rhel7静态安装oracle11g真的很麻烦!!!
oracle启动
$sqlplus /nolog
SQL> connect /as sysdba
Connected.
SQL> startup
“/nolog”是不登陆到数据库服务器的意思,如果没有/nolog参数,sqlplus会提示你输入用户名和密码 如果在sql*plus环境中启动数据库的话,必须先使用不登陆到数据库服务器的方式进入sqlplus环境,再用startup命令启动数据库。因为数据库没有启动的话,不能登陆数据库,也无法验证用户名和密码。
启动和关闭监听服务: Oracle监听用于相应客户端连接oracle服务器的请求,如果监听没有启动,则不能通过网络方式访问Oracle数据库服务,只能在Oracle服务器本机以IPC通信的方式接入
$ lsnrctl start/status/stop
登录Oracle服务器
管理员登陆,是典型的操作系统认证,不需要listener进程。
$ sqlplus / as sysdba
普通用户登录。
$ sqlplus scott/11
切换用户:
SQL> connect / as sysdba 将当前登录用户切换为管理员登录
SQL> connect scott/tiger(原始密码) 将当前登录用户切换为scott用户登录
查看用户:
SQL> select username from dba_users;
修改用户密码:
如在登录时出现如下错误提示,说明用户密码即将到期,需进行重设或者修改。
ERROR:
ORA-28002: the password will expire within 7 days
可以采用如下方法修改或重设用户密码:
$sqlplus / as sysdba
SQL> alter user scott identified by password;
User altered. 出现此提示说明修改用户密码成功。
linux下sqlplus使用ed命令
- 在sqlplus中 键入 ed
- 在另外一个应用程序中,打开afiedt.buf文件。进行修改 保存 退出
- 回到sqlplus环境中,键入q
- 在sqlplus中 /
可以将相关命令设置到配置文件中,其配置方法如下:
打开该文件:
# vi $ORACLE_HOME/sqlplus/admin/glogin.sql
在配置文件末尾写入如下内容:
define _editor=vim
set linesize 140
set pagesize 140
Pro*C/C++简介
官方文档查询:E11882_01、e10825_oracleproc联机文件.pdf
proc编译工具的初步使用,宿主变量、连接数据库。
proc“程序结构”
proc“开发流程”:对比.c 和 .pc文件编译流程。
ANSI(美国国家标准学会)定义标准:Oracle → proc编译器
Linux: proc 编译器位置:cdORACLE_HOME → cd bin → ls -l p*
Windows: C:> proc 编译器位置: C:\app\Administrator\product\11.2.0\client_1\BIN
1.proc编程初步
1.1编写hello world
proc编译.pc文件→.c程序。
proc hello.pc → hello.c
编译出错:需要修改 proc 配置文件 pcscfg.cfg
上述问题是因为hello.pc中stdio.h在proc编译器中没有被找到所致
打开设置文件
$ cd $ORACLE_HOME
$ cd ./precomp/admin/
$ vi pcscfg.cfg

将两个版本对应上

1.2连接Oracle数据库
宿主变量:定义在缓冲区中,是连接C语言群和嵌入式SQL语言群的纽带。
EXEC SQL BEGIN DECLARE SECTION;//分号结束标记。
char *serversid = "scott/scott@orc1"; 宿主变量可以被c直接引用;@后面是数据库名称
EXEC SQL END DECLARE SECTION;
EXEC SQL CONNECT :serversid;
C直接使用,嵌入式SQL使用“:”
if (sqlca.sqlcode != 0) { 连接数据库失败
判断sqlca.sqlcode的值是否为0。
sqlcode:数据库操作的返回码,成功→0;失败→-1
前提保证Oracle数据库已经启动,并且监听服务也启动成功。
#include "sqlca.h" 所在目录:$ORACLE_HOME/precomp/public
动态库libclntsh.so 所在目录:$ORACLE_HOME/lib
gcc test.c -o test -L $ORACLE_HOME/lib
-I $ORACLE_HOME/precomp/public -l clntsh
连接数据库出错:如,将登陆密码错误输入,./test 执行文件 得到错误提示:connect err : -1017
使用:“oerr ora 错误码” 查看错误描述。如:oerr ora 1017(负号省略)
断开连接 EXEC SQL COMMIT RELEASE; release 是断开连接,断开之前必须commit或者rollback
1.2.1示例程序:【hello.pc】
#include
#include "sqlca.h"
EXEC SQL BEGIN DECLARE SECTION;
char *serversid = "scott/121@orcl";
EXEC SQL END DECLARE SECTION;
int main(void)
{
int ret = 0;
printf("serversid: %s\n", serversid);
EXEC SQL CONNECT :serversid;
if (sqlca.sqlcode != 0) {
ret = sqlca.sqlcode;
printf("connect err: %d\n", ret);
return ret;
}
printf("connect ok...\n");
EXEC SQL COMMIT RELEASE;
printf("hello proc...\n");
return 0;
}
1.2.2Makefile文件的编写
C_FILES = $(wildcard *.pc)
C_MIDDLE1 = $(patsubst %.pc, %.c, $(C_FILES))
C_MIDDLE2 = $(patsubst %.pc, %.lis, $(C_FILES))
C_TARGET = $(patsubst %.pc, %, $(C_FILES))
lib_path = ${ORACLE_HOME}/lib
inc_path = ${ORACLE_HOME}/precomp/public
all:$(C_TARGET)
$(C_TARGET):%:%.c
gcc $< -o $@ -L$(lib_path) -I$(inc_path) -lclntsh
%.c:%.pc
proc $<
.PHONY:clean all
clean:
-rm -rf $(C_TARGET) $(C_MIDDLE1) $(C_MIDDLE2) *~
${ ORACLE_HOME }可以在Makefile中使用环境变量使用自定义变量是 $(abc)
1.3proc编译C++程序
将test.pc修改成test2.pc,使用c++的语法。 同样使用proc编译 出错。
原因是proc编译器默认会将.pc的文件按C语法进行编译。如果想编译c++程序,需要在proc编译时指定编译选项
parse=none 告诉proc编译器 按照c++规范解析文件
code=cpp 告诉proc编译器 按照c++规范生成文件
oname 指定输出文件名
$ proc test2.pc parse=none code=cpp oname=test2.cpp
$ g++ test2.cpp -o test2 -I $ORACLE_HOME/precomp/public -L $ORACLE_HOME/lib -l clntsh
1.4静态SQL insert/update/delete
1.4.1在proc程序中insert
EXEC SQL insert into dept(deptno, dname, loc) values(:deptno, :dname, :loc);
由于事物的隔离性,所以任何一个操作结束后应及时使用 EXEC SQL COMMIT
注意:proc中做insert、update、delete操作的时候,sqlplus不要做除select之外其他操作。否则会发生死锁。
1.4.2在proc程序中update
EXEC SQL update dept set loc = :loc, dname = :dname where deptno=50;
1.4.3在proc程序中delete
EXEC SQL delete from dept where deptno = :deptno;
示例程序:【01_insert_up_del.pc】
#include
#include
EXEC SQL BEGIN DECLARE SECTION;
char *serversid = "scott/scott@orc1";
EXEC SQL END DECLARE SECTION;
int main(void)
{
int ret;
printf("serversid = %s\n",serversid);//C直接使用
EXEC SQL connect :serversid;//PROC连接
if(sqlca.sqlcode != 0){//非0表示连接失败,错误提示保存在sqlca结构体的sqlcode中
ret = sqlca.sqlcode;
printf("connect error:%d\n",sqlca.sqlcode);//u can find error by "oerr ora ret"
return ret;
}
printf("connect success!\n");
//insert into dept(deptno,dname,loc) values(51,'Engineer','BEIJING');
EXEC SQL insert into dept(deptno,dname,loc) values(55,'Engineer','BEIJING');
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("insert error:%d\n",sqlca.sqlcode);
return ret;
}
EXEC SQL commit;//插入一个事务,必须要commit代表完成,不然要到完成整个事务,这个insert才算成功
printf("insert success!\n");
//update dept set dname='50dname',loc='50loc' where deptno = 50;
EXEC SQL update dept set dname='50dname',loc='50loc' where deptno = 55;
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("update error:%d\n",sqlca.sqlcode);
return ret;
}
printf("update success!\n");
getchar();
//delete from dept where deptno > 40;
EXEC SQL delete from dept where deptno > 40;
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("delete error:%d\n",sqlca.sqlcode);
return ret;
}
printf("delete success!\n");
EXEC SQL COMMIT RELEASE;//断开连接
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("release error:%d\n",sqlca.sqlcode);
return ret;
}
printf("release success!\n");
return 0;
}
1.4.4select
将数据库中的数据查询出来,保存在 宿主变量 中,并回显到终端上。
EXEC SQL select deptno, dname, loc into :deptno, :dname, :loc from dept where deptno = 10;
由于数据类型的原因,所有不足20字节的字符串填充了“空格”!——> 宿主变量的数据类型。
【注意】:当搜索结果为多行的时候,一个变量是无法保存的,编译会报错:SELECT..INTO returns too many rows
例如,使用where deptno = 20作为限定条件,查询emp表。但是,如果是where empno = 7788则没有问题。
1.4.5变长字符串类型
使用 EXEC SQL select deptno, dname, loc into :deptno, :dname, :loc from dept where deptno = 10;
输出到屏幕,由于数据类型的原因,所有不足20字节的字符串填充了“空格”!在此处应该使用变长字符串varchar类型。但这种数据类型存储的数据,如何让gcc编译器认得呢?
分析程序结构,应发现:
EXEC SQL BEGIN DECLARE SECTION;
...
EXEC SQL END DECLARE SECTION;
之间的变量应是Proc编译器,借助C定义变量的语法,定义的变量。
原因:.pc → proc → .c → gcc → 可执行文件。
在 proc_xxx.pc 中 定义varchar dname[20] 宿主变量,varchar 类型只有proc识得
但gcc编译器也没有报错。查看生成的.c文件,发现:proc编译器对varchar进行了转化:
varchar dname[20] → struct { unsigned short len; unsigned char arr[20]; } dname2;
C程序使用dname时,实际用的是dname.arr,——如:printf("dname:%s, loc:%s, deptno:%d\n", dname2.arr, loc2.arr, deptno2);
而 EXEC SQL 使用danme的时候,就直接使用danme,因为proc会在编译的时候将danme → struct ....结构体。
——程序比较,使用char dname[20]; printf("%s", dname) 和 varchar dname[20] printf("%s",danme.arr);区别。
示例程序:
#include
#include
EXEC SQL BEGIN DECLARE SECTION;//宿主变量部分
char *serverid = "scott/scott@orc1";
int deptno;
varchar dname[20];
varchar loc[20];
EXEC SQL END DECLARE SECTION;
int main(void)
{
int ret;
EXEC SQL CONNECT :serverid;
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("connect error:%d\n",sqlca.sqlcode);
return ret;
}
printf("connect success!\n");
//select deptno,dname,loc from dept where deptno = 10;
EXEC SQL select deptno,dname,loc into :deptno, :dname, :loc from dept where deptno = 10;//结果需要变量接收
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("select error:%d\n",sqlca.sqlcode);
return ret;
}
printf("deptno = %d |dname = %s|loc = %s\n",deptno,dname.arr,loc.arr);
/*查看编译出来的.c文件,varchar类型被自动转化为一个结构体!*/
EXEC SQL COMMIT RELEASE;
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("release error:%d\n",sqlca.sqlcode);
return ret;
}
printf("release success!\n");
return 0;
}
1.5Oracle Proc数据类型
在借助Proc程序访问Oracle数据库的整个过程中,主要涉及到的数据类型有三种,分别是:宿主变量数据类型、外部数据类型、内部数据类型。
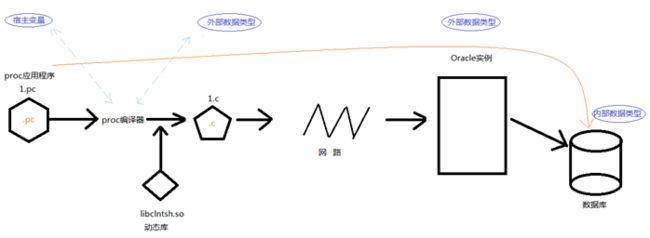
1.5.1内部数据类型
数据库中的表和伪列使用的数据类型,如:varchar2、number、date ……Oracle将数据存储到表的列中所使用的数据格式。
1.5.2宿主变量数据类型
在 .pc 文件中定义变量所使用的数据类型,如:int、char、char[N]、short、varchar[N]、……
用于在 .pc 应用程序中和oracle数据库之间传递数据。
1.5.3外部数据类型
外部数据类型包括全部的 内部数据类型 和 宿主变量数据类型。
.pc生成的可执行程序,在运行时会将宿主变量数据类型,映射成Oracle外部数据类型。
重点:在编写Pro*C/C++程序的时候不能直接使用Oracle外部数据类型来定义宿主变量!
1.5.4数据类型转换
只有“宿主变量数据类型”和我们的.pc程序直接产生关系。proc编译时,需完成转化成外部数据类型工作:
- 自动转换:varchar dname[20] → struct { unsigned short len; unsigned char arr[20]; } dname2;
- 手动转换:其主要转换语法如下:
typedef char dnameType[20]; 使用typedef定义数组数据类型
EXEC SQL BEGIN DECLARE SECITON;
EXEC SQL TYPE dnameType is string(20); 告诉proc编译器将dnameType类型转为string类型 ('\0'结束标记)。
dnameType dname; 使用新定义的数据类型定义变量。相当于 char danme[20];
EXEC SQL END DELARE SECTION; 手动转化、变量定义都应该放置在声明段中。
注意:手动转换,这里没有使用到varchar数据类型,只是char[N] 和 string 之间进行转换。
无论是自动转换还是手动转换,都必须满足“可以转换”的前提条件。
——程序比较,使用typedef、EXEC SQL TYPE 与之前两种类型,printf输出的区别。
示例程序:
#include
#include
#include
typedef char dnameType[20];
EXEC SQL BEGIN DECLARE SECTION;//宿主变量部分
char *serverid = "scott/scott@orc1";
EXEC SQL TYPE dnameType is string(20);//向proc编译器注册
int deptno;
dnameType dname;//char dname[20];
dnameType loc;
EXEC SQL END DECLARE SECTION;
int main(void)
{
int ret;
EXEC SQL CONNECT :serverid;
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("connect error:%d\n",sqlca.sqlcode);
return ret;
}
printf("connect success!\n");
deptno = 80;
strcpy(dname,"80dname");//双引号
strcpy(loc,"80loc");
EXEC SQL insert into dept(deptno,dname,loc) values(:deptno,:dname,:loc);
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("insert error:%d\n",sqlca.sqlcode);
return ret;
}
EXEC SQL COMMIT;
printf("insert success!\n");
//select deptno,dname,loc from dept where deptno = 10;
EXEC SQL select deptno,dname,loc into :deptno, :dname, :loc from dept where deptno = 80;//结果需要变量接收
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("select error:%d\n",sqlca.sqlcode);
return ret;
}
printf("deptno = %d |dname = %s|loc = %s\n",deptno,dname,loc);
/*查看编译出来的.c文件,varchar类型被自动转化为一个结构体!*/
EXEC SQL COMMIT RELEASE;
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("release error:%d\n",sqlca.sqlcode);
return ret;
}
printf("release success!\n");
return 0;
}
1.6宿主变量和指示变量的作用
宿主变量:
通过 EXEC SQL 从程序写数据到数据库中 ——输入
通过 EXEC SQL 从数据库读数据到程序中 ——输出
指示变量:写入、读出数据库数据是一个“空值”的时候。
在 DECLARE SECTION (声明段) 中,对应宿主变量定义指示变量:只能使用short类型。如:short loc_ind;
loc_ind = -1;当指示变量被赋值为-1时,执行插入语句时,无论对应宿主变量为何值,都直接写入NULL,
EXEC SQL insert into dept(deptno, dname, loc) values(:deptno, :dname, :loc:loc_ind);
EXEC SQL COMMIT;
EXEC SQL select deptno, dname, loc into :deptno, :dname, :loc:loc_ind from dept where deptno = :deptno;
if (loc_ind == -1) {
strcpy(loc, "NULL");
}
同样,从数据库读取数据时, 若原表中数据为空,loc_ind将被置成-1。
可以根据需要,将为NULL的数据设置为指定值。如:设置成字符串“NULL”
#include
#include
#include
typedef char dnameType[20];
EXEC SQL BEGIN DECLARE SECTION;//宿主变量部分
char *serverid = "scott/scott@orc1";
EXEC SQL TYPE dnameType is string(20);//向proc编译器注册
int deptno;
dnameType dname;//char dname[20];
dnameType loc;
short loc_ind;//定义指示变量
EXEC SQL END DECLARE SECTION;
int main(void)
{
int ret;
EXEC SQL CONNECT :serverid;
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("connect error:%d\n",sqlca.sqlcode);
return ret;
}
printf("connect success!\n");
deptno = 81;
strcpy(dname,"80dname");//双引号
strcpy(loc,"80loc");
loc_ind = -1;//指示变量赋值
EXEC SQL insert into dept(deptno,dname,loc) values(:deptno,:dname,:loc:loc_ind);//指示变量用法
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("insert error:%d\n",sqlca.sqlcode);
return ret;
}
EXEC SQL COMMIT;
printf("insert success!\n");
getchar();
//select deptno,dname,loc from dept where deptno = 10;
EXEC SQL select deptno,dname,loc into :deptno, :dname, :loc:loc_ind from dept where deptno = 81;//结果需要变量接收
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("select error:%d\n",sqlca.sqlcode);
return ret;
}
if(loc_ind == -1){
strcpy(loc,"NULL");
}
printf("deptno = %d |dname = %s|loc = %s\n",deptno,dname,loc);
/*查看编译出来的.c文件,varchar类型被自动转化为一个结构体!*/
EXEC SQL COMMIT RELEASE;
if(sqlca.sqlcode != 0){
ret = sqlca.sqlcode;
printf("release error:%d\n",sqlca.sqlcode);
return ret;
}
printf("release success!\n");
return 0;
}
1.6通讯区和错误处理
当 .pc → proc → .c 文件,proc编译器在编译期间向源文件加入了一个重要区域: —— 通讯区。
ORACLE提供的两个通信区,sqlca 和 oraca。当需要更进一步的信息时,ORACA将帮助我们达成愿望,所以ORACA也可以看作时SQLCA的补充和辅助。
通讯区用来缓存程序信息,如程序编译出错,错误信息会被对应到 sqlca.h 中的结构体中。可以从该头文件中找到该通讯区的结构。
查看sqlca.h头文件所在位置:
Linux: $ORACLE_HOME/precomp/public/sqlca.h
该头文件实际上只包含两个部分,struct sqlca 定义和初始化。定义中嵌套了结构体变量 sqlerrm:
表示 sql error message ,两个成员变量分别表示 sql error message length 和sql error message contents
#ifndef SQLCA
#define SQLCA 1
struct sqlca
{
/* ub1 */ char sqlcaid[8]; //被初始化为sqlca,标识SQL通讯区
/* b4 */ int sqlabc; //SQL通讯区的长度
/* b4 */ int sqlcode; //最近执行的SQL语句的状态码 0:正确执行
//>0:执行了语句,但没有记录行返回
//<0:数据库,系统,网络故障,SQL语句没有执行
struct
{
/* ub2 */ unsigned short sqlerrml; // sqlerrmc数组的实际文本长度
/* ub1 */ char sqlerrmc[70]; //与sqlcode一致的对应的错误信息文本
//只有当sqlcode<0才能访问,否则是上次错误信息
} sqlerrm;
/* ub1 */ char sqlerrp[8]; //没有使用
/* b4 */ int sqlerrd[6]; //sqlerrd[0],sqlerrd[1] , sqlerrd[3], sqlerrd[5]没有使用
//sqlerrd[2]SQL语句处理的行数,如果SQL执行失败,则没有定义
//sqlerrd[4]出现语法分析错误的字符开始位置,第一个位置是0
/* ub1 */ char sqlwarn[8]; //警告标记
//sqlwarn[0]其他警告标记设置,该标记就被设置
//sqlwarn[1]字段值被截断输出到宿主变量的时候被设置
//sqlwarn[2],sqlwarn[6],sqlwarn[7]没有被使用
//sqlwarn[3]查询字段个数不等于宿主变量个数的时候被设置
//sqlwarn[4]表中记录被没有where子句的delete,update处理的时候被设置
//sqlwarn[5]当EXEC SQL CREATE{PROCDURE|FUNCTION|PACKAGE}语句编译错误的时候被设置
/* ub1 */ char sqlext[8]; //没有被使用
};
#ifndef SQLCA_NONE
#ifdef SQLCA_STORAGE_CLASS
SQLCA_STORAGE_CLASS struct sqlca sqlca
#else
struct sqlca sqlca
#endif
#ifdef SQLCA_INIT
= {
{'S', 'Q', 'L', 'C', 'A', ' ', ' ', ' '},
sizeof(struct sqlca),
0,
{ 0, {0}},
{'N', 'O', 'T', ' ', 'S', 'E', 'T', ' '},
{0, 0, 0, 0, 0, 0},
{0, 0, 0, 0, 0, 0, 0, 0},
{0, 0, 0, 0, 0, 0, 0, 0}
}
#endif
;
#endif
#endif
1.6.1示例程序:
//sqlerr函数的实现。
//EXEC SQL WHENEVER SQLERROR DO sqlerr();
#include
#include
#include
#include "sqlca.h"
typedef char dnameType[20];
EXEC SQL BEGIN DECLARE SECTION;
char *serversid = "scott/121@orcl";
EXEC SQL TYPE dnameType is string(20);
int deptno;
dnameType dname;
dnameType loc;
short loc_ind;
EXEC SQL END DECLARE SECTION;
void sqlerr(void)
{
EXEC SQL WHENEVER SQLERROR CONTINUE;
printf("Error Reason: %.*s\n", sqlca.sqlerrm.sqlerrml, sqlca.sqlerrm.sqlerrmc);
EXEC SQL ROLLBACK RELEASE;
exit(1);
}
int main(void)
{
int ret = 0;
EXEC SQL WHENEVER SQLERROR DO sqlerr(); //注册错误处理
EXEC SQL CONNECT :serversid;
printf("-----------exec here?------------\n");
if (sqlca.sqlcode != 0) {
ret = sqlca.sqlcode;
printf("connect error : %d\n", ret);
return ret;
}
EXEC SQL select deptno, dname, loc into :deptno, :dname, :loc:loc_ind from dept where deptno = 10;
if (loc_ind == -1) {
strcpy(loc, "NULL");
}
printf("dname:%s, loc:%s, deptno:%d\n", dname, loc, deptno);
EXEC SQL COMMIT RELEASE;
return 0;
}
EXEC SQL WHENEVER SQLERROR DO sqlerr();可以代替之前 EXEC SQL 语句后的if (sqlca.sqlcode != 0)
printf("Error Reason: %.*s\n", sqlca.sqlerrm.sqlerrml, sqlca.sqlerrm.sqlerrmc);语句中,“*”用来指定宽度,对应一个整数。“.”与后面的数合起来,指定必须输出这个宽度,如果输出的字符串长度大于该数,则按此宽度输出,如果小于,则输出实际长度。
EXEC SQL WHENEVER SQLERROR CONTINUE;中“continue”的作用:“下一步”,防止递归。 区别于for、while中的continue。
在CONTINUE之后的 EXEC SQL ROLLBACK RELEASE;如果出错,那么不会再次调用sqlerr(),而是执行“下一步”exit(1)。
1.7宿主数组
当查询表中多行数据的时候,一个宿主变量不能胜任,此时应该使用“宿主数组”。
char dname2[10][20];表示可以存10行dname,每个dname的字符数不超过20字节
EXEC SQL select deptno, dname, loc into :deptno2, :dname2, :loc2:loc_ind from dept;
注意跟之前的宿主变量select比较, 这里没有使用where限制条件,可以一次查询多行数据。
如果宿主变量没有跟随指示变量loc_ind,查询结果有“空值”时,会出现SQL错误:ORA-01405: fetched column value is NULL
——复习创建表、删除表:
create table 表名 as select * from 数据源表名 where 1=2;
drop table 表名 purge;
——向表dept2中插入多行数据:
EXEC SQL For :count insert into dept2(deptno, dname, loc) values(:deptno2, :dname2, :loc2:loc_ind);
count = sqlca.sqlerrd[2]; 通讯区的sqlerrd[2]保存了SQL语句处理的行数。
for (i = 0; i < count; i++)
printf("%d\t%s\t%s\n", deptno2[i], dname2[i].arr, loc2[i].arr);
注意:如果是从一张表中读出数据,插入另外一张表,那么字符数组 dname2、loc2 应该是varchar类型,而非char类型。
——创建表: 使用SQL创建一张表dept2,格式同dept
EXEC SQL create table dept2 as select * from dept where 1=2;
示例程序:
#include
#include
#include
#include "sqlca.h"
typedef char dnameType[20]; //dnameType类型
EXEC SQL BEGIN DECLARE SECTION;
char *serversid = "scott/11@orcl";
EXEC SQL TYPE dnameType is string(20);
int count; //记录rows
int deptno2[10];
varchar dname2[10][20]; //10个名字,每个名字最长20字符
varchar loc2[10][20];
short loc_ind[10];
EXEC SQL END DECLARE SECTION;
void sqlerr(void)
{
EXEC SQL WHENEVER SQLERROR CONTINUE;
printf("Error Reason: %.*s\n", sqlca.sqlerrm.sqlerrml, sqlca.sqlerrm.sqlerrmc);
EXEC SQL ROLLBACK RELEASE;
exit(1);
}
int main(void)
{
int i;
EXEC SQL WHENEVER SQLERROR DO sqlerr(); //错误处理,代替if(sqlca.sqlcode != 0)
EXEC SQL CONNECT :serversid; //链接数据库
EXEC SQL select deptno, dname, loc into :deptno2, :dname2, :loc2:loc_ind from dept;
count = sqlca.sqlerrd[2]; //通讯区的sqlerrd[2]保存了SQL语句处理的行数。
printf("------SQL rows = %d\n", count);
for (i = 0; i < count; i++) {
printf("%d\t%s\t%s\n", deptno2[i], dname2[i], loc2[i]); //dname2[i]取二维数组的行
}
printf("Enter any key to create dept2 \n");
getchar();
getchar();
//使用SQL创建一张表dept2,格式同dept
EXEC SQL create table dept2 as select * from dept where 7=3;
printf("Enter any key to insert into dept2 ----lots of rows\n");
getchar();
//向表中插入多行数据:
EXEC SQL For :count insert into dept2(deptno, dname, loc)
values(:deptno2, :dname2, :loc2:loc_ind);
printf("----insert into dept2 finish...\n");
EXEC SQL COMMIT RELEASE; //提交事物并断开连接。
return 0;
}
1.8普通游标
使用宿主数组操作表:
优点:整体数据操作,便捷;
缺点:不灵活。如果表中有100000行数据,varchar dname[100000][20]不合适。
游标(cursor):单行单行获取数据。
——所以: 不需要定义宿主数组(宿主变量即可),也不使用 count 和 sqlca.cqlerrd[2]
使用一般步骤:
- 定义游标: ——理解:游标是为某一次查询(select)而生的。
EXEC SQL DECLARE dept_cursor CURSOR For select deptno, dname, loc from dept;
- 打开游标:
EXEC SQL OPEN dept_cursor;
打开游标成功,将做两件事:
- 将select查询的结果放置到内存区。
- 将游标指针指向第一行数据。
- 提取数据:fetch into
每取完一条数据,游标指针自动向下移动一行。所以,多行数据时,应该使用循环。
while (1) {
EXEC SQL FETCH dept_cursor INTO :deptno, :dname, :loc:loc_ind;
if (sqlca.sqlcode == 100 || sqlca.sqlcode == 1403) {
break;
}
printf("%d, %s, %s\n", deptno, dname.arr, loc.arr);
//效果等同于使用宿主数组时的 EXEC SQL select ... into ... from dept;
}
100 → ANSI标准 1403 → Oracle标准 判断是否到达数据结尾。
- 关闭游标:
EXEC SQL CLOSE dept_cursor;
当使用varchar变量的arr成员时,会发生短数据名称中包含长数据结尾的现象。原因是结构体中的arr保存完数据后不会自动清空。
varchar dname2[20]; → proc预编译器 → struct { unsigned short len; unsigned char arr[22]; } dname2[20];
varchar loc2[20]; → proc预编译器 → struct { unsigned short len; unsigned char arr[22]; } loc2[20];
可以使用memset()来手动置空。memset(dname.arr, 0, 20); memset(loc.arr, 0, 20);
也可以使用typedef 和 TYPE ... is string(20) 转化为string外部数据类型。
typedef char dnameType[20];
typedef char locType[20];
EXEC SQL TYPE dnameType is string(20);
EXEC SQL TYPE locType is string(20);
dnameType dname;
locType loc;
while (1) {
EXEC SQL FETCH dept_cursor INTO :deptno, :dname, :loc:loc_ind;
if (sqlca.sqlcode == 100 || sqlca.sqlcode == 1403) {
break;
}
printf("%d\t%s\t%s\n", deptno, dname, loc);
}
示例程序
#include
#include
#include
#include "sqlca.h"
typedef char dnameType[20];
typedef char locType[20];
EXEC SQL BEGIN DECLARE SECTION;
char *serversid = "scott/scott@orc1";
EXEC SQL TYPE dnameType is string(20);
EXEC SQL TYPE locType is string(20);
int deptno;
dnameType dname;
locType loc;
short loc_ind;
EXEC SQL END DECLARE SECTION;
void sqlerr(void)
{
EXEC SQL WHENEVER SQLERROR CONTINUE;
printf("Error Reason: %.*s\n", sqlca.sqlerrm.sqlerrml, sqlca.sqlerrm.sqlerrmc);
EXEC SQL ROLLBACK RELEASE;
exit(1);
}
int main(void)
{
int ret = 0;
deptno = 50;
strcpy(dname,"Engineer");
strcpy(loc,"BeiJing");
EXEC SQL WHENEVER SQLERROR DO sqlerr(); //错误处理,代替if(sqlca.sqlcode != 0)
EXEC SQL CONNECT :serversid; //链接数据库
EXEC SQL insert into dept(deptno, dname, loc) values(:deptno, :dname, :loc);
printf("insert ok...\n");
//1. 定义游标
EXEC SQL DECLARE dept_cursor CURSOR for select * from dept;
//2. 打开游标
EXEC SQL OPEN dept_cursor;
//3. 提取数据
while (1) {
EXEC SQL FETCH dept_cursor INTO :deptno, :dname, :loc:loc_ind;
/*
没有commit为什么能查到新插入的数据?
我的所有操作都在同一个事务当中,所以我可以查询得到
如果是另外一个事务要查询,这里必须是commit,它才可以查询得到
*/
if (sqlca.sqlcode == 100 || sqlca.sqlcode == 1403) {
break;
}
printf("%d\t%s\t%s\n", deptno, dname, loc);
}
//4. 关闭游标
EXEC SQL CLOSE dept_cursor;
EXEC SQL COMMIT RELEASE; //提交事物并断开连接。
return 0;
}
2.动态SQL
- 静态SQL:
如果将SQL语句直接写死到程序中,那么proc、gcc编译完成生成可执行程序,不能再进行修改。 - 动态SQL:
程序运行起来以后,再进行输入SQL语句(SQL语句生成的时间晚于应用程序)。 sqlplus使用大量的动态SQL 所以,含有动态SQL的程序要解析所有的用户输入/输出:
select ....
form tab1, tab2 ...
where ...
order by...
group by...
having
动态SQL分为4种,前面三种作为第4种的基础。
第4种动态SQL有两种实现方式:
- ANSI标准
- Oracle自定义
应用场景:公司内部proc项目组,为公司提供企业的、通用的proc API接口。(自定义API函数)
2.1动态SQL1
非select语言
可以执行insert、update、delete这样的非select语句,这些语句的特点是,没有select结果集。
执行用户输入的SQL语句(保存在pSql中):
EXEC SQL EXECUTE IMMEDIATE :pSql;
注:测试 动态sql_1 时,insert into dept values(68, '68name', '68loc')之后不要加 “ ;”程序中未添加结束标记判定。
---------------------------显示错误SQL语句函数sqlgls----------------------------
sqlerr02 sqlgls(char *, size_t *, size_t *) → .../public/sqlcpr.h
-------------------------------------------------------------------------------------
#include
#include
#include
#include "sqlca.h"
#include "oraca.h"
extern sqlgls(char * , size_t *, size_t * );
void connet();
void sqlerr02()
{
char stm[120];
size_t sqlfc, stmlen=120;
unsigned int ret = 0;
//出错时,可以把错误SQL语言给打印出来
EXEC SQL WHENEVER SQLERROR CONTINUE;
ret = sqlgls(stm, &stmlen, &sqlfc);
printf("出错的SQL:%.*s\n", stmlen, stm);
printf("出错原因:%.*s\n", sqlca.sqlerrm.sqlerrml, sqlca.sqlerrm.sqlerrmc);
EXEC SQL ROLLBACK WORK RELEASE;
exit(1);
}
void nodata(void)
{
int ret = 0;
printf("没有发现数据\n");
if (sqlca.sqlcode != 0) {
ret = sqlca.sqlcode;
printf("sqlca.sqlcode: err:%d \n", sqlca.sqlcode);
return ;
}
}
typedef char dnameType[20];
typedef char locType[20];
EXEC SQL BEGIN DECLARE SECTION;
EXEC SQL TYPE dnameType is string(20);
EXEC SQL TYPE locType is string(20);
char *usrname = "scott";
char *passwd = "scott";
char *serverid = "orc1";
int deptno;
dnameType dname;
short dname_ind;
locType loc;
short loc_ind;
char mySql[1024];
char *pSql;
EXEC SQL END DECLARE SECTION;
/*动态sql_1
insert into dept values(69, '69name', '69loc') 没有结果集
非select语言,无占位符变量
*/
void connet(void)
{
int ret = 0;
//连接数据库
EXEC SQL CONNECT:usrname IDENTIFIED BY:passwd USING:serverid ;
if (sqlca.sqlcode != 0)
{
ret = sqlca.sqlcode;
printf("sqlca.sqlcode: err:%d \n", sqlca.sqlcode);
return ;
} else {
printf("connect ok...\n");
}
}
int main(void)
{
int ret = 0;
int i = 0;
char choosechar;
memset(mySql, 0, sizeof(mySql)); //缓冲区清空
pSql = NULL;
EXEC SQL WHENEVER SQLERROR DO sqlerr02();
connet();
EXEC SQL WHENEVER NOT FOUND DO nodata();
pSql = mySql; //指针指向缓冲区
//循环处理sql语言
for(;;)
{
printf("\nPlease enter sql(not select and no ';'): ");
gets(mySql);
//scanf("%s", mySql); --不宜使用,因为空格截断
printf("mysql:%s\n", mySql);
EXEC SQL EXECUTE IMMEDIATE :pSql;//pSql正指向mySql
//> update dept set loc= 'locloc' where deptno=62
EXEC SQL COMMIT;
printf("继续执行吗?\n");
scanf("%c", &choosechar);
fflush(stdin);
if (choosechar=='n' || choosechar=='N')
{
break;
}
}
EXEC SQL COMMIT WORK RELEASE;//WORK可以省略
printf("return ok...\n");
return ret ;
}
2.2动态SQL2
非select语言,可绑定变量(占位符)
相较于动态SQL1,可以使用户在输入SQL语句时有机会指定a、b两处的值,这两个占位符得值将绑定到宿主变量。
准备动态SQL:
EXEC SQL PREPARE my_pre_sql FROM 'update dept set loc = :a where deptno = :b';执行动态SQL:
EXEC SQL EXECUTE my_pre_sql USING :loc, :deptno;//关键是using
/*初始化:同 1例*/
/*动态sql2
非查询语言, 可以带固定数量的宿主变量
使用内嵌PREPARE命令准备SQL语言
有2步骤:
1. PREPARE语法
EXEC SQL PREPARE statement_name FROM {:host_string | string_literal};
意为:准备一个SQL语句statement_name, 该语句包含占位符。但尚未执行。
PREPARE是一个预编译器标识符,而不是宿主变量。
2. USING子句
EXEC SQL EXECUTE statement_name [USING :host_variable1[:indicator1] [, :host_variable2[:indicator2] ... ] ;
意为:使用准备好的SQL语句statement_name, 同时使用宿主变量
*/
int main(void)
{
int ret = 0;
int i = 0;
char choosechar;
memset(mySql, 0, sizeof(mySql));
pSql = NULL;
EXEC SQL WHENEVER SQLERROR DO sqlerr02();
connet();
EXEC SQL WHENEVER NOT FOUND DO nodata();
pSql = mySql;
//循环处理sql语句
for(;;)
{
printf("\update ur new deptno ");
scanf("%d", &deptno);
printf("\nupdate ur new loc ");
scanf("%s", loc);
//准备动态sql
EXEC SQL PREPARE my_pre_sql FROM 'update dept set loc = :a where deptno = :b';
//执行动态sql,并使用宿主变量 :a :b相当于留坑!等着下面填
EXEC SQL EXECUTE my_pre_sql USING :loc, :deptno; //:a = loc :b = deptno
EXEC SQL COMMIT;
printf("\n press any key to continue ");
getchar();
printf("\npress n to log out ");
scanf("%c", &choosechar);
fflush(stdin);
if (choosechar=='n' || choosechar=='N') {
break;
}
}
EXEC SQL COMMIT WORK RELEASE;
printf("return ok...\n");
return ret ;
}
2.3
可以处理select返回回来的结果集 (有限个数)。
可以 select 语句。但:
输入宿主变量个数固定,查询条件固定。
输出宿主变量个数固定,返回结果固定。
在sqlplus中查询dept表可以返回3列,查询emp表可以返回多列,而在动态SQL3中只能查询一种固定列数的结果集。
EXEC SQL PREPARE my_pre_sql3 FROM 'select deptno, dname, loc from dept where deptno > :a';
相当于给 select deptno, dname, loc from dept where deptno > :a起了一个别名 my_pre_sql3,带有占位符,用来给用户输入条件。无论指定几个占位符,编译完成,用户一但输入,查询条件即固定。同样,输出的列数也是固定的。deptno,dname,loc
动态sql_3是将 PREPARE 与 游标 结合在一起使用.
/*动态sql_3
查询部门号大于10的所有部门信息
处理选择列表项(select查询出来的结果列数固定) 和 输入宿主变量个数一定
本质: 输入宿主变量个数固定 查询条件固定
输出宿主变量个数固定 返回结果固定
语法特征:结合游标一起使用
*/
int main(void)
{
int ret = 0;
char choosechar;
memset(mySql, 0, sizeof(mySql));
pSql = NULL;
EXEC SQL WHENEVER SQLERROR DO sqlerr02();
connet();
EXEC SQL WHENEVER NOT FOUND DO nodata();
//循环处理sql语言
for(;;)
{
printf("\n请输入部门编号 ");
scanf("%d", &deptno);
//准备动态sql,在SQL2中用到
EXEC SQL PREPARE my_pre_sql3 FROM 'select deptno, dname, loc from dept where deptno > :a';
//定义游标c1,为某一次查询
EXEC SQL DECLARE c1 CURSOR FOR my_pre_sql3;
//打开游标c1,使用占位符指定的宿主变量
EXEC SQL OPEN c1 USING :deptno;//USING相当于填坑操作,位置不固定,只要在proc语句中
//相当于下面循环中加入了: if (sqlca.sqlcode == 100 || sqlca.sqlcode == 1403)
EXEC SQL WHENEVER NOT FOUND DO break;
//提取数据
for (;;) {
//当游标查询到结果时,将数据fetch into到宿主变量中。处理完一行,游标下移处理下一行
EXEC SQL FETCH c1 INTO :deptno, :dname, :loc:loc_ind;
printf("%d\t %s\t %s \n", deptno, dname, loc);
}
//关闭游标
EXEC SQL CLOSE c1;
EXEC SQL COMMIT;
printf("\n 按任意键继续? ");
getchar();
printf("\n键入 n 退出, 其他继续? ");
scanf("%c", &choosechar);
fflush(stdin);
if (choosechar == 'n' || choosechar == 'N') {
break;
}
}
EXEC SQL COMMIT WORK RELEASE;
printf("return ok...\n");
return ret ;
}
2.4动态SQL4
2.4.1ANSI标准方式
按照ANSI组织定义的标准实现的动态SQL。掌握程度:理解程序架构即可。
读程序思考:
- 如何处理select语句 和 非select语句。→ 二者最大区别在于:应用程序是否能处理select的结果集。
找到程序中处理结果集的代码。区分非处理结果集代码。 - 输入描述区 和 输出描述区。
- 如何处理输入描述区
- 如何处理输出描述区(如何一行一行的解析数据库返回的数据集)
#include
#include
#include
#include
/* 定义绑定变量值 和 选择列表项值的最大长度
* 绑定变量:类似于在SQL语句中输入的“&”占位符。
*/
#define MAX_VAR_LEN 30
/* 定义选择列表项名的最大长度 */
#define MAX_NAME_LEN 31
/* 定义宿主变量 */
exec sql begin declare section;
char *usrname = "scott";
char *passwd = "11";
char *serverid = "orcl";
char sql_stat[100];
char current_date[20];
exec sql end declare section;
void sql_error(void);
void connet(void);
void process_input(void);
void process_output(void);
int main(void)
{
/* 安装错误处理句柄 */
exec sql whenever sqlerror do sql_error();
/* 连接到数据库 */
connet();
/*
* 分配输入描述区和输出描述区
* Ansi定义了该套标准,proc程序开发者按标准实现了它
* 这两条语句在proc编译的时候会开辟对应大小的存储空间
*/
exec sql allocate descriptor 'input_descriptor'; //用来存储输入的宿主变量
exec sql allocate descriptor 'output_descriptor'; //用来缓存数据库端返回的结果集
for ( ; ; ) {
printf("\n请输入动态SQL语句(EXIT:退出):\n");
gets(sql_stat);
/* EXIT(exit)->退出 */
if(0 == strncmp(sql_stat , "EXIT" , 4) || 0 == strncmp(sql_stat , "exit" , 4))
break;
/* 准备动态SQL语句 */
exec sql prepare s from :sql_stat;
/* 定义游标 */
exec sql declare c cursor for s;
/* 处理绑定变量 , 即处理占位符 “&” */
process_input();
/*
* 打开游标成功 意寓着结果已经被保存到输出描述区了。
* select语句:处理查询结果
* 其他SQL语句:执行
*/
exec sql open c using descriptor 'input_descriptor';
if(0 == strncmp(sql_stat , "SELECT" , 6) , 0 == strncmp(sql_stat , "select" , 6)) {
process_output();
}
/* 关闭游标 */
exec sql close c;
}
/* 释放输入描述区和输出描述区 */
exec sql deallocate descriptor 'input_descriptor';
exec sql deallocate descriptor 'output_descriptor';
/* 提交事务,断开连接 */
exec sql commit work release;
puts("谢谢使用ANSI动态SQL!\n");
return 0;
}
void sql_error(void)
{
/* 显示SQL错误号、错误描述 */
printf("%.*s\n" , sqlca.sqlerrm.sqlerrml , sqlca.sqlerrm.sqlerrmc);
exit(1);
}
void process_input(void)
{
int i;
/* 定义宿主变量 */
exec sql begin declare section;
int input_count;
int input_type ;
int input_len;
char input_buffer[MAX_VAR_LEN];
char name[MAX_NAME_LEN];
int occurs;
exec sql end declare section;
/* 绑定变量->输入描述区 */
exec sql describe input s using descriptor 'input_descriptor';
/* 取得绑定变量个数 */
exec sql get descriptor 'input_descriptor' :input_count = count;
/* 循环处理绑定变量名 */
for(i = 0 ; i != input_count ; ++i) {
occurs = i + 1;
/* 取得绑定变量名 */
exec sql get descriptor 'input_descriptor' value :occurs :name = name;
printf("请输入%s的值:" , name);
gets(input_buffer);
/* 以NULL结尾 */
input_len = strlen(input_buffer);
input_buffer[input_len] = '\0';
/* 设置绑定变量类型、长度和值 */
input_type = 1;
exec sql set descriptor 'input_descriptor' value :occurs
type = :input_type , length = :input_len , data = :input_buffer;
}
}
void process_output(void)
{
int i;
// 定义宿主变量
EXEC SQL BEGIN DECLARE SECTION ;
int output_count;
int output_type;
int output_len;
char output_buffer[MAX_VAR_LEN];
short output_indicator;
char name[MAX_NAME_LEN];
int occurs;
EXEC SQL END DECLARE SECTION ;
// 选择列表项->输出描述区
exec sql describe output s using descriptor 'output_descriptor';
//取得选择列表项个数
exec sql get descriptor 'output_descriptor' :output_count = count;
//循环处理选择列表项(即列名,或者叫表头)
output_type = 12; //设置类型为变长字符串varchar
for(i = 0 ; i != output_count ; ++i) {
occurs = i + 1;
output_len = MAX_VAR_LEN;
// 设置选择列表项的类型和长度(设置每一列,按照varchar类型进行显示)
exec sql set descriptor 'output_descriptor' value :occurs
type = :output_type , length = :output_len;
//取得选择列表项的名称并输出
exec sql get descriptor 'output_descriptor' value :occurs :name = name;
//显示选择列表项名称
printf("\t%s" , name);
}
printf("\n");
// 提取数据完毕->退出循环
exec sql whenever not found do break;
// 循环处理选择列表项数据
for ( ; ; ) {
// 行数据-> fetch into 利用游标从输出描述区读取数据。
exec sql fetch c into descriptor 'output_descriptor';
// 循环处理每列数据
for (i = 0 ; i < output_count ; ++i) {
occurs = i + 1;
// 取得列数据和指示变量值
exec sql get descriptor 'output_descriptor' VALUE :occurs
:output_buffer = DATA , :output_indicator = INDICATOR;
//输出列数据
if (-1 == output_indicator)
printf("\t%s", " ");
else
printf("\t%s" , output_buffer);
}
printf("\n");
}
}
void connet(void)
{
int ret = 0;
//连接数据库
EXEC SQL CONNECT:usrname IDENTIFIED BY:passwd USING:serverid ;
if (sqlca.sqlcode != 0) {
ret = sqlca.sqlcode;
printf("sqlca.sqlcode: err:%d \n", sqlca.sqlcode);
return ;
} else {
printf("connect ok...\n");
}
}
2.4.2Oracle实现方式
/*******************************************************************
Sample Program 10: Dynamic SQL Method 4
This program connects you to ORACLE using your username and
password, then prompts you for a SQL statement. You can enter
any legal SQL statement. Use regular SQL syntax, not embedded SQL.
Your statement will be processed. If it is a query, the rows
fetched are displayed.
You can enter multiline statements. The limit is 1023 characters.
This sample program only processes up to MAX_ITEMS bind variables and
MAX_ITEMS select-list items. MAX_ITEMS is #defined to be 40.
*******************************************************************/
#include
#include
#include
#include
#include
#include
#define SQL_SINGLE_RCTX ((void *)0)
/* Maximum number of select-list items or bind variables. */
#define MAX_ITEMS 40
/* Maximum lengths of the _names_ of the
select-list items or indicator variables. */
#define MAX_VNAME_LEN 30
#define MAX_INAME_LEN 30
#ifndef NULL
#define NULL 0
#endif
/* Prototypes */
#if defined(__STDC__)
void sql_error(void);
int oracle_connect(void);
int alloc_descriptors(int, int, int);
int get_dyn_statement(void);
void set_bind_variables(void);
void process_select_list(void);
void help(void);
#else
void sql_error(/*_ void _*/);
int oracle_connect(/*_ void _*/);
int alloc_descriptors(/*_ int, int, int _*/);
int get_dyn_statement(/* void _*/);
void set_bind_variables(/*_ void -*/);
void process_select_list(/*_ void _*/);
void help(/*_ void _*/);
#endif
char *dml_commands[] = {"SELECT", "select", "INSERT", "insert",
"UPDATE", "update", "DELETE", "delete"};
EXEC SQL INCLUDE sqlda;
EXEC SQL INCLUDE sqlca;
EXEC SQL BEGIN DECLARE SECTION;
char dyn_statement[1024];
EXEC SQL VAR dyn_statement IS STRING(1024);
EXEC SQL END DECLARE SECTION;
SQLDA *bind_dp;
SQLDA *select_dp;
/* Define a buffer to hold longjmp state info. */
jmp_buf jmp_continue;
/* A global flag for the error routine. */
int parse_flag = 0;
void main()
{
int i;
/* Connect to the database. */
if (oracle_connect() != 0)
exit(1);
/* Allocate memory for the select and bind descriptors. */
if (alloc_descriptors(MAX_ITEMS, MAX_VNAME_LEN, MAX_INAME_LEN) != 0)
exit(1);
/* Process SQL statements. */
for (;;)
{
(void) setjmp(jmp_continue);
/* Get the statement. Break on "exit". */
if (get_dyn_statement() != 0)
break;
/* Prepare the statement and declare a cursor. */
EXEC SQL WHENEVER SQLERROR DO sql_error();
parse_flag = 1; /* Set a flag for sql_error(). */
EXEC SQL PREPARE S FROM :dyn_statement;
parse_flag = 0; /* Unset the flag. */
EXEC SQL DECLARE C CURSOR FOR S;
/* Set the bind variables for any placeholders in the
SQL statement. */
set_bind_variables();
/* Open the cursor and execute the statement.
* If the statement is not a query (SELECT), the
* statement processing is completed after the
* OPEN.
*/
EXEC SQL OPEN C USING DESCRIPTOR bind_dp;
/* Call the function that processes the select-list.
* If the statement is not a query, this function
* just returns, doing nothing.
*/
process_select_list();
/* Tell user how many rows processed. */
for (i = 0; i < 8; i++)
{
if (strncmp(dyn_statement, dml_commands[i], 6) == 0)
{
printf("\n\n%d row%c processed.\n", sqlca.sqlerrd[2],
sqlca.sqlerrd[2] == 1 ? '\0' : 's');
break;
}
}
} /* end of for(;;) statement-processing loop */
/* When done, free the memory allocated for
pointers in the bind and select descriptors. */
for (i = 0; i < MAX_ITEMS; i++)
{
if (bind_dp->V[i] != (char *) 0)
free(bind_dp->V[i]);
free(bind_dp->I[i]); /* MAX_ITEMS were allocated. */
if (select_dp->V[i] != (char *) 0)
free(select_dp->V[i]);
free(select_dp->I[i]); /* MAX_ITEMS were allocated. */
}
/* Free space used by the descriptors themselves. */
SQLSQLDAFree(SQL_SINGLE_RCTX, bind_dp);
SQLSQLDAFree(SQL_SINGLE_RCTX, select_dp);
EXEC SQL WHENEVER SQLERROR CONTINUE;
/* Close the cursor. */
EXEC SQL CLOSE C;
EXEC SQL COMMIT WORK RELEASE;
puts("\nHave a good day!\n");
EXEC SQL WHENEVER SQLERROR DO sql_error();
return;
}
int oracle_connect()
{
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR username[128];
VARCHAR password[32];
EXEC SQL END DECLARE SECTION;
printf("\nusername: ");
fgets((char *) username.arr, sizeof username.arr, stdin);
username.arr[strlen((char *) username.arr)-1] = '\0';
username.len = (unsigned short)strlen((char *) username.arr);
printf("password: ");
fgets((char *) password.arr, sizeof password.arr, stdin);
password.arr[strlen((char *) password.arr) - 1] = '\0';
password.len = (unsigned short)strlen((char *) password.arr);
EXEC SQL WHENEVER SQLERROR GOTO connect_error;
EXEC SQL CONNECT :username IDENTIFIED BY :password;
printf("\nConnected to ORACLE as user %s.\n", username.arr);
return 0;
connect_error:
fprintf(stderr, "Cannot connect to ORACLE as user %s\n", username.arr);
return -1;
}
/*
* Allocate the BIND and SELECT descriptors using SQLSQLDAAlloc().
* Also allocate the pointers to indicator variables
* in each descriptor. The pointers to the actual bind
* variables and the select-list items are realloc'ed in
* the set_bind_variables() or process_select_list()
* routines. This routine allocates 1 byte for select_dp->V[i]
* and bind_dp->V[i], so the realloc will work correctly.
*/
alloc_descriptors(size, max_vname_len, max_iname_len)
int size;
int max_vname_len;
int max_iname_len;
{
int i;
/*
* The first SQLSQLDAAlloc parameter is the runtime context.
* The second parameter determines the maximum number of
* array elements in each variable in the descriptor. In
* other words, it determines the maximum number of bind
* variables or select-list items in the SQL statement.
*
* The third parameter determines the maximum length of
* strings used to hold the names of select-list items
* or placeholders. The maximum length of column
* names in ORACLE is 30, but you can allocate more or less
* as needed.
*
* The fourth parameter determines the maximum length of
* strings used to hold the names of any indicator
* variables. To follow ORACLE standards, the maximum
* length of these should be 30. But, you can allocate
* more or less as needed.
*/
if ((bind_dp =
SQLSQLDAAlloc(SQL_SINGLE_RCTX, size, max_vname_len, max_iname_len)) ==
(SQLDA *) 0)
{
fprintf(stderr,
"Cannot allocate memory for bind descriptor.");
return -1; /* Have to exit in this case. */
}
if ((select_dp =
SQLSQLDAAlloc (SQL_SINGLE_RCTX, size, max_vname_len, max_iname_len)) ==
(SQLDA *) 0)
{
fprintf(stderr,
"Cannot allocate memory for select descriptor.");
return -1;
}
select_dp->N = MAX_ITEMS;
/* Allocate the pointers to the indicator variables, and the
actual data. */
for (i = 0; i < MAX_ITEMS; i++) {
bind_dp->I[i] = (short *) malloc(sizeof (short));
select_dp->I[i] = (short *) malloc(sizeof(short));
bind_dp->V[i] = (char *) malloc(1);
select_dp->V[i] = (char *) malloc(1);
}
return 0;
}
int get_dyn_statement()
{
char *cp, linebuf[256];
int iter, plsql;
for (plsql = 0, iter = 1; ;)
{
if (iter == 1)
{
printf("\nSQL> ");
dyn_statement[0] = '\0';
}
fgets(linebuf, sizeof linebuf, stdin);
cp = strrchr(linebuf, '\n');
if (cp && cp != linebuf)
*cp = ' ';
else if (cp == linebuf)
continue;
if ((strncmp(linebuf, "EXIT", 4) == 0) ||
(strncmp(linebuf, "exit", 4) == 0))
{
return -1;
}
else if (linebuf[0] == '?' ||
(strncmp(linebuf, "HELP", 4) == 0) ||
(strncmp(linebuf, "help", 4) == 0))
{
help();
iter = 1;
continue;
}
if (strstr(linebuf, "BEGIN") ||
(strstr(linebuf, "begin")))
{
plsql = 1;
}
strcat(dyn_statement, linebuf);
if ((plsql && (cp = strrchr(dyn_statement, '/'))) ||
(!plsql && (cp = strrchr(dyn_statement, ';'))))
{
*cp = '\0';
break;
}
else
{
iter++;
printf("%3d ", iter);
}
}
return 0;
}
void set_bind_variables()
{
int i, n;
char bind_var[64];
/* Describe any bind variables (input host variables) */
EXEC SQL WHENEVER SQLERROR DO sql_error();
bind_dp->N = MAX_ITEMS; /* Initialize count of array elements. */
EXEC SQL DESCRIBE BIND VARIABLES FOR S INTO bind_dp;
/* If F is negative, there were more bind variables
than originally allocated by SQLSQLDAAlloc(). */
if (bind_dp->F < 0) {
printf ("\nToo many bind variables (%d), maximum is %d\n.",
-bind_dp->F, MAX_ITEMS);
return;
}
/* Set the maximum number of array elements in the
descriptor to the number found. */
bind_dp->N = bind_dp->F;
/* Get the value of each bind variable as a
* character string.
*
* C[i] contains the length of the bind variable
* name used in the SQL statement.
* S[i] contains the actual name of the bind variable
* used in the SQL statement.
*
* L[i] will contain the length of the data value
* entered.
*
* V[i] will contain the address of the data value
* entered.
*
* T[i] is always set to 1 because in this sample program
* data values for all bind variables are entered
* as character strings.
* ORACLE converts to the table value from CHAR.
*
* I[i] will point to the indicator value, which is
* set to -1 when the bind variable value is "null".
*/
for (i = 0; i < bind_dp->F; i++) {
printf ("\nEnter value for bind variable %.*s: ",
(int)bind_dp->C[i], bind_dp->S[i]);
fgets(bind_var, sizeof bind_var, stdin);
/* Get length and remove the new line character. */
n = strlen(bind_var) - 1;
/* Set it in the descriptor. */
bind_dp->L[i] = n;
/* (re-)allocate the buffer for the value.
SQLSQLDAAlloc() reserves a pointer location for
V[i] but does not allocate the full space for
the pointer. */
bind_dp->V[i] = (char *) realloc(bind_dp->V[i],
(bind_dp->L[i] + 1));
/* And copy it in. */
strncpy(bind_dp->V[i], bind_var, n);
/* Set the indicator variable's value. */
if ((strncmp(bind_dp->V[i], "NULL", 4) == 0) ||
(strncmp(bind_dp->V[i], "null", 4) == 0))
*bind_dp->I[i] = -1;
else
*bind_dp->I[i] = 0;
/* Set the bind datatype to 1 for CHAR. */
bind_dp->T[i] = 1;
}
return;
}
void process_select_list()
{
int i, null_ok, precision, scale;
if ((strncmp(dyn_statement, "SELECT", 6) != 0) &&
(strncmp(dyn_statement, "select", 6) != 0))
{
select_dp->F = 0;
return;
}
/* If the SQL statement is a SELECT, describe the
select-list items. The DESCRIBE function returns
their names, datatypes, lengths (including precision
and scale), and NULL/NOT NULL statuses. */
select_dp->N = MAX_ITEMS;
EXEC SQL DESCRIBE SELECT LIST FOR S INTO select_dp;
/* If F is negative, there were more select-list
items than originally allocated by SQLSQLDAAlloc(). */
if (select_dp->F < 0)
{
printf ("\nToo many select-list items (%d), maximum is %d\n",
-(select_dp->F), MAX_ITEMS);
return;
}
/* Set the maximum number of array elements in the
descriptor to the number found. */
select_dp->N = select_dp->F;
/* Allocate storage for each select-list item.
SQLNumberPrecV6() is used to extract precision and scale
from the length (select_dp->L[i]).
sqlcolumnNullCheck() is used to reset the high-order bit of
the datatype and to check whether the column
is NOT NULL.
CHAR datatypes have length, but zero precision and
scale. The length is defined at CREATE time.
NUMBER datatypes have precision and scale only if
defined at CREATE time. If the column
definition was just NUMBER, the precision
and scale are zero, and you must allocate
the required maximum length.
DATE datatypes return a length of 7 if the default
format is used. This should be increased to
9 to store the actual date character string.
If you use the TO_CHAR function, the maximum
length could be 75, but will probably be less
(you can see the effects of this in SQL*Plus).
ROWID datatype always returns a fixed length of 18 if
coerced to CHAR.
LONG and
LONG RAW datatypes return a length of 0 (zero),
so you need to set a maximum. In this example,
it is 240 characters.
*/
printf ("\n");
for (i = 0; i < select_dp->F; i++)
{
char title[MAX_VNAME_LEN];
/* Turn off high-order bit of datatype (in this example,
it does not matter if the column is NOT NULL). */
SQLColumnNullCheck (0, (unsigned short *)&(select_dp->T[i]),
(unsigned short *)&(select_dp->T[i]), &null_ok);
switch (select_dp->T[i])
{
case 1 : /* CHAR datatype: no change in length
needed, except possibly for TO_CHAR
conversions (not handled here). */
break;
case 2 : /* NUMBER datatype: use SQLNumberPrecV6() to
extract precision and scale. */
SQLNumberPrecV6( SQL_SINGLE_RCTX,
(unsigned long *)&(select_dp->L[i]), &precision, &scale);
/* Allow for maximum size of NUMBER. */
if (precision == 0) precision = 40;
/* Also allow for decimal point and
possible sign. */
/* convert NUMBER datatype to FLOAT if scale > 0,
INT otherwise. */
if (scale > 0)
select_dp->L[i] = sizeof(float);
else
select_dp->L[i] = sizeof(int);
break;
case 8 : /* LONG datatype */
select_dp->L[i] = 240;
break;
case 11 : /* ROWID datatype */
select_dp->L[i] = 18;
break;
case 12 : /* DATE datatype */
select_dp->L[i] = 9;
break;
case 23 : /* RAW datatype */
break;
case 24 : /* LONG RAW datatype */
select_dp->L[i] = 240;
break;
}
/* Allocate space for the select-list data values.
SQLSQLDAAlloc() reserves a pointer location for
V[i] but does not allocate the full space for
the pointer. */
if (select_dp->T[i] != 2)
select_dp->V[i] = (char *) realloc(select_dp->V[i],
select_dp->L[i] + 1);
else
select_dp->V[i] = (char *) realloc(select_dp->V[i],
select_dp->L[i]);
/* Print column headings, right-justifying number
column headings. */
/* Copy to temporary buffer in case name is null-terminated */
memset(title, ' ', MAX_VNAME_LEN);
strncpy(title, select_dp->S[i], select_dp->C[i]);
if (select_dp->T[i] == 2)
if (scale > 0)
printf ("%.*s ", select_dp->L[i]+3, title);
else
printf ("%.*s ", select_dp->L[i], title);
else
printf("%-.*s ", select_dp->L[i], title);
/* Coerce ALL datatypes except for LONG RAW and NUMBER to
character. */
if (select_dp->T[i] != 24 && select_dp->T[i] != 2)
select_dp->T[i] = 1;
/* Coerce the datatypes of NUMBERs to float or int depending on
the scale. */
if (select_dp->T[i] == 2)
if (scale > 0)
select_dp->T[i] = 4; /* float */
else
select_dp->T[i] = 3; /* int */
}
printf ("\n\n");
/* FETCH each row selected and print the column values. */
EXEC SQL WHENEVER NOT FOUND GOTO end_select_loop;
for (;;)
{
EXEC SQL FETCH C USING DESCRIPTOR select_dp;
/* Since each variable returned has been coerced to a
character string, int, or float very little processing
is required here. This routine just prints out the
values on the terminal. */
for (i = 0; i < select_dp->F; i++)
{
if (*select_dp->I[i] < 0)
if (select_dp->T[i] == 4)
printf ("%-*c ",(int)select_dp->L[i]+3, ' ');
else
printf ("%-*c ",(int)select_dp->L[i], ' ');
else
if (select_dp->T[i] == 3) /* int datatype */
printf ("%*d ", (int)select_dp->L[i],
*(int *)select_dp->V[i]);
else if (select_dp->T[i] == 4) /* float datatype */
printf ("%*.2f ", (int)select_dp->L[i],
*(float *)select_dp->V[i]);
else /* character string */
printf ("%-*.*s ", (int)select_dp->L[i],
(int)select_dp->L[i], select_dp->V[i]);
}
printf ("\n");
}
end_select_loop:
return;
}
void help()
{
puts("\n\nEnter a SQL statement or a PL/SQL block at the SQL> prompt.");
puts("Statements can be continued over several lines, except");
puts("within string literals.");
puts("Terminate a SQL statement with a semicolon.");
puts("Terminate a PL/SQL block (which can contain embedded semicolons)");
puts("with a slash (/).");
puts("Typing \"exit\" (no semicolon needed) exits the program.");
puts("You typed \"?\" or \"help\" to get this message.\n\n");
}
void sql_error()
{
/* ORACLE error handler */
printf ("\n\n%.70s\n",sqlca.sqlerrm.sqlerrmc);
if (parse_flag)
printf
("Parse error at character offset %d in SQL statement.\n",
sqlca.sqlerrd[4]);
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL ROLLBACK WORK;
longjmp(jmp_continue, 1);
}