原文链接:聚类(一):DBSCAN算法实现(r语言)
微信公众号:机器学习养成记 搜索添加微信公众号:chenchenwings
DBSCAN(Density-BasedSpatial Clustering of Applications with Noise),一种基于密度的聚类方法,即找到被低密度区域分离的稠密区域,要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定阈值。
Some points
一、两个参数。
1,距离参数(Eps)
2,邻域内点最少个数(MinPts)
二、根据基于中心的密度进行点分类。
密度的基于中心的方法使得点分为三类:
1,核心点。稠密区域内部的点。该点以Eps为半径的区域内点的个数不少于MinPts(包括自身)。
2,边界点。稠密区边缘上的点,不是核心点,但在某个或多个核心点邻域内。
3,噪声点。稀疏区域中的点,既非核心点也非边界点。
4,密度可达。如果点p在核心点q的Eps邻域内,则称p是从q出发可以直接密度可达。如果存在点链p1,p2, …, pn,p1=q,pn=p,pi+1是从pi直接密度可达,则称点p是从q关于r和M密度可达的,密度可达是单向的。
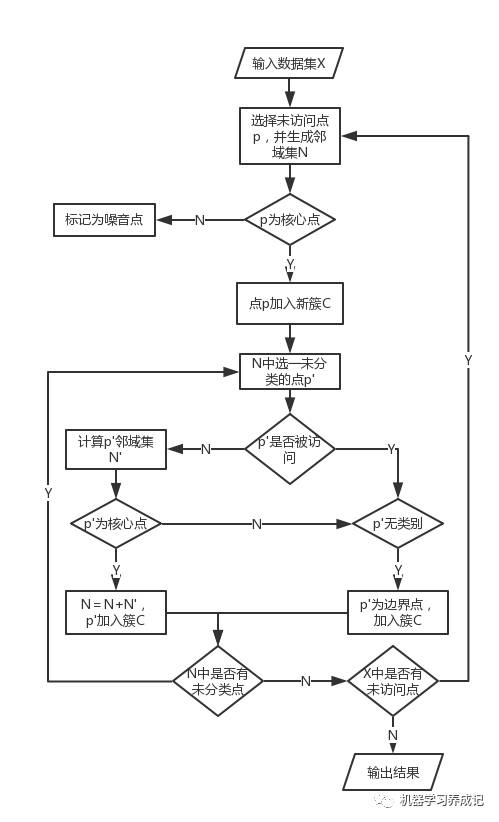
算法流程
从某点出发,将密度可达的点聚为一类,不断进行区域扩张,直至所有点都被访问。
R语言实现
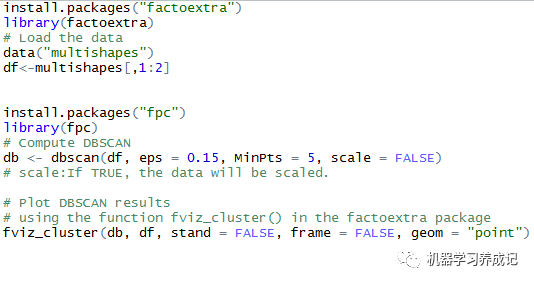
在R中实现DBSCAN聚类,可以使用fpc包中的dbscan()函数。在下面的例子中,我们使用factoextra包中的数据集multishapes进行演示。
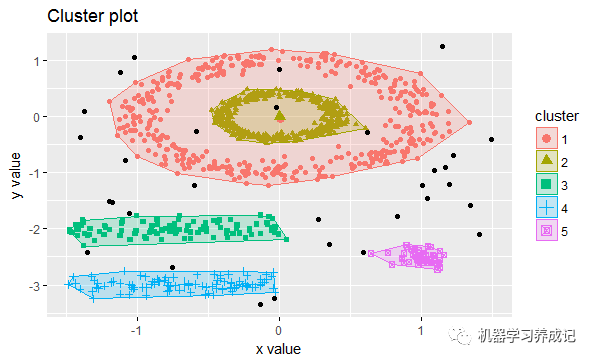
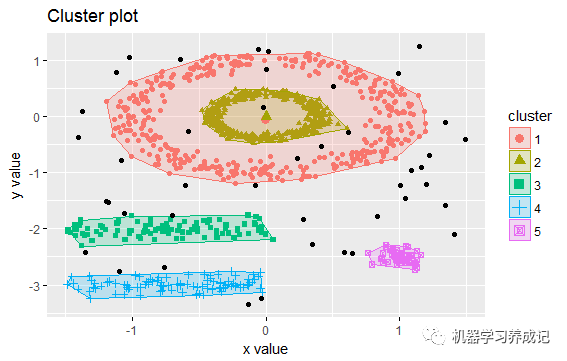
如下可查看聚类后的结果:

具体每个样本点的分类结果,可用db$cluster查看,其中0表示噪声点,如下随机显示50个点的分类结果:
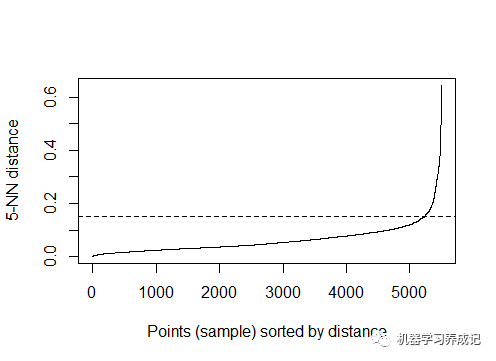
选择最优的Eps值
方法为计算每个点到其最近邻的k个点的平均距离。k的取值根据MinPts由用户指定。R语言中,使用dbscan包中的kNNdistplot()函数进行计算。

由图可知,拐点处基本在0.15左右,因此可以认为最优Eps值在0.15左右。
自定义距离公式
dbscan()函数中计算距离公式为欧式距离,在一些特定的场合无法使用,比如要计算地图上两点的距离,就要应用特定的计算地图上两点的距离公式。
R里面的很多函数都是开源的,因此,直接运行fpc::dbscan可以看到此函数的原程序。我们用geosphere包中的distm()函数对原程序中的距离计算公式进行修改,实现地图上两点距离的计算。
将原程序中的distcomb函数改为如下形式:
将修改过的dbscan函数重新命名为disdbscan,重新将数据进行聚类:

DBSCAN优缺点
优点:
(1)聚类速度快,且能够有效处理噪声点。
(2)能发现任意形状的空间聚类。
(3)聚类结果几乎不依赖于点遍历顺序。
(4)不需要输入要划分的聚类个数。
缺点:
(1)当数据量增大时,要求较大的内存支持I/O消耗也很大;
(2)当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差。
聚类(三):KNN算法(R语言)
聚类(二):k-means算法(R&python)
微信公众号:机器学习养成记 搜索添加微信公众号:chenchenwings

扫描二维码,关注我们。
如需转载,请在开篇显著位置注明作者和出处,并在文末放置机器学习养成记二维码和添加原文链接。
快来关注我们吧!
