摘要: 送你18个训练Tensorflow.js模型的小技巧!

在移植现有模型(除tensorflow.js)进行物体检测、人脸检测、人脸识别后,我发现一些模型不能以最佳性能发挥。而tensorflow.js在浏览器中表现相当不错,如果你想见证浏览器内部机器学习的潜力以及tensorflow.js为我们的Web开发人员提供的所有可能性,我个人建议你可以尝试下。
但是,由于深度学习模型无法直接在浏览器中运行,因为这些模型不是专为在浏览器中运行而设计的,更不用说在移动端了。以现有技的物体探测器为例:它们通常需要大量的计算资源才能以合理的fps运行,更不用说以实时速度运行了。此外,在简单的Web应用程序中将100MB+模型权重加载到客户端浏览器是根本不可行的。
为Web训练高效的深度学习模型
但让我告诉你,我们能够构建和训练相当不错的模型,这些模型通过设计一些基本原则可以在Web环境中运行进行。信不信由你:我们可以训练相当不错的图像分类-甚至物体检测模型,最终只有几兆字节大小甚至只有几千字节:

在本文中,我想给你一些关于开始训练你自己的卷积神经网络(CNN)的一般技巧,还有一些技巧是直接针对在浏览器中使用张量流训练CNN网络。

现在你可能想知道:为什么我可以在浏览器中使用tensorflow.js训练我的模型,在我的机器上如何使用tensorflow训练它们?当然,如果你的机器配备了NVIDIA卡,你也可以这样做。在浏览器中训练深度学习的一个巨大的优势,它的引擎盖下利用WebGL的,这就意味着你不需要NVIDIA GPU训练的模式,而是AMD GPU上训练深度学习模型。
因此,如果你的机器配备了NVIDIA卡,你可以简单地采用标准张量流方法(在这种情况下,你可以在python中编写训练代码)并忽略浏览器的提示。现在,让我们开始吧!
网络架构
在开始训练我们自己的图像分类器、对象检测器之前,我们必须首先实现网络架构。我通常建议选择现有的架构,例如Yolo、SSD、ResNet、MobileNet等。
就个人而言,我认为在你自己的架构中使用这些架构所采用的一些概念是很有价值的。然而,正如我最初指出的那样,简单地采用这些架构不会让我们的模型是体积小,推理快和易于训练成为可能。
无论你是想要适应现有架构还是从头开始,我都想给你以下建议,这有助于为Web设计高效的CNN架构:
1.从小型网络架构开始!
记住,我们的网络越小,同时仍能在解决问题时获得良好的准确性,它在推理时间内执行的速度就越快,客户端下载和缓存该模型就越容易。此外,较小的模型具有较少的参数,因此在训练时会更快地收敛。
如果你发现当前的网络架构性能不佳,或者达不到准确性水平,你仍然希望是它,你可以逐步增加网络的大小,例如通过增加每层卷积滤波器的数量或堆叠更多层简单地使你的网络更深入。
2.采用深度可分的卷积!
由于我们正在训练一个新模型,我们希望明确使用深度可分卷积而不是普通2D卷积。深度可分离卷积将常规卷积运算分成深度卷积,然后是逐点(1x1)卷积。与常规卷积操作相比,它们具有更少的参数,这将使用更少的浮点运算并且更容易并行化,这意味着推断将更快(我通过简单地替换常规卷积来进行推断的速度提升高达10倍)和较少的资源消耗。此外,因为它们具有较少的参数,所以训练它们所花费的时间较少。

在MobileNet和Xception中采用了深度可分离卷积的思想,你可以在MobileNet和PoseNet的tensorflow.js模型中找到它们。深度可分离卷积是否导致模型不太准确可能是一个公开的辩论,但根据我的经验,它们绝对是网络模型的方式。
长话短说:我建议在你的第一层使用常规的没有那么多的参数的conv2d操作,以保留提取的特征中的RGB通道之间的关系。
export type ConvParams = {
filter: tf.Tensor4D
bias: tf.Tensor1D
}
export function convLayer(
x: tf.Tensor4D,
params: ConvParams,
stride: [number, number],
padding: string
): tf.Tensor4D {
return tf.tidy(() => {
let out = tf.conv2d(x, params.filter, stride, padding)
out = tf.add(out, params.bias)
return out
})
}
对于其余的卷积,只需使用深度可分离的卷积。因此,我们将使用3x3xchannels_inx1深度滤波器和1x1x channels_in x channels_out逐点滤波器,而不是单个内核。
export type SeparableConvParams = {
depthwise_filter: tf.Tensor4D
pointwise_filter: tf.Tensor4D
bias: tf.Tensor1D
}
export function depthwiseSeparableConv(
x: tf.Tensor4D,
params: SeparableConvParams,
stride: [number, number],
padding: string
): tf.Tensor4D {
return tf.tidy(() => {
let out = tf.separableConv2d(x, params.depthwise_filter: tf.Tensor4D, params.pointwise_filter, stride, padding)
out = tf.add(out, params.bias)
return out
})
}
并且,不是使用tf.conv2d与具有形状的内核[3,3,32,64],我们将简单地使用tf.separableConv2d及深度方向内核的形状为[3,3,32,1]以及形状为[1,1,32,64]状作为点状核。
3.跳过连接(Skip connections)和密集连接(Densely Connected)的块
一旦决定建立更深层的网络,很快就面临着训练神经网络最常见的问题之一:梯度消失问题。在一些时期之后,损失只会在非常微小的步骤中减少,这会增加训练时间或者导致模型不收敛。
ResNet和DenseNet中使用的跳过连接允许它们构建更深层的体系结构,同时减轻梯度消失问题。我们所要做的就是在应用激活函数之前,将先前层的输出添加到位于网络中更深层的层输入中:

跳过连接工作,通过快捷方式连接图层。这种技术背后的本质是,梯度不必仅通过卷积(或完全连接)反向传播,这导致梯度一旦到达网络的早期层就会减少。它们可以通过跳过连接的添加操作来“skip”层。
显然,假设你想要将A层与B层连接,A的输出形状必须与B的输入形状相匹配。如果你想构建残差或密集连接的块,只需确保在该块的卷积中保持相同数量的滤波器,并使用相同的填充保持1的步幅。正如旁注一样,也有不同的方法,它们填充A的输出,使其与输入B的形状匹配,或者连接来自先前层的特征映射,使得连接层的深度再次匹配。
起初,我尝试使用类似ResNet的方法,只需在其他层之间引入跳过连接,如上图所示,但很快就发现,密集连接的块工作得更好,并且可以很快的收敛:

这是一个密集块实现的例子,我用它作为面部标志检测器的基本构建块face-api.js。其中一个块涉及4个可深度分离的卷积层(注意,第一个密集块的第一个卷积是常规卷积),每个块的第一个卷积运算使用2的步幅来缩小输入:
export type DenseBlock4Params = {
conv0: SeparableConvParams | ConvParams
conv1: SeparableConvParams
conv2: SeparableConvParams
conv3: SeparableConvParams
}
export function denseBlock4(
x: tf.Tensor4D,
denseBlockParams: DenseBlock4Params,
isFirstLayer: boolean = false
): tf.Tensor4D {
return tf.tidy(() => {
const out0 = isFirstLayer
? convLayer(x, denseBlockParams.conv0 as ConvParams, [2, 2], 'same')
: depthwiseSeparableConv(x, denseBlockParams.conv0 as SeparableConvParams, [2, 2], 'same')
as tf.Tensor4D
const in1 = tf.relu(out0) as tf.Tensor4D
const out1 = depthwiseSeparableConv(in1, denseBlockParams.conv1, [1, 1], 'same')
// first join
const in2 = tf.relu(tf.add(out0, out1)) as tf.Tensor4D
const out2 = depthwiseSeparableConv(in2, denseBlockParams.conv2, [1, 1], 'same')
// second join
const in3 = tf.relu(tf.add(out0, tf.add(out1, out2))) as tf.Tensor4D
const out3 = depthwiseSeparableConv(in3, denseBlockParams.conv3, [1, 1], 'same')
// final join
return tf.relu(tf.add(out0, tf.add(out1, tf.add(out2, out3)))) as tf.Tensor4D
})
}
4.使用ReLU类型激活函数!
除非你有特定的理由使用其他类型的激活函数,否则就使用tf.relu。原因很简单,ReLU类型激活函数有助于缓解梯度消失的问题。
你还可以尝试ReLU的变体,例如leaky ReLU,它正在Yolo架构中使用:
export function leakyRelu(x: tf.Tensor, epsilon: number) {
return tf.tidy(() => {
const min = tf.mul(x, tf.scalar(epsilon))
return tf.maximum(x, min)
})
}
或者正在移动网络使用的ReLU-6:
export function relu6(x: tf.Tensor) {
return tf.clipByValue(x, 0, 6)
}
训练
一旦我们完成初始架构,我们就可以开始训练我们的模型了。
5.如果有疑问,只需使用Adam Optimizer!
当第一次开始训练自己的模型时,我想知道哪种优化器最好?我一开始使用普通的SGD,它似乎有时会陷入局部最小值中,甚至导致梯度爆炸,以至于模型权重无限增长,最终导致NaNs。
我并不是说,Adam是所有问题的最佳选择,但我发现它是训练新模型最简单且最强大的方法,只需使用默认参数和学习率为0.001的Adam开始:
const optimizer = tf.train.adam(0.001)
6.调整学习率
一旦损失没有显着下降,很可能,我们的模型确实收敛,并且无法进一步学习。此时我们不妨停止训练过程,以防止我们的模型不会出现过度拟合。
但是,你可以通过调整(降低)学习率来避免它发生。特别是如果在训练集上计算的总损失开始振荡,这表明尝试降低学习率可能是个好主意。
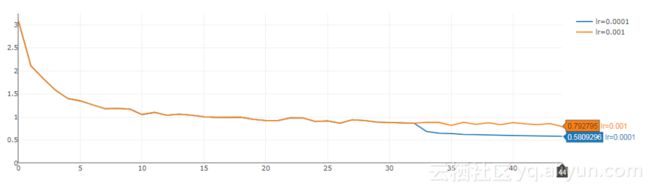
下面是一个示例,显示了训练面部标志模型时整体误差的图表。在46epoch,损失值开始振荡。正如你所看到的那样,继续训练从46epoch的检查点再学习10个以上,学习率为0.0001而不是0.001,这能够进一步降低整体误差:
7.权重初始化
如果你对如何正确初始化模型权重没有任何线索:一个简单的经验法则,从某种正态分布中得出,用零初始化所有偏差(tf.zeros(shape))和你的权重(卷积的核和全连接层的权重)与非零值。例如,你可以简单地使用tf.randomNormal(shape),但是现在我更喜欢使用glorot正态分布,这在tfjs-layers中是可用的,如下所示:
const initializer = tf.initializers.glorotNormal()
const depthwise_filter = initializer.apply([3, 3, 32, 1])
const pointwise_filter = initializer.apply([1, 1, 32, 64])
const bias = tf.zeros([64])
本文作者:【方向】
阅读原文
本文为云栖社区原创内容,未经允许不得转载。