姓名:崔少杰 学号:16040510021
转载自:http://www.jianshu.com/p/d1b7ca81d1af=有修改
【嵌牛导读】:广义线性模型、指数分布族中的高斯分布、伯努利分布
【嵌牛鼻子】:广义线性模型、指数分布族、高斯分布、伯努利分布
【嵌牛提问】:为什么要有指数分布族?
【嵌牛正文】:定义指数分布族:(指数分布族的定义符号有很多版本,这里采用的是CS229 描述的写法,注意PRML的写法稍有不同,CS229是斯坦福大学Andrew NG的机器学习课程,PRML是模式识别机器学习的经典书籍)
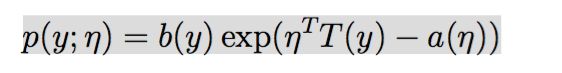
指数分布族形式
η 是 自然参数(natural parameter,also called thecanonical parameter)。
T(y) 是充分统计量 (sufficient statistic) ,一般情况下就是y。
a(η) 是 对数部分函数(log partition function),这部分确保Y的分布p(y:η) 计算的结果加起来(连续函数是积分)等于1.
伯努利分布作为指数分布族的例子(比如在某段时间内,广告被点击的分布;某段时间内,顾客是否进店等等):
设 均值(mean)为 φ,分布 在Y上的取值为{0,1},因此
p(y= 1;φ) =φ;
p(y= 0;φ) = 1−φ
即,调整φ,得到不同的伯努利分布,一旦设定好φ,T,a,b都被固定住,就能得到一个伯努利分布。
如
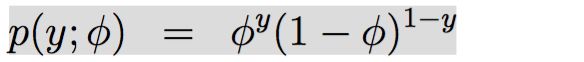
伯努利分布
把上式的右边改写成指数分布族形式
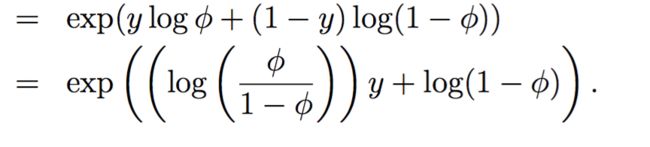
指数分布族形式
可以看出,
b(y) = 1
T(y) = y
a(η) = -log(1−φ)
η = log (φ/(1-φ))
因此 φ=

这个就是sigmoid函数了,也是logistic 函数,Great.
高斯分布作为指数分布族的例子(线性回归 linear regression):
假设 σ^2 = 1
(注:If we leaveσ2as a variable, the Gaussian distribution can also be shown to be in the)
exponential family, whereη∈R2is now a 2-dimension vector that depends on bothμandσ. For the purposes of GLMs, however, theσ2parameter can also be treated by considering
a more general definition of the exponential family:p(y;η, τ) =b(a, τ) exp((ηTT(y)−a(η))/c(τ)). Here,τis called thedispersion parameter, and for the Gaussian,c(τ) =σ2;
but given our simplification above, we won’t need the more general definition for the
examples we will consider here.) From CS229 lecture notes。
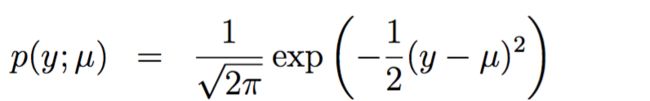
高斯分布
指数分布族的形式为

指数分布族形式
可以看出,

当然指数分布族中的成员很多,泊松分布,gamma分布,beta分布等等,碰到需要解决一个具体问题的时候(比如要去判断多少人在一个时间段内访问某个店,也是某一家店需要扩张选店的其中一个依据),泊松分布是一个很好的模型,泊松分布恰巧也是属于指数分布族。
下面描述一个方法:如何构造一个广义线性模型(GLMS)来解决上述问题(如某个时间段内,多少人进店)
具体来说,思考一个分类(classification)问题或者回归(regression)问题,我们需要预测随机变量Y是X的函数(比如多少人进店的问题,X是某个店的奖励政策、近期广告等等一些特征)
要建立一个GLM处理这个问题,首先做三个假设:
1:给定X、θ,Y的分布服从某个指数族分布(nature parameter = η).
2:给定X,目标是预测E[Y|x](大部分情况下,T(Y) = Y,),即,假设函数(hypothesis)h(x) = E[Y|x].

比如线性回归的hypothesis:
比如logistic regression的hypothesis:
hθ(x) =p(y= 1|x;θ) = 0·p(y=0|x;θ)+1·p(y= 1|x;θ) = E[y|x;θ]
3:η和X线性(叫“指定选择” design choice 可能更合适):

应用三个假设举例如下:
比如 最小二乘(ordinary least square regression),是指数分布族模型的一种special case。
ordinary least square regression ,Andrew 在9.1写的是Ordinary least square ,我自己理解为这里讲的是ordinary least square regression,)
Andrew 使用的术语是canonical link function:g(μ) =η,用来描述均值(mean)依赖线性预测器(linear predictor ),E(Y) =μ,g(μ) =η.
canonical response function 是canonical link function的反函数。
根据假设2,可以得出
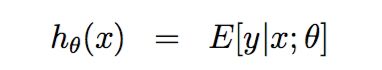
假设2
根据假设1,假设服从高斯分布,可以得出

假设1
高斯分布 η = μ(参考前述高斯分布) ,
根据假设3:

假设3
比如 logistic regression 同理:

等式2为伯努利分布的均值
假设2可得到等式1
假设1可得到等式3
假设3可得到等式4