写在前面
使用云服务一般都可以用商家的监控来监控自己的云服务器,但是自建机房或者想要自己监控服务器性能指标的话,就要借助第三方工具了,这里记录下自己写脚本监控服务器几个性能指标的过程,抛砖引玉。
- 使用工具:prometheus + grafana,快速安装参考我的上一篇文档:https://www.jianshu.com/p/ad3cb95f0720
- 报警途径:钉钉机器人
- 监控参数:服务器内存使用率、磁盘使用率、cpu使用率、cpu负载
监控脚本
获取服务器性能指标参数
mkdir /monitor/linux_monitor/ && cd /monitor/linux_monitor/
vim linux_monitor.sh
#!/bin/sh
get_ip() {
ifconfig eth0|grep "inet addr" > /dev/null 2>&1
if [ $? -eq 0 ];then
inter_ip=`ifconfig eth0|grep "inet "|awk -F ' ' '{print $2}'|awk -F ':' '{print $2}'`
#public_ip=`ifconfig eth1|grep "inet "|awk -F ' ' '{print $2}'|awk -F ':' '{print $2}'`
else
inter_ip=`ifconfig eth0|grep "inet "|awk -F ' ' '{print $2}'`
#public_ip=`ifconfig eth1|grep "inet "|awk -F ' ' '{print $2}'`
fi
}
get_cpu() {
CPU_1=$(cat /proc/stat | grep 'cpu ' | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}')
SYS_IDLE_1=$(echo $CPU_1 | awk '{print $4}')
Total01=$(echo $CPU_1 | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}')
sleep 2
CPU_2=$(cat /proc/stat | grep 'cpu ' | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}')
SYS_IDLE_2=$(echo $CPU_2 | awk '{print $4}')
Total_2=$(echo $CPU_2 | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}')
SYS_IDLE=`expr $SYS_IDLE_2 - $SYS_IDLE_1`
Total=`expr $Total_2 - $Total01`
TT=`expr $SYS_IDLE \* 100`
SYS_USAGE=`expr $TT / $Total`
SYS_Rate=`expr 100 - $SYS_USAGE`
#cpu_fz=`uptime |awk -F ' ' '{print $10}'|awk -F ',' '{print $1}'`
cpu_fz=`uptime |awk -F ' ' '{print $NF}'`
}
get_mem() {
mem_total=`free -m|grep "Mem"|awk -F ' ' '{print $2}'`
#mem_used=`free -m|grep Mem|awk -F ' ' '{print $3}'`
# free -m|grep "\-\/\+"
if [ $? -eq 0 ];then
mem_used=`free -m|sed -n 3p|awk -F ' ' '{print $3}'`
else
mem_used=`free -m|grep Mem|awk -F ' ' '{print $3}'`
fi
mem_rate=`echo "$mem_used $mem_total" | awk '{printf("%0.1f\n",$1/$2*100)}'`
}
get_tcp() {
tcp_established=`netstat -antp|grep ESTABLISHED|wc -l`
}
get_root_used() {
root_used=`df|grep /$|awk -F ' ' '{print $(NF-1)}'`
}
get_opt_used() {
opt_used=`df|grep /opt$|awk -F ' ' '{print $(NF-1)}'`
}
get_data_used() {
data_used=`df|grep /data$|awk -F ' ' '{print $(NF-1)}'`
}
get_data1_used() {
data1_used=`df|grep /data1$|awk -F ' ' '{print $(NF-1)}'`
}
get_data2_used() {
data2_used=`df|grep /data2$|awk -F ' ' '{print $(NF-1)}'`
}
get_ip
get_cpu
get_mem
get_tcp
get_root_used
get_opt_used
get_data_used
get_data1_used
get_data2_used
echo inter_ip:$inter_ip
#echo public_ip:$public_ip
echo cpu_rate:$SYS_Rate
echo cpu_load:$cpu_fz
echo mem_total:$mem_total
echo mem_rate:$mem_rate
echo tcp_established:$tcp_established
echo root_used:$root_used
[ -n "$opt_used" ] && echo /opt:$opt_used
[ -n "$data_used" ] && echo /data:$data_used
[ -n "$data1_used" ] && echo /data1:$data1_used
[ -n "$data2_used" ] && echo /data2:$data2_used
脚本直接运行:
sh linux_monitor.sh
得到以下参数
inter_ip:172.44.33.193
cpu_rate:1
cpu_load:0.00
mem_total:8005
mem_rate:8.0
tcp_established:25
root_used:5%
接下来通过py脚本起一个exporter,让prometheus能pull这些参数
vim linux_monitor.py
#coding:utf-8
#!/bin/python
#author: OrangeLoveMilan
import os
import requests
import json
import prometheus_client
from prometheus_client.core import CollectorRegistry
from prometheus_client import Gauge
from flask import Response,Flask
d = {}
app = Flask(__name__)
REGISTRY = CollectorRegistry(auto_describe=False)
##----------------------------这里不同服务器上要把参数名改成不一样的,比如ECS1的参数名可以定义为xxx_ECS1-------------
tcp = Gauge("tcp_ECS1","value is:",registry=REGISTRY)
cpuRate = Gauge("cpuRate_ECS1","value is:",registry=REGISTRY)
cpuLoad = Gauge("cpuLoad_ECS1","value is:",registry=REGISTRY)
memTotal = Gauge("memTotal_ECS1","value is:",registry=REGISTRY)
memRate = Gauge("memRate_ECS1","value is:",registry=REGISTRY)
rootUsed = Gauge("rootUsed_ECS1","value is:",registry=REGISTRY)
#optUsed = Gauge("optUsed_ECS1","value is:",registry=REGISTRY)
##------------------------------萌萌哒分割线ε=(´ο`*)))----------------------------------------------------------
@app.route("/metrics")
def metrice():
##-----------------------------要注意刚才的shell脚本的存放位置-------------------------------------------
values=os.popen('sh /monitor/linux_monitor/linux_monitor.sh')
for i in values.readlines():
if i.startswith('inter_ip'):
d['inter_ip']=i.split(':')[1].strip()
elif i.startswith('cpu_rate'):
d['cpu_rate']=i.split(':')[1].strip()
elif i.startswith('cpu_load'):
d['cpu_load']=i.split(':')[1].strip()
elif i.startswith('mem_total'):
d['mem_total']=i.split(':')[1].strip()
elif i.startswith('mem_rate'):
d['mem_rate']=i.split(':')[1].strip()
elif i.startswith('tcp_established'):
d['tcp_established']=i.split(':')[1].strip()
elif i.startswith('root_used'):
d['root_used']=i.split(':')[1].strip().replace('%','')
# elif i.startswith('/opt'):
# d['/opt']=i.split(':')[1].strip().replace('%','')
else:
pass
cpuRate.set(d['cpu_rate'])
cpuLoad.set(d['cpu_load'])
memTotal.set(d['mem_total'])
memRate.set(d['mem_rate'])
rootUsed.set(d['root_used'])
# optUsed.set(d['/opt'])
tcp.set(d['tcp_established'])
return Response(prometheus_client.generate_latest(REGISTRY),mimetype="text/plain")
if __name__ == "__main__":
##------------------------------------监听的host、port可以自己定义------------------------------------
app.run(host='0.0.0.0',port=3533)
这个python脚本可以直接拿来用,注意脚本中的提示,对应的参数改改就行
安装依赖库:
pip install —upgrade pip && pip install requests && pip install flask && pip install prometheus_client
启动监控脚本,可以加入开机自启动
nohup python /monitor/linux_monitor/linux_monitor.py > /var/log/linuxHeath.log 2>&1 &
开机自启动加到/erc/rc.local里面
查看数据:localhost改成脚本所在服务器的ip
curl localhost:3533/metrics
展示到grafana上
在prometheus的配置文件prometheus.yml添加,记得ip要自己改
#-------------------------------- linux ECS heath -----------------------------------
scrape_configs:
- job_name: 'linxu_heath_monitor'
static_configs:
- targets: ['172.33.44.198:3533','172.33.44.199:3533','172.33.44.194:3533']
重启prometheus,我是用docker启动的,直接docker restart prometheus就可以了
打开grafana的dashboard,开始添加监控项目吧,敏感打马
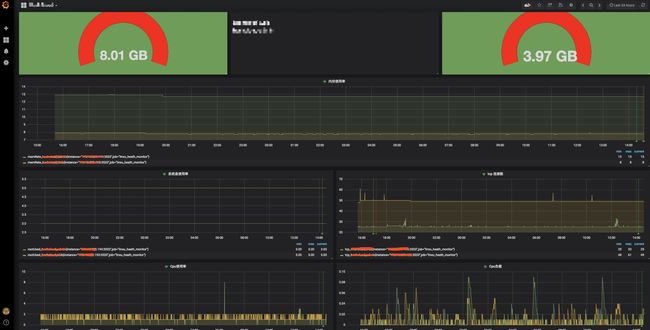
设置报警
每个参数设置相应的告警值,其中cpu负载我设置的是核数乘以0.7,超过这个值就告警

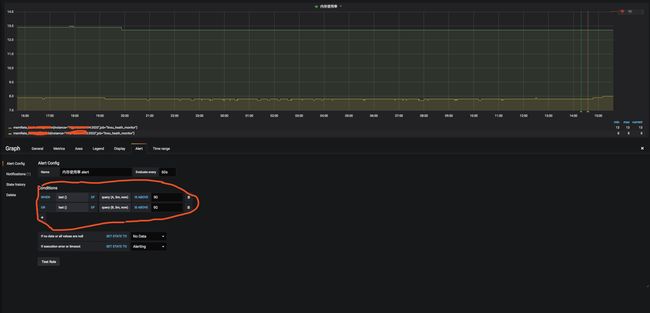
画圆圈的地方参数自行修改
设置告警内容:
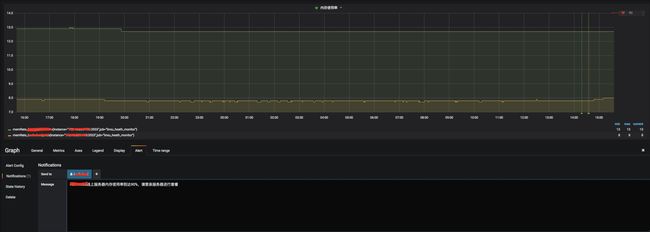
配置钉钉告警:
填写告警机器人的webhook的url

达到告警条件了就会触发告警:

QA
Q:告警机器人的告警的url连接打不开
A:
docker exec -it grafana bash
进入grafana的容器
编辑配置文件vim /etc/grafana/grafana.ini
root_url = http://ip:3000/
把ip改成grafana所在服务器的ip
重启grafana服务
docker restart grafana
这时候,告警机器人的消息中的连接就可以打开了
终于成功了
