针对闭包相信小伙伴们有很多不同的概念跟理解
何为闭包,从结构上来讲,闭包就是函数套函数,类似递归这种函数调用函数本身的也算是闭包;当然这是从结构上来看,从闭包的特点来看,递归又不算是闭包
闭包的作用主要是获取函数内部的局部变量,这也是Javascript语言的特殊之处
JS 的闭包包含以下要点:
函数声明的时候,会生成一个独立的作用域
同一作用域的对象可以互相访问
作用域呈层级包含状态,形成作用域链,子作用域的对象可以访问父作用域的对象,反之不能;另外子作用域会使用最近的父作用域的对象
上代码理解闭包,通过实例会更容易理解
function f1(){
var n=999; =>一定要加声明 不然变成全局变量了
return function f2(){
console.log(n);
}
}
f1()()// 999
js中变量只有两种情况,局部变量与全局变量
这就是函数的作用域链
我把代码解构一下 方便大家理解
function f1(){ ---------------------------------------------
var n=999;
此处都属于f1的作用域 也可以称之父作用域
return function f2(){ -------------------------
console.log(n); 这段就是子作用域
}-----------------------------------------
}--------------------------------------------------------------------------------------
f1()()// 999
f1()的结果是返回f2 f2()函数执行 打印n 但是此时f2中并没有n
那么他就会往它的父作用域去找 ,好 此时找到了n 那么此时n为999
var n=999;
function f1(){
return function f2(){
console.log(n);
}
}
f1()()// 999
相同的, 如果f1里不存在n 那么就会再去上一级 也就是window中寻找n 那么此时n就是window中的n
var n=999;
function f1(){
var n=80;
return function f2(){
console.log(n);
}
}
f1()()// 80
此时 f1中也有了n 那么 根据前面说的 闭包的特点 子作用域会使用最近的父作用域的对象
他会取到最近的作用域的属性 此时n为80
function f1(){
return function f2(){
console.log(n);
}
}
f1()()// undefined
var n=80;
注意,作用域只会向上寻找,不会向下,函数的声明位置是无所谓的,这根函数的预解析有关,函数的声明只跟调用有关,此时在函数向上寻找n的过程中没有发现n,其实已经发现了,n等于undefined此时,因为var 变量提升
通过这个例子,我想大家很容易理解上面特点的第三条
作用域呈层级包含状态,形成作用域链,子作用域的对象可以访问父作用域的对象,反之不能;另外子作用域会使用最近的父作用域的对象
那么我们也说过 闭包的作用主要是获取函数内部的局部变量
我们尝试来提取一下
function f1(){
return function f2(){
for(var i=0;i<10;i++){
console.log(i) //0,1,2,3,4,5,6,7,8,9
}
}
}
f1()()
这样我们就可以将子函数的变量给提取出来了
我们都知道 for循环是异步进行的 如果我们在外面调用此方法,打印出来的是10个10
待会我们一起分析几道闭包的笔试题来做更深入的了解
这里我们番外一下,什么是js的 任务队列
在此之前希望你对promise又简单的了解,不然下方的例子可能看不懂
首先我们要知道,javascript它是单线程语言
JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。那么,为什么JavaScript不能有多个线程呢?这样能提高效率啊。
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
之所以js是单线程语言
就是说在一行代码执行的过程中,必然不会存在同时执行的另一行代码,就像使用alert()以后进行疯狂console.log,如果没有关闭弹框,控制台是不会显示出一条log信息的
亦或者有些代码执行了大量计算,比方说在前端暴力破解密码之类的鬼操作,这就会导致后续代码一直在等待,页面处于假死状态,因为前边的代码并没有执行完。
所以如果全部代码都是同步执行的,这会引发很严重的问题,比方说我们要从远端获取一些数据,难道要一直循环代码去判断是否拿到了返回结果么?就像去饭店点餐,肯定不能说点完了以后就去后厨催着人炒菜的,会被揍的。
于是就有了异步事件的概念,注册一个回调函数,比如说发一个网络请求,我们告诉主程序等到接收到数据后通知我,然后我们就可以去做其他的事情了。
然后在异步完成后,会通知到我们,但是此时可能程序正在做其他的事情,所以即使异步完成了也需要在一旁等待,等到程序空闲下来才有时间去看哪些异步已经完成了,可以去执行。
比如说打了个车,如果司机先到了,但是你手头还有点儿事情要处理,这时司机是不可能自己先开着车走的,一定要等到你处理完事情上了车才能走。
相反,如果是公交车,那就不管你了
因为同步太好理解了,从上向下执行操作,主要讲一下异步事件
微任务(microtask)与宏任务(macrotask)=>异步事件
mircotask(微任务)
promise
mutation.oberver
process.nextTick
marcotask(宏任务)
setTimeout,setInterval
requestAnimationFrame
解析HTML
执行主线程js代码
修改url
页面加载
用户交互
有些没见过或者不认识的没关系,因为有些是node.js中的 我这边也主要举例浏览器内的事件队列
console.log('script start'); 第一个打印
setTimeout(function() {
console.log('setTimeout'); 第五个打印
}, 0);
Promise.resolve().then(function() {
console.log('promise1'); 第三个打印
}).then(function() {
console.log('promise2'); 第四个打印
});
console.log('script end'); 第二个打印

从这里我们可以看出 微任务(mircotask)它的事件比宏任务(marcotask)优先执行
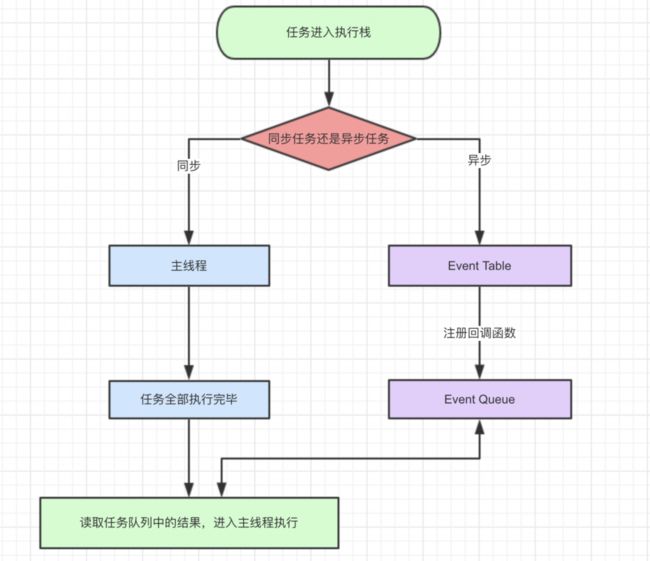
解读:
同步和异步任务分别进入不同的执行"场所",同步的进入主线程,异步的进入Event Table并注册函数
当指定的事情完成时,Event Table会将这个函数移入Event Queue。
主线程内的任务执行完毕为空,会去Event Queue读取对应的函数,进入主线程执行。
上述过程会不断重复,也就是常说的Event Loop(事件循环)。
let data = [];
$.ajax({
url:www.javascript.com,
data:data,
success:() => {
console.log('发送成功!');
}
})
console.log('代码执行结束');
ajax进入Event Table,注册回调函数success。
执行console.log('代码执行结束')。
ajax事件完成,回调函数success进入Event Queue。
主线程从Event Queue读取回调函数success并执行。
微任务和宏任务皆为异步任务,也就是说它们都会进入Event Table,它们都属于一个队列,主要区别在于他们的执行顺序,Event Loop的走向和取值。那么他们之间到底有什么区别呢?
我们先来看看setTimeout(宏任务),这个大家应该很熟悉
setTimeout(() => {
console.log('延时3秒');
},3000)
很明显 3秒后 打印出数据 再看一个函数
setTimeout(() => {
task();=>随意的一个函数
},3000)
console.log('执行console');
有时候我们通过定时器来触发函数的时候有没有发现,有时候明明写的延时3秒,实际却5,6秒才执行函数,当然这个函数需要一定的复杂性,一时间难以写出就 顺带说明一下
我们知道setTimeout这个函数,是经过指定时间后,把要执行的任务(本例中为task())加入到Event Queue中,又因为是单线程任务要一个一个执行,如果前面的任务需要的时间太久,那么只能等着,导致真正的延迟时间远远大于3秒。
关于setTimeout要补充的是,即便主线程为空,0毫秒实际上也是达不到的。根据HTML的标准,最低是4毫秒。也就说哪怕定时器之前没有任何事件,也要4毫秒之后才运行setTimeout 有兴趣的同学可以自行了解
接着我们看下promise(微任务)
console.log('start') 第一
let p = new Promise((resolve,reject)=>{
console.log('Promise1') 第二
resolve()
})
p.then(()=>{
console.log('Promise2') 第四
})
console.log('end')第三

有些小伙伴又懵了,promise不是异步操作吗
我们先抛开任务队列不讲,注意了,只有resolve与reject函数 才是真正的异步操作,也就是说在
new Promise(){
这一块还是同步事件
}
因为js是单线程 所以此时 从上到下 先完成同步,再执行异步
接着我们来分析promise(微任务)混搭setTimeout(宏任务)
setTimeout(()=>{
console.log('setTimeout1')
},0)
let p = new Promise((resolve,reject)=>{
console.log('Promise1')
resolve()
})
p.then(()=>{
console.log('Promise2')
})
最后输出结果是Promise1,Promise2,setTimeout1
虽然同是异步事件,但微任务优先于宏任务(暂时先这么理解)
再看一个例子
Promise.resolve().then(()=>{
console.log('Promise1')
setTimeout(()=>{
console.log('setTimeout2')
},0)
})
setTimeout(()=>{
console.log('setTimeout1')
Promise.resolve().then(()=>{
console.log('Promise2')
})
},0)
这回是嵌套,大家可以看看,最后输出结果是Promise1,setTimeout1,Promise2,setTimeout2
一步步来分析一下
第一个输出Promise1 应该没什么问题,因为此时是同步
第二个输出setTimeout1 有点问题来了,为什么promise先执行,但是输出的是下面的setTimeout呢?
此时给大家理一下正确的任务队列
当我们同步事件运行完成的时候,我们先来看看当前的任务队列
首先是 microtasks(微任务队列),此时是上方的promise=>这个应该好理解
然后是macrotasks(宏任务队列),此时很明显是下方的setTimeout
先执行微任务队列中的promise,此时会生成一个新的setTimeout(宏任务)事件
这时候我们宏任务队列增加了一条那就是setTimeout2,那么此时的顺序就是setTimeout1,setTimeout2(还是不懂的同学可以写个记事本记录一下)
注意,微任务此时已经清空了,对吧。因为promise执行完了
此时执行宏任务事件,根据顺序先执行setTimeout1,所以第二个打印setTimeout1,照理说接下去打印setTimeout2,但是再执行setTimeout1的时候这个任务又创建了promise 微任务,此时微任务队列又增加了一条primise2事件
那么老样子,微任务事件一旦生成,优先于宏任务,那么此时又执行了promise2,最后执行setTimeout2
其实是应该当微任务队列全执行完了才执行宏任务队列,因为此处例子不是很复杂,起初只有一条微任务队列
这是浏览器中常见的事件,放更复杂的怕大家怀疑人生,希望大家好好理解一下
接下来我找几道闭包的笔试题来巩固一下什么是闭包
for (var i = 1; i <= 5; i++) {
setTimeout( function timer() {
console.log(i);
}, 0); 这里输出5个6我想很容易理解
}
好 不修改代码,如何输出1,2,3,4,5,考验了你对闭包的理解与写法
for (var i = 1; i <= 5; i++) {
(function(i){
setTimeout( function timer() {
console.log(i);
}, 0 );
})(i);
}
首先要了解结构,函数套函数
其次明白闭包的作用,它是获取函数内部的变量,那肯定不要写存在变量函数的里面,不然我们无法获取
接下来就是如上方所示
永远不要小瞧代码 下面这道题让新手做 头皮发麻
function fun(n,o){
console.log(o);
return {
fun:function(m){
return fun(m,n);
}
};
}
var a = fun(0);a.fun(1); a.fun(2); a.fun(3);
var b = fun(0).fun(1).fun(2).fun(3);
var c = fun(0).fun(1); c.fun(2);c.fun(3);
问上面各个函数打印什么
解析这道题之前,先带个小坑,如果我们的函数参数未传参,默认为undefined
也就是说 function fn(a,b){console.log(a,b)}
那我们使用的时候fn(b) 那么a其实是等于undefined的
好接来下我们来一步步解析一下这道题
一部部来 先看var a 一共四个值 fun(0);a.fun(1);a.fun(2);a.fun(3);
先解释fun(0) 我们此时将代码带入 ,注意此时函数返回的是一个对象
{
fun:function(m){
return fun(m,n);
}
到这里就结束了,刚才提过未带入参数,则默认undefined 那么此时 fun(0)最后打印结果就是undefined
接下来是a.fun(1),注意此时a已经改变了,var a=fun(0) a已经默认返回了一个对象,此时调用对象里面的fun函数
仔细看细节,我们给他转换一下就是
function(1){
return fun(1,n) =>注意这里 他调用了上面那个函数 但是这里传入了两个函数
}
到这里是不是有思路了呢,我把函数整理一下 再看一遍
function fun(n,o){ 第一步 首先我们进行fun(0)
console.log(o); 也就是说此时里面的值其实是这样的,n=0,o=undefined(这也是第一步的值)
return { 第二步再次进行调用fun,但是注意,此时的作用域变了
fun:function(m){ function(1)
return fun(m,n); 此时m=1,但是n等于多少呢,n并没有传入,好 它会去父作用域去找,会找到n=0
} 接着调用最初的fun(n,o)这个方法 ,但此时,n形参对应m实参,o形参对应n实参
}; 那么此时o=n=0
} 所以 控制台 将 打印 0 有没有发现其实我们只要判断n的值就可以了
a.fun(2); a.fun(3);的结果其实跟a.fun(1)相同 都是0 不要被迷惑了哦 要相信自己
来分析一下 b ; var b = fun(0).fun(1).fun(2).fun(3);
注意这里全是调用,我们一步一步看
根据第一步的分析我们已经了解了,只需要判断n的值就可以了
fun(0) 得 n=undefined fun(0).fun(1)得 n=0 按照原来的思路 一直发现 n其实很简单 最终n=2
四次函数调用 控制台将会打印 undefined 0 1 2 现在是不是觉得很简单了呢