https://mp.weixin.qq.com/s/BuHiG9FjX-OiSNWx3KquQQ
17.随机梯度下降算法之经典变种
场景描述
提到Deep Learning中的优化方法,人们都会想到Stochastic Gradient Descent (SGD),但是SGD并不是理想的万金油,反而有时会成为一个坑。当你设计出一个deep neural network时,如果只知道用SGD来训练,不少情况下你得到一个很差的训练结果,于是你放弃继续在这个深度模型上投入精力。但可能的原因是,SGD在优化过程中失效了,导致你丧失了一次新发现的机会。
问题描述
Deep Learning中最常用的优化方法是SGD,但是SGD有时候会失效,无法给出满意的训练结果,这是为什么?为了改进SGD,研究者都做了哪些改动,提出了哪些SGD变种,它们各有哪些特点?
*背景知识假设:Gradient Descent Method, *
Stochastic Gradient Descent Method
解答与分析
(1)SGD失效的原因——摸着石头下山
为了回答第一个问题,我们先做一个形象的比喻:想象一下你是一个下山的人,眼睛很好,能看清自己所在位置的坡度,那么沿着坡向下走,最终你会走到山底。现在你被蒙上双眼,只能凭脚底踩石头的感觉判断当前位置的坡度,精确性大大下降。有时候你认为的坡,实际上可能不是坡,走上一段时间发现没有下山,或者曲曲折折走了好多弯路才下山。
我们回到SGD,传统的Gradient Descent(也称Batch Gradient Descent)是带着眼睛下山,而SGD是蒙着眼睛下山。Gradient Descent的每一步,为了获取准确的梯度,把整个训练集载入模型中计算,时间花费和内存开销非常大,无法用于实际中大数据集和大模型的场景。SGD放弃了对梯度准确性的追求,每步仅仅随机采样少量样本来计算梯度,计算速度快,内存开销小,但是由于每步接受的信息量有限,对梯度的估计常常出现偏差,造成目标函数曲线收敛得很不稳定,伴有剧烈波动,甚至有时出现不收敛的情况。图1展示了GD与SGD在优化过程中的参数轨迹,可以看到GD稳定地逼近最低点,而SGD曲曲折折简直是“黄河十八弯”。
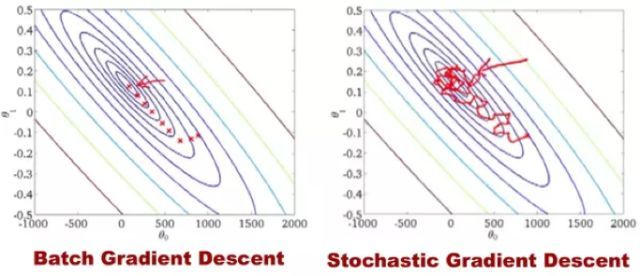
图1 GD与SGD的参数优化轨迹
进一步地,有人会说deep learning优化问题本身就很难,有太多局部最优点的陷阱。没错,这个陷阱对SGD和GD都是普遍存在的。但对SGD来说,可怕的不是局部最优点,而是两类地形——山谷和鞍点[1]。山谷顾名思义就是狭长的山间小道,左右两边是峭壁;鞍点的形状像是一个马鞍,一个方向上两头翘,另一个方向上两头垂,而中心区域是一片近乎水平的平地。
为什么SGD最害怕遇上这两类地形呢?在山谷中,准确的梯度方向是沿山道向下,稍有偏离就会撞向山壁,而SGD粗糙的梯度估计使得它在两山壁间来回反弹震荡,不能沿山道方向迅速下降,导致收敛不稳定和收敛速度慢;在鞍点处,SGD走入一片平坦之地(此时离最低点还很远,故也称plateau),想象一下蒙着双眼只凭借脚底感觉坡度,如果坡度很明显那么不精确也能估计出下山的大致方向,但是如果坡度不明显那么很可能走错方向,同样在几近零的梯度区域,对梯度微小变化无法准确察觉的SGD蒙圈了,结果停滞下来。
(2)解决之道——惯性保持和环境感知
SGD本质上是采用迭代方式更新参数,每次迭代在当前位置的基础上,沿着某一方向迈一小步抵达下一位置,然后在下一位置接着这么做。SGD的更新公式是:
其中当前估计的梯度﹣gt表示步子的方向,学习速率η控制步子的大小。改造SGD仍然基于这个更新形式。
变种1:Momentum
为了解决SGD的山谷震荡和鞍点停滞的问题,我们做一个简单的思维实验。想象一下纸团在山谷和鞍点处的运动轨迹,在山谷中纸团受重力作用沿山道滚下,两边是不规则的山壁,纸团不可避免地撞在山壁,由于质量小受山壁弹力的干扰大,从一侧山壁反弹回来撞向另一侧山壁,结果来回震荡地滚下;当纸团来到鞍点的一片平坦之地时,还是由于质量小,速度很快减为零。纸团的情况和SGD遇到的问题简直如出一辙。直觉上,如果换成一个铁球,当沿山谷滚下时,会不容易受到途中旁力的干扰,轨迹更稳更直;当来到鞍点中心处,在惯性作用下继续前行,从而有机会冲出这片平坦的陷阱。因此,我们有了Momentum的方法[2],更新公式为
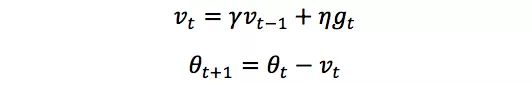
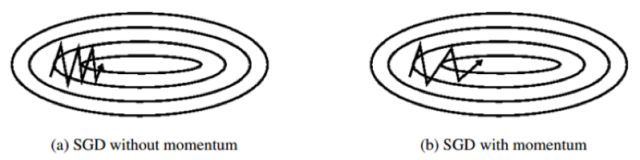
前进步子﹣vt由两部分组成:(1) 学习速率η和当前估计梯度gt,(2) 衰减下的前一次步子vt-1。这里,惯性就体现在对前次步子信息的重利用上。拿中学物理作个类比,当前梯度就好比当前时刻受力产生的加速度,前一次步子好比前一时刻的速度,当前步子好比当前时刻的速度,为了计算当前时刻的速度,我们应当考虑前一时刻速度和当前加速度共同作用的结果,因此vt直接依赖于vt-1和gt,而不是仅有gt。另外,衰减系数γ扮演了阻力的作用。
中学物理还告诉我们,刻画惯性的物理量是动量,这也是算法名字的由来。沿山谷滚下的铁球,会受到两个方向上的力:沿坡道向下的力和与左右山壁碰撞的弹力。向下的力稳定不变,产生的动量不断累积,速度越来越快;左右的弹力总是在不停切换,动量累积的结果是相互抵消,自然减弱了球的来回震荡。因此,与SGD相比,Momentum的收敛速度快,收敛曲线稳定。
变种2:AdaGrad
惯性的获得是基于历史信息的。那么,除了从过去的步伐中获得一股子向前冲的劲儿,我们还能获得什么?我们期待获得对周围环境的感知,即使蒙上双眼,依靠前几次迈步的感觉,我们也应该能判断出一些信息,比如这个方向总是坑坑洼洼的,那个方向可能很平坦。
具体到SGD中,对环境的感知是指在参数空间中,对不同参数方向上的经验性判断,确定这个参数的自适应学习速率,即更新不同参数的步子大小应是不同的。在一些任务中,如文本处理中训练word embeddings参数,有的words频繁出现,有的则极少出现,数据的稀疏导致相应参数的梯度稀疏,即不频繁出现words的参数大多数情况梯度为零,使得这些参数被更新的频率很低,因此我们希望更新它们的步子大些,而对频繁更新的参数,更新的步子小些。AdaGrad[2]采用过往梯度平方和

的方式来衡量不同参数的梯度稀疏性,和越小表明越稀疏。AdaGrad的更新公式是:
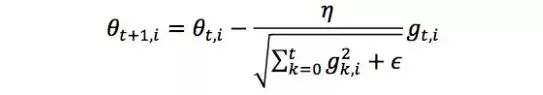
其中θt+1,i表示θt+1的第i个参数。另外,分母中和的形式实现了退火的过程,这是很多优化技术中常见的策略,意味着随着时间推移,学习速率

越来越小,从而保证了优化的最终收敛。
变种3:Adam
Adam方法[4]将惯性保持和环境感知这两个优点集于一身。一方面,Adam记录梯度的first moment,即过往梯度与当前梯度的平均,这体现了惯性保持;另一方面,Adam还记录梯度的second moment,即过往梯度平方与当前梯度平方的平均,这类似AdaGrad,体现了环境感知,为不同参数产生自适应的学习速率。First moment和second moment求平均的思想类似滑动窗口内求平均的做法,关注当前梯度和近一段时间内梯度的平均值,时间久远的梯度对当前平均的贡献呈指数衰减,具体采用指数衰退平均(exponential decay average)技术,计算公式为:

其中β1, β2为衰减系数。
如何理解first moment和second moment呢?First moment相当于估计,由于当下梯度gt是随机采样估计的结果,比起gt我们更关心它在统计意义上的期望;second moment相当于估计
从开始到现在的和而是它的期望。它们的物理意义是:当‖mt‖大vt大时,梯度大且稳定,表明遇到一个明显的大坡,前进方向明确;当‖mt‖趋零vt大时,梯度不稳定,可能遇到一个峡谷,容易引起反弹震荡;当‖mt‖大vt趋零时,这种情况不可能出现;当‖mt‖趋零vt趋零时,梯度趋零,可能到达局部最低点,也可能走到一片坡度极缓的平地,此时要避免陷入plateau。另外,Adam还考虑了mt**, vt在零初始值情况下的偏置矫正。Adam的更新公式为:
[图片上传中...(image-1ed96c-1526902673016-3)]
扩展阅读
除了上述三种SGD变种,研究者还提出了其他方法:
1. Nesterov Accelerated Gradient:扩展了Momentum方法,顺着惯性方向,计算未来可能位置处的梯度而非当前位置的梯度,这个“提前量”的设计让算法有了对前方环境预判的能力。
2. AdaDelta和RMSProp:这两个方法非常类似,是对AdaGrad的改进。AdaGrad采用所有过往梯度平方和的平方根做分母,分母随时间单调递增,产生的自适应学习速率随时间衰减的速度过于激进,因此AdaDelta和RMSProp采用指数衰退平均的计算方法,用过往梯度的均值代替它们的和。
3. AdaMax:基于Adam的一个变种,对梯度平方的处理由指数衰退平均改为指数衰退求max。
4. Nadam:可看成Nesterov Accelerated Gradient版的Adam。
参考文献:
[1] Yann N. Dauphin, Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, Surya Ganguli, and Yoshua Bengio. Identifying and attacking the saddle point problem in high-dimensional nonconvex optimization. arXiv, pages 1–14, 2014
[2] Ning Qian. On the momentum term in gradient descent learning algorithms. Neural networks: the official journal of the International Neural Network Society, 12(1):145–151, 1999
[3] John Duchi, Elad Hazan, and Yoram Singer. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. Journal of Machine Learning Research, 12:2121–2159, 2011
[4] Diederik P. Kingma and Jimmy Lei Ba. Adam: a Method for Stochastic Optimization. InternationalConference on Learning Representations, pages 1–13, 2015.
18. SVM – 核函数与松弛变量
场景描述
当我们在SVM中处理线性不可分的数据时,核函数可以对数据进行映射,从而使得原问题在某种度量下具有更为可分的相似度,而通过引入松弛变量,我们可以放弃一些离群点的精确分类来使分类平面不受太大的影响。将这两种技术与SVM结合起来,正是SVM分类器简洁而强大的原因之一。
问题描述
- 一个使用高斯核
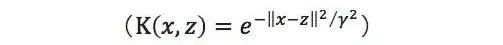 image
image
训练的SVM(Support Vector Machine)中,试证明若给定训练集中不存在两个点在同一位置,则存在一组参数{α1, ... αm, b}以及参数γ使得该SVM的训练误差为0。- 若我们使用问题1中得到的参数γ训练一个不加入松弛变量的SVM,是否能保证得到的SVM,仍有训练误差为0的结果,试说明你的观点。
- 若我们使用SMO(Sequential Minimal Optimization)算法来训练一个带有松弛变量的SVM,并且惩罚因子C为任意事先不知道的常数,我们是否仍能得到训练误差为0的结果,试说明你的观点。
先验知识:SVM训练过程、核函数、SMO算法
解答与分析
1.
根据SVM的原理,我们可以将SVM的预测公式可写为下式:
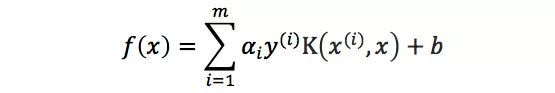
其中{(x(1), y(1)), …, (x(m), y(m))}为训练样本,而{α1, …, αm, b}以及高斯核参数γ则为训练样本的参数,根据题意我们可以得到对于任意的i≠j 我们有‖x(i)﹣x(j)‖≥ε,我们可以直接对任意i,取αi=1,b=0,则有
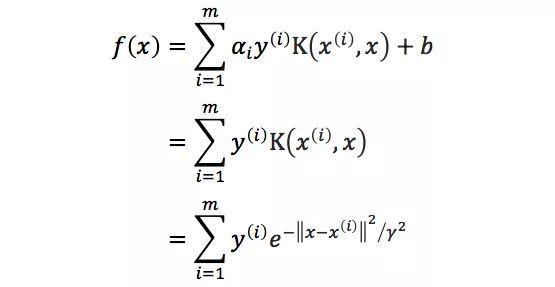
将任意x(j)代入则有
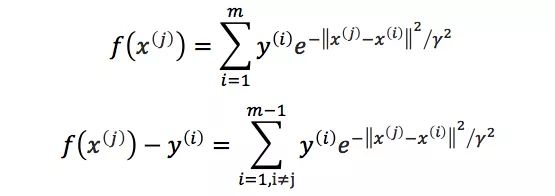
注意到y(i)∈{1, ﹣1}
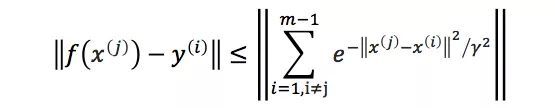
由题意知‖x(i)﹣x(j)‖≥ε,取γ=ε/㏒1/2m

故有
可知对于任意x(j),预测结果与样本的距离不超过1,则训练误差为0。
2.
我们能得到训练误差为0的分类器,我们仅需要证明解存在即可。考虑SVM推导中的限制y(i)(wTx(i)﹢b)≥1,与上一问相同,我们取b=0,那么则有y(i)·f(x(j))>0,由上问,我们有
所以一个可行解在将所有αi取到足够大时(这里改变αi的取值并不会影响上一问的结论),我们可得到y(i)(wTx(i)﹢b)≥1,则得到一个可行解,那么最优解的训练误差仍为0。
3.
我们的分类器并不一定能得到0训练误差,因为我们的优化目标改变了,并不再是训练误差最小,考虑我们优化的结果实际上包含两项
可知当我们的参数C选取较小的值时,我们就可以得出后一正则项将占据优化的较大比重,那么一个带有训练误差,但是参数较小的点将成为更优的结果,例如当C取0时,w也可取0即可达到优化目标,但是显然这样我们的训练误差不一定能达到0。
19. 主题模型
场景描述
基于Bag-Of-Words(或N-gram)的文本表示模型有一个明显的缺陷,就是无法识别出不同的词(或词组)具有相同主题的情况。我们需要一种技术能够将具有相同主题的词(或词组)映射到同一维度上去,于是产生了主题模型(Topic Model)。主题模型是一种特殊的概率图模型。想象一下我们如何判定两个不同的词具有相同的主题呢?这两个词可能有更高的概率出现在同一主题的文档中;换句话说,给定某一主题,这两个词的产生概率都是比较高的,而另一些不太相关的词产生的概率则是较低的。假设有K个主题,我们可以把任意文章表示成一个K维的主题向量,其中向量的每一维代表一个主题,权重代表这篇文章属于该主题的概率。主题模型所解决的事情,就是从语料库中发现有代表性的主题(得到每个主题上面词的分布),并且计算出每篇文章对应着哪些主题。这样具有相似主题的文章拥有相似的主题向量表示,从而能够更好地表示文章的语义,提高文本分类、信息检索等应用的效果。
问题描述
1. 常见的主题模型有哪些?试介绍其原理。
2. 如何确定LDA模型中的主题个数?
解答与分析
1. 常见的主题模型有哪些?试介绍其原理。
常用的主题模型当属pLSA和LDA,下面分别介绍其原理:
(1) pLSA
pLSA(probabilistic Latent Semantic Analysis) [1]用一个生成模型来建模文章的生成过程。假设有K个主题,M篇文章;对语料库中的任意文章d, 假设该文章有N个词,则对于其中的每一个词, 我们首先选择一个主题z, 然后在当前主题的基础上生成一个词w。这一过程表示成图模型(Graphical Model)如下图所示:

生成主题z和词w的过程遵照一个确定的概率分布。设在文章d中生成主题z的概率为p(z|d), 在选定主题的条件下生成词w的概率为p(w|z),则给定文章d,生成词w的概率可以写成:
在这里我们做一个简化,假设给定主题z的条件下,生成词w的概率是与特定的文章无关的,则公式可以简化为:
整个语料库中的文本生成概率可以用以下公式表示,我们称之为似然函数(Likelihood Function):
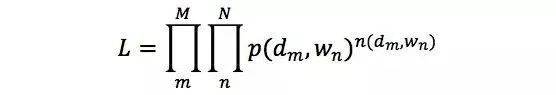
其中p(dm, wn)是在第m篇文章中,第n个单词为wn的概率,与上文中p(w|d)的含义是相同的,只是换了一种符号表达。n(dm, wn)表示单词wn在文章dm中出现的次数。
于是,对数似然函数可以写成:
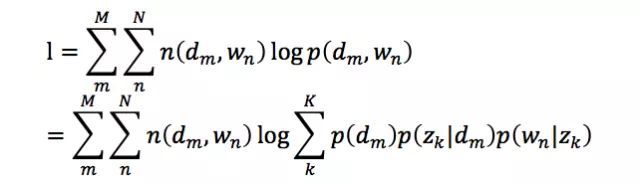
在上面的公式中,定义在文章上的主题分布p(zk|dm)和定义在主题上的词分布p(wn|zk)是待估计的参数 。我们需要找到最优的参数,使得整个语料库的对数似然函数最大化。由于参数中包含的zk是隐含变量(即无法直接观测到的变量),因此无法用最大似然估计直接求解,可以利用EM(Expectation-Maximization)算法来解决。
(2) LDA
LDA(Latent Dirichlet Allocation)[2]可以看作是pLSA的贝叶斯版本,其文本生成过程与pLSA基本相同,不同的是为主题分布和词分布分别加了狄利克雷(Direchlet)先验。为什么要加入狄利克雷先验呢?这就要从频率学派和贝叶斯学派的区别说起。pLSA采用的是频率派思想,将每篇文章对应的主题分布p(zk|dm)和每个主题对应的词分布p(wn|zk)看成确定的未知常数,并可以求解出来;而LDA采用的是贝叶斯学派的思想,认为待估计的参数(主题分布和词分布)不再是一个固定的常数,而是服从一定分布的随机变量。这个分布符合一定的先验概率分布(即Dirichlet分布),并且在观察到样本信息之后,可以对先验分布进行修正,从而得到后验分布。LDA之所以选择Dirichlet分布做为先验分布,是因为它为多项式分布的共轭先验概率分布,后验概率依然服从Dirichlet分布,这样做可以为计算带来便利。LDA的图模型表示如下:
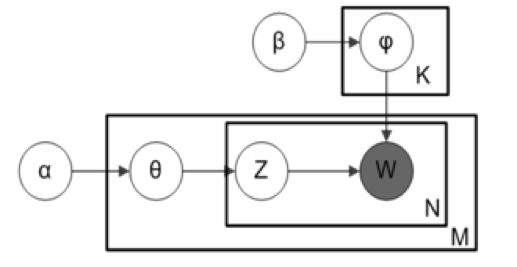
其中α,β分别为两个Dirichlet分布的超参数,为人工设定。语料库的生成过程如下。
对文本库中的每一篇文档dm:

这里主题分布θm以及词分布
是待估计的参数,可以用吉布斯采样(Gibbs Sampling)[4]求解其期望。具体做法为,首先随机给定每个词的主题,然后在其它变量固定的情况下,根据转移概率抽样生成每个词的新主题。对于每个词来说,转移概率可以理解为:给定文章中的所有词以及除自身以外其它所有词的主题,在此条件下该词对应各个新主题的概率。最后,经过反复迭代,我们可以根据收敛后的采样结果计算主题分布和词分布的期望。
2. 如何确定LDA模型中的主题个数?
在LDA中,主题的个数K是一个预先指定的超参数。对于模型超参数的选择,实践中的做法一般是将全部数据集分成训练集、验证集、和测试集3部分,然后利用验证集对超参数进行选择。例如,在确定LDA的主题个数时,我们可以随机选取60%的文档组成训练集,另外20%的文档组成验证集,剩下20%的文档组成测试集。我们在训练时尝试多组超参数的取值,并在验证集上检验哪一组超参数所对应的模型取得了最好的效果。最终,在验证集上效果最好的一组超参数和其对应的模型将被选定,并在测试集上进行测试。
为了衡量LDA模型在验证集和测试集上的效果,我们需要寻找一个合适的评估指标。一个常用的评估指标是困惑度(perplexity)。在文档集合D上,模型的困惑度被定义为:
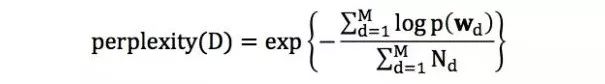
其中M为文档的总数,wd为文档d中单词所组成的词袋向量,p(wd)为模型所预测的文档d的生成概率,Nd为文档d中单词的总数。
一开始,随着主题个数的增多,模型在训练集和验证集的困惑度呈下降趋势,但是当主题数目足够大的时候,会出现过拟合,导致困惑度指标在训练集上继续下降但在验证集上反而增长。这时,我们可以取困惑度极小值点所对应的主题个数作为超参数。实践中,困惑度的极小值点可能出现在主题数目非常大的时候,然而实际应用并不能承受如此大的主题数目,这时就需要在实际应用中合理的主题数目范围内进行选择,比如选择合理范围内困惑度的下降明显变慢(拐点)的时候。
另外一种方法是在LDA基础之上融入分层狄利克雷过程(Hierarchical Dirichlet Process,HDP)[3],构成一种非参数主题模型HDP-LDA。非参数主题模型的好处是不需要预先指定主题的个数,模型可以随着文档数目的变化而自动对主题个数进行调整;它的缺点是在LDA基础上融入HDP之后使得整个概率图模型更加复杂, 训练速度也更加缓慢,因此在实际应用中还是经常采用第一种方法确定合适的主题数目。
参考文献:
[1] Hofmann, Thomas. "Probabilistic latent semantic analysis." Proceedings of the Fifteenth conference on Uncertainty in artificial intelligence. Morgan Kaufmann Publishers Inc., 1999.
[2] Blei, David M., Andrew Y. Ng, and Michael I. Jordan. "Latent dirichlet allocation." Journal of machine Learning research3.Jan (2003): 993-1022.
[3] Teh, Yee W., et al. "Sharing clusters among related groups: Hierarchical Dirichlet processes." Advances in neural information processing systems. 2005.
[4] George, Edward I., and Robert E. McCulloch. "Variable selection via Gibbs sampling." Journal of the American Statistical Association 88.423 (1993): 881-889.
20. PCA 最小平方误差理论
场景描述
经历了强化学习、深度学习、集成学习一轮轮面试题的洗礼,我们是否还记得心底对宇宙,对世界本源的敬畏与探索之心?时间回溯到40多天前,我们曾经从宇宙空间出发,讨论维度,从维度引到机器学习,由PCA探寻降维之道,传送门:Hulu机器学习与问答系列第六弹-PCA算法。彼日,我们从最大方差的角度解释了PCA的原理、目标函数和求解方法。今夕,我们将从最小平方误差之路,再次通向PCA思想之核心。
问题描述
观察到其实PCA求解的是最佳投影方向,即一条直线,这与数学中线性回归问题的目标不谋而合,能否从回归的角度定义PCA的目标并相应地求解问题呢?
背景知识:线性代数
解答与分析

我们还是考虑二维空间这些样本点,最大方差角度求解的是一条直线,使得样本点投影到这条直线上的方差最大。从求解直线的思路出发,很容易联想到数学中的线性回归问题,其目标也是求解一个线性函数使得对应直线能够更好地拟合样本点集合。如果我们从这个角度定义PCA的目标,那么问题就会转化为一个回归问题。
顺着这个思路,在高维空间中,我们实际上是要找到一个d维超平面,使得数据点到这个超平面的距离平方和最小。对于一维的情况,超平面退化为直线,即把样本点投影到最佳直线,最小化的就是所有点到直线的距离平方之和,如下图所示。




第一项x****kTxk与我们选取的W无关,是个常数。我们利用刚才求出的投影向量表示将第二项和第三项分别继续展开

其中ωiT****xk和ωjT****xk表示投影长度,都是数字。且i≠j时,ωiTωj=0,因此上式的交叉项中只剩下d项。
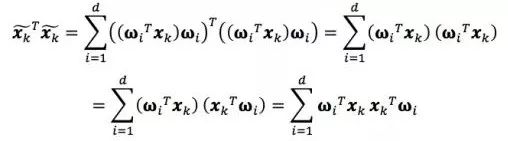

我们要最小化的式子即对所有的k求和,可以写成

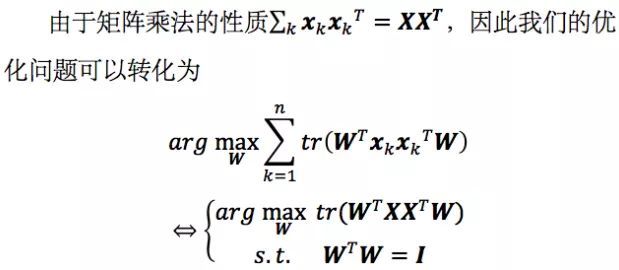
如果我们对W中的d个基ω1, ω2, ..., ωd依次求解,就会发现和上一节中方法完全等价。比如当d=1时,我们实际求解的问题是

这个最佳直线ω与最大方差法求解的最佳投影方向一致,即协方差矩阵的最大特征值所对应的特征向量,差别仅是协方差矩阵∑的一个倍数,以及一个常数偏差,但这并不影响我们对最大值的优化。
总结与扩展
至此,我们从最小平方误差的角度解释了PCA的原理、目标函数和求解方法,不难发现,这与最大方差角度殊途同归,从不同的目标函数出发,得到相同的求解方法。
21.分类、排序、回归模型的评估
场景描述
在模型评估过程中,分类问题、排序问题、回归问题往往需要使用不同的评估指标进行评估。但在诸多的评估指标中,大部分指标只能片面的反映模型一部分的能力,如果不能合理的综合运用评估指标,不仅不能发现模型本身的问题,甚至会得出错误的结论。下面以hulu的业务为背景,假想了几个模型评估的场景,看看大家能否管中窥豹,发现指标选择或者模型本身的问题。
问题描述
准确率(Accuracy)的局限
精确率(Precision)和召回率(Recall)的权衡
均方根误差(Root Mean Square Error,RMSE)的“意外”
知识点:
*准确率(Accuracy) *精确率(Precision)
召回率(Recall) 均方根误差(Root Mean Square Error, RMSE)
解答与分析
1. 准确率(Accuracy)的局限
hulu的奢侈品广告主们希望把广告定向投放给奢侈品用户,hulu通过第三方的DMP(Data Management Platform,数据管理平台)拿到了一部分奢侈品用户的数据,并以此为训练集和测试集训练奢侈品用户的分类模型;该模型的分类准确率超过了95%,但在实际广告投放过程中,该模型还是把大部分广告投给了非奢侈品用户,有可能是什么原因造成的?
难度:1星
在解答该问题之前,我们先明确一下分类准确率(Accuracy)的定义——准确率是指分类正确的样本个数,占总样本个数的比例。

其中ncorrect为被正确分类的样本个数,ntotal为总样本的个数。
准确率是分类问题最简单也是最直观的评价指标,但准确率存在明显的缺陷,即当样本所属类别的比例非常不均衡时,样本占比大的分类往往成为影响准确率的最主要因素。比如负样本占99%,那么分类器把所有样本预测为负样本也可以获得99%的准确率。
明确这一点,我们这道题也就迎刃而解了。因为奢侈品用户显然只占hulu全体用户的一小部分,模型的整体分类准确率高,不代表着对奢侈品用户的分类准确率高。在线上投放过程中,我们只会对模型判定的“奢侈品用户“进行投放,因此对“奢侈品用户”判定的准确率不够高的问题被放大了。为解决这个问题,使用平均准确率(每个类别下的样本准确率的算术平均)来进行模型评估是更为有效的指标。
事实上,这道题是一道比较开放的试题,需要面试者根据问题的现象去一步步地排查问题。标准答案不限于指标选择的问题,即使评估指标选择对了,仍会存在模型过拟合或欠拟合,测试集和训练集划分,线下评估与线上测试样本分布存在差异等等一系列的问题。但评估指标选择的问题是最容易被发现也是最可能影响评估结果的因素。
2. 精确率(precision)与召回率(recall)的权衡
hulu提供视频的模糊搜索功能,搜索排序模型返回的top 5结果的精确率(precision)非常高,但在实际的使用过程中,用户却还是经常找不到想要找的视频,特别是一些比较冷门的剧集,这有可能是哪个环节出了问题?
难度:1星
要回答这个问题,我们需要首先明确两个概念,精确率(precision)和召回率(recall)。
精确率(precision):分类正确的正样本个数占分类器判定为正样本的样本个数的比例。
召回率(recall):分类正确的正样本个数占真正的正样本个数的比例。
在排序模型中,由于没有一个准确的阈值把结果判定为正负样本,所以往往使用Top N返回结果的Precision和Recall值来衡量排序模型的性能。即我们认为排序模型返回的Top N的结果就是模型判定的正样本,计算Precision@N,和Recall@N。
Precision和Recall是矛盾统一的两个指标,为了提高精确率,需要分类器尽量在“更有把握时”才把样本预测为正样本,但此时分类器往往会因为过于保守的选择而漏掉很多“没有把握”的正样本,导致召回率降低。
回到问题中来,问题给出Precision@5的结果非常好,也就是说排序模型Top 5的返回值的质量是很高的,但在实际使用过程中,用户为了找一些冷门的视频,往往会寻找排在较靠后的结果,甚至翻页去查找目标视频,但根据题目,用户经常找不到想要的视频,这说明模型没有把相关的视频都找出来呈现给用户,显然,问题出在召回率上,如果相关结果有100个的话,即使Precision@5达到了100%,Recall@5也仅仅是5%。在评价Precision的时候,我们是否应该同时看Recall的指标?进一步,是否应该选取不同的Top N进行观察?再进一步,是否应该选取更高阶的评估指标能够更全面的反映模型在Precision和Recall两方面的表现?
答案显然都是肯定的,为了综合评估一个排序模型的好坏,我们不仅要看模型在不同top N下的Precision@N和Recall@N,而且最好能据此画出Precision-Recall曲线,这里我们简单介绍一下P-R曲线的绘制方法。
P-R曲线的横轴是召回率,纵轴是精确率。对于一个排序模型来说,其P-R曲线上的某一个点代表着在某一个正样本阈值(大于该阈值模型预测为正样本,小于该阈值预测为负样本)下所对应的召回率和精确率。而整条P-R曲线是通过从最高到最低滑动正样本阈值生成的。如下图图b所示,其中实线代表模型insts模型的P-R曲线,虚线代表insts2模型的P-R曲线。横轴接近0的点代表着正样本阈值最大时模型的精确率和召回率。如图可见,在召回率接近0时,insts模型的精确率是0.9,而insts2模型的精确率是1。说明insts2模型得分前几位的样本全部是真正的正样本,而insts模型即使是得分最高的几个样本也存在预测错误的情况。而随着召回率的增加,精确率整体上有所下降,在召回率为1时,insts模型的精确率反而超过了insts2模型,这充分说明了我们只用一个点的精确率和召回率结果是不能全面衡量模型性能的,只有通过P-R曲线的整体表现,才能够对模型进行更为全面的评估。
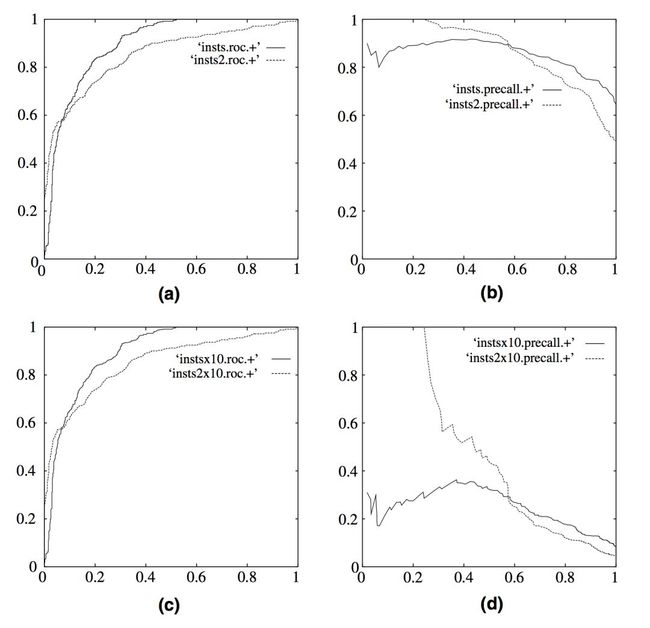
(图片来自 Fawcett, Tom. "An introduction to ROC analysis." Pattern recognition letters27.8 (2006): 861-874.)
除此之外,F1 score和ROC曲线也是能够综合地反映一个排序模型的性能,F1-score是精准率和召回率的调和平均值,定义如下:

ROC曲线我们在前面的文章中做过详细的介绍,感兴趣的同学可以翻一下公众号的历史文章。
3. 平方根误差的“意外”
hulu作为一家流媒体公司,拥有众多美剧资源,预测每部美剧的流量趋势对于广告投放、用户增长都是非常重要。我们希望构建一个回归模型来预测某部美剧的流量趋势,但无论采用何种回归模型,我们得到的RMSE(Root Mean Square Error,平方根误差)指标都非常高,然而事实上,模型在95%的时间区间内的预测误差都小于1%,取得了相当不错的预测结果,那么造成RMSE指标居高不下的最可能的原因是什么?
难度:1星
大家知道,RMSE(Root Mean Square Error,均方根误差)是经常用来衡量一个回归模型好坏的。但按照题目的叙述,RMSE这个指标却失效了。我们首先看一下RMSE的计算方式:
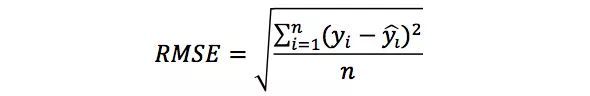
其中,yi是第i个样本点的真实值,
是第i个样本点的预测值,n是样本点的个数。
一般情况下,RMSE能够很好的反映回归模型预测值与真实值的偏离程度,但当实际问题中存在别偏离程度非常大的离群点时,即使是极个别的点,也会让RMSE指标变得很差。
回到问题中来,模型在95%的时间区间内的预测误差都小于1%,显然大部分时间区间内模型效果都是非常优秀的。但RMSE效果却一直很差,很可能是由于在剩余5%的时间区间内存在非常严重的离群点。事实上,在流量预估这个实际问题中,噪声点确实是很容易产生的,对于特别小流量的美剧,刚上映的美剧,或者获奖的美剧,甚至一些相关社交媒体突发事件带来的流量,都会成为离群点产生的原因。
那么有什么解决方法呢?这里有三个角度,第一个角度是如果我们认定这些离群点是“噪声点”的话,我们就需要在数据预处理的阶段就把这些噪声点过滤掉;第二个角度,如果我们不认为这些离群点是噪声点的话,我们其实是需要进一步提高模型的预测能力,将离群点产生的机制建模进去。关于流量预估模型如何改进这个问题是一个宏大的话题,我们就不展开讨论了;第三个角度,我们希望找一个更合适评估该模型的指标,关于这个问题,其实是存在比RMSE鲁棒性更好的指标的,比如MAPE(Mean Absolute Percent Error平均绝对百分比误差),定义如下:
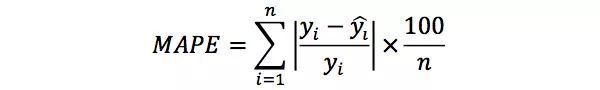
相比RMSE,MAPE相当于把每个点的误差进行了归一化,消除了个别离群点带来的绝对误差的影响。
总结与扩展
本篇文章,我们基于三个假想的hulu的应用场景,主要说明了评估指标选择的重要性。每个评估指标都有其价值,但是如果只从单一的评估指标出发去评价模型,往往会得出片面甚至错误的结论。只有通过一组互补的评价指标去验证试验结果,我们才能够更好的发现并解决模型存在的问题,从而更好的解决实际业务场景的问题。
【特征工程—结构化数据】
场景描述
特征工程是指结合问题寻找有效的特征并进行处理成适合模型的输入形式。机器学习中有句经典的话叫做“Garbage in, garbage out”,意思是如果输入的数据是垃圾,那么得到的结果也是垃圾。可以看出模型成败的关键并不仅仅取决于模型的选取,还取决于我们是否有根据特定的问题找到了行之有效的输入。常用的数据可以分为结构化数据和非结构化数据,其中:结构化数据可以看成关系型数据库的一张表,每列都有清晰的定义,包含了数值型、类别型两种基本类型;非结构化数据主要包括文本数据和图像数据,所有信息都是混在一起的,并没有清晰的类别定义,并且每条数据的大小都是不一样的。
问题描述
1. 为什么需要对数值类型的特征做归一化?
2. 怎样处理类别型特征?
3. 怎样处理高维组合特征?
4. 怎样有效地找到组合特征?
解答与分析
1. 为什么需要对数值类型的特征做归一化?
对数值类型的特征做归一化(normalization)可以将所有的特征都统一到一个大致相同的区间内。最常用的归一化是z-score normalization,它会将特征变换映射到以均值为0、标准差为1的正态分布上。准确的来说,假设原始特征的均值为μ、标准差为σ,那么z-score normalization定义为:
为什么通常需要对数值型做归一化呢?我们可以借助随机梯度下降来说明归一化的重要性。假设有两种数值型特征,x1的取值范围为[0, 10],x2的取值范围为[0, 3],可以构造一个目标函数符合以下等值图:

在学习速率相同的情况下,x1的更新速度会大于x2,需要更多的迭代才能找到最优值[1]。如果将x1和x2归一化到相同的区间后,则优化目标的等值图会变成右图的圆形,x1和x2的更新速度会比较一致,能够更快的找到最优值。
那么归一化适用于哪些模型,又对哪些模型是不适用的呢?首先,通过梯度下降法求解的模型是需要归一化的,包括包括线性回归、logistic regression、支持向量机(Support Vector Machine)、神经网络(Neuro Network)。但对于决策树模型则是不适用的,以C4.5为例,决策树在进行节点分裂时主要依据的是x >= threshold 和 x < threshold的信息增益比,而信息增益比跟x是否经过归一化是无关的,因为归一化并不会改变样本在x上的相对顺序。
2. 怎样处理类别型特征?
类别型特征(categorical feature)主要是指性别(男、女)、血型(A、B、AB、O)等类似的在有限选项内取值的特征。通常类别型特征原始输入都是字符串形式,只有决策树等少数模型能直接处理字符串形式的输入。对于Logistic Regression、线性支持向量机等模型来说,类别型特征必须经过处理转换成数值型特征才能正确工作。
本节主要介绍三种常用的转换方法:Ordinal Encoding、One-hot Encoding、Binary Encoding。
Ordinal Encoding通常用于处理类别间具有大小关系的数据,例如成绩可以分为Low、Medium、High三档,并且存在High > Medium > Low的排序关系。Ordinal Encoding会按照大小关系对类别型特征赋予一个数值ID,例如High表示为3、Medium表示为2、Low表示为1,转换后依然保留了大小关系。
One-hot Encoding通常用于处理类别间不具有大小关系的特征,以血型为例,血型一共有四个取值(A、B、AB、O),在One-hot Encoding后血型会变成一个4维稀疏向量:A型血表示为(1, 0, 0, 0),B型血表示为(0, 1, 0, 0),AB型表示为(0, 0, 1, 0),O型血表示为(0, 0, 0, 1)。对于类别取值较多的情况下使用One-hot Encoding需要注意以下问题:
使用稀疏向量来节省空间:在One-hot Encoding下,只有某一维取值为1,其他位置取值均为0。因此可以用向量的稀疏表示来有效节省空间,并且目前大部分的算法都会实现接受稀疏向量形式的输入。
配合特征选择来降低维度:高维度特征会带来两方面的问题:(1)在K近邻算法中,高纬空间下两点之间的距离很难得到有效的衡量; (2) 在Logistic Regression中,模型的参数的数量会随着维度的增高而增加,容易引起过拟合问题; (3) 通常只有部分维度是对分类、预测有帮助,因此可以考虑配合特征选择来降低维度。
最后介绍Binary Encoding,该方法主要分为两步:用Ordinal Encoding给每个类别赋予一个ID,然后将ID对应的二进制编码作为结果。以血型A、B、AB、O为例,Binary Encoding的过程如下图所示:A型血的Ordinal Encoding为1,二进制表示为(0, 0, 1);B型血的Ordinal Encoding为2,二进制表示为(0, 1, 0),以此类推可以得到AB型血和O型血的二进制表示。可以看出,Binary Encoding本质上是利用二进制编码对ID进行哈希,最终得到了0/1向量维数要少于One-hot Encoding,节省了空间。
除了本章介绍的Encoding方法外,有兴趣的读者还可以参照[2]了解其他的编码方式,包括Helmert Contrast、Sum Contrast、Polynomial Contrast、Backward Difference Contrast。
3. 怎样处理高维组合特征?
为了提高复杂关系的拟合能力,在特征工程中经常会把一阶离散特征两两组合成高阶特征,构成交互特征(Interaction Feature)。以广告点击预估问题为例,如图1所示,原始数据有语言和类型两种离散特征。为了提高拟合能力,语言和类型可以组成二阶特征,如图2所示:
△ 图1
△ 图2
以Logistic Regression为例,假设数据的特征向量X = (x_1, x_2, …, x_k),我们有
其wij的维度等于|xi| * |xj|。在上面的广告点击预测问题当中,w的维度是4(2x2,语言取值为中文或者英文、 类型的取值为电影或者电视剧)。
在上面广告预测的问题看起来特征组合是没有任何问题的,但当引入ID类型的特征时,问题就出现了。以推荐问题为例,原始数据如图3所示,用户ID和物品ID组合成新的特征后的数据如图4所示:
△ 图3
△ 图4
假设用户的数量为m、物品的数量为n,那么需要学习的参数的规模为m × n。在互联网环境下,用户数量和物品数量都可以到达千万量级,几乎无法学习m × n的参数规模。在这种情况下,一种行之有效的方法是将用户和物品分别用k维的低维向量表示(k << m, k << n),
其中wij=xi'· xj',在这里xi'和xj'分别表示对应的低维向量。在上面的推荐问题中,需要学习的参数的规模为m × k + n × k。熟悉推荐算法的同学可以看出来这等于矩阵分解,希望这篇文章提供了另一个理解矩阵分解的思路。
4. 怎样有效地找到组合特征?
在上节中我们介绍了如何利用降维方法来减少两个高维特征进行组合需要学习的参数。但是在很多实际数据当中,我们常常需要面对多种高维特征。如果简单的两两组合,参数过多、容易过拟合的问题依然存在,并且并不是所有的特征组合都是有意义地。因此,我们迫切需要一种有效地方法来帮助我们找到哪些特征应该进行组合。
本节介绍介绍一种基于决策树的特征组合寻找方法[3]。以点击预测问题为例,假设原始输入特征包含年龄、性别、用户类型(试用期、付费)、物品类型(护肤、食品等)四个方面的信息,并且假设我们根据原始输入和标签(点击与否)构造出了两个决策树,那么每一条从根节点到叶子节的路径都可以看成一种特征组合的方式。具体来说,我们可以将“年龄<=35”且“性别=女”看成一个特征组合,将“年龄<=35”且“物品类别=护肤”看出是一个特征组合,将“用户类型=付费”且“物品类型=食品”看成是一种特征组合,将“用户类型=付费”且“年龄<=40”看成是一种特征组合。假设我们有两个样本如下表所示,那么第一行可以编码为(1, 1, 0, 0),因为既满足“年龄<=35”且“性别=女”,也满足“年龄<=35”且“物品类别=护肤”。同理可以看出第二个样本可以编码为(0, 0, 1, 1),因为既满足“用户类型=付费”且“物品类型=食品”,又满足“用户类型=付费”且“年龄<=40”。


最后,那么给定原始输入该如何有效构造多棵决策树呢?在这里我们采用梯度提升决策树 (gradient boosting decision tree),该方法地思想是每次都在之前构建的决策树的残差(residual)上构建下一棵决策树,对GDBT感兴趣的读者可以参考原始文献[4]。
参考文献:
[1] https://www.coursera.org/learn/machine-learning
[2] http://contrib.scikit-learn.org/categorical-encoding/index.html
[3] Practical Lessons from Predicting Clicks on Ads at Facebook, ADKDD’14
[4] J. H. Friedman. Greedy function approximation: A gradient boosting machine. Annals of Statistics, 29:1189–1232, 1999.
【神经网络训练中的批量归一化】
场景描述
深度神经网络的训练中涉及诸多手调参数,如学习率,权重衰减系数,Dropout比例等,这些参数的选择会显著影响模型最终的训练效果。批量归一化(Batch Normalization, BN)方法从数据分布入手,有效减弱了这些复杂参数对网络训练产生的影响,在加速训练收敛的同时也提升了网络的泛化能力。
问题描述
- BN基本动机与原理是什么?
- BN的具体实现中怎样恢复前一层学习到的特征分布?
- 简述BN在卷积神经网络中如何使用?
背景知识:统计学习,深度学习
解答与分析
1. BN的基本动机与原理是什么?
神经网络训练过程的本质是学习数据分布,训练数据与测试数据的分布不同将大大降低网络的泛化能力,因此我们需要在训练开始前对所有输入数据进行归一化处理。
然而随着网络训练的进行,每个隐层的参数变化使得后一层的输入发生变化,从而每一批(batch)训练数据的分布也随之改变,致使网络在每次迭代中都需要拟合不同的数据分布,增大了训练的复杂度以及过拟合的风险。
Batch Normalization方法是针对每一批数据,在网络的每一层输入之前增加归一化处理(均值为0,标准差为1),将所有批数据强制在统一的数据分布下,即对该层的任意一个神经元(不妨假设为第k维)采用如下公式:
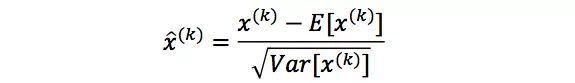
2. BN的具体实现中怎样恢复前一层学习到的特征分布?
按照上式直接进行归一化会导致上层学习到的数据分布发生变化,以sigmoid激活函数为例,BN之后数据整体处于函数的非饱和区域,只包含线性变换,破坏了之前学习到的特征分布。为了恢复原始数据分布,具体实现中引入了变换重构以及可学习参数γ,β:
其中
分别为输入数据分布的方差和偏差,对于一般的网络,不采用BN操作时,这两个参数高度依赖前面网络的学习到的连接权重(对应复杂的非线性)。而在BN操作中提取出来后,γ,β变成了该层的学习参数,与之前网络层的参数无关,从而更加有利于优化的过程。
完整的Batch Normalization网络层的前向传导过程公式如下:
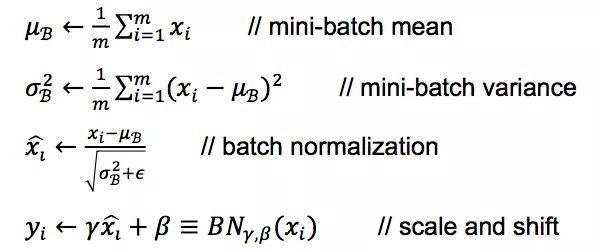
3. 简述BN在卷积神经网络中如何使用?
卷积神经网络中每一层操作后得到一系列特征图(feature maps),卷积层上的BN同样使用类似权值共享的策略,将每张特征图做为一个处理单元,即全连接网络中的单个神经元,进行归一化操作。
具体实现中,假设网络训练中每个batch包含b个样本,特征图个数为f,特征图的宽高分别为w, h,那么,每个特征图所对应的全部神经元个数为b * w * h,利用这些神经元我们可得到一组学习参数γ,β用于对该特征图进行BN操作。详细过程可参考问题2中的公式,其中m=b * w * h,为BN操作中的mini-batch。
【随机梯度下降法】
场景描述
深度学习得以在近几年迅速占领工业界和学术界的高地,重要原因之一是数据量的爆炸式增长。如下图所示,随着数据量的增长,传统机器学习算法的性能会进入平台期,而深度学习算法因其强大的表示能力,性能得以持续增长,甚至在一些任务上超越人类。因此有人戏称,“得数据者得天下”。
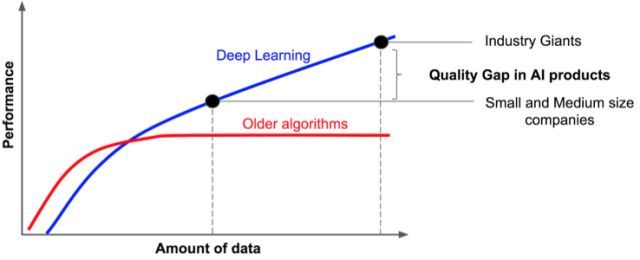
经典的优化方法,例如梯度下降法,每次迭代更新需要用到所有的训练数据,这给求解大数据、大规模的优化问题带来了挑战。掌握基于大量训练数据求解模型的方法,对于掌握机器学习,尤其是深度学习至关重要。
问题描述
针对训练数据量过大的问题,当前有哪些优化求解算法?
先验知识:概率论、梯度下降法
解答与分析
在机器学习中,优化问题的目标函数通常可以表示成
其中θ是待优化的模型参数,x是模型输入,f(x, θ)是模型的实际输出,y是模型的目标输出,L(·,·)刻画了模型在数据(x, y)上的损失,Pdata表示数据的分布,E表示期望。J(θ)刻画了当参数为θ时,模型在所有数据上的平均损失,我们希望能够找到使得平均损失最小的模型参数,也就是求解优化问题
为了求解该问题,梯度下降法的迭代更新公式为
其中α>0是步长。若采用所有训练数据的平均损失来近似目标函数及其梯度,即
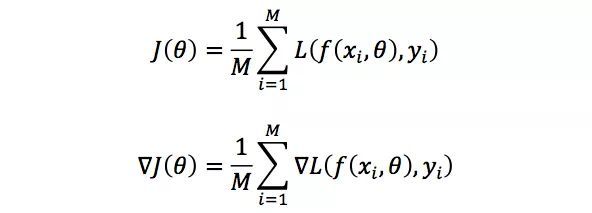
其中M表示训练数据的个数,则对模型参数的单次更新需要遍历所有的训练数据,这在M很大时是不可取的。
为了解决该问题,随机梯度下降法(stochastic gradient descent, SGD)采用单个训练数据的损失近似平均损失,即
因此,随机梯度下降法用单个训练数据即可对模型参数进行一次更新,大大加快了收敛速率。该方法也非常适用于数据源源不断到来的在线场景。
为了降低梯度的方差从而使得算法的收敛更加稳定,也为了充分利用高度优化的矩阵运算操作,实际中我们会同时处理若干训练数据,该方法被称为小批量梯度下降法(mini-batch gradient descent)。假设需要处理m个训练数据{xi1, yi1, …, xim, yim},则目标函数及其梯度为
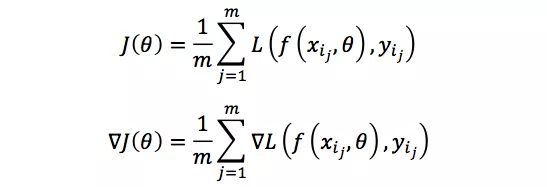
对于小批量梯度下降法,有三点需要注意的地方:
如何选取参数m?在不同的应用中,最优的m通常会不一样,需要通过调参选取。一般m取2的幂次时能充分利用矩阵运算操作,所以我们可以在2的幂次中挑选最优的取值,例如64,128,256,512等。
如何挑选m个训练数据?为了避免数据的特定顺序给算法收敛带来的影响,一般会在每次遍历训练数据之前,先对所有的数据进行随机排序,然后顺序挑选m个训练数据进行训练,直至遍历完所有的数据。
如何选取学习速率α?为了加快收敛速率同时提高求解精度,通常会选取递减的学习速率方案。算法一开始能够以较快的速率收敛到最优解附近,再以较小的速率精细调整最优解。最优的学习速率方案也通常需要调参才能得到。
综上,我们通常采用小批量梯度下降法解决训练数据量过大的问题,每次迭代更新只需要处理m个训练数据即可,其中m是一个远小于总数据量M的常数,能够大大加快收敛速率。