本文是我自己动手用R语言写的实现分类树的代码,以及在此基础上写的袋装法(bagging)和随机森林(random forest)的算法实现。全文的结构是:
- 分类树
- 基本知识
- pred
- gini
- splitrule
- splitrule_best
- splitrule_random
- splitting
- buildTree
- predict
- 装袋法与随机森林
- 基本知识
- bagging
- predict_ensemble
- 性能测试
- 写在后面
全部的代码如下:
## x和y为自变量(矩阵)和因变量(列向量)
ylevels = levels(y)
nlevels = length(ylevels)
n = length(y)
k = dim(x)[2]
pred = function(suby) {
# majority vote 所占比例最大的值为预测值
vote = rep(0,nlevels)
for (i in 1:nlevels) { vote[i] = sum(suby==ylevels[i]) }
return(ylevels[which.max(vote)])
}
gini = function(suby,summary = FALSE) {
# 给定一列因变量,计算它的基尼系数
if (!summary) suby = as.vector(summary(suby))
obs = sum(suby)
return( 1-(drop(crossprod(suby)))/(obs*obs) )
}
splitrule = function(subx,suby) {
#这里subx和suby都是向量,给定一个自变量,求出它的最优划分条件
subylen = length(suby)
xvalues = sort(unique(subx))
if (length(xvalues)>1) { #只有在自变量的取值不是完全相同时(有不同的x),才能够对x划分
cutpoint = ( xvalues[1:(length(xvalues)-1)] + xvalues[2:length(xvalues)] )/2
minimpurity = 1 #初始启动值
for ( i in 1:length(cutpoint) ) {
lefty = suby[subx>=cutpoint[i]]
righty = suby[subx1) {
intervals = cut(subx,xvalues,right = FALSE) #区间左闭右开
suby_splited = matrix(unlist(by(suby,intervals,summary)),ncol = nlevels, byrow = TRUE)
suby_splited_left = matrix(apply(suby_splited,2,cumsum),ncol = nlevels)
suby_splited_right = sweep(-suby_splited_left,2,as.vector(summary(suby)),FUN = "+")
suby_splited_left_obs = apply(suby_splited_left,1,sum)
suby_splited_right_obs = suby_length - suby_splited_left_obs
impurity = NULL
for (i in 1:(length(xvalues)-1) ) {
impurity = c(impurity,
(gini(suby_splited_left[i,],summary = TRUE)*suby_splited_left_obs[i]
+ gini(suby_splited_right[i,],summary = TRUE)*suby_splited_right_obs[i])/suby_length)
}
minimpurity = min(impurity)
splitpoint = xvalues[which.min(impurity)]
} else {
splitpoint = xvalues
minimpurity = gini(suby)
}
return(c(splitpoint,minimpurity))
}
splitrule_random = function(subx,suby) {
# splitrule的一个变形。较为极端的方法,不排序,不取唯一值,任意抽取一个数作划分节点。
suby_length = length(suby)
subx_withoutmax = subx[subx!=max(subx)]
if (length(subx_withoutmax)>0) {
splitpoint = subx_withoutmax[sample(length(subx_withoutmax),1)]
suby_splited_left = suby[subx<=splitpoint]
suby_splited_right = suby[subx>splitpoint]
impurity = (gini(suby_splited_left)*length(suby_splited_left)
+ gini(suby_splited_right)*length(suby_splited_right))/suby_length
} else{
splitpoint = 0
impurity = 1
}
return(c(splitpoint,impurity))
}
splitting = function(subx,suby,split,rf) {
# subx是一个矩阵,suby是列向量。给定自变量矩阵,返还最优划分变量和相应最优划分条件
if (!rf) chosen_variable = 1:k
if (rf == TRUE) chosen_variable = sample(1:k,round(sqrt(k)))
if (split == "best") temp = apply(subx[,chosen_variable],2,splitrule_best,suby=suby)
if (split == "random") temp = apply(subx[,chosen_variable],2,splitrule_random,suby=suby)
splitpoint = temp[1,]
minimpurity = temp[2,]
splitvariable = chosen_variable[which.min(minimpurity)] #确定第几个变量是最优划分变量
splitpoint = splitpoint[which.min(minimpurity)]
minimpurity = min(minimpurity)
return(c(splitvariable,splitpoint,minimpurity))
}
buildTREE = function(x,y,split = "best",rf = FALSE) {
TREE = NULL
index = 1:n
tree = as.data.frame(list(leftnode=0,rightnode=0,splitvariable=0,splitpoint=0,obs=n,
pred=levels(y)[1],leaf=TRUE,begin=1,end=n))
cur = 1 #当前正在分析的节点编号,它要追赶nodes,每次循环过后增加1。
nodes = 1 #当前这棵树的总节点数量
while ((cur<=nodes) ) {
beginC = tree$begin[cur]; endC = tree$end[cur]
indexCurrent = index[beginC:endC]
subx = x[indexCurrent,]
suby = y[indexCurrent]
impurityCurrent = gini(suby)
if (impurityCurrent>0.1) {
temp <- splitting(subx,suby,split)
if (temp[3] tree$splitpoint[cur]]
index[beginC:endC] <- c(indexL,indexR)
#这是最为聪明的一步,index被一步一步地精炼更新直至最后成品,搭配begin和end使用。
predL = pred(y[indexL])
predR = pred(y[indexR])
nodeL = as.data.frame(list(leftnode=0,rightnode=0,splitvariable=0,splitpoint=0,obs=length(indexL),
pred=predL,leaf=TRUE,begin = beginC, end = beginC+length(indexL)-1) )
nodeR = as.data.frame(list(leftnode=0,rightnode=0,splitvariable=0,splitpoint=0,obs=length(indexR),
pred=predR,leaf=TRUE,begin = beginC+length(indexL),end = beginC+length(indexCurrent)-1) )
tree = as.data.frame(rbind(tree,nodeL,nodeR))
}
}
cur = cur + 1 #迭代循环iterator
}
TREE <- tree
return(TREE)
}
predict = function(TREE,newx) { #newx是一个自变量矩阵,返还一列因变量的预测值。
subpredict = function(subx) { #给定一行观测的自变量,我预测它的因变量
row = 1 #从第一个节点开始出发
while(TRUE) {
if (TREE$leaf[row]==TRUE) {
predicted = TREE$pred[row]
break
}
#给定一个观测值,判断它是往左走还是往右走,一直走下去,直到抵达叶节点leaf为止
if (subx[TREE$splitvariable[row]] <= TREE$splitpoint[row]) {row = TREE$leftnode[row]}
else {row = TREE$rightnode[row]}
}
return(predicted)
}
return(apply(newx,1,subpredict))
}
bagging = function(x,y,trees = 150,split = "best",rf = FALSE) {
TREES = list()
for (i in 1:trees) {
bootstrap_index = sample(1:n,n,replace = TRUE)
x_bagging = x[bootstrap_index,]
y_bagging = y[bootstrap_index]
tree = buildTREE(x_bagging,y_bagging,split,rf)
TREES = c(TREES,list(tree))
}
return(TREES)
}
predict_ensemble = function(newx,TREES) { #此处newx为自变量矩阵,TREES为bagging树林或是随机森林
subpredict_ensemble = function(subx,TREES){ #给定一行观测的自变量和一片树林,我预测它的因变量
subpredict = function(TREE,subx) { #给定一行观测的自变量和一棵树的结构,我预测它的因变量
row = 1 #从第一个节点开始出发
while(TRUE) {
if (TREE$leaf[row]==TRUE) {
predicted = TREE$pred[row]
break
}
#给定一个观测值,判断它是往左走还是往右走,一直走下去,直到抵达叶节点leaf为止
if (subx[TREE$splitvariable[row]] <= TREE$splitpoint[row]) {row = TREE$leftnode[row]}
else {row = TREE$rightnode[row]}
}
return(predicted)
}
sub_predicted = unlist(lapply(TREES,subpredict,subx)) #对每一行数据进行预测
return( names(summary(sub_predicted))[which.max(summary(sub_predicted))] )
#每棵树进行投票,确定最终预测值
}
apply(newx,1,subpredict_ensemble,TREES)
}
分类树
基本知识
有监督的机器学习中有两类主要问题,回归问题(预测房价、预测销售量)和分类问题(预测性别、预测是否信贷违约)。对应地,决策树有回归树和分类树两种。决策树算是最接近人类思考模式的算法之一,从图像上来看就是一连串的流程图,给定一个个体的信息,沿着流程往下走,判断它最终的归属。下面放两张马老师的课件,对应的场景是预测某位用户是否会拖欠贷款。
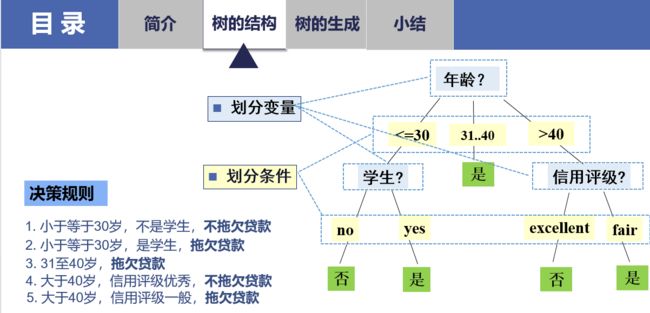
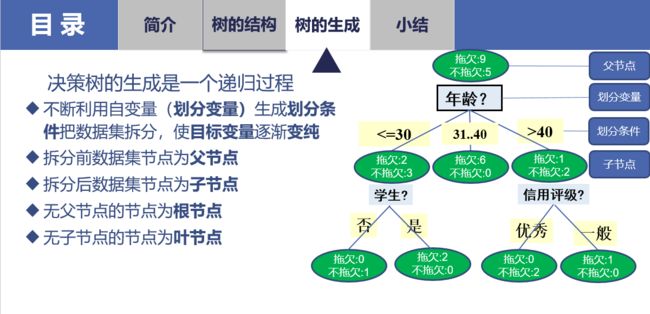
生成决策树的规则是不断地使得不纯度下降,对于不纯度的计算,可以采用基尼系数,公式为:

例如,十个用户中有六个拖欠贷款,四个按时还贷,那么不纯度为:1 - 0.4^2 - 0.6^2 = 1 - 0.16 - 0.36 = 0.48
给定一个树节点,是否进行划分,取决于划分之后不纯度是否会下降,如果下降,则继续划分,如果不能下降,该节点成为叶节点。如果能够划分,使得不纯度下降幅度最大的那个自变量和划分节点便是最优划分变量和最优划分条件。
讲完基本概念,我们来看用R代码实现分类树,涉及到了下面几个函数。
- pred:给定一列因变量,求出其中占比例最大的值。分类树中,对于最终的结果的预测,是由落入到这个叶节点中的占比例最大的值确定的。
- gini:给定一列因变量,求出其基尼系数。
- splitrule:给定一列自变量和因变量,求出这个自变量的最优划分条件和划分之后的不纯度。
- split_best:对上一版splitrule的改进,减少了计算量。
- split_random:对split_best的再改进,减少了计算量,同时有一定几率能带来预测精度的提高(没有严谨的数学证明)。
- splitting:给定一个自变量矩阵和一列因变量,求出所有自变量中最优的划分变量,以及对应的最优划分条件和不纯度。
- buildTREE:主函数,在上面各个基本函数的基础上,给定一套数据,生成一棵分类树。
下面逐个说明。
pred()
pred = function(suby) {
# majority vote 所占比例最大的值为预测值
vote = rep(0,nlevels)
for (i in 1:nlevels) { vote[i] = sum(suby==ylevels[i]) }
return(ylevels[which.max(vote)])
}
给定一列因变量,求出其中占比例最大的值。分类树中,对于最终的结果的预测,是由落入到这个叶节点中的占比例最大的值确定的。
gini()
gini = function(suby,summary = FALSE) {
# 给定一列因变量,计算它的基尼系数
if (!summary) suby = as.vector(summary(suby))
obs = sum(suby)
return( 1-(drop(crossprod(suby)))/(obs*obs) )
}
这个函数就是照着数学公式来写的,没什么特别。
summary是R里面一个相当好用的函数,它能够统计一个factor的频数:
> example
[1] absent absent present absent absent absent absent
[8] absent absent present present absent absent absent
[15] absent absent absent absent absent absent
Levels: absent present
> summary(example)
absent present
17 3
因为不知道你要传入的因变量是以像example这样逐个列出的形式,还是以像summary(example)这样进行频数统计的形式,所以设置了一个summary参数,默认FALSE,即默认以前者的形式传入因变量。
splitrule()
splitrule = function(subx,suby) {
#这里subx和suby都是向量,给定一个自变量,求出它的最优划分条件
subylen = length(suby)
xvalues = sort(unique(subx))
if (length(xvalues)>1) { #只有在自变量的取值不是完全相同时(有不同的x),才能够对x划分
cutpoint = ( xvalues[1:(length(xvalues)-1)] + xvalues[2:length(xvalues)] )/2
minimpurity = 1 #初始启动值
for ( i in 1:length(cutpoint) ) {
lefty = suby[subx>=cutpoint[i]]
righty = suby[subx写得很直观的一个函数,完全就是按照上面的决策树的流程图来写的。传入一列因变量和一列自变量,对自变量进行从小到大排序,给定一个划分点cutpoint,自变量小于等于cutpoint的观测落入左边的子节点,自变量大于cutpoint的观测落入到右边的子节点,划分之后,计算不纯度并记录一下。遍历所有可能的cutpoint,记录最小的不纯度,以及对应的cutpoint值。
splitrule_best()
splitrule_best = function(subx,suby) {
# 这是对上面splitrule原有版本的改进。自变量按从小到大排列,每次划分时,把落入到左边的观测记录下来
# 随着划分节点不断增大,落入左节点的数据越来越多,在上一次的基础上进行累加就行。
suby_length = length(suby)
xvalues = sort(unique(subx))
if (length(xvalues)>1) {
intervals = cut(subx,xvalues,right = FALSE) #区间左闭右开
suby_splited = matrix(unlist(by(suby,intervals,summary)),ncol = nlevels, byrow = TRUE)
suby_splited_left = matrix(apply(suby_splited,2,cumsum),ncol = nlevels)
suby_splited_right = sweep(-suby_splited_left,2,as.vector(summary(suby)),FUN = "+")
suby_splited_left_obs = apply(suby_splited_left,1,sum)
suby_splited_right_obs = suby_length - suby_splited_left_obs
impurity = NULL
for (i in 1:(length(xvalues)-1) ) {
impurity = c(impurity,
(gini(suby_splited_left[i,],summary = TRUE)*suby_splited_left_obs[i]
+ gini(suby_splited_right[i,],summary = TRUE)*suby_splited_right_obs[i])/suby_length)
}
minimpurity = min(impurity)
splitpoint = xvalues[which.min(impurity)]
} else {
splitpoint = xvalues
minimpurity = gini(suby)
}
return(c(splitpoint,minimpurity))
}
这个是对刚才的splitrule的改进,最终实现的效果是相同的。上一版的缺点在于,每给一个cutpoint,所有的自变量值都要和它进行比较,从而判断是要落入左边还是落入右边。这其实做了很多轮的大小比较,浪费了时间。改进的想法是,把所有的cutpoint都摆出来,把自变量值相应地划入到不同的区间中,进行记录。这个时候,R自带的cut函数就派上用场了。
> example = 1:15
> example
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
> cut(example,breaks = c(0,3,7,15))
[1] (0,3] (0,3] (0,3] (3,7] (3,7] (3,7] (3,7]
(7,15] (7,15] (7,15] (7,15] (7,15] (7,15] (7,15] (7,15]
Levels: (0,3] (3,7] (7,15]
如上,自变量有15个取值,若以3和7作为划分点,可以把所有的自变量归入到三个区间内。这样一来,通过命令intervals = cut(subx,xvalues,right = FALSE)就能够把所有的自变量取值进行划分。
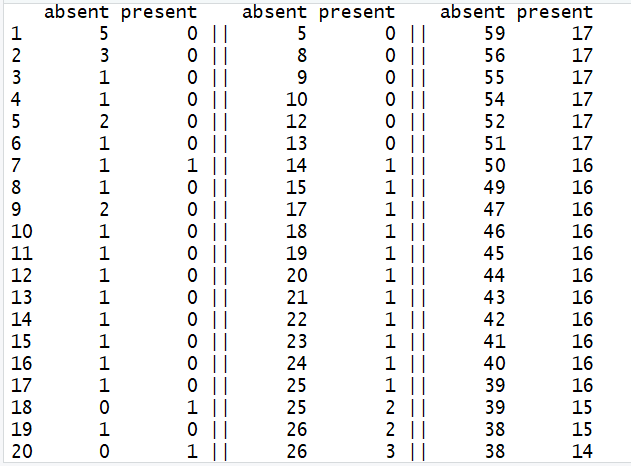
以rpart包中的kyphosis数据集为例,该数据共有81个观测,其中有64个因变量取值"absent",有17个因变量取值"present"。
左边是每个区间内的因变量情况,中间是累积的落入到左边子节点的情况,右边是累积的落入到右边子节点的情况。先看第一行,能够看到,第一次划分时,有5个观测落入到左节点,剩余的76个观测落入右节点;同样地,第二行可以看出,有8个观测落入到左节点,剩下的73个观测落入到右节点。这样,只通过一轮的比较大小,就能够完成任务,成功减少了运算量。
splitrule_random()
splitrule_random = function(subx,suby) {
# splitrule的一个变形。较为极端的方法,不排序,不取唯一值,任意抽取一个数作划分节点。
suby_length = length(suby)
subx_withoutmax = subx[subx!=max(subx)]
if (length(subx_withoutmax)>0) {
splitpoint = subx_withoutmax[sample(length(subx_withoutmax),1)]
suby_splited_left = suby[subx<=splitpoint]
suby_splited_right = suby[subx>splitpoint]
impurity = (gini(suby_splited_left)*length(suby_splited_left)
+ gini(suby_splited_right)*length(suby_splited_right))/suby_length
} else{
splitpoint = 0
impurity = 1
}
return(c(splitpoint,impurity))
}
即便进行了改进,splitrule_best的运算量还是大,因为每次调用这个函数时都要对所有的自变量取值进行排序。splitrule_random函数的做法是,不进行排序,从自变量中随便挑出一个值作为cutpoint,并记录不纯度。例如,自变量取值是1:20,随机挑选一个值(例如,选出7),那么自变量取1:7的观测落入左节点,取8:20的落入右节点。
这是一种相当简单粗暴的做法,因为计算得到的不纯度有可能非常高,而上面的splitrule_best函数计算得到的,是所有可能的不纯度里最低的那个,一定是优于splitrule_random得到的不纯度的。但是,这种做法有它的道理,具体的会在下面讲随机森林的时候谈到。
splitting()
splitting = function(subx,suby,split,rf) {
# subx是一个矩阵,suby是列向量。给定自变量矩阵,返还最优划分变量和相应最优划分条件
if (!rf) chosen_variable = 1:k
if (rf == TRUE) chosen_variable = sample(1:k,round(sqrt(k)))
if (split == "best") temp = apply(subx[,chosen_variable],2,splitrule_best,suby=suby)
if (split == "random") temp = apply(subx[,chosen_variable],2,splitrule_random,suby=suby)
splitpoint = temp[1,]
minimpurity = temp[2,]
splitvariable = chosen_variable[which.min(minimpurity)] #确定第几个变量是最优划分变量
splitpoint = splitpoint[which.min(minimpurity)]
minimpurity = min(minimpurity)
return(c(splitvariable,splitpoint,minimpurity))
}
之前的splitrule函数是把一列自变量的最优划分点给求出来,现在的这个splitting函数是把所有自变量的最优划分点和相应的不纯度都求出来。不纯度最低的划分变量,便是我们要的最优划分变量。
buildTREE()
buildTREE = function(x,y,split = "best",rf = FALSE ) {
TREE = NULL
index = 1:n
tree = as.data.frame(list(leftnode=0,rightnode=0,splitvariable=0,splitpoint=0,obs=n,
pred=levels(y)[1],leaf=TRUE,begin=1,end=n))
cur = 1 #当前正在分析的节点编号,它要追赶nodes,每次循环过后增加1。
nodes = 1 #当前这棵树的总节点数量
while ((cur<=nodes) ) {
beginC = tree$begin[cur]; endC = tree$end[cur]
indexCurrent = index[beginC:endC]
subx = x[indexCurrent,]
suby = y[indexCurrent]
impurityCurrent = gini(suby)
if (impurityCurrent>0.1) {
temp <- splitting(subx,suby,split)
if (temp[3] tree$splitpoint[cur]]
index[beginC:endC] <- c(indexL,indexR)
#这是最为聪明的一步,index被一步一步地精炼更新直至最后成品,搭配begin和end使用。
predL = pred(y[indexL])
predR = pred(y[indexR])
nodeL = as.data.frame(list(leftnode=0,rightnode=0,splitvariable=0,splitpoint=0,obs=length(indexL),
pred=predL,leaf=TRUE,begin = beginC, end = beginC+length(indexL)-1) )
nodeR = as.data.frame(list(leftnode=0,rightnode=0,splitvariable=0,splitpoint=0,obs=length(indexR),
pred=predR,leaf=TRUE,begin = beginC+length(indexL),end = beginC+length(indexCurrent)-1) )
tree = as.data.frame(rbind(tree,nodeL,nodeR))
}
}
cur = cur + 1 #迭代循环iterator
}
TREE <- tree
return(TREE)
}
这是分类树算法的主函数,也是最难写的一个函数。代码不多,但是写了很长时间。它的作用是,在上面几个基本函数的基础上,把一棵分类树给生成出来。写这个函数时,一个首要的问题是:怎么表达一棵树?
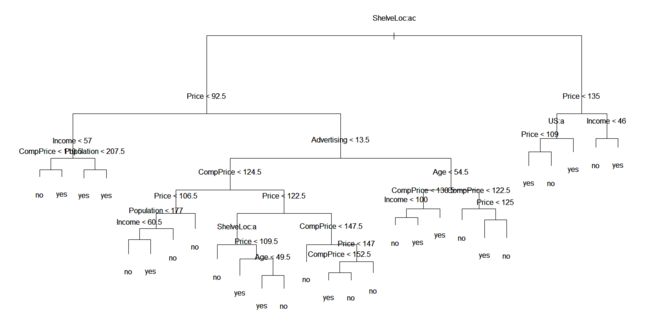
首先映入脑海的是这样的图像,一棵树应该用这样一幅图来表达,把划分变量和划分条件讲得很清楚。可是,R里面怎么用代码把一幅图给写出来?
上了马老师的课之后,我认识到,分类树从表面上看是一幅图,实际上它的结构是一张表(data.frame),图像只不过是直观地表达这张表格罢了。buildTREE这个函数,最终生成的便是这样一个data.frame。
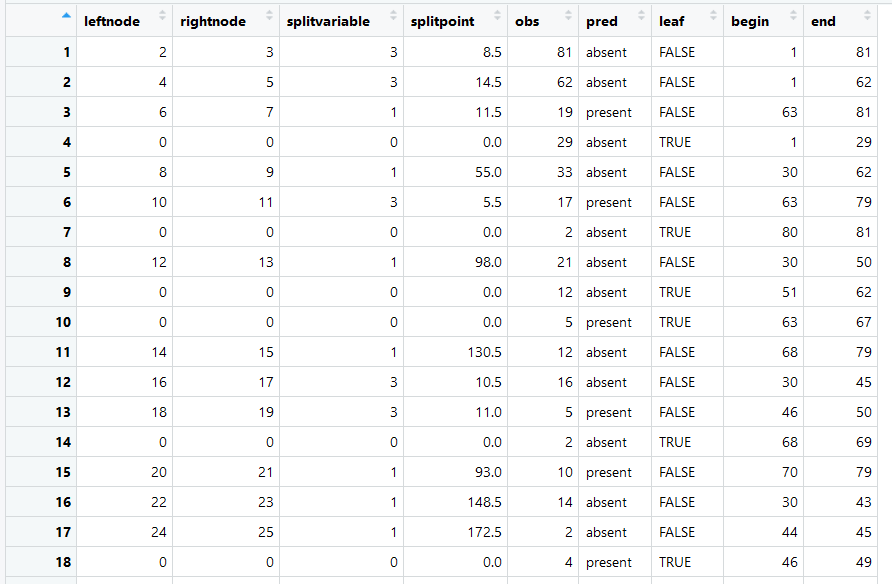
每一行表示一个节点的相关信息,节点的编号由最左端的1,2,3,4...确定。leftnode和rightnode表示这个节点划分之后的子节点的编号,如果都是0,则表明这个节点是叶节点。splitvariable表示最优划分变量是第几个自变量,splitpoint表示划分点,小于等于这个值的观测落入左节点,大于这个值的观测落入右节点。obs表示有多少个观测落入到这个节点中,leaf表示该节点是否为叶节点,如果是,pred表示这个叶节点的预测值。
这个函数中最关键的三行代码是
indexL = indexCurrent[subx[,tree$splitvariable[cur]] <= tree$splitpoint[cur]]
indexR = indexCurrent[subx[,tree$splitvariable[cur]] > tree$splitpoint[cur]]
index[beginC:endC] <- c(indexL,indexR)
index是一个十分重要的变量,用来标记落入每一个节点中的观测编号。还是举刚才的kyphosis的例子,观测量有81个,index最初是1:81,在第一次划分后,有62个观测落入到左边,19个观测落入到右边,此时对index进行顺序调整,使其前62个数字表示左节点的观测编号,后19个数字表示右节点的观测编号。按照这种方法进行下去,每轮迭代都对index进行更新,在完成了所有的划分之后,最终的index记录了所有的叶节点的观测编号。

使用index这个向量的意义在于,你不必每轮迭代都使用一个list来记录落入到某个节点的观测(我第一次实现分类树就是这么做的),不必要浪费内存。能够想到使用向量来记录观测,用data.frame来表达一棵决策树,需要对数据结构有足够深的理解,这一点我在上一篇博客里提到了。
predict()
predict = function(TREE,newx) { #newx是一个自变量矩阵,返还一列因变量的预测值。
subpredict = function(subx) { #给定一行观测的自变量,我预测它的因变量
row = 1 #从第一个节点开始出发
while(TRUE) {
if (TREE$leaf[row]==TRUE) {
predicted = TREE$pred[row]
break
}
#给定一个观测值,判断它是往左走还是往右走,一直走下去,直到抵达叶节点leaf为止
if (subx[TREE$splitvariable[row]] <= TREE$splitpoint[row]) {row = TREE$leftnode[row]}
else {row = TREE$rightnode[row]}
}
return(predicted)
}
return(apply(newx,1,subpredict))
}
这个函数比较简单。上一步已经把一棵树(data.frame)给训练出来了,现在给定一套数据,通过划分变量和划分条件,判断观测是往左节点走还是往右节点走,沿着树一直走下去,直到走到叶节点为止。至此,预测就完成了。
装袋法与随机森林
基本知识
bagging和random forest都是基于bootstrap的集成学习方法(ensemble learning method),所谓集成学习,指的是把多个机器学习器给整合起来,综合考虑它们的结果。例如,你训练了100个学习器去做考试题,有7台机器选择A,4台机器选择B,80台机器选择C,9台机器选择D,那么你最后应该选择C选项,这就是所谓的集体智慧(Wisedom of the Crowd)。
给定原始数据,通过bootstrap生成一套新数据,在这基础上训练出一棵树,再bootstrap得到又一套数据,再训练出一棵树,持续进行下去,便得到了一片树林。bagging和随机森林便是这样得到的树林。之所以要种植多棵分类树,是因为单棵分类树有着严重的过度拟合问题,在训练集上表现良好,在测试集上却做得一塌糊涂。通过综合多棵树,能够大幅度降低variance,而只是小幅度地增加bias,这样一来测试集的MSE也就能够显著下降了。
随机森林和bagging的区别在于,bagging每一轮迭代都会遍历所有的自变量,从而找到最优的划分变量,而随机森林限定了搜索的自变量数量,在这自变量的子集里寻找最优划分变量。例如,现有25个自变量,bagging在每一个树节点处都要进行25轮循环,找到最优的那个,而随机森林在每个节点处随机地挑选出5个自变量,在这5个里找到最优的。至于这种做法究竟有什么道理,Hastie在
In other words, in building a random forest, at each split in the tree, the algorithm is not even allowed to consider a majority of the available predictors. This may sound crazy, but it has a clever rationale. Suppose that there is one very strong predictor in the data set, along with a number of other moderately strong predictors. Then in the collection of bagged trees, most or all of the trees will use this strong predictor in the top split. Consequently, all of the bagged trees will look quite similar to each other. Hence the predictions from the bagged trees will be highly correlated. In particular, this means that bagging will not lead to a substantial reduction in variance over a single tree in this setting.
决策树的决策规则是,每一次划分节点,都要使用不纯度下降最多的划分变量,一个变量能使不纯度下降0.15,另一个变量使不纯度下降0.1,决策树便会选择前一个变量。这种做法的问题在于,后者虽然效果不好,但是可能在划分以后,再次划分能够使不纯度再下降0.2,而前一个变量可能再次划分时只能使不纯度下降0.05。决策树的问题在于,它能够保证每一个节点处的划分都是最有效的,但没法保证这样生成的一棵树就是最好的。这有些像宏观经济学里讲的动态不一致,每一步的最优和整体上的最优不一致。所以Hastie说,做决策树的时候,目光要放得长远一些。
The splitting rule is too short-sighted since a seemingly worthless split early on in the tree might be followed by a very good split — that is, a split that leads to a large reduction in RSS later on.
决策树会按照最优划分准则一根筋地生成下去,而随机森林这一算法的意义在于改变这个最优划分准侧,使得每棵树之间的相似度下降,随机森林的随机便体现在随机挑选自变量上。
下面介绍一下bagging和随机森林的实现。
bagging()
bagging = function(x,y,trees = 150,split = "best",rf = FALSE) {
TREES = list()
for (i in 1:trees) {
bootstrap_index = sample(1:n,n,replace = TRUE)
x_bagging = x[bootstrap_index,]
y_bagging = y[bootstrap_index]
tree = buildTREE(x_bagging,y_bagging,split,rf)
TREES = c(TREES,list(tree))
}
return(TREES)
}
这个函数能够得到一片树林。做法非常简单,从原本的数据中随机抽样出新数据,生成新的一棵树就行了,默认是生成150棵树。bagging和随机森林都是使用这个函数,通过参数rf就能够在两种方法之间进行切换了,之前的splitting函数里也相应地设置了参数rf,其中k是原始数据的自变量个数,bagging遍历全部k个自变量,而随机森林只随机挑选其中sqrt(k)个。
if (!rf) chosen_variable = 1:k
if (rf == TRUE) chosen_variable = sample(1:k,round(sqrt(k)))
上面提到的split_random函数,实际上是受到了随机森林算法的启发。既然你能随机地选取划分变量,那么我为什么不能够随机地选取划分条件呢?同样是为了降低树与树之间的相似性,我这样做应该也是合理的。只要保证总体上不纯度是在下降就行,不必要追求每一次划分都能带来大幅度的下降。
predict_ensemble()
predict_ensemble = function(newx,TREES) { #此处newx为自变量矩阵,TREES为bagging树林或是随机森林
subpredict_ensemble = function(subx,TREES){ #给定一行观测的自变量和一片树林,我预测它的因变量
subpredict = function(TREE,subx) { #给定一行观测的自变量和一棵树的结构,我预测它的因变量
row = 1 #从第一个节点开始出发
while(TRUE) {
if (TREE$leaf[row]==TRUE) {
predicted = TREE$pred[row]
break
}
#给定一个观测值,判断它是往左走还是往右走,一直走下去,直到抵达叶节点leaf为止
if (subx[TREE$splitvariable[row]] <= TREE$splitpoint[row]) {row = TREE$leftnode[row]}
else {row = TREE$rightnode[row]}
}
return(predicted)
}
sub_predicted = unlist(lapply(TREES,subpredict,subx)) #对每一行数据进行预测
return( names(summary(sub_predicted))[which.max(summary(sub_predicted))] ) #每棵树进行投票,确定最终预测值
}
apply(newx,1,subpredict_ensemble,TREES)
}
这个函数和之前的单棵树的predict函数基本上一样的,无非是给定数据判断它向左走还是向右走的问题罢了。唯一的区别是加了个多数投票的函数,对应的是上面举的例子,100棵树里,80棵树选了C选项,所以最后我选C。
性能测试
现在试着用mlbench包里LetterRecognition数据集来做一下预测性能测试,数据的预处理过程就不写了,一个简单的分层抽样。
### 单棵分类树
> tree = buildTREE(train_x,train_y)
> predicted1 = predict(tree,test_x)
> result1 = mean(predicted1!=test_y)
### Bagging
> system.time(baggingtrees1 <- bagging(train_x,train_y,split = "best",rf = FALSE))
user system elapsed
349.58 0.38 354.38
> system.time(predicted2 <- predict_ensemble(test_x,baggingtrees1))
user system elapsed
7.72 0.00 7.80
> result2 = mean(predicted2!=test_y)
> system.time(baggingtrees2 <- bagging(train_x,train_y,split = "random",rf = FALSE))
user system elapsed
126.17 0.25 129.95
> system.time(predicted3 <- predict_ensemble(test_x,baggingtrees2))
user system elapsed
7.15 0.00 7.18
> result3 = mean(predicted3!=test_y)
### 随机森林
> system.time(randomforest1 <- bagging(train_x,train_y,split = "best",rf = TRUE))
user system elapsed
155.83 0.06 157.02
> system.time(predicted4 <- predict_ensemble(test_x,randomforest1))
user system elapsed
7.84 0.00 7.99
> result4 = mean(predicted4!=test_y)
> system.time(randomforest2 <- bagging(train_x,train_y,split = "random",rf = TRUE))
user system elapsed
108.47 0.01 109.62
> system.time(predicted5 <- predict_ensemble(test_x,randomforest2))
user system elapsed
7.64 0.02 7.66
> result5 = mean(predicted5!=test_y)
##
### 结果展示
> result1
[1] 0.38
> result2
[1] 0.215
> result3
[1] 0.235
> result4
[1] 0.23
> result5
[1] 0.215
###
从错误率来看,单棵分类树是最差的,bagging和随机森林差不多,可能是数据量小没有体现出随机森林的优势。使用random的划分和使用best的划分在精度上差别不大,但是运算时间明显减少了,这可以看做是算法改进成功了。
再用R里的randomforest包来试试,发现和我写的函数性能差别并不大(也许是因为数据量太小了)。
###
library(randomForest)
bag = randomForest(x = train_x,y = train_y,ntree = 150, mtry = k)
predicted6 = predict(bag,newdata = test_x,type = "response")
result6 = mean(predicted6!=test_y)
rf = randomForest(x = train_x,y = train_y,ntree = 150, mtry = sqrt(k))
predicted7 = predict(rf,newdata = test_x,type = "response")
result7 = mean(predicted7!=test_y)
> result6
[1] 0.23
> result7
[1] 0.21
写在后面
这份代码是我入门机器学习以来写得比较完整的代码,源代码来自于马老师的数据挖掘课,我是全部读懂了之后凭着理解再自己写出来的。相当吃力,前前后后大概花了20多个小时,把各个变量整合起来尤其困难,系统报错太多的时候心态都有些崩。虽然过程有些辛苦,但总归是写了出来,算是对自己的一次锻炼,写了这篇文章记录一下。