机器学习工程师纳米学位
模型评价与验证
项目 : 预测波士顿房价
第一步. 导入数据
在这个项目中,你将利用马萨诸塞州波士顿郊区的房屋信息数据训练和测试一个模型,并对模型的性能和预测能力进行测试。通过该数据训练后的好的模型可以被用来对房屋做特定预测---尤其是对房屋的价值。对于房地产经纪等人的日常工作来说,这样的预测模型被证明非常有价值。
此项目的数据集来自UCI机器学习知识库(数据集已下线)。波士顿房屋这些数据于1978年开始统计,共506个数据点,涵盖了麻省波士顿不同郊区房屋14种特征的信息。本项目对原始数据集做了以下处理:
- 有16个
'MEDV'值为50.0的数据点被移除。 这很可能是由于这些数据点包含遗失或看不到的值。 - 有1个数据点的
'RM'值为8.78. 这是一个异常值,已经被移除。 - 对于本项目,房屋的
'RM','LSTAT','PTRATIO'以及'MEDV'特征是必要的,其余不相关特征已经被移除。 -
'MEDV'特征的值已经过必要的数学转换,可以反映35年来市场的通货膨胀效应。
运行下面区域的代码以载入波士顿房屋数据集,以及一些此项目所需的 Python 库。如果成功返回数据集的大小,表示数据集已载入成功。
# Import libraries necessary for this project
import numpy as np
import pandas as pd
from sklearn.model_selection import ShuffleSplit
# Import supplementary visualizations code visuals.py
import visuals as vs
# Pretty display for notebooks
%matplotlib inline
# Load the Boston housing dataset
data = pd.read_csv('housing.csv')
prices = data['MEDV']
features = data.drop('MEDV', axis = 1)
# Success
print("Boston housing dataset has {} data points with {} variables each.".format(*data.shape))
Boston housing dataset has 489 data points with 4 variables each.
第二步. 分析数据
在项目的第一个部分,你会对波士顿房地产数据进行初步的观察并给出你的分析。通过对数据的探索来熟悉数据可以让你更好地理解和解释你的结果。
由于这个项目的最终目标是建立一个预测房屋价值的模型,我们需要将数据集分为特征(features)和目标变量(target variable)。
- 特征
'RM','LSTAT',和'PTRATIO',给我们提供了每个数据点的数量相关的信息。 - 目标变量:
'MEDV',是我们希望预测的变量。
他们分别被存在 features 和 prices 两个变量名中。
编程练习 1:基础统计运算
你的第一个编程练习是计算有关波士顿房价的描述统计数据。我们已为你导入了 NumPy,你需要使用这个库来执行必要的计算。这些统计数据对于分析模型的预测结果非常重要的。
在下面的代码中,你要做的是:
- 计算
prices中的'MEDV'的最小值、最大值、均值、中值和标准差; - 将运算结果储存在相应的变量中。
# TODO: Minimum price of the data
minimum_price =prices.min() # or np.min(prices, 0)
# TODO: Maximum price of the data
maximum_price =prices.max() # or np.max(prices, 0)
# TODO: Mean price of the data
mean_price = prices.mean() #or np.mean(prices, 0)
# TODO: Median price of the data
median_price = prices.median() #np.median(prices, 0)
# TODO: Standard deviation of prices of the data
std_price = prices.std() #np.std(prices,0)
# Show the calculated statistics
print("Statistics for Boston housing dataset:\n")
print("Minimum price: ${:.2f}".format(minimum_price))
print("Maximum price: ${:.2f}".format(maximum_price))
print("Mean price: ${:.2f}".format(mean_price))
print("Median price ${:.2f}".format(median_price))
print("Standard deviation of prices: ${:.2f}".format(std_price))
Statistics for Boston housing dataset:
Minimum price: $105000.00
Maximum price: $1024800.00
Mean price: $454342.94
Median price $438900.00
Standard deviation of prices: $165340.28
问题 1 - 特征观察
如前文所述,本项目中我们关注的是其中三个值:'RM'、'LSTAT' 和'PTRATIO',对每一个数据点:
-
'RM'是该地区中每个房屋的平均房间数量; -
'LSTAT'是指该地区有多少百分比的业主属于是低收入阶层(有工作但收入微薄); -
'PTRATIO'是该地区的中学和小学里,学生和老师的数目比(学生/老师)。
凭直觉,上述三个特征中对每一个来说,你认为增大该特征的数值,'MEDV'的值会是增大还是减小呢?每一个答案都需要你给出理由。
提示:你预期一个'RM' 值是6的房屋跟'RM' 值是7的房屋相比,价值更高还是更低呢?
问题 1 - 回答:
使用数据可视化的方式可以直观的观察出特征和结果之间的关系。现在已知数据集中的单个样本具备三个特征,可以分别画出三个特征和结果值的散点图,观察其关系。
data.plot.scatter('RM','MEDV', c='red')
data.plot.scatter('LSTAT', 'MEDV', c='green')
data.plot.scatter('PTRATIO', 'MEDV', c='blue');
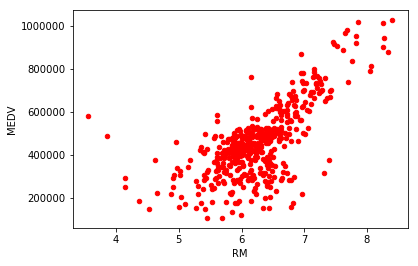
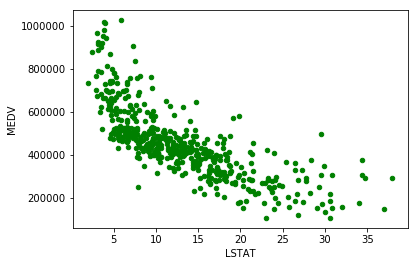
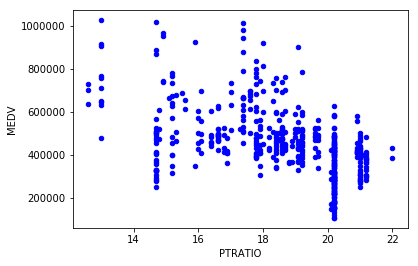
通过散点图,可以很明显的看出来,RM值与price基本上成正比例关系,而LSTAT值和price可近似的看做反比关系;值得注意的是,PTRATIO值无法直接从散点图中观察出来其与price之间的关系,但隐约可以看出,在价格低于600000的区间内,PTRATIO分布的比较密集。
第三步. 建立模型
在项目的第三步中,你需要了解必要的工具和技巧来让你的模型进行预测。用这些工具和技巧对每一个模型的表现做精确的衡量可以极大地增强你预测的信心。
编程练习2:定义衡量标准
如果不能对模型的训练和测试的表现进行量化地评估,我们就很难衡量模型的好坏。通常我们会定义一些衡量标准,这些标准可以通过对某些误差或者拟合程度的计算来得到。在这个项目中,你将通过运算决定系数 R^2 来量化模型的表现。模型的决定系数是回归分析中十分常用的统计信息,经常被当作衡量模型预测能力好坏的标准。
R^2 的数值范围从0至1,表示目标变量的预测值和实际值之间的相关程度平方的百分比。一个模型的 R^2 值为0还不如直接用平均值来预测效果好;而一个 R^2 值为1的模型则可以对目标变量进行完美的预测。从0至1之间的数值,则表示该模型中目标变量中有百分之多少能够用特征来解释。模型也可能出现负值的 R^2,这种情况下模型所做预测有时会比直接计算目标变量的平均值差很多。
在下方代码的 performance_metric 函数中,你要实现:
- 使用
sklearn.metrics中的r2_score来计算y_true和y_predict的 R^2 值,作为对其表现的评判。 - 将他们的表现评分储存到
score变量中。
# TODO: Import 'r2_score'
from sklearn.metrics import r2_score
def performance_metric(y_true, y_predict):
""" Calculates and returns the performance score between
true and predicted values based on the metric chosen. """
# TODO: Calculate the performance score between 'y_true' and 'y_predict'
score = r2_score(y_true, y_predict)
# Return the score
return score
问题 2 - 拟合程度
假设一个数据集有五个数据且一个模型做出下列目标变量的预测:
| 真实数值 | 预测数值 |
|---|---|
| 3.0 | 2.5 |
| -0.5 | 0.0 |
| 2.0 | 2.1 |
| 7.0 | 7.8 |
| 4.2 | 5.3 |
你觉得这个模型已成功地描述了目标变量的变化吗?如果成功,请解释为什么,如果没有,也请给出原因。
提示1:运行下方的代码,使用 performance_metric 函数来计算 y_true 和 y_predict 的决定系数。
提示2:R^2 分数是指可以从自变量中预测的因变量的方差比例。 换一种说法:
- R^2 为0意味着因变量不能从自变量预测。
- R^2 为1意味着可以从自变量预测因变量。
- R^2 在0到1之间表示因变量可预测的程度。
- R^2 为0.40意味着 Y 中40%的方差可以从 X 预测。
# Calculate the performance of this model
score = performance_metric([3, -0.5, 2, 7, 4.2], [2.5, 0.0, 2.1, 7.8, 5.3])
print("Model has a coefficient of determination, R^2, of {:.3f}.".format(score))
Model has a coefficient of determination, R^2, of 0.923.
对R^2的分析反馈:
我认为:如果是在一元回归分析中这个模型一定程度上描述了目标变量的变化,但是还不够成功,因为还存在较大的误差,不过模型的好坏最终还是要分析的具体问题。如果是在多元回归分析中,虽然我们得到了0.923这个看上去不错的R^2分数,但是不排除还有其他特征也会对目标值有很大的影响,很难去判断模型是否成功,但是但就对当前要评估的特征来讲,0.923的分数意味着当前评判的这些特征对输出值有相当很高的的解释程度,因变量Y(输出值)中92.3%的方差可以从当前的特征来预测。放在上面的问题中,0.923得R^2分数事实上也并不能让我们很满意,因为我们要预测的是具体的数值。
问题 2 - 回答:
编程练习 3: 数据分割与重排
接下来,你需要把波士顿房屋数据集分成训练和测试两个子集。通常在这个过程中,数据也会被重排列,以消除数据集中由于顺序而产生的偏差。
在下面的代码中,你需要
- 使用
sklearn.model_selection中的train_test_split, 将features和prices的数据都分成用于训练的数据子集和用于测试的数据子集。- 分割比例为:80%的数据用于训练,20%用于测试;
- 选定一个数值以设定
train_test_split中的random_state,这会确保结果的一致性;
- 将分割后的训练集与测试集分配给
X_train,X_test,y_train和y_test。
# TODO: Import 'train_test_split'
from sklearn.model_selection import train_test_split
# TODO: Shuffle and split the data into training and testing subsets
X_train, X_test, y_train, y_test = train_test_split(features, prices, test_size=0.2)
# Success
print("Training and testing split was successful.")
Training and testing split was successful.
问题 3 - 训练及测试
将数据集按一定比例分为训练用的数据集和测试用的数据集对学习算法有什么好处?
如果用模型已经见过的数据,例如部分训练集数据进行测试,又有什么坏处?
提示: 如果没有数据来对模型进行测试,会出现什么问题?
问题 3 - 回答:
划分训练集和测试集的好处在于,我们可以近似的求出模型的泛化误差,帮助我们评估模型的泛化能力。
我们总是希望得到泛化误差比较小的模型,但是泛化误差在训练中是无法得到的,因为永远也不知道新的数据到底是个什么样子。但是我们可以对泛化误差进行评估,评估的方法就是把数据集分为训练集和测试集两部分,常见的办法有留出法,交叉验证法(包含留一法)和自助法(适合小规模的数据),他们的原理就是从数据集中拿出一部部分数据,这部分数据不参加训练,用来充当新的数据,进而评估在模型在当前数据集中的表现,通过测试误差近似的代表其泛化误差,但是要注意要在分割的时候保持数据分布的一致性。
违背黄金法则就意味着最终会得到不准确的测试误差,我们对模型的泛化能力评估在很大程度上失去了意义。
这里有一条黄金法则:测试集中的样本永远都不可以参加训练,因为一旦测试集中的样本参加了训练,就等于污染了训练集,训练中已经习得了新数据的特性,甚至在过拟合的情况下完全记住了这些样本,之后再遇到这些样本,结果可想而知,测试已经失去了测试的意义;这就好比我们要检验一个学生的真实能力,但是在试卷中除了了很多学生训练过的原题,但是同样的道理换一个题型,学生还会不会解我们依旧不知道,学生的能力到底有多强,也就很难判断了。
第四步. 分析模型的表现
在项目的第四步,我们来看一下不同参数下,模型在训练集和验证集上的表现。这里,我们专注于一个特定的算法(带剪枝的决策树,但这并不是这个项目的重点),和这个算法的一个参数 'max_depth'。用全部训练集训练,选择不同'max_depth' 参数,观察这一参数的变化如何影响模型的表现。画出模型的表现来对于分析过程十分有益。
学习曲线
下方区域内的代码会输出四幅图像,它们是一个决策树模型在不同最大深度下的表现。每一条曲线都直观得显示了随着训练数据量的增加,模型学习曲线的在训练集评分和验证集评分的变化,评分使用决定系数 R^2。曲线的阴影区域代表的是该曲线的不确定性(用标准差衡量)。
运行下方区域中的代码,并利用输出的图形回答下面的问题。
# Produce learning curves for varying training set sizes and maximum depths
vs.ModelLearning(features, prices)
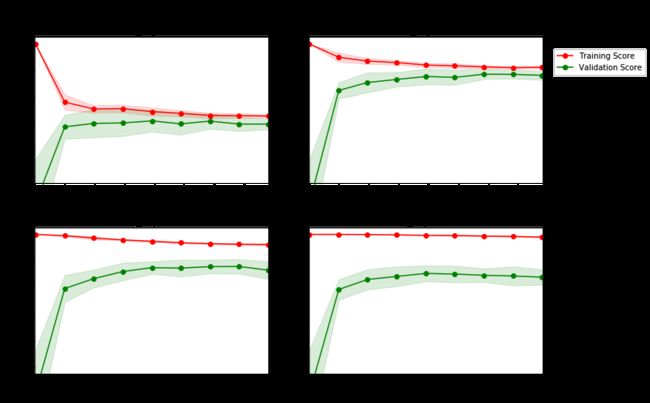
问题 4 - 学习曲线
- 选择上述图像中的其中一个,并给出其最大深度。
- 随着训练数据量的增加,训练集曲线的评分有怎样的变化?验证集曲线呢?
- 如果有更多的训练数据,是否能有效提升模型的表现呢?
提示:学习曲线的评分是否最终会收敛到特定的值?一般来说,你拥有的数据越多,模型表现力越好。但是,如果你的训练和测试曲线以高于基准阈值的分数收敛,这是否有必要?基于训练和测试曲线已经收敛的前提下,思考添加更多训练点的优缺点。
模型2使用的最大深度为3,随着训练样本的增加,训练集的r^2值和测试集的R^2值最终都比较接近0.8。
随着训练数据量(训练样本)的增加,训练集曲线的评分有不断减小的趋势,最终会趋向于一条直线,不过幅度越来越小。相对应的测试集的R^2值会逐渐的
增大,但最终也会和训练集曲线那样最终趋向于一条直线。有足够大的训练集是一件好事,这就意味着可以在学习过程中学习的更加全面,就像一个经验丰富的大人肯定会比一个小学生更会处理事务;但从曲线图可以看
出来,训练集也并非越大越好,在一定程度上,数据集大小达到某一个阙值之后,最终的在训练集上的误差会趋向于平稳,这个时候再去增加数据量意义不大反而
会影响的训练的效率;而这个阙值的大小取决于模型,有的模型对训练集里的数据学习的很全面,以至于快要记住所有数据了,就像上面的表4,这样的模型在训练
集中表现很好但是在测试集上未必会有较高的精度,因为他过度的学习了训练集,以至于泛化能力下降,这也就是常说的过拟合。合适的模型应该像表2中那样,既
不会丢失掉一些特征,又不会过度学习,综合来讲训练效率较高,最终得到的模型泛化能力较强。当然,单纯的根据训练误差来评估一个模型的泛化性能是远远不够的,还需要对泛化能力进行评估。
问题 4 - 回答:
复杂度曲线
下列代码内的区域会输出一幅图像,它展示了一个已经经过训练和验证的决策树模型在不同最大深度条件下的表现。这个图形将包含两条曲线,一个是训练集的变化,一个是验证集的变化。跟学习曲线相似,阴影区域代表该曲线的不确定性,模型训练和测试部分的评分都用的 performance_metric 函数。
运行下方区域中的代码,并利用输出的图形并回答下面的问题5与问题6。
vs.ModelComplexity(X_train, y_train)
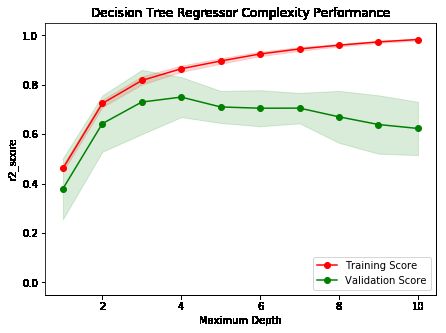
问题 5 - 偏差(bias)与方差(variance)之间的权衡取舍
- 当模型以最大深度 1训练时,模型的预测是出现很大的偏差还是出现了很大的方差?
- 当模型以最大深度10训练时,情形又如何呢?
- 图形中的哪些特征能够支持你的结论?
提示: 高偏差表示欠拟合(模型过于简单),而高方差表示过拟合(模型过于复杂,以至于无法泛化)。考虑哪种模型(深度1或10)对应着上述的情况,并权衡偏差与方差。
问题 5 - 回答:
当模型以最大深度1训练的时候,模型的预测出现了比较大的偏差,因为阴影区域代表该曲线的不确定性,当深度为一时,阴影区域的跨度最大,此时的模型不确定因素太大,换句话说,也就是精度较低,算法的拟合能力较差。
当模型以最大深度10训练的时候,模型的预测出现了比较大的方差,因为训练集合测试集之间的距离更大,模型这个时候已经过拟合,在测试集中泛化能力过差。以至于出现比较高的方差。
上述图形中当训练深度为3到4的时候,看上去训练效果最好,因为他使得模型的偏差和方差取得了平衡。根据上图可以看出,偏差和方差之间是存在冲突的,我们希望取得最小的方差和偏差,只有深度为4的时候,方差和偏差同时最小。
问题 6- 最优模型的猜测
- 结合问题 5 中的图,你认为最大深度是多少的模型能够最好地对未见过的数据进行预测?
- 你得出这个答案的依据是什么?
提示:查看问题5上方的图表,并查看模型在不同 depth下的验证分数。随着深度的增加模型的表现力会变得更好吗?我们在什么情况下获得最佳验证分数而不会使我们的模型过度复杂?请记住,奥卡姆剃刀:“在竞争性假设中,应该选择假设最少的那一个。”
问题 6 - 回答:
- 我认为最大深度为3的时候,模型能够最好的对未见到的数据进行预测。
- 随着深度的增加,模型的表现力并不会变得越来越好,其主要原因就是因为学习过于深入,以至于把很多不必要的特征拿来对新数据进行预测,最终导致泛化能力变差,所以也并非模型越复杂得到的结果就越让人满意。奥卡姆提到原则的目的就是使复杂的问题简单化,尽量去排查那些不必要的特征的干扰。但是卡奥姆提到原则也不是永远正确的,天下没有免费的午餐(NFL)定理就证明了,在所有问题同等重要的情况下,误差和算法是无关的。到底应该去选择什么样的模型,还应该具体问题具体对待,放到这里来讲,我们对波士顿房价数据的三个特征和最终的因变量房价进行了对比,模型最终是否能够解决这个问题,取决于模型对这三个特征的归纳和偏好是否与实际情况相匹配,而不是取决于用什么样的算法。
第五步. 评估模型的表现
在项目的最后一节中,你将构建一个模型,并使用 fit_model 中的优化模型去预测客户特征集。
问题 7- 网格搜索(Grid Search)
- 什么是网格搜索法?
- 如何用它来优化模型?
提示:在解释网格搜索算法时,首先要理解我们为什么使用网格搜索算法,以及我们使用它的最终目的是什么。为了使你的回答更具有说服力,你还可以给出一个模型中可以使用此方法进行优化参数的示例。
问题 7 - 回答:
有的问题很复杂,特征很多,使用当前算法进行训练的时候要么过拟合,要么欠拟合,效果往往都不理想。针对当前的算法,我们不知道到底应该去选择什么样的参数,这个时候,最笨的办法就是把这些参数所有有可能的组合都去试一遍,这样就不用不停地手动调参了。
网格搜索法就是把当前要使用的算法所有参数的定义域进行组合,组合出很多可能,最后得到一个网格。比如某一个模型需要两个参数分别是,k(k=1or2), a
(a = 3 or 4), 得到的网格就是[(1,3)(1,4)(2,3)(2,4)];然后把这个网格里面的每一组参数拿到模型里面去进行训练,最后会得到一个最佳的参数组合。要用网格搜索法来优化模型,首先要知道对应的算法使用了哪些参数,哪些参数可以人工确定下来,哪些参数和问题没关系,那些参数是不确定的,然后再去使用网络搜索法,先生成网格,然后使用网格里的参数组合挨个进行训练(可能需要训练多次),这个时候还可以去泡杯茶品一品!比如k近邻算法在进行分类的时候,k的值就是邻居的数量,到底应该选几个邻居来比较呢?唯一的办法好像就是在可能的取值范围内测试k取值是多少的时候,习得模型的精度最高。
问题 8 - 交叉验证
- 什么是K折交叉验证法(k-fold cross-validation)?
- GridSearchCV 是如何结合交叉验证来完成对最佳参数组合的选择的?
- GridSearchCV 中的
'cv_results_'属性能告诉我们什么? - 网格搜索为什么要使用K折交叉验证?K折交叉验证能够避免什么问题?
提示:在解释k-fold交叉验证时,一定要理解'k'是什么,和数据集是如何分成不同的部分来进行训练和测试的,以及基于'k'值运行的次数。
在考虑k-fold交叉验证如何帮助网格搜索时,你可以使用特定的数据子集来进行训练与测试有什么缺点,以及K折交叉验证是如何帮助缓解这个问题。
问题 8 - 回答:
k折较差验证法,就是把一个数据集分为k份子集,这些子集互斥,每次训练的时候选择k-1个子集的并集作为训练集,另外一个作为测试集,一共进行这样k次训练和测试,最后返回k个结果,然后取这些结果的均值。
GridSearchCV有很多参数,其中estimator 参数是要进行调参的算法,param_grid 就是参数网格(以列表或者字典的形式输入,字典的键对应被调算法的参数名; scoring参数对应的被调算法的返回的评价标准,默认是误差估计函数);参数cv是指定较差验证的k值,默认是进行3折较差验证。它运行的原理就是,把参数放进来,然后把数据集分成cv份,对每一组参数进行cv次训练和测试,最后取均值;如果参数网格的空间大小是10,我们同时选择了进行10折较差验证,那么最终会进行100次训练和测试,返回10个结果。
GridSearchCV的cv_cv_results_是一个字典,在搜索完成之后会返回最优结果,这个最优结果内容包含些什么取决于我们指定的评估函数,通过指定scoring参数来设定,概括起来,他直接返回了最优参数组合,以及使用最优参数组合得到的训练和测试结果。
网格搜索之所以选择k折较差验证,是因为k折较差验证在k次训练之后可以保证数据集中的每一个样本都参与训练,从而确保每一组参数在参与训练的时候面对的训练集是一致的,最终保证搜索出来结果是可信服的,但是k折较差验证也有很大的缺点,那就是调参需要进行参数数目*k次的训练和测试,比较耗费性能,如果参数较多,参数的取值范围较大,步长太短,数据量太大,k的取值过大,任何一种情况都严重影响训练的效率。要解决这个问题,没有通用的法则,唯一的办法是根据具体问题和对被调算法的深入理解,排除掉一些不需要进入网格的参数,确定或缩小一些参数的取值范围,合理的取k值。
编程练习 4:拟合模型
在这个练习中,你将需要将所学到的内容整合,使用决策树算法训练一个模型。为了得出的是一个最优模型,你需要使用网格搜索法训练模型,以找到最佳的 'max_depth' 参数。你可以把'max_depth' 参数理解为决策树算法在做出预测前,允许其对数据提出问题的数量。决策树是监督学习算法中的一种。
另外,你会发现在实现的过程中是使用ShuffleSplit()作为交叉验证的另一种形式(参见'cv_sets'变量)。虽然它不是你在问题8中描述的K-fold交叉验证方法,但它同样非常有用!下面的ShuffleSplit()实现将创建10个('n_splits')混洗集合,并且对于每个混洗集,数据的20%('test_size')将被用作验证集合。当您在实现代码的时候,请思考一下它与 K-fold cross-validation 的不同与相似之处。
请注意,ShuffleSplit 在 Scikit-Learn 版本0.17和0.18中有不同的参数。对于下面代码单元格中的 fit_model 函数,您需要实现以下内容:
- 定义
'regressor'变量: 使用sklearn.tree中的DecisionTreeRegressor创建一个决策树的回归函数; - 定义
'params'变量: 为'max_depth'参数创造一个字典,它的值是从1至10的数组; - 定义
'scoring_fnc'变量: 使用sklearn.metrics中的make_scorer创建一个评分函数。将‘performance_metric’作为参数传至这个函数中; - 定义
'grid'变量: 使用sklearn.model_selection中的GridSearchCV创建一个网格搜索对象;将变量'regressor','params','scoring_fnc'和'cv_sets'作为参数传至这个对象构造函数中;
如果你对 Python 函数的默认参数定义和传递不熟悉,可以参考这个MIT课程的视频。
# TODO: Import 'make_scorer', 'DecisionTreeRegressor', and 'GridSearchCV'
from sklearn.metrics import make_scorer
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeRegressor
def fit_model(X, y):
""" Performs grid search over the 'max_depth' parameter for a
decision tree regressor trained on the input data [X, y]. """
# Create cross-validation sets from the training data
# sklearn version 0.18: ShuffleSplit(n_splits=10, test_size=0.1, train_size=None, random_state=None)
# sklearn versiin 0.17: ShuffleSplit(n, n_iter=10, test_size=0.1, train_size=None, random_state=None)
cv_sets = ShuffleSplit(n_splits=10, test_size=0.20, random_state=42)
# TODO: Create a decision tree regressor object
regressor = DecisionTreeRegressor()
# TODO: Create a dictionary for the parameter 'max_depth' with a range from 1 to 10
params = {"max_depth":np.arange(1,11)}
# TODO: Transform 'performance_metric' into a scoring function using 'make_scorer'
scoring_fnc = make_scorer(performance_metric)
# TODO: Create the grid search cv object --> GridSearchCV()
# Make sure to include the right parameters in the object:
# (estimator, param_grid, scoring, cv) which have values 'regressor', 'params', 'scoring_fnc', and 'cv_sets' respectively.
grid = GridSearchCV(estimator =regressor, param_grid=params, scoring=scoring_fnc, cv=cv_sets)
# Fit the grid search object to the data to compute the optimal model
grid = grid.fit(X, y)
# Return the optimal model after fitting the data
return grid.best_estimator_
第六步. 做出预测
当我们用数据训练出一个模型,它现在就可用于对新的数据进行预测。在决策树回归函数中,模型已经学会对新输入的数据提问,并返回对目标变量的预测值。你可以用这个预测来获取数据未知目标变量的信息,这些数据必须是不包含在训练数据之内的。
问题 9 - 最优模型
最优模型的最大深度(maximum depth)是多少?此答案与你在问题 6所做的猜测是否相同?
运行下方区域内的代码,将决策树回归函数代入训练数据的集合,以得到最优化的模型。
# Fit the training data to the model using grid search
reg = fit_model(X_train, y_train)
# Produce the value for 'max_depth'
print("Parameter 'max_depth' is {} for the optimal model.".format(reg.get_params()['max_depth']))
Parameter 'max_depth' is 4 for the optimal model.
问题 9 - 回答:
将决策树回归函数带入训练数据的集合,得到的最优深度是4,和我在问题6的猜测相同,因为通过6中的图中可以观察到起方差和偏差在深度为4的时候两者都接近最小值。
问题 10 - 预测销售价格
想像你是一个在波士顿地区的房屋经纪人,并期待使用此模型以帮助你的客户评估他们想出售的房屋。你已经从你的三个客户收集到以下的资讯:
| 特征 | 客戶 1 | 客戶 2 | 客戶 3 |
|---|---|---|---|
| 房屋内房间总数 | 5 间房间 | 4 间房间 | 8 间房间 |
| 社区贫困指数(%被认为是贫困阶层) | 17% | 32% | 3% |
| 邻近学校的学生-老师比例 | 15:1 | 22:1 | 12:1 |
- 你会建议每位客户的房屋销售的价格为多少?
- 从房屋特征的数值判断,这样的价格合理吗?为什么?
提示:用你在分析数据部分计算出来的统计信息来帮助你证明你的答案。
运行下列的代码区域,使用你优化的模型来为每位客户的房屋价值做出预测。
# Produce a matrix for client data
client_data = [[5, 17, 15], # Client 1
[4, 32, 22], # Client 2
[8, 3, 12]] # Client 3
# Show predictions
for i, price in enumerate(reg.predict(client_data)):
print("Predicted selling price for Client {}'s home: ${:,.2f}".format(i+1, price))
Predicted selling price for Client 1's home: $412,440.00
Predicted selling price for Client 2's home: $235,611.76
Predicted selling price for Client 3's home: $928,666.67
问题 10 - 回答:
根据模型预测出来的数值,我会推荐客户1的房屋销售价格为:412440.00;客户2的房屋销售价格为:235611.76;客户3的房屋销售价格为: $928,666.67;
我觉得这个数据还是比较合理的,排除在校学生和老师的比例,房屋的数量和房屋的价格成正相关关系这里被体现,贫困指数和房屋价格成负相关关系这个因素也被体现的比较明显,数据的趋势完全符合数据分析中两个特征和输出值之间的关系,我认为这样的预测结果有一定的可信程度,但是到底可信不可信,现在还不能确定,因为还没有完成对模型的评估。
编程练习 5
你刚刚预测了三个客户的房子的售价。在这个练习中,你将用你的最优模型在整个测试数据上进行预测, 并计算相对于目标变量的决定系数 R^2 的值。
提示:
- 你可能需要用到
X_test,y_test,reg,performance_metric。 - 参考问题10的代码进行预测。
- 参考问题2的代码来计算 R^2 的值。
# TODO Calculate the r2 score between 'y_true' and 'y_predict'
y_predict = reg.predict(X_test)
r2 = performance_metric(y_predict, y_test)
print("Optimal model has R^2 score {:,.2f} on test data".format(r2))
Optimal model has R^2 score 0.72 on test data
问题11 - 分析决定系数
你刚刚计算了最优模型在测试集上的决定系数,你会如何评价这个结果?
问题11 - 回答
对于回归问题来说,我们希望得到一个精确的数值,而0.72得R^2分数似乎远远不够,我觉得这个模型预测的结果还不足以让人信服,模型还不足以让人能够放心的使用。
模型健壮性
一个最优的模型不一定是一个健壮模型。有的时候模型会过于复杂或者过于简单,以致于难以泛化新增添的数据;有的时候模型采用的学习算法并不适用于特定的数据结构;有的时候样本本身可能有太多噪点或样本过少,使得模型无法准确地预测目标变量。这些情况下我们会说模型是欠拟合的。
问题 12 - 模型健壮性
模型是否足够健壮来保证预测的一致性?
提示: 执行下方区域中的代码,采用不同的训练和测试集执行 fit_model 函数10次。注意观察对一个特定的客户来说,预测是如何随训练数据的变化而变化的。
vs.PredictTrials(features, prices, fit_model, client_data)
Trial 1: $391,183.33
Trial 2: $411,417.39
Trial 3: $415,800.00
Trial 4: $420,622.22
Trial 5: $413,334.78
Trial 6: $411,931.58
Trial 7: $390,250.00
Trial 8: $407,232.00
Trial 9: $402,531.82
Trial 10: $413,700.00
Range in prices: $30,372.22
问题 12 - 回答:
问题 13 - 实用性探讨
简单地讨论一下你建构的模型能否在现实世界中使用?
提示:回答以下几个问题,并给出相应结论的理由:
- 1978年所采集的数据,在已考虑通货膨胀的前提下,在今天是否仍然适用?
- 数据中呈现的特征是否足够描述一个房屋?
- 在波士顿这样的大都市采集的数据,能否应用在其它乡镇地区?
- 你觉得仅仅凭房屋所在社区的环境来判断房屋价值合理吗?
问题 13 - 回答:
我认为,1978年的数据在考虑通货膨胀的前提下今天并不能完全适用,通货膨胀只能解决一部分问题,因为通货膨胀不不是从1978年到现在,现金金额越来越大的唯一原因,类似的很多数据都无法量化,比如时代的发展对人们消费观的改变等,就像一个模型有很多参数,通货膨胀只是其中一个参数,可能起了很大的作用,但是并不是唯一的决定性因素,也不能完全用通货膨胀直接换算金钱数额。
数据中出现的特征并不能足够描述一个房屋,房屋的价格还受到很多其他因素的影响,而给出的三个特征远远不够,我么还需要更多的特征,比如房屋面积,房屋周边的环境等。
很明显大都市采集的房屋数据并不能用到乡镇地区,原因显而易见,从机器学习角度来讲,很有可能我们习得的模型根本没有学到任何乡镇数据应有的特征。而且就像没有免费的午餐定理一样,不同的模型解决不同的问题,不同的问题要区别对待,很明显大都市和乡镇就是两个完全不同的问题,根本不能一概而论。
我觉得并不合理,虽然根据房屋社区的环境大致的分出高端房和低端房,但是房屋的价格不单单受到周边环境的影响,周边环境这个特征也并不一定是决定房屋价格的充分条件。