常大,数据内容复杂,存放时间比较久,且希望在需要时可以比较快速的根据各种条件做明细查询,或者在一定范围内做复杂的分析。这种情况下可以充分发挥IndexR的低成本,可扩展,适合超大数据集的优势。
目前业界典型选型:
- 使用Mysql,PostgreSQL等关系型数据库,不仅用于业务查询(OLTP),也做统计分析,一般是在现有业务数据库上直接做一些分析需求。这种方式在数据量增长之后就会遇到性能问题,特别是分析查询会对业务查询产生极大影响。可以考虑把数据导入IndexR做分析,即把业务数据库和分析数据库分开。
- ES,Solr等全文搜索数据库用于统计分析场景。这类数据库最大的特点是使用了倒排索引解决索引问题。对于统计分析场景通常没有特别优化,在大数据量场景下内存和磁盘压力比较大。如果遇到性能问题,或者数据量撑不住了,可以考虑使用IndexR。
- Druid,Pinot等所谓时序数据库。在查询条件命中大量数据情况下可能会有性能问题,而且排序、聚合等能力普遍不太好,从我们的使用经验来看运维比较困难,灵活性和扩展性不够,比如缺乏Join、子查询等。在保存大量历史数据情况下需要的硬件资源相对昂贵。这种场景下可以考虑使用IndexR直接替换,不用担心业务实现问题。
- Infobright,ClickHose等列式数据库。列式数据库本身非常适合于OLAP场景,IndexR也属于列式数据库。最大的区别在于IndexR是基于Hadoop生态的。
- 离线预聚合,建Cube,结果数据存放于HBase等KV数据库,如Kylin等。这种方式在只有多维分析场景且查询比较简单的情况下非常有效。问题就在于灵活性不足(flexibility),无法探索式分析,以及更复杂的分析需求。IndexR可以通过表配置达到预聚合的效果,并且聚合是实时,没有延迟的;可以保留原始数据或者高维度数据,通过表路由决定具体的查询表。
- 为了解决大数据量的即时分析问题,上层使用Impala,Presto,SparkSQL,Drill等计算引擎来做查询,存储层使用开源数据格式比如Parquet,基于Hadoop生态。这类架构和IndexR很相似。IndexR的优势在于更有效的索引设计,更好的性能,并且支持实时入库,秒级延迟。我们在相同环境下与Parquet格式做过查询性能对比,IndexR的查询速度提升在3~8倍以上。之后IndexR经历了很大的性能优化,估计会有更好的表现。
- Kudu,Phoenix等既支持OLTP场景,又为OLAP场景优化等开源产品。通常很难两者兼顾,建议分成实时库和历史库,针对不同数据特点采用不用的存储方案。
- 内存数据库。贵。
IndexR的未来方向
IndexR项目由舜飞科技开源并快速推进,目前已经发布0.6.1版本。IndexR立志于成为Hadoop生态下快速分析查询的标准存储格式。希望它可以获得业界更多的关注和使用,和社区的更多积极参与。
大数据经过近些年的快速发展,完整的生态渐渐成熟,已经早已不是只有Hadoop跑MR任务的时代。人们在在满足了能够分析大量数据集的需求之后,渐渐的对时效性、易用性等方面提出了更高的要求,因而诞生了如Storm,Spark等新的工具。新的问题催生新的挑战,提供新的机遇。而传统的数据仓库产品,在面对大数据的冲击显得非常无力。IndexR为解决这种现状,提供了新的思路和方向。
IndexR是新一代数据仓库系统,为OLAP场景而设计,可以对超大量的结构化数据进行快速的分析,支持快速的实时入库。它功能强大,并简单可靠,支持大规模集群部署。它与Hadoop生态系统深度整合,可以充分发挥大数据工具的能力。
不用再为分析能力的瓶颈担忧,不用放弃经典的OLAP理论,不用降级你的服务,不用担心业务人员对大数据工具不熟悉,IndexR像Mysql一样好用,会SQL就好了。
IndexR在开源之后,我们已经看到有不少使用案例,包括国内外的不同团队。有意思的是,有些团队的使用方式比较特别,比如用于存放超大量(单表千亿级别)的复杂明细数据,做历史数据的明细查询。IndexR不仅可以用于多维分析,商业智能等OLAP经典领域,还可以用于物联网,舆情监控,人群行为分析等新兴方向。