数据集的划分
神经网络的建立过程是一个需要多次重复的实验过程:从最开始的想法产生,到通过编写代码来算法实现,再到建立数据集来训练调参,都需要经历多次的迭代才能完成。
为了更快的完成这个迭代过程,数据集的准备工作非常重要。一般在训练过程中会将已有的数据集分为训练数据集 training set, 调整数据集 cross-validation / development set 和测试数据集 test set 三部分。训练数据集的作用是通过提供足够多的数据对网络进行训练,使得网络获得基本的架构和参数;而调整数据集的主要作用则是通过交叉验证模型是否对于训练数据做了过拟合,以及在采用多个不同的架构和算法构建模型时辅助选择一个错误率较低的模型,需要注意的是不能用验证数据集中的数据来对参数进行修改;测试数据集则是确切给出选定算法的准确率及置信水平。调整数据集也可以翻译成验证数据集、开发数据集,我个人更倾向于调整数据集,因此后续也会使用这个名字。

对于数据集的准备和划分,Andrew 给了大家三条建议:
训练数据集的比重应随总体样本集数量的增加而增加:在以前的经验中,一般会把数据集大致按照 70% VS 30% 的比例进行划分,用其中的 70% 作为训练数据集,剩余 30% 作为调整和测试数据集。但到了大数据时代,由于可获得的数据的数量较以往呈指数级的上升,因此测试数据集中的样本虽然在绝对数量上不一定减少,但其在总体样本集中所占的比例会大幅度下降,各个样本集的比例一般会变化为 98% VS 1% VS 1% 甚至是 99.5% VS 0.4% VS 0.1%,这样做的目的是使的网络在训练的过程中尽可能多的接触到更多的数据,使得训练的效果更好
应尽量确保调整数据集和测试数据集的样本具有相同的分布情况:理想情况下各个数据集的来源应该相同,但在实际的应用中,训练数据集、调整数据集、测试数据集可能有不同的来源。为了保证调整的质量,应确保后两者具有相同的分布情况,否则就会出现模型调整完毕后在真实的应用环境下出现出现较高的错误率
在某些情况下没有测试集,只有调整集也是被允许的
Bias VS Variance 偏差 VS 方差
偏差和方差在 Andrew 老师看来是容易学习,但很难真正掌握的两个概念。实际上一开始我在视频里并没有听的很懂,于是在 Quora 里找到了这样一张图:
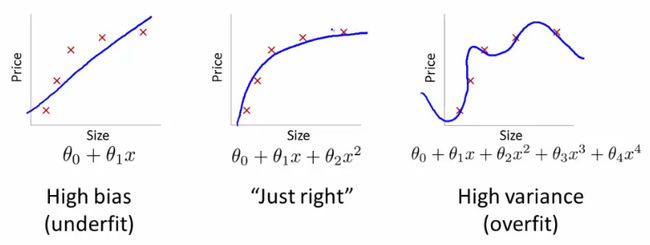
Andrew 在这里没有讲的另外一个比较常见的概念是误差 error,也即系统出错的概率,偏差、方差和数据中的错误都对系统的误差有贡献。可以将高偏差 High Bias 理解为对于关系的过度简化而导致的欠拟合,表现为系统在训练数据集和验证数据集中都具有较高的误差,也就是说神经网络构造出来的预测模型与真实世界相差较大;而高方差 High Variance 则可以理解为网络针对训练数据集做了过度复杂化的关系构造而导致的过拟合,使得系统而在不同的数据集上的准确率离散程度很大,也被称为无法泛化 generalize 到其他的数据。
下面这张图也是讨论这两个概念常用的,图中红色区域代表真实标签值,而蓝色代表预测数据值。由于方差衡量的是数据的离散程度,因而高方差的数据更加离散,而偏差则可以理解为预测值与真实值的偏离程度,因此对应高偏差时,数据更多的被错误的分类。如果需要更详细的解释也可以参考 Ved 的回答。
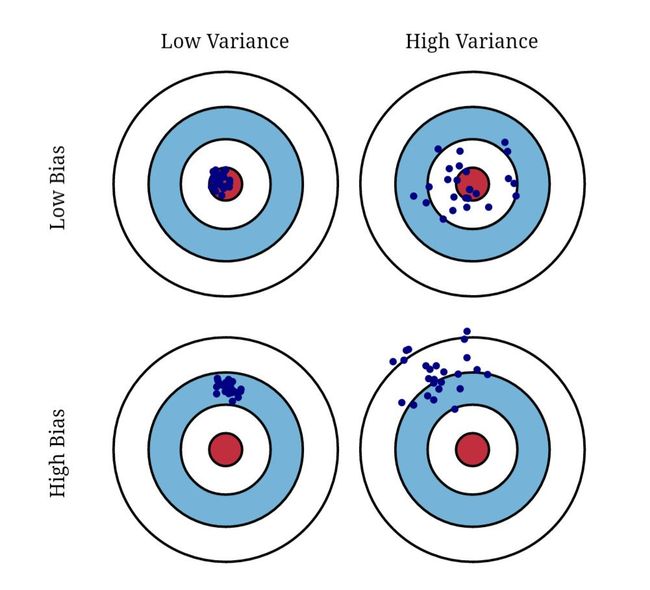
需要注意的一点是在实际应用中,Bias 和 Variance 值的大小是一个相对值,取决于最优误差 Bayesian optimal error 的大小,这个最优误差值常用已知的表现最佳的分类器的误差值,在感知型任务中通常选择人类的误差值来代替。
另外需要注意的就是 Andrew 指出在当前的大数据时代,有一个趋势是很少再去提及“误差和方差的权衡 bias-variance tradeoff”,在深度学习之前的算法中,由于算法的能力以及数据量的限制,基本上改善偏差和方差中的一方就要损及另一方,因此经常要考虑偏差和方差的权衡。但在深度学习和大数据时代,通过持续的训练一个更大的网络和纳入更多的数据很可能同时做到二者兼得,这也是深度学习在监督学习中获得如此多关注的一个重要原因。
以下摘自 Building powerful image classification models using very little data:
Overfitting happens when a model exposed to too few examples learns patterns that do not generalize to new data.
Data augmentation is one way to fight overfitting, but it isn't enough since our augmented samples are still highly correlated. Your main focus for fighting overfitting should be the entropic capacity of your model --how much information your model is allowed to store. A model that can store a lot of information has the potential to be more accurate by leveraging more features, but it is also more at risk to start storing irrelevant features. Meanwhile, a model that can only store a few features will have to focus on the most significant features found in the data, and these are more likely to be truly relevant and to generalize better.
There are different ways to modulate entropic capacity. The main one is the choice of the number of parameters in your model, i.e. the number of layers and the size of each layer. Another way is the use of weight regularization, such as L1 or L2 regularization, which consists in forcing model weights to taker smaller values.
Dropout also helps reduce overfitting, by preventing a layer from seeing twice the exact same pattern, thus acting in a way analoguous to data augmentation (you could say that both dropout and data augmentation tend to disrupt random correlations occuring in your data).
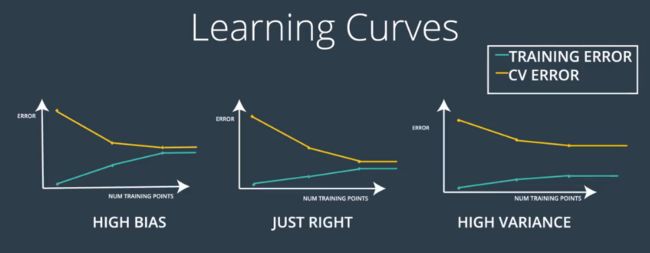
在实际使用中,可以通过绘制不同模型采用不同数量的样本进行训练时得到的训练误差和验证误差的变动情况来绘制学习曲线来了解模型的工作状态:
from sklearn.model_selection import learning_curve
train_sizes, train_scores, test_scores = learning_curve(
estimator, X2, y2, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, num_trainings))
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.title("Learning Curves")
plt.xlabel("Training examples")
plt.ylabel("Score")
plt.plot(train_scores_mean, 'o-', color="g",
label="Training score")
plt.plot(test_scores_mean, 'o-', color="y",
label="Cross-validation score")
plt.legend(loc="best")
plt.show()
机器学习应用的基本功
在这一系列的课程里,Andrew 对于机器学习和深度学习并没有做严格的区分,因此很多时候在课堂里用的都是 Machine Learning 这个词。机器学习可以理解为通过算法设计使得计算机可以表现出一定的认知能力, 从而完成诸如预测,分类,识别等任务的一门学科,而深度学习则是利用深度神经网络进行机器学习的一个重要的方法。
为了更加有效的通过深度神经网络进行机器学习,Andrew 建议大家在网络的构建过程中系统性的遵循下面这些步骤:
在初始模型训练完成后,先确认模型的偏差情况如何,即是否对于训练集有较好的预测能力。如果发现模型偏差值较高,则可以尝试使用更大的神经网络,例如增加层数及单元的数量、或者增加训练的时间、采用更高级的算法或采用不同架构的神经网络
当偏差水平达到满意的程度以后,就要考虑模型的方差值是否合理,即通过调整数据集来交叉验证模型预测能力的稳定性。解决高方差的一个重要方法就是在训练数据集中增加更多的数据,但如果无法获取更多的数据,则要通过对数据正则化 Regularization 来降低方差值。在这一步有时候更换神经网络的架构也是有效的,并且还有可能一箭双雕的同时解决偏差和方差问题。
神经网络的正则化
当怀疑神经网络出现过拟合(高方差)时,首先先要想到的就是实施正则化,其次才是获取更多的训练数据。
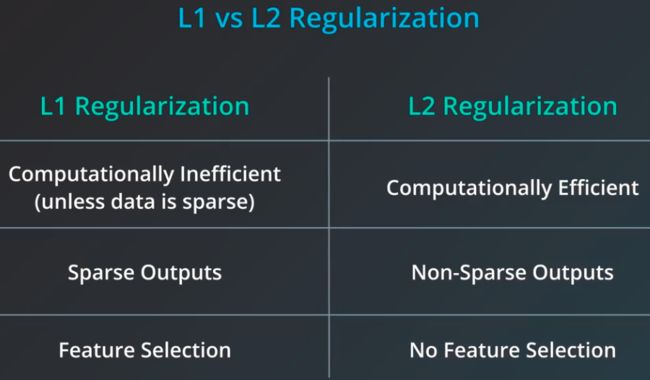
正则化的具体操作就是在成本函数的计算公式中添加包含正则化参数 λ 的项,根据这一正则化项的不同,可以将其分为以下 2 种:
L1 正则化是在原有成本函数 J(w, b) 的基础上加上 λ ||w||1 / m,其中 ||w||1 为 w 中各个参数的绝对值之和
L2 正则化是在原有成本函数 J(w, b) 的基础上加上 λ ||w||22 / 2m,其中 ||w||22 = wTw 是 w 中各个参数的平方和

正则化的原理就是我们在成本函数定义时,不仅考虑模型的准确性,还将复杂度纳入其中。由于复杂的模型需要更多的参数,而更多的参数意味着系统的容错能力更差,也即泛化能力更低,进而可以将模型中用到的参数的绝对值之和或者平方和加入到成本函数的计算中,对于复杂的模型给予更多的惩罚。进一步地,还可以根据模型对于复杂度的要求通过调整正则化参数 λ 来控制复杂度对于误差的影响。λ 越大,则对于复杂度的惩罚越高,也即最终的模型越简化。
L1 正则化后较小的权重参数会倾向于被设定为 0,因此会形成一个稀疏的权重矩阵,这样有利于实现特征筛选,而相比较而言,L2 正则化则更加容易使得权重平均的分配,因此 L2 正则化是最常用的一种方式,分母中的 2 是为了便于消除平方求导产生的 2,所以也可以不添加,唯一影响的就是 λ 的值,这个正则化参数 λ 的具体数值需要通过调整数据集来确定。
假设初始训练中使用的成本函数如下:
- J = (1 / m)ΣL(ŷ(i), y(i)) = (1 / m)Σ(-y(i)logŷ(i) - (1 - y(i))log(1 - ŷ(i))),其中 i = 1, 2, 3, ... , m,m 为样本的数量
当发现模型的方差过大时,则在添加 L2 正则化项后成本函数变为:
J = (1 / m)ΣL(ŷ(i), y(i)) + λ ||w||22 / 2m = (1 / m)Σ(-y(i)logŷ(i) - (1 - y(i))log(1 - ŷ(i))) + λ(w12 + w22 + ... + wn2) / 2m
在添加了正则化项后,后向传播的数学表达式将变为:dw[ l ] = [back propagation] + λw[ l ] / m ,w[ l ] = w[ l ] - αdw[ l ],由此可以看出 w 在每次更新后将变得更小,因此 L2 正则化也称为权重衰减 weights decay。
直观的理解 L2 正则化之所以能够减少过拟合是因为较大的正则化项的加入在 J(w, b) 取最小值的前提下会使的 w 的值进一步缩小,从而使得权重矩阵 w 中的参数更接近于 0 ,进而使得很多隐藏单元在计算过程中近乎被消除掉了,这就使得神经网络更加的简单化了,从而消除掉了很多异常数据的影响。
正则化 regularization 这个词听起来非常拗口,在我看来这个操作其实就是使得算法的参数获取过程更加的“稳健”,而不容易受到输入中的异常因素的影响而反应过激。类似于机械设计中的“稳健设计”,对应的英文是 Robust,但相比正则化更加悲惨的是,这个词被离奇的翻译成“鲁棒性”。
作为非英语国家的人,在学习的时候总会遇到很多前人留下的莫名其妙的翻译,一个建议就是在学习的时候要努力把这些词汇翻译成自己能够理解的语言,因为如果不能深刻的理解一个定义,就很难用它来有效的思考。就像 Regular Expression 这个词,在被翻译成了“正则表达式”后让很多人听而生畏,实际上这个词我自己的翻译版本就是“常用表达方式”或者“常规表达方式”。这里做这个引申是希望大家在学习的时候也能对于新接触的概念多几分思考,按照自己的方式去深刻理解这些概念。
随机失活 Dropout 正则化
Dropout 这个词一般指学生“中途退学”,用在这里就是指通过一定的操作不定时的删除掉一些单元的影响,其核心要义是在神经网络的每一个隐藏层都设置一个留存概率 keep-probability,使得网络在每一个样本的训练过程中依据留存概率来随机的消除掉一些单元,而使得网络更加简化。
Dropout 正则化的实施有很多种方法,在本课中 Andrew 主要讲了如何实施反向随机失活 Inverted dropout 正则化,过程如下:
对神经网络的任意一层 l 首先构造一个随机失活矩阵:
dl = np.random.rand(al.shape[0], al.shape[1]) < keep_prob,keep_prob 就是留存概率,假设其为 0.8 则表示这一层中的每一个单元在一次计算中都有 80% 的概率得以被保留,注意此时dl中元素为对应位置上的数字是否 < 0.8 的 True 或 False这一层的激活函数
al = np.multiply(al, dl),使得原有al中的元素被保留或 0 化最后一步需要再将
al /= keep_prob这样做的意义是不改变al以及下一层 z[ l+1 ] = w[ l+1 ]a[ l ] + b[ l+1 ] 的期望值,进而无需对于最终输出进行放大
Dropout 正则化能够减少过拟合的直观解释可以有以下几个方面:
通过随机的 0 化网络中的隐藏单元,相当于简化了网络的结构
由于 0 化是随机进行的,使得网络不会过度依赖某一个特征,权重矩阵中的元素会整体变小且分散到各个特征中去,进而收缩权重的平方范数 ||w||22,其效果相当于 L2 正则化
在实际应用中可以根据不同层的矩阵大小情况设置不同的 keep_prob,矩阵越大则令 keep_prob 的值越小,但需要注意的是原则上不要失活原始输入层,并且除了计算机视觉领域外,除非算法出现了过拟合,否则不建议算法中默认实施正则化。
Dropout 正则化的一个重要的缺点是由于它随机的消除掉了一部分单元,使得网络原本的成本函数的定义不再严格意义上正确,所以如果希望通过绘制成本函数和迭代次数的曲线来了解算法的工作状态时,就需要先关闭 Dropout 正则化,即将 keep_prob 设置为 1 ,再确认曲线是否单调递减。
利用 TensorFlow 实施 dropout 正则化的方法如下:
keep_prob = tf.placeholder(tf.float32) # probability to keep units
hidden_layer = tf.add(tf.matmul(features, weights[0]), biases[0])
hidden_layer = tf.nn.relu(hidden_layer)
hidden_layer = tf.nn.dropout(hidden_layer, keep_prob)
logits = tf.add(tf.matmul(hidden_layer, weights[1]), biases[1])
...
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch_i in range(epochs):
for batch_i in range(batches):
....
sess.run(optimizer, feed_dict={
features: batch_features,
labels: batch_labels,
keep_prob: 0.5})
validation_accuracy = sess.run(accuracy, feed_dict={
features: test_features,
labels: test_labels,
keep_prob: 1})
其他的正则化方法
数据扩增 Data Augmentation
在计算机视觉领域的神经网络应用中,对于数据量的渴求似乎要高于其他领域,所以如果能够通过数据扩增的方式以较低的成本的增加数据的数量,其现实意义会更加凸显。最简单的数据扩增的例子就是在图像分类应用中通过对已有图片进行镜像、随机修剪、旋转、扭曲等方式。除了形状处理,还可以采用改变图片 RGB 通道值来改变颜色的方式,并且对于 RGB 通道改变的量通常遵循某些已知的概率分布,或者参考开源的图片数据扩增实现算法。
借助 Keras 进行数据扩增的方法如下:
from keras.preprocessing.image import ImageDataGenerator
# below is the data augmentation configuration used for training
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# below is the data augmentation configuration used for testing, with only rescaling
test_datagen = ImageDataGenerator(rescale=1. / 255)
# data generator which process the img in parallel with the training or testing
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
# train the model with fit_generator() which incoprate mini-batch and data augmentation
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size)
训练的提前终止 Early Stopping
在神经网络训练过程中,我们通常会绘制成本函数和迭代次数的关系图,理想的情况是成本函数随迭代次数的增加单调递减。在实际应用中,在测试结束后可以在同一张图上叠加调整数据集中成本函数和迭代次数的关系,寻找两条曲线出现较大背离时对应的迭代次数,进而将训练迭代次数设置在此范围内,即使的训练提前终止,使用出现过拟合前的训练参数作为模型的参数。
提前终止的问题在于,在神经网络的使用中,成本函数的最小化和模型的过拟合在理想的情况下应该是两项彼此正交 Orthogonal 的任务,即可以通过不同的工具独立进行。而采用提前终止则将二者合并操作,使得成本函数并未真正的达到现有能力下的最小,因此相比较而言 L2 正则化更加常用。
输入数据的标准化 Normalization
由于输入数据中不同特征的取值范围可能相差很大,并且同一特征在不同样本中的数据取值范围同样也可能相差很大,例如对于取值范围在 [ 0.1, 10000 ] 这样的数据,很明显不应该不加处理的直接进行线性求和,这时就需要输入数据的标准化。除了使得数据更加规整,标准化的隐含的好处是它可以有效的加快学习速度,并且很少会因为对于数据做了标准化而引发不良结果,因此可以有备无患的对于输入数据做标准化处理。
这里所说的标准化就是概率论中常用的通过 z = (x - μ) / σ 对变量做标准化,其中 μ 为对应特征在全部样本集中的取值的均值,σ 为对应特征在全部样本集中的取值的均方差,在课堂中分母 Andrew 用的是 σ2,这里他应该是笔误。
需要注意的是,如果已经对于训练数据做了标准化,则在标准化调整和测试数据时,应采用前面训练数据集中得到的 μ 和 σ ,而不应该在调整和测试数据中重新计算这两个值,这是因为在数学上来自同一个总体的两个子数据集的均值和方差不一定完全相同。
梯度消失 Vanishing 与梯度爆炸 Explosion
在深层神经网络训练中,很可能遇到梯度变的非常小或非常大的情况,使得训练变得困难,前者称为梯度消失,反之则称为梯度爆炸。出现这一现象的原因简单说来就是如果各层参数 w 均大于 1 则在多次传递后,激活函数的值会指数级的增长;反之如果 w 均小于 1 ,则多次传递后,激活函数的值可能会指数级的下降,因此在深度神经网络中如何进行参数的初始化就变得非常重要。
从线性计算部分 z = w1x1 + w2x2 + w3x3 + ... + wnxn 中可以看出,我们需要 w 的值随着 n 的增大而减小,这样才能有效控制 z 的扩增,因此在随机初始化的同时,可以将随机生成的 w 乘以一个关于 n 的函数,具体采用哪一个函数取决于激活函数的选择:
采用 ReLU 作为激活函数:w[ l ] = np.random.randn(shape_tuple) * np.sqrt( 2 / n[ l-1 ])
-
采用 tanh 作为激活函数:
Xavier 初始化:w[ l ] = np.random.randn(shape_tuple) * np.sqrt( 1 / n[ l-1 ])
Bengio:w[ l ] = np.random.randn(shape_tuple) * np.sqrt( 2 / (n[ l-1 ] + n[ l ]))
上述三个权重参数的计算结果生成的是一个形状为 shape 元组的、服从均值为 0、标准差为相应指定的关于 n 的函数的正态分布。这个关于 n 的函数也可以作为超参数成为训练中调整参数的一个目标,但一般不是优先考虑调整的对象。
Udacity 课程中推荐的参数随机初始化方式为:
- weights = np.random.normal(scale=1 / np.sqrt(n), size=shape_tuple)
这个方法获得的参数与上面三种方式得到的结果类似,生成的是一个服从均值为 0,标准差为 σ = scale = 1 / np.sqrt(n) 的正态分布的序列。
在 TensorFlow 中有一个更加优化的一个实现方式是通过在正态分布中只提取均值 0 附近 ±2σ 范围内的取值:
- weights = tf.Variable(tf.truncated_normal(shape_tuple, stddev=1 / np.sqrt(shape_tuple[0])))
反向传播的梯度检查
在反向传播中,可以利用“双边导数 f(θ + ε) - f(θ - ε) / 2ε 可以近似逼近 θ 点的导数”这一性质检查算法中的梯度参数设置是否正确,具体的执行步骤为:
将 W[1], b[1], W[2], b[2], ... , W[L], b[L] 整理成一个大的向量 θ
将 dW[1], db[1], dW[2], db[2], ... , dW[L], db[L] 也整理成一个大的向量 dθ
对于 θ 中每一个元素 θ[ i ] 通过双边导数法计算 dθapprox[ i ],和 dθ[ i ],最终通过计算 || dθapprox - dθ ||2 / (|| dθapprox ||2 + || dθ ||2) 并对比这个值与 ε 的数量级来验证 dθapprox 与 dθ 是否近似相等
关于梯度检查需要注意的是:
梯度检查只应该在 debug 的时使用,不应该在训练中也去做这一计算
如果检查没有通过,应该仔细检查造成这一差异的影响因素在哪里,并作出修改
如果实施了 L2 正则化,则成本函数需要考虑正则化项
如果采用了随机失活正则化,则这个检查将失效,所以在执行检查的时候应该先关闭失活操作
参考阅读
机器学习中正则化项L1和L2的直观理解
机器学习中的范数规则化之(一)L0、L1与L2范数
正则化方法:L1和L2 regularization、数据集扩增、dropout