作 者: 月牙眼的楼下小黑
联 系:[email protected]
声 明: 欢迎转载本文中的图片或文字,请说明出处
我这三天一直思考的问题的是:
当网络最后一层输出的
prediciton map size和label map size大小不匹配时,除了bilinea interpolation等暴力措施,且不采取unpooling,deconvolution等decoder结构, 为了实现 dense prediction , 该怎么做呢?
我前天向一位其他组的师兄请教这个问题时,他给我指出了一个方向:shift and stitch。 他这一提醒,我就想起来了,当初在看论文 《Fully Convolutional Networks for Semantic Segmentation》时,因为看不懂,就跳过了好几段,其中就包括 "3.2 Shift-sttch is filter rarefaction"这一节。
作者在这一节中指出: 为了实现dense prediction ,他们比较了三种不同方案,分别是 shift and stitch, decreasing subsampling,deconvolution
我当初为什么看不懂呢? 我们看看作者对 shift and stitch 是怎样描述的:

当然,因为我现在已经弄明白了,所以觉得作者描述得其实挺清晰了。但是在这之前,我看了好几遍还是一脸懵逼。网上关于这一段的翻译更是千篇一律,不知所云,所以很多博客就是搬运工的工作,互相抄来抄去。(更于 2019/4/9: 在写这篇笔记期间,我经历了些不好的事情,变得怨天尤地,文字间也不禁流露出一些戾气,但是现在回过头想想,何必呢, 抱怨是弱者的姿态, love and peace ~ )
网上的关于shift-and-stitch的解释:设原图与FCN所得输出图之间的降采样因子是f,那么对于原图的每个fxf 的区域(不重叠),“shift the input x pixels to the right and y pixels down for every (x,y) ,0 < x,y < f." 把这个f x f区域对应的output作为此时区域中心点像素对应的output,这样就对每个 fxf 的区域得到了 f2 个output,也就是每个像素都能对应一个output,所以成为了dense prediction

后来,我看了作者 引用 的关于 shift and stitch 的两篇文章:
[28] P. H. Pinheiro and R. Collobert. Recurrent convolutional
neural networks for scene labeling. In ICML, 2014[29] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus,
and Y. LeCun. Overfeat: Integrated recognition, localization
and detection using convolutional networks. In ICLR, 2014.
我明白了 shift and stitch的做法其实就是:
设降采样因子是f , 通过 shift pixels (平移像素)的方式,产生 f2 个
version的input,输入网络后相应地产生 f2 个output, 然后stitch(这个词不好翻译,先翻译成织联)所有output就实现了dense prediciton。
我在另一篇论文中找到了对shift and stitch 更详尽的描述 :

接下来受论文[2] 的启发,我们举一个简单的例子来直观地说明 shift and stitch 的做法:
设网络只有一层 2x2 的maxpooling 层且 stride = 2,所以下采样因子 f =2, 我们需要对input image 的 pixels 平移 (x,y)个单位,即将 image 向左平移 x 个pixels , 再向上平移y个单位,整幅图像表现向左上方向平移,空出来的右下角就以0 padding 。我们当然可以采取 FCN论文中的做法,将图像向右下角平移,空出来的左上角用 0 padding ,这两种做法产生的结果是一致的,没有本质区别。(x,y) 取(0,0), (0,1),(1,0),(1,1) 后,就产生了 f^2^ = 4 个input,不妨记为: shifted input (0,0)、shifted input (0,1),shifted input (1,0),shifted input (1,1)(回答一个读者的问题:图中的数字表示像素值,不是索引值 )
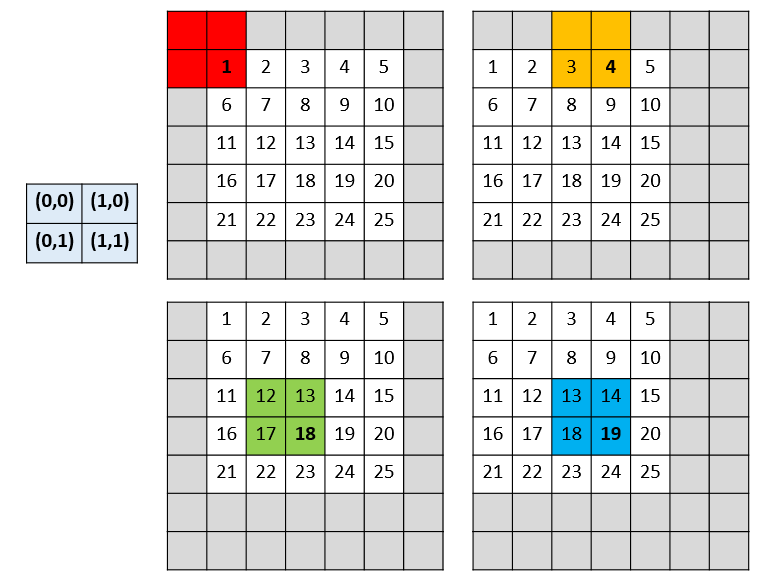
4个input分别进行 2x2 的maxpooling 操作后,共产生了4个output。
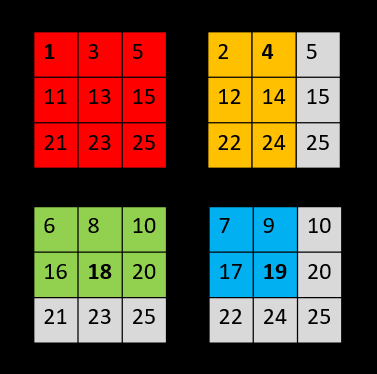
最后,stitch the 4 different output 获得 dense prediction :
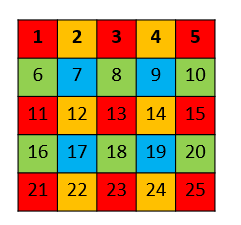
那么问题来了,是怎样进行 stitch的呢?FCN 作者的说法是:
Process each of these f2 inputs, and interlace the outputs so that the predictions correspond to the pixels at the centers of their receptive fields
说的很明白了,output 中的每个pixel都对应 original image 的
不同 receptive field,将receptive field 的中心c填上来自output的pixel值,就是网络对original image 中像素 c类别的prediction。
为表述简洁,我用 “ 像素 i ” 表示“ 值为 i 的像素 ”。
红色
output中的像素1对应shifted input(0,0)的红色部分, 而对应original image的部分,也即receptive field仅仅为像素[1],所以receptive field的中心为像素[1], 该位置填上红色output中像素1的值。黄色
output中的像素4对应shifted input(1,0)的黄色部分, 而对应original image的部分,也即receptive field为像素[3,4], 所以receptive field的中心为像素[4], 该位置填上黄色output中像素4的值。以此类推..
注意: 我们注意到黄色
output中的像素5与红色output中的像素5对应的receptive field中心是重叠的,所以将黄色output中的像素5标为灰色,表示不予考虑。同理其他ouput中的灰色区域也代表receptive field中心重叠的像素。
附:
答一个读者的疑问:
可以麻烦以计算一下一个5x5的矩阵:【(7,12,9,1,2),(25,3,75,45,11),(27,2,5,54,7),(68,86,7,41,20),(98,54,65,5,19)】的计算结果吗?我计算出来的是【(7,12,9,空值,2),(25,空值,75,45,11),(27,空值,空值,54,空值),(68,86,空值,41,20),(98,空值,65,空值,19)】
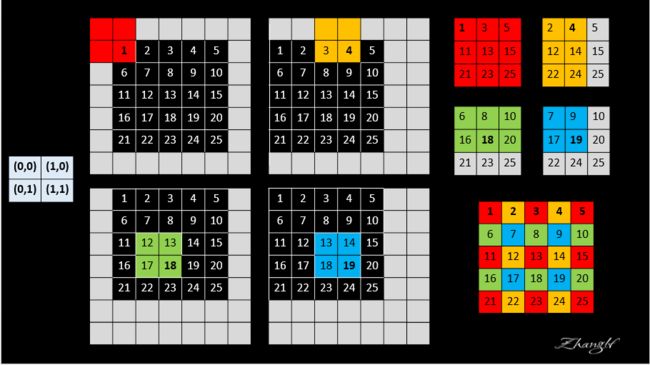
我重新做了张图:
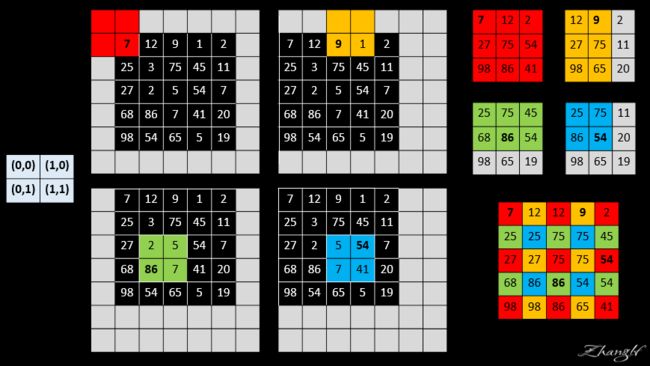
好,到此就完成了对FCN论文中的 Shift-and-stitch 的详尽解释,好辛苦。还是那句酷酷的话:
转载请说明出处。

参考资料:
[1] Fully Convolutional Networks for Semantic Segmentation
[2] Recurrent Convolutional Neural Networks for Scene Parsing
[3] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. In ICLR, 2014.
[4] Convolutional Neural Networks with Intra-layer Recurrent Connections for Scene Labeling