把函数视为对象:一等函数
把函数视为对象
python函数是对象。
>>> def factorial(n):
... '''returns n!'''
... return 1 if n < 2 else n * factorial(n-1)
...
>>> factorial(42)
1405006117752879898543142606244511569936384000000000
>>> factorial.__doc__ #__doc__ is one of several attributes of function objects.
'returns n!'
>>> type(factorial) *factorial is an instance of the function class.
>>> fact = factorial
>>> fact
>>> fact(5)
120
>>> map(factorial, range(11))
高阶函数
函数式编程的特点之一是使用高阶函数。接受函数为参数,或者把函数作为结果返回的函数是高阶函数。
例如:根据单词长度给一个列表排序
>>> fruits = ['strawberry', 'fig', 'apple', 'cherry', 'raspberry', 'banana']
>>> sorted(fruits, key=len)
['fig', 'apple', 'cherry', 'banana', 'raspberry', 'strawberry']
例如:根据反向拼写给一个单词列表排序
>>> def reverse(word):
... return word[::-1]
>>> reverse('testing')
'gnitset'
>>> sorted(fruits, key=reverse)
['banana', 'apple', 'fig', 'raspberry', 'strawberry', 'cherry']
map、filter和reduce的现代替代品
它们的直接替代品是生成器表达式。
例如:使用reduce和sum计算0~99之和
>>> from functools import reduce
>>> from operator import add
>>> reduce(add, range(100))
4950
>>> sum(range(100))
4950
sum和reduce的通用思想是把某个操作连续应用到序列的元素上,累计之前的结果,把一系列值归约成一个值。all和any也是内置的归约函数。
可调用对象
- 用户定义的函数 —— 使用def或lambda创建
- 内置函数 —— 使用C语言(CPython)实现的函数,例如len
- 内置方法 —— 使用C语言实现的方法,例如dict.get
- 方法 —— 在类的定义体中定义的函数
- 类 —— 调用类时会运行类的__new__方法创建一个实例,然后运行__init__方法,初始化实例,最后把实例返回给调用方。
- 类的实例 —— 如果类定义了__call__方法,那么它的实例可以作为函数调用。
- 生成器函数 —— 使用yield关键字的函数或方法。
用户定义的可调用类型
只需实现实例方法__call__。
"""
# BEGIN BINGO_DEMO
>>> bingo = BingoCage(range(3))
>>> bingo.pick()
1
>>> bingo()
0
>>> callable(bingo)
True
# END BINGO_DEMO
"""
# BEGIN BINGO
import random
class BingoCage:
def __init__(self, items):
self._items = list(items) # <1>
random.shuffle(self._items) # <2>
def pick(self): # <3>
try:
return self._items.pop()
except IndexError:
raise LookupError('pick from empty BingoCage') # <4>
def __call__(self): # <5>
return self.pick()
# END BINGO
函数内省
和用户定义的常规类一样,函数使用__dict__属性存储赋予它的用户属性。
>>> class C: pass #
>>> obj = C() #
>>> def func(): pass #
>>> sorted(set(dir(func)) - set(dir(obj))) #
['__annotations__', '__call__', '__closure__', '__code__', '__defaults__','__get__', '__globals__', '__kwdefaults__', '__name__', '__qualname__']
获取关于参数的信息
函数对象有个__defaults__属性,它的值一个元组,里面保存着定位参数和关键字参数的默认值。
例如:在指定长度附近阶段字符串的函数
def clip(text, max_len=80):
"""Return text clipped at the last space before or after max_len
"""
end = None
if len(text) > max_len:
space_before = text.rfind(' ', 0, max_len)
if space_before >= 0:
end = space_before
else:
space_after = text.rfind(' ', max_len)
if space_after >= 0:
end = space_after
if end is None: # no spaces were found
end = len(text)
return text[:end].rstrip()
例如:提取关于函数参数的信息
>>> from clip import clip
>>> clip.__defaults__
(80,)
>>> clip.__code__ # doctest: +ELLIPSIS
>>> clip.__code__.co_varnames
('text', 'max_len', 'end', 'space_before', 'space_after')
>>> clip.__code__.co_argcount
2
其实,我们有更好的方式——使用inspect模块
例如:提取函数的签名
>>> from clip import clip
>>> from inspect import signature
>>> sig = signature(clip)
>>> sig # doctest: +ELLIPSIS
>>> str(sig)
'(text, max_len=80)'
>>> for name, param in sig.parameters.items():
... print(param.kind, ':', name, '=', param.default)
...
POSITIONAL_OR_KEYWORD : text =
POSITIONAL_OR_KEYWORD : max_len = 80
inspect.Signature对象有个bind方法,它可以把任意个参数绑定到签名中的形参上。框架可以使用这个方法在真正调用函数前验证参数。
例如:把tag函数的签名绑定到一个参数字典上
>>> import inspect
>>> sig = inspect.signature(tag)
>>> my_tag = {'name': 'img', 'title': 'Sunset Boulevard',
... 'src': 'sunset.jpg', 'cls': 'framed'}
>>> bound_args = sig.bind(**my_tag)
>>> bound_args
>>> for name, value in bound_args.arguments.items():
... print(name, '=', value)
...
name = img
cls = framed
attrs = {'title': 'Sunset Boulevard', 'src': 'sunset.jpg'}
>>> del my_tag['name']
>>> bound_args = sig.bind(**my_tag)
Traceback (most recent call last):
...
TypeError: 'name' parameter lacking default value
函数注解
支持函数式编程的包
operator模块
operator模块为多个算术运算符提供了对应的函数。
例如:使用reduce和operator.mul函数计算阶乘
from functools import reduce
from operator import mul
def fact(n):
return reduce(mul, range(1, n+1))
operator模块中还有一类函数,能替代从序列中取出元素或读取对象属性的lambda表达式;因此,itemgetter和attrgetter其实会自行构建函数。
例如:使用itemgetter排序一个元组列表
>>> metro_data = [
... ('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
... ('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
... ('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
... ('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
... ('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
... ]
>>>
>>> from operator import itemgetter
>>> for city in sorted(metro_data, key=itemgetter(1)):
... print(city)
...
('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833))
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889))
('Tokyo', 'JP', 36.933, (35.689722, 139.691667))
('Mexico City', 'MX', 20.142, (19.433333, -99.133333))
('New York-Newark', 'US', 20.104, (40.808611, -74.020386))
itemgetter使用[]运算符,因此它不仅支持序列,还支持映射和任何实现__getitem__方法的类。
attrgetter和itemgetter作用类似,它创建的函数根据名称提取对象的属性。
例如
>>> from collections import namedtuple
>>> LatLong = namedtuple('LatLong', 'lat long')
>>> Metropolis = namedtuple('Metropolis', 'name cc pop coord')
>>> metro_areas = [Metropolis(name, cc, pop, LatLong(lat, long)) #
... for name, cc, pop, (lat, long) in metro_data]
>>> metro_areas[0]
Metropolis(name='Tokyo', cc='JP', pop=36.933, coord=LatLong(lat=35.689722,
long=139.691667))
>>> metro_areas[0].coord.lat #
35.689722
>>> from operator import attrgetter
>>> name_lat = attrgetter('name', 'coord.lat') #
>>>
>>> for city in sorted(metro_areas, key=attrgetter('coord.lat')): #
... print(name_lat(city)) #
...
('Sao Paulo', -23.547778)
('Mexico City', 19.433333)
('Delhi NCR', 28.613889)
('Tokyo', 35.689722)
('New York-Newark', 40.808611)
methodcaller与之类似,它会自行创建函数。methodcaller创建的函数会在对象上调用参数指定的方法。
例如
>>> from operator import methodcaller
>>> s = 'The time has come'
>>> upcase = methodcaller('upper')
>>> upcase(s)
'THE TIME HAS COME'
>>> hiphenate = methodcaller('replace', ' ', '-')
>>> hiphenate(s)
'The-time-has-come'
使用functools.partial冻结参数
使用functools.patial函数基于一个函数创建一个新的可调用对象,把原函数的某些参数固定。
例如
>>> from operator import mul
>>> from functools import partial
>>> triple = partial(mul, 3)
>>> triple(7)
21
>>> list(map(triple, range(1, 10)))
[3, 6, 9, 12, 15, 18, 21, 24, 27]
>>> import unicodedata, functools
>>> nfc = functools.partial(unicodedata.normalize, 'NFC')
>>> s1 = 'café'
>>> s2 = 'cafe\u0301'
>>> s1, s2
('café', 'café')
>>> s1 == s2
False
>>> nfc(s1) == nfc(s2)
True
函数装饰器和闭包
(1)装饰器基础知识
装饰器是可调用的对象,其参数是另一个函数。装饰器可能会处理被装饰的函数,然后把它返回,或者将其替换成另一个函数或可调用对象。
例如:装饰器通常把函数替换成另一个函数
>>> def deco(func):
... def inner():
... print('running inner()')
... return inner
...
>>> @deco
... def target():
... print('running target()')
...
>>> target()
running inner()
>>> target
.inner at 0x10063b598>
装饰器的两大特性是
- 能把被装饰的函数替换成其他函数
- 装饰器在加载模块时立即执行
(2)Python何时执行装饰器
装饰器的一个关键特性是,它们在被装饰的函数定义之后立即运行,这通常是在导入时。
例如:registration.py
# BEGIN REGISTRATION
registry = [] # <1>
def register(func): # <2>
print('running register(%s)' % func) # <3>
registry.append(func) # <4>
return func # <5>
@register # <6>
def f1():
print('running f1()')
@register
def f2():
print('running f2()')
def f3(): # <7>
print('running f3()')
def main(): # <8>
print('running main()')
print('registry ->', registry)
f1()
f2()
f3()
if __name__=='__main__':
main() # <9>
$ python3 registration.py
running register()
running register()
running main()
registry -> [, ]
running f1()
running f2()
running f3()
如果导入registration.py模块,输出如下
>>> import registration
running register()
running register()
(3)使用装饰器改进“策略”模式
# strategy_best4.py
# Strategy pattern -- function-based implementation
# selecting best promotion from list of functions
# registered by a decorator
"""
>>> joe = Customer('John Doe', 0)
>>> ann = Customer('Ann Smith', 1100)
>>> cart = [LineItem('banana', 4, .5),
... LineItem('apple', 10, 1.5),
... LineItem('watermellon', 5, 5.0)]
>>> Order(joe, cart, fidelity)
>>> Order(ann, cart, fidelity)
>>> banana_cart = [LineItem('banana', 30, .5),
... LineItem('apple', 10, 1.5)]
>>> Order(joe, banana_cart, bulk_item)
>>> long_order = [LineItem(str(item_code), 1, 1.0)
... for item_code in range(10)]
>>> Order(joe, long_order, large_order)
>>> Order(joe, cart, large_order)
# BEGIN STRATEGY_BEST_TESTS
>>> Order(joe, long_order, best_promo)
>>> Order(joe, banana_cart, best_promo)
>>> Order(ann, cart, best_promo)
# END STRATEGY_BEST_TESTS
"""
from collections import namedtuple
Customer = namedtuple('Customer', 'name fidelity')
class LineItem:
def __init__(self, product, quantity, price):
self.product = product
self.quantity = quantity
self.price = price
def total(self):
return self.price * self.quantity
class Order: # the Context
def __init__(self, customer, cart, promotion=None):
self.customer = customer
self.cart = list(cart)
self.promotion = promotion
def total(self):
if not hasattr(self, '__total'):
self.__total = sum(item.total() for item in self.cart)
return self.__total
def due(self):
if self.promotion is None:
discount = 0
else:
discount = self.promotion(self)
return self.total() - discount
def __repr__(self):
fmt = ''
return fmt.format(self.total(), self.due())
# BEGIN STRATEGY_BEST4
promos = [] # <1>
def promotion(promo_func): # <2>
promos.append(promo_func)
return promo_func
@promotion # <3>
def fidelity(order):
"""5% discount for customers with 1000 or more fidelity points"""
return order.total() * .05 if order.customer.fidelity >= 1000 else 0
@promotion
def bulk_item(order):
"""10% discount for each LineItem with 20 or more units"""
discount = 0
for item in order.cart:
if item.quantity >= 20:
discount += item.total() * .1
return discount
@promotion
def large_order(order):
"""7% discount for orders with 10 or more distinct items"""
distinct_items = {item.product for item in order.cart}
if len(distinct_items) >= 10:
return order.total() * .07
return 0
def best_promo(order): # <4>
"""Select best discount available
"""
return max(promo(order) for promo in promos)
(4)闭包
闭包指延伸了作用域的函数,关键是它能访问定义体之外定义的非全局变量。

例如:审查make_averager创建的函数
>>> avg.__code__.co_varnames
('new_value', 'total')
>>> avg.__code__.co_freevars
('series',)
>>> avg.__closure__
(| ,)
>>> avg.__closure__[0].cell_contents
[10, 11, 12]
| (5)nonlocal声明
上述函数对数字、字符串、元组等不可变类型来说,只能读取,不能更新。因此,python 3 引入了nonlocal声明。
例如:计算移动平均值,不保存所有历史
def make_averager():
count = 0
total = 0
def averager(new_value):
nonlocal count, total
count += 1
total += new_value
return total / count
return averager
(6)实现一个简单的装饰器
例如:一个简单的装饰器,输出函数的运行时间
# clockdeco.py
import time
def clock(func):
def clocked(*args):
t0 = time.time()
result = func(*args)
elapsed = time.time() - t0
name = func.__name__
arg_str = ', '.join(repr(arg) for arg in args)
print('[%0.8fs] %s(%s) -> %r' % (elapsed, name, arg_str, result))
return result
return clocked
例如:使用clock装饰器
# clockdeco_demo.py
import time
from clockdeco import clock
@clock
def snooze(seconds):
time.sleep(seconds)
@clock
def factorial(n):
return 1 if n < 2 else n*factorial(n-1)
if __name__=='__main__':
print('*' * 40, 'Calling snooze(.123)')
snooze(.123)
print('*' * 40, 'Calling factorial(6)')
print('6! =', factorial(6))
$ python3 clockdeco_demo.py
**************************************** Calling snooze(123)
[0.12405610s] snooze(.123) -> None
**************************************** Calling factorial(6)
[0.00000191s] factorial(1) -> 1
[0.00004911s] factorial(2) -> 2
[0.00008488s] factorial(3) -> 6
[0.00013208s] factorial(4) -> 24
[0.00019193s] factorial(5) -> 120
[0.00026107s] factorial(6) -> 720
6! = 720
上述实现的装饰器有几个缺点:不支持关键字参数,而且遮盖了被装饰函数的__name__和__doc__属性。下例使用functools.wraps装饰器把相关的属性从func复制到clocked中。
例如:改进后的clock装饰器
import time
import functools
def clock(func):
@functools.wraps(func)
def clocked(*args, **kwargs):
t0 = time.time()
result = func(*args, **kwargs)
elapsed = time.time() - t0
name = func.__name__
arg_lst = []
if args:
arg_lst.append(', '.join(repr(arg) for arg in args))
if kwargs:
pairs = ['%s=%r' % (k, w) for k, w in sorted(kwargs.items())]
arg_lst.append(', '.join(pairs))
arg_str = ', '.join(arg_lst)
print('[%0.8fs] %s(%s) -> %r ' % (elapsed, name, arg_str, result))
return result
return clocked
(7)标准库中的装饰器
使用functools.lru_cache做备忘
functools.lru_cache实现了备忘功能,这是一项优化技术,它把耗时的函数结果保存起来,避免传入相同的参数时重复计算。
例如:生成第n个斐波那契数列,递归方式非常耗时
import functools
from clockdeco import clock
@functools.lru_cache()
@clock
def fibonacci(n):
if n < 2:
return n
return fibonacci(n-2) + fibonacci(n-1)
if __name__=='__main__':
print(fibonacci(6))
单分配泛函数
使用@singledispatch装饰的普通函数会变成泛函数。
例如
r"""
htmlize(): generic function example
# BEGIN HTMLIZE_DEMO
>>> htmlize({1, 2, 3}) # <1>
'{1, 2, 3}'
>>> htmlize(abs)
'
'
>>> htmlize('Heimlich & Co.\n- a game') # <2>
'Heimlich & Co.
\n- a game
'
>>> htmlize(42) # <3>
'42 (0x2a)
'
>>> print(htmlize(['alpha', 66, {3, 2, 1}])) # <4>
alpha
66 (0x42)
{1, 2, 3}
# END HTMLIZE_DEMO
"""
# BEGIN HTMLIZE
from functools import singledispatch
from collections import abc
import numbers
import html
@singledispatch # <1>
def htmlize(obj):
content = html.escape(repr(obj))
return '{}'.format(content)
@htmlize.register(str) # <2>
def _(text): # <3>
content = html.escape(text).replace('\n', '
\n')
return '{0}
'.format(content)
@htmlize.register(numbers.Integral) # <4>
def _(n):
return '{0} (0x{0:x})'.format(n)
@htmlize.register(tuple) # <5>
@htmlize.register(abc.MutableSequence)
def _(seq):
inner = '\n'.join(htmlize(item) for item in seq)
return '\n- ' + inner + '
\n
'
(8)叠放装饰器
@d1
@d2
def f():
print('f')
等同于
def f():
print('f')
f = d1(d2(f))
(9)参数化装饰器
一个参数化的注册装饰器
我们为它提供一个可选的active参数,设为False时,不注册被装饰的函数。
# BEGIN REGISTRATION_PARAM
registry = set() # <1>
def register(active=True): # <2>
def decorate(func): # <3>
print('running register(active=%s)->decorate(%s)'
% (active, func))
if active: # <4>
registry.add(func)
else:
registry.discard(func) # <5>
return func # <6>
return decorate # <7>
@register(active=False) # <8>
def f1():
print('running f1()')
@register() # <9>
def f2():
print('running f2()')
def f3():
print('running f3()')
>>> from registration_param import *
running register(active=False)->decorate()
running register(active=True)->decorate()
>>> registry #
{}
>>> register()(f3) #
running register(active=True)->decorate()
>>> registry #
{, }
>>> register(active=False)(f2) #
running register(active=False)->decorate()
>>> registry #
{}
参数化clock装饰器
例如:clockdeco_param.py模块:参数化clock装饰器
# clockdeco_param.py
"""
>>> snooze(.1) # doctest: +ELLIPSIS
[0.101...s] snooze(0.1) -> None
>>> clock('{name}: {elapsed}')(time.sleep)(.2) # doctest: +ELLIPSIS
sleep: 0.20...
>>> clock('{name}({args}) dt={elapsed:0.3f}s')(time.sleep)(.2)
sleep(0.2) dt=0.201s
"""
# BEGIN CLOCKDECO_CLS
import time
DEFAULT_FMT = '[{elapsed:0.8f}s] {name}({args}) -> {result}'
class clock:
def __init__(self, fmt=DEFAULT_FMT):
self.fmt = fmt
def __call__(self, func):
def clocked(*_args):
t0 = time.time()
_result = func(*_args)
elapsed = time.time() - t0
name = func.__name__
args = ', '.join(repr(arg) for arg in _args)
result = repr(_result)
print(self.fmt.format(**locals()))
return _result
return clocked
if __name__ == '__main__':
@clock()
def snooze(seconds):
time.sleep(seconds)
for i in range(3):
snooze(.123)
import time
from clockdeco_param import clock
@clock('{name}: {elapsed}s')
def snooze(seconds):
time.sleep(seconds)
for i in range(3):
snooze(.123)
$ python3 clockdeco_param_demo1.py
snooze: 0.12414693832397461s
snooze: 0.1241159439086914s
snooze: 0.12412118911743164s
import time
from clockdeco_param import clock
@clock('{name}({args}) dt={elapsed:0.3f}s')
def snooze(seconds):
time.sleep(seconds)
for i in range(3):
snooze(.123)
$ python3 clockdeco_param_demo2.py
snooze(0.123) dt=0.124s
snooze(0.123) dt=0.124s
snooze(0.123) dt=0.124s
面向对象惯用法:对象引用、可变性和垃圾回收
(1)变量不是盒子
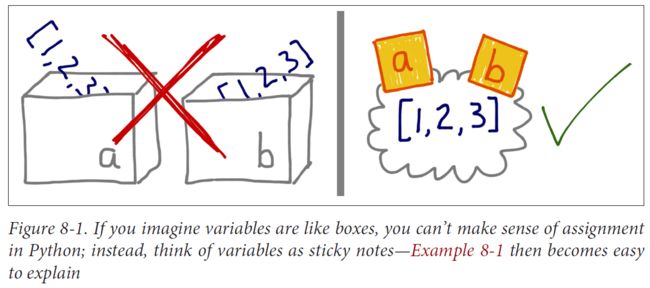
(2)默认做浅复制
复制列表(或多数内置的可变集合)最简单的方式是使用内置的类型构造方法。
>>> l1 = [3, [55, 44], (7, 8, 9)]
>>> l2 = list(l1)
>>> l2
[3, [55, 44], (7, 8, 9)]
>>> l2 == l1
True
>>> l2 is l1
False
copy模块提供的deepcopy和copy函数能为任意对象做深复制和浅复制。
(3)函数的参数作为引用时
不要用可变类型作为参数的默认值
(4)del和垃圾回收
del语句删除名称,而不是对象。
(5)弱引用
WeakValueDictionary简介
WeakValueDictionary类实现的是一种可变映射,里面的值是对象的弱引用,它经常用于缓存。
面向对象惯用法:序列的修改、散列和切片
(1)Vector类第3版:动态存取属性
属性查找失败后,解释器会调用__getattr__方法。简单来说,对my_obj.x表达式,Python会检查my_obj实例有没有名为x的属性;如果没有,到类(my_obj.__class__)中查找;如果还没有,顺着继承树继续查找。如果依旧找不到,调用my_obj所属类中定义的__getattr__方法,传入self和属性名称的字符串形式(如'x')。
例如:vector_v3.py的部分代码
shortcut_names = 'xyzt'
def __getattr__(self, name):
cls = type(self) # <1>
if len(name) == 1: # <2>
pos = cls.shortcut_names.find(name) # <3>
if 0 <= pos < len(self._components): # <4>
return self._components[pos]
msg = '{.__name__!r} object has no attribute {!r}' # <5>
raise AttributeError(msg.format(cls, name))
改写__setattr__方法,例如
def __setattr__(self, name, value):
cls = type(self)
if len(name) == 1: # <1>
if name in cls.shortcut_names: # <2>
error = 'readonly attribute {attr_name!r}'
elif name.islower(): # <3>
error = "can't set attributes 'a' to 'z' in {cls_name!r}"
else:
error = '' # <4>
if error: # <5>
msg = error.format(cls_name=cls.__name__, attr_name=name)
raise AttributeError(msg)
super().__setattr__(name, value) # <6>
(2)Vecotr类第4版:散列和快速等值测试
reduce()函数的第一个参数是接受两个参数的函数,第二个参数是一个可迭代的对象。假如有个接受两个参数的fn函数和一个list列表,调用reduce(fn, list)时,fn会应用到第一队元素上,生成第一个结果r1,然后fn会应用到r1和下一个元素上,直到最后一个元素,返回最后得到的结果rN。
例如:使用zip和all函数实现Vector.__eq__方法
def __eq__(self, other):
return len(self) == len(other) and all(a == b for a, b in zip(self, other))
控制流程:可迭代的对象、迭代器和生成器
迭代是数据处理的基石。扫描内存中放不下的数据集时,我们要找到一种惰性获取数据项的方式,即按需一次获取一个数据项,这就是迭代器模式。
(1)Sentence类第1版:单词序列
序列可以迭代的原因:iter函数
内置的iter函数有以下作用。
- 检查对象是否实现__iter__方法,如果实现了就调用它,获取一个迭代器
- 如果没有实现__iter__方法,但是实现了__getitem__方法,Python会创建一个迭代器,尝试按顺序获取元素
- 如果尝试失败,Python抛出TypeError异常
例如
>>> class Foo:
... def __iter__(self):
... pass
...
>>> from collections import abc
>>> issubclass(Foo, abc.Iterable)
True
>>> f = Foo()
>>> isinstance(f, abc.Iterable)
True
(2)可迭代的对象与迭代器的对比
如果对象实现了能返回迭代器的__iter__方法,那么对象就是可迭代的。序列都可以迭代,实现了__getitem__方法,而且其参数是从零开始的索引,这种对象也可以迭代。Python从可迭代的对象中获取迭代器。
字符串'ABC'是可迭代的对象,背后是有迭代器的,只不过我们看不到。
>>> s = 'ABC'
>>> for char in s:
... print(char)
...
A
B
C
如果没有for语句,不得不使用while循环模拟。
>>> s = 'ABC'
>>> it = iter(s) #
>>> while True:
... try:
... print(next(it)) #
... except StopIteration: #
... del it #
... break #
...
A
B
C
标准的迭代器接口有两个方法
- __next__ —— 返回下一个可用的元素,如果没有元素了,抛出StopIteration异常
- __iter__ —— 返回self,以便在应该使用可迭代对象的地方使用迭代器,例如在for循环中
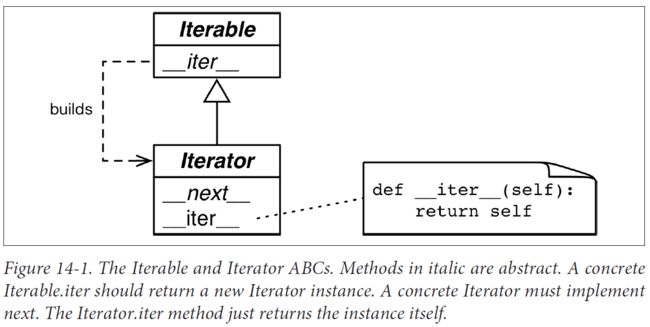
迭代器是这样的对象:实现了无参数的__next__方法,返回序列中的下一个元素;如果没有元素了,那么抛出StopIteration异常。Python中的迭代器还实现了__iter__方法,因此迭代器也可以迭代。
(3)Sentence类第2版:典型的迭代器
import re
import reprlib
RE_WORD = re.compile('\w+')
class Sentence:
def __init__(self, text):
self.text = text
self.words = RE_WORD.findall(text)
def __repr__(self):
return 'Sentence(%s)' % reprlib.repr(self.text)
def __iter__(self): # <1>
return SentenceIterator(self.words) # <2>
class SentenceIterator:
def __init__(self, words):
self.words = words # <3>
self.index = 0 # <4>
def __next__(self):
try:
word = self.words[self.index] # <5>
except IndexError:
raise StopIteration() # <6>
self.index += 1 # <7>
return word # <8>
def __iter__(self): # <9>
return self
(4)Sentence类第3版:生成器函数
符合Python习惯的方法是,用生成器函数代替SentenceIterator类。
"""
Sentence: iterate over words using a generator function
"""
import re
import reprlib
RE_WORD = re.compile('\w+')
class Sentence:
def __init__(self, text):
self.text = text
self.words = RE_WORD.findall(text)
def __repr__(self):
return 'Sentence(%s)' % reprlib.repr(self.text)
def __iter__(self):
for word in self.words: # <1>
yield word # <2>
return
生成器函数的工作原理
只要Python函数的定义体中有yield关键字,该函数就是生成器函数。
>>> def gen_123():
... yield 1
... yield 2
... yield 3
...
>>> for i in gen_123():
... print(i)
1
2
3
>>> g = gen_123()
>>> next(g)
1
>>> next(g)
2
>>> next(g)
3
>>> next(g)
Traceback (most recent call last):
...
StopIteration
例如:运行时打印消息的生成器函数
>>> def gen_AB():
... print('start')
... yield 'A'
... print('continue')
... yield 'B'
... print('end.')
...
>>> for c in gen_AB():
... print('-->', c)
...
start
--> A
continue
--> B
end.
(5)Sentence类第4版:惰性实现
例如:在生成器函数中调用re.finditer生成器函数,实现Sentence类
"""
Sentence: iterate over words using a generator function
"""
import re
import reprlib
RE_WORD = re.compile('\w+')
class Sentence:
def __init__(self, text):
self.text = text # <1>
def __repr__(self):
return 'Sentence(%s)' % reprlib.repr(self.text)
def __iter__(self):
for match in RE_WORD.finditer(self.text): # <2>
yield match.group()
(6)Sentence类第5版:生成器表达式
例如:使用生成器表达式实现Sentence类
"""
Sentence: iterate over words using a generator expression
"""
import re
import reprlib
RE_WORD = re.compile('\w+')
class Sentence:
def __init__(self, text):
self.text = text
def __repr__(self):
return 'Sentence(%s)' % reprlib.repr(self.text)
def __iter__(self):
return (match.group() for match in RE_WORD.finditer(self.text))
(7)另一个示例:等差数列生成器
典型的迭代器模式作用很简单——遍历数据结构。
"""
Arithmetic progression class
>>> ap = ArithmeticProgression(0, 1, 3)
>>> list(ap)
[0, 1, 2]
>>> ap = ArithmeticProgression(1, .5, 3)
>>> list(ap)
[1.0, 1.5, 2.0, 2.5]
>>> ap = ArithmeticProgression(0, 1/3, 1)
>>> list(ap)
[0.0, 0.3333333333333333, 0.6666666666666666]
>>> from fractions import Fraction
>>> ap = ArithmeticProgression(0, Fraction(1, 3), 1)
>>> list(ap)
[Fraction(0, 1), Fraction(1, 3), Fraction(2, 3)]
>>> from decimal import Decimal
>>> ap = ArithmeticProgression(0, Decimal('.1'), .3)
>>> list(ap)
[Decimal('0.0'), Decimal('0.1'), Decimal('0.2')]
"""
class ArithmeticProgression:
def __init__(self, begin, step, end=None):
self.begin = begin
self.step = step
self.end = end # None -> "infinite" series
def __iter__(self):
result = type(self.begin + self.step)(self.begin)
forever = self.end is None
index = 0
while forever or result < self.end:
yield result
index += 1
result = self.begin + self.step * index
利用itertools模块生成等差数列
下例返回一个生成器,因此它与其他生成器函数一样,也是生成器工厂函数。
import itertools
def aritprog_gen(begin, step, end=None):
first = type(begin + step)(begin)
ap_gen = itertools.count(first, step)
if end is not None:
ap_gen = itertools.takewhile(lambda n: n < end, ap_gen)
return ap_gen
(8)标准库中的生成器函数
第一组是用于过滤的生成器函数:从输入的可迭代对象中产出元素的子集,而且不修改元素本身。


>>> def vowel(c):
... return c.lower() in 'aeiou'
...
>>> list(filter(vowel, 'Aardvark'))
['A', 'a', 'a']
>>> import itertools
>>> list(itertools.filterfalse(vowel, 'Aardvark'))
['r', 'd', 'v', 'r', 'k']
>>> list(itertools.dropwhile(vowel, 'Aardvark'))
['r', 'd', 'v', 'a', 'r', 'k']
>>> list(itertools.takewhile(vowel, 'Aardvark'))
['A', 'a']
>>> list(itertools.compress('Aardvark', (1,0,1,1,0,1)))
['A', 'r', 'd', 'a']
>>> list(itertools.islice('Aardvark', 4))
['A', 'a', 'r', 'd']
>>> list(itertools.islice('Aardvark', 4, 7))
['v', 'a', 'r']
>>> list(itertools.islice('Aardvark', 1, 7, 2))
['a', 'd', 'a']
第二组是用于映射的生成器函数:在输入的单个可迭代对象中的各个元素上做计算,然后返回结果

>>> sample = [5, 4, 2, 8, 7, 6, 3, 0, 9, 1]
>>> import itertools
>>> list(itertools.accumulate(sample)) #
[5, 9, 11, 19, 26, 32, 35, 35, 44, 45]
>>> list(itertools.accumulate(sample, min)) #
[5, 4, 2, 2, 2, 2, 2, 0, 0, 0]
>>> list(itertools.accumulate(sample, max)) #
[5, 5, 5, 8, 8, 8, 8, 8, 9, 9]
>>> import operator
>>> list(itertools.accumulate(sample, operator.mul)) #
[5, 20, 40, 320, 2240, 13440, 40320, 0, 0, 0]
>>> list(itertools.accumulate(range(1, 11), operator.mul))
[1, 2, 6, 24, 120, 720, 5040, 40320, 362880, 3628800]
>>> list(enumerate('albatroz', 1)) #
[(1, 'a'), (2, 'l'), (3, 'b'), (4, 'a'), (5, 't'), (6, 'r'), (7, 'o'), (8, 'z')]
>>> import operator
>>> list(map(operator.mul, range(11), range(11))) #
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
>>> list(map(operator.mul, range(11), [2, 4, 8])) #
[0, 4, 16]
>>> list(map(lambda a, b: (a, b), range(11), [2, 4, 8]))
[(0, 2), (1, 4), (2, 8)]
>>> import itertools
>>> list(itertools.starmap(operator.mul, enumerate('albatroz', 1))) #
['a', 'll', 'bbb', 'aaaa', 'ttttt', 'rrrrrr', 'ooooooo', 'zzzzzzzz']
>>> sample = [5, 4, 2, 8, 7, 6, 3, 0, 9, 1]
>>> list(itertools.starmap(lambda a, b: b/a,
... enumerate(itertools.accumulate(sample), 1))) #
[5.0, 4.5, 3.6666666666666665, 4.75, 5.2, 5.333333333333333,
5.0, 4.375, 4.888888888888889, 4.5]
第三组是用于合并的生成器函数,这些函数都从输入的多个可迭代对象中产出元素。

>>> list(itertools.chain('ABC', range(2))) #
['A', 'B', 'C', 0, 1]
>>> list(itertools.chain(enumerate('ABC'))) #
[(0, 'A'), (1, 'B'), (2, 'C')]
>>> list(itertools.chain.from_iterable(enumerate('ABC'))) #
[0, 'A', 1, 'B', 2, 'C']
>>> list(zip('ABC', range(5))) #
[('A', 0), ('B', 1), ('C', 2)]
>>> list(zip('ABC', range(5), [10, 20, 30, 40])) #
[('A', 0, 10), ('B', 1, 20), ('C', 2, 30)]
>>> list(itertools.zip_longest('ABC', range(5))) #
[('A', 0), ('B', 1), ('C', 2), (None, 3), (None, 4)]
>>> list(itertools.zip_longest('ABC', range(5), fillvalue='?')) #
[('A', 0), ('B', 1), ('C', 2), ('?', 3), ('?', 4)]
>>> list(itertools.product('ABC', range(2))) #
[('A', 0), ('A', 1), ('B', 0), ('B', 1), ('C', 0), ('C', 1)]
>>> suits = 'spades hearts diamonds clubs'.split()
>>> list(itertools.product('AK', suits)) #
[('A', 'spades'), ('A', 'hearts'), ('A', 'diamonds'), ('A', 'clubs'),
('K', 'spades'), ('K', 'hearts'), ('K', 'diamonds'), ('K', 'clubs')]
>>> list(itertools.product('ABC')) #
[('A',), ('B',), ('C',)]
>>> list(itertools.product('ABC', repeat=2)) #
[('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'B'),
('B', 'C'), ('C', 'A'), ('C', 'B'), ('C', 'C')]
>>> list(itertools.product(range(2), repeat=3))
[(0, 0, 0), (0, 0, 1), (0, 1, 0), (0, 1, 1), (1, 0, 0),
(1, 0, 1), (1, 1, 0), (1, 1, 1)]
>>> rows = itertools.product('AB', range(2), repeat=2)
>>> for row in rows: print(row)
...
('A', 0, 'A', 0)
('A', 0, 'A', 1)
('A', 0, 'B', 0)
('A', 0, 'B', 1)
('A', 1, 'A', 0)
('A', 1, 'A', 1)
('A', 1, 'B', 0)
('A', 1, 'B', 1)
('B', 0, 'A', 0)
('B', 0, 'A', 1)
('B', 0, 'B', 0)
('B', 0, 'B', 1)
('B', 1, 'A', 0)
('B', 1, 'A', 1)
('B', 1, 'B', 0)
('B', 1, 'B', 1)
第四组生成器函数会从一个元素中产出多个值,扩展输入的可迭代对象。


>>> ct = itertools.count() #
>>> next(ct) #
0
>>> next(ct), next(ct), next(ct) #
(1, 2, 3)
>>> list(itertools.islice(itertools.count(1, .3), 3)) #
[1, 1.3, 1.6]
>>> cy = itertools.cycle('ABC') #
>>> next(cy)
'A'
>>> list(itertools.islice(cy, 7)) #
['B', 'C', 'A', 'B', 'C', 'A', 'B']
>>> rp = itertools.repeat(7) #
>>> next(rp), next(rp)
(7, 7)
>>> list(itertools.repeat(8, 4)) #
[8, 8, 8, 8]
>>> list(map(operator.mul, range(11), itertools.repeat(5))) #
[0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50]
>>> list(itertools.combinations('ABC', 2)) #
[('A', 'B'), ('A', 'C'), ('B', 'C')]
>>> list(itertools.combinations_with_replacement('ABC', 2)) #
[('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'B'), ('B', 'C'), ('C', 'C')]
>>> list(itertools.permutations('ABC', 2)) #
[('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'C'), ('C', 'A'), ('C', 'B')]
>>> list(itertools.product('ABC', repeat=2)) #
[('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'B'), ('B', 'C'),
('C', 'A'), ('C', 'B'), ('C', 'C')]
第五组的生成器函数用于产出输入的可迭代对象中的全部元素,不过会以某种方式重新排列


>>> list(itertools.groupby('LLLLAAGGG')) #
[('L', ),
('A', ),
('G', )]
>>> for char, group in itertools.groupby('LLLLAAAGG'): #
... print(char, '->', list(group))
...
L -> ['L', 'L', 'L', 'L']
A -> ['A', 'A',]
G -> ['G', 'G', 'G']
>>> animals = ['duck', 'eagle', 'rat', 'giraffe', 'bear',
... 'bat', 'dolphin', 'shark', 'lion']
>>> animals.sort(key=len) #
>>> animals
['rat', 'bat', 'duck', 'bear', 'lion', 'eagle', 'shark',
'giraffe', 'dolphin']
>>> for length, group in itertools.groupby(animals, len): #
... print(length, '->', list(group))
...
3 -> ['rat', 'bat']
4 -> ['duck', 'bear', 'lion']
5 -> ['eagle', 'shark']
7 -> ['giraffe', 'dolphin']
>>> for length, group in itertools.groupby(reversed(animals), len): #
... print(length, '->', list(group))
...
7 -> ['dolphin', 'giraffe']
5 -> ['shark', 'eagle']
4 -> ['lion', 'bear', 'duck']
3 -> ['bat', 'rat']
>>> list(itertools.tee('ABC'))
[, ]
>>> g1, g2 = itertools.tee('ABC')
>>> next(g1)
'A'
>>> next(g2)
'A'
>>> next(g2)
'B'
>>> list(g1)
['B', 'C']
>>> list(g2)
['C']
>>> list(zip(*itertools.tee('ABC')))
[('A', 'A'), ('B', 'B'), ('C', 'C')]
(9)Python 3.3中新出现的句法:yield from
如果生成器函数需要产出另一个生成器生成的值,传统的解决方法是使用嵌套的for循环。
例如,实现自己的chain生成器
>>> def chain(*iterables):
... for it in iterables:
... for i in it:
... yield i
...
>>> s = 'ABC'
>>> t = tuple(range(3))
>>> list(chain(s, t))
['A', 'B', 'C', 0, 1, 2]
可以用下列方式替代实现。
>>> def chain(*iterables):
... for i in iterables:
... yield from i
...
>>> list(chain(s, t))
['A', 'B', 'C', 0, 1, 2]
这里可以看到,yield from i 完全代替了内层的for循环。
(11)可迭代的归约函数


>>> all([1, 2, 3])
True
>>> all([1, 0, 3])
False
>>> all([])
True
>>> any([1, 2, 3])
True
>>> any([1, 0, 3])
True
>>> any([0, 0.0])
False
>>> any([])
False
>>> g = (n for n in [0, 0.0, 7, 8])
>>> any(g)
True
>>> next(g)
8
控制流程:协程
从句法上看,协程与生成器类似,都是定义体中包含yield关键字的函数。不管数据如何流动,yield都是一种流程控制工具,使用它可以实现协作式多任务;协程可以把控制器让步给中心调度程序,从而激活其他的协程。
(1)用作协程的生成器的基本行为
例如:可能是协程最简单的使用演示
>>> def simple_coroutine():
... print('-> coroutine started')
... x = yield
... print('-> coroutine received:', x)
...
>>> my_coro = simple_coroutine()
>>> my_coro
>>> next(my_coro)
-> coroutine started
>>> my_coro.send(42)
-> coroutine received: 42
Traceback (most recent call last):
...
StopIteration
协程可以身处四个状态中的一个。
- 'GEN_CREATED' —— 等待开始执行
- 'GEN_RUNNING' —— 解释器正在执行
- 'GEN_SUSPENDED' —— 在yield表达式处暂停
- 'GEN_CLOSED' —— 执行结束
仅当协程处于暂停状态时才能调用send方法。不过,如果协程还没激活,情况就不同了。因此,始终要调用next(my_coro)激活协程——也可以调用my_coro.send(None),效果一样。最先调用next(my_coro)函数这一步通常称为“预激”(prime)协程(即,让协程向前执行到第一个yield表达式,准备好作为活跃的协程使用)。
例如:产出两个值的协程
>>> def simple_coro2(a):
... print('-> Started: a =', a)
... b = yield a
... print('-> Received: b =', b)
... c = yield a + b
... print('-> Received: c =', c)
...
>>> my_coro2 = simple_coro2(14)
>>> from inspect import getgeneratorstate
>>> getgeneratorstate(my_coro2)
'GEN_CREATED'
>>> next(my_coro2)
-> Started: a = 14
14
>>> getgeneratorstate(my_coro2)
'GEN_SUSPENDED'
>>> my_coro2.send(28)
-> Received: b = 28
42
>>> my_coro2.send(99)
-> Received: c = 99
Traceback (most recent call last):
File "", line 1, in
StopIteration
>>> getgeneratorstate(my_coro2)
'GEN_CLOSED'

(2)使用协程计算移动平均值
例如:定义一个计算移动平均值的协程
"""
A coroutine to compute a running average
>>> coro_avg = averager() # <1>
>>> next(coro_avg) # <2>
>>> coro_avg.send(10) # <3>
10.0
>>> coro_avg.send(30)
20.0
>>> coro_avg.send(5)
15.0
"""
def averager():
total = 0.0
count = 0
average = None
while True: # <1>
term = yield average # <2>
total += term
count += 1
average = total/count
(3)预激协程的装饰器
如果不预激,那么协程没什么用。调用my_coro.send(x)之前,记住一定要调用next(my_coro)。为了简化协程的用法,有时会使用一个预激装饰器。
from functools import wraps
def coroutine(func):
"""Decorator: primes `func` by advancing to first `yield`"""
@wraps(func)
def primer(*args,**kwargs): # <1>
gen = func(*args,**kwargs) # <2>
next(gen) # <3>
return gen # <4>
return primer
"""
A coroutine to compute a running average
>>> coro_avg = averager()
>>> from inspect import getgeneratorstate
>>> getgeneratorstate(coro_avg)
'GEN_SUSPENDED'
>>> coro_avg.send(10)
10.0
>>> coro_avg.send(30)
20.0
>>> coro_avg.send(5)
15.0
"""
from coroutil import coroutine
@coroutine
def averager():
total = 0.0
count = 0
average = None
while True:
term = yield average
total += term
count += 1
average = total/count
(4)终止协程和异常处理
例如:未处理的异常会导致协程终止
>>> from coroaverager1 import averager
>>> coro_avg = averager()
>>> coro_avg.send(40)
40.0
>>> coro_avg.send(50)
45.0
>>> coro_avg.send('spam') #
Traceback (most recent call last):
...
TypeError: unsupported operand type(s) for +=: 'float' and 'str'
>>> coro_avg.send(60) #
Traceback (most recent call last):
File "", line 1, in
StopIteration
这里暗示了终止协程的一种方式:发送某个哨符值,让协程退出。内置的None和Ellipsis等常量经常用作哨符值。
从Python 2.5 开始,客户代码可以在生成器对象上调用两个方法,显式地把异常发给协程。这两个方法是throw和close。
- generator.throw(exc_type[, exc_value[, traceback]]) —— 致使生成器在暂停的yield表达式处抛出指定的异常。
- generator.close() —— 致使生成器在暂停的yield表达式处抛出GeneratorExit异常。
下面说明如何使用close和throw方法控制协程。
"""
Coroutine closing demonstration::
# BEGIN DEMO_CORO_EXC_1
>>> exc_coro = demo_exc_handling()
>>> next(exc_coro)
-> coroutine started
>>> exc_coro.send(11)
-> coroutine received: 11
>>> exc_coro.send(22)
-> coroutine received: 22
>>> exc_coro.close()
>>> from inspect import getgeneratorstate
>>> getgeneratorstate(exc_coro)
'GEN_CLOSED'
# END DEMO_CORO_EXC_1
Coroutine handling exception::
# BEGIN DEMO_CORO_EXC_2
>>> exc_coro = demo_exc_handling()
>>> next(exc_coro)
-> coroutine started
>>> exc_coro.send(11)
-> coroutine received: 11
>>> exc_coro.throw(DemoException)
*** DemoException handled. Continuing...
>>> getgeneratorstate(exc_coro)
'GEN_SUSPENDED'
# END DEMO_CORO_EXC_2
Coroutine not handling exception::
# BEGIN DEMO_CORO_EXC_3
>>> exc_coro = demo_exc_handling()
>>> next(exc_coro)
-> coroutine started
>>> exc_coro.send(11)
-> coroutine received: 11
>>> exc_coro.throw(ZeroDivisionError)
Traceback (most recent call last):
...
ZeroDivisionError
>>> getgeneratorstate(exc_coro)
'GEN_CLOSED'
# END DEMO_CORO_EXC_3
"""
class DemoException(Exception):
"""An exception type for the demonstration."""
def demo_exc_handling():
print('-> coroutine started')
while True:
try:
x = yield
except DemoException:
print('*** DemoException handled. Continuing...')
else:
print('-> coroutine received: {!r}'.format(x))
raise RuntimeError('This line should never run.')
(5)让协程返回值
例如:定义一个求平均值的协程,让它返回一个结果
"""
A coroutine to compute a running average.
Testing ``averager`` by itself::
# BEGIN RETURNING_AVERAGER_DEMO1
>>> coro_avg = averager()
>>> next(coro_avg)
>>> coro_avg.send(10) # <1>
>>> coro_avg.send(30)
>>> coro_avg.send(6.5)
>>> coro_avg.send(None) # <2>
Traceback (most recent call last):
...
StopIteration: Result(count=3, average=15.5)
# END RETURNING_AVERAGER_DEMO1
Catching `StopIteration` to extract the value returned by
the coroutine::
# BEGIN RETURNING_AVERAGER_DEMO2
>>> coro_avg = averager()
>>> next(coro_avg)
>>> coro_avg.send(10)
>>> coro_avg.send(30)
>>> coro_avg.send(6.5)
>>> try:
... coro_avg.send(None)
... except StopIteration as exc:
... result = exc.value
...
>>> result
Result(count=3, average=15.5)
# END RETURNING_AVERAGER_DEMO2
"""
from collections import namedtuple
Result = namedtuple('Result', 'count average')
def averager():
total = 0.0
count = 0
average = None
while True:
term = yield
if term is None:
break # <1>
total += term
count += 1
average = total/count
return Result(count, average)
(6)使用yield from
例如
>>> def gen():
... for c in 'AB':
... yield c
... for i in range(1, 3):
... yield i
...
>>> list(gen())
['A', 'B', 1, 2]
可以改写为
>>> def gen():
... yield from 'AB'
... yield from range(1, 3)
...
>>> list(gen())
['A', 'B', 1, 2]
yield from x 表达式对x对象所做的第一件事是,调用iter(x),从中获取迭代器。因此,x可以使任何可迭代对象。
yield from 的主要功能是打开双向通道,把最外层的调用方与最内层的子生成器连接起来,这样二者可以直接发送和产出值,还可以直接传入异常,而不用在位于中间的协程中添加大量处理异常的样板代码。
术语
- 委派生成器(delegating generator) —— 包含yield from
表达式的生成器函数 - 子生成器(subgenerator) —— 从yield from 表达式中
部分获取的生成器 - 调用方(caller) —— 指代调用委派生成器的客户端代码
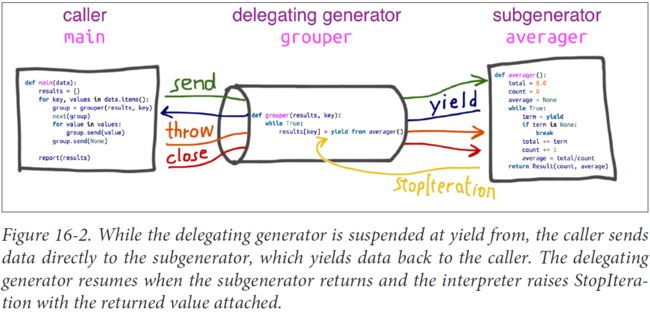
使用yield from 计算平均值并输出统计报告
"""
A coroutine to compute a running average.
Testing ``averager`` by itself::
>>> coro_avg = averager()
>>> next(coro_avg)
>>> coro_avg.send(10)
>>> coro_avg.send(30)
>>> coro_avg.send(6.5)
>>> coro_avg.send(None)
Traceback (most recent call last):
...
StopIteration: Result(count=3, average=15.5)
Driving it with ``yield from``::
>>> def summarize(results):
... while True:
... result = yield from averager()
... results.append(result)
...
>>> results = []
>>> summary = summarize(results)
>>> next(summary)
>>> for height in data['girls;m']:
... summary.send(height)
...
>>> summary.send(None)
>>> for height in data['boys;m']:
... summary.send(height)
...
>>> summary.send(None)
>>> results == [
... Result(count=10, average=1.4279999999999997),
... Result(count=9, average=1.3888888888888888)
... ]
True
"""
# BEGIN YIELD_FROM_AVERAGER
from collections import namedtuple
Result = namedtuple('Result', 'count average')
# the subgenerator
def averager(): # <1>
total = 0.0
count = 0
average = None
while True:
term = yield # <2>
if term is None: # <3>
break
total += term
count += 1
average = total/count
return Result(count, average) # <4>
# the delegating generator
def grouper(results, key): # <5>
while True: # <6>
results[key] = yield from averager() # <7>
# the client code, a.k.a. the caller
def main(data): # <8>
results = {}
for key, values in data.items():
group = grouper(results, key) # <9>
next(group) # <10>
for value in values:
group.send(value) # <11>
group.send(None) # important! <12>
# print(results) # uncomment to debug
report(results)
# output report
def report(results):
for key, result in sorted(results.items()):
group, unit = key.split(';')
print('{:2} {:5} averaging {:.2f}{}'.format(
result.count, group, result.average, unit))
data = {
'girls;kg':
[40.9, 38.5, 44.3, 42.2, 45.2, 41.7, 44.5, 38.0, 40.6, 44.5],
'girls;m':
[1.6, 1.51, 1.4, 1.3, 1.41, 1.39, 1.33, 1.46, 1.45, 1.43],
'boys;kg':
[39.0, 40.8, 43.2, 40.8, 43.1, 38.6, 41.4, 40.6, 36.3],
'boys;m':
[1.38, 1.5, 1.32, 1.25, 1.37, 1.48, 1.25, 1.49, 1.46],
}
if __name__ == '__main__':
main(data)
委派生成器相当于管道,可以把任意数量个委派生成器连接在一起:一个委派生成器使用yield from调用一个子生成器,而那个子生成器本身也是委派生成器,使用yield from调用另一个子生成器,以此类推。最终,这个链条要以一个只使用yield表达式的简单生成器结束。
任何yield from链条都必须由客户驱动,在最外层委派生成器上调用next(...)函数或.send(...)方法。可以隐式调用,例如使用for循环。
(7)使用案例:使用协程做离散事件仿真
"""
Taxi simulator
==============
Driving a taxi from the console::
>>> from taxi_sim import taxi_process
>>> taxi = taxi_process(ident=13, trips=2, start_time=0)
>>> next(taxi)
Event(time=0, proc=13, action='leave garage')
>>> taxi.send(_.time + 7)
Event(time=7, proc=13, action='pick up passenger')
>>> taxi.send(_.time + 23)
Event(time=30, proc=13, action='drop off passenger')
>>> taxi.send(_.time + 5)
Event(time=35, proc=13, action='pick up passenger')
>>> taxi.send(_.time + 48)
Event(time=83, proc=13, action='drop off passenger')
>>> taxi.send(_.time + 1)
Event(time=84, proc=13, action='going home')
>>> taxi.send(_.time + 10)
Traceback (most recent call last):
File "", line 1, in
StopIteration
Sample run with two cars, random seed 10. This is a valid doctest::
>>> main(num_taxis=2, seed=10)
taxi: 0 Event(time=0, proc=0, action='leave garage')
taxi: 0 Event(time=5, proc=0, action='pick up passenger')
taxi: 1 Event(time=5, proc=1, action='leave garage')
taxi: 1 Event(time=10, proc=1, action='pick up passenger')
taxi: 1 Event(time=15, proc=1, action='drop off passenger')
taxi: 0 Event(time=17, proc=0, action='drop off passenger')
taxi: 1 Event(time=24, proc=1, action='pick up passenger')
taxi: 0 Event(time=26, proc=0, action='pick up passenger')
taxi: 0 Event(time=30, proc=0, action='drop off passenger')
taxi: 0 Event(time=34, proc=0, action='going home')
taxi: 1 Event(time=46, proc=1, action='drop off passenger')
taxi: 1 Event(time=48, proc=1, action='pick up passenger')
taxi: 1 Event(time=110, proc=1, action='drop off passenger')
taxi: 1 Event(time=139, proc=1, action='pick up passenger')
taxi: 1 Event(time=140, proc=1, action='drop off passenger')
taxi: 1 Event(time=150, proc=1, action='going home')
*** end of events ***
See longer sample run at the end of this module.
"""
import random
import collections
import queue
import argparse
import time
DEFAULT_NUMBER_OF_TAXIS = 3
DEFAULT_END_TIME = 180
SEARCH_DURATION = 5
TRIP_DURATION = 20
DEPARTURE_INTERVAL = 5
Event = collections.namedtuple('Event', 'time proc action')
# BEGIN TAXI_PROCESS
def taxi_process(ident, trips, start_time=0): # <1>
"""Yield to simulator issuing event at each state change"""
time = yield Event(start_time, ident, 'leave garage') # <2>
for i in range(trips): # <3>
time = yield Event(time, ident, 'pick up passenger') # <4>
time = yield Event(time, ident, 'drop off passenger') # <5>
yield Event(time, ident, 'going home') # <6>
# end of taxi process # <7>
# END TAXI_PROCESS
# BEGIN TAXI_SIMULATOR
class Simulator:
def __init__(self, procs_map):
self.events = queue.PriorityQueue()
self.procs = dict(procs_map)
def run(self, end_time): # <1>
"""Schedule and display events until time is up"""
# schedule the first event for each cab
for _, proc in sorted(self.procs.items()): # <2>
first_event = next(proc) # <3>
self.events.put(first_event) # <4>
# main loop of the simulation
sim_time = 0 # <5>
while sim_time < end_time: # <6>
if self.events.empty(): # <7>
print('*** end of events ***')
break
current_event = self.events.get() # <8>
sim_time, proc_id, previous_action = current_event # <9>
print('taxi:', proc_id, proc_id * ' ', current_event) # <10>
active_proc = self.procs[proc_id] # <11>
next_time = sim_time + compute_duration(previous_action) # <12>
try:
next_event = active_proc.send(next_time) # <13>
except StopIteration:
del self.procs[proc_id] # <14>
else:
self.events.put(next_event) # <15>
else: # <16>
msg = '*** end of simulation time: {} events pending ***'
print(msg.format(self.events.qsize()))
# END TAXI_SIMULATOR
def compute_duration(previous_action):
"""Compute action duration using exponential distribution"""
if previous_action in ['leave garage', 'drop off passenger']:
# new state is prowling
interval = SEARCH_DURATION
elif previous_action == 'pick up passenger':
# new state is trip
interval = TRIP_DURATION
elif previous_action == 'going home':
interval = 1
else:
raise ValueError('Unknown previous_action: %s' % previous_action)
return int(random.expovariate(1/interval)) + 1
def main(end_time=DEFAULT_END_TIME, num_taxis=DEFAULT_NUMBER_OF_TAXIS,
seed=None):
"""Initialize random generator, build procs and run simulation"""
if seed is not None:
random.seed(seed) # get reproducible results
taxis = {i: taxi_process(i, (i+1)*2, i*DEPARTURE_INTERVAL)
for i in range(num_taxis)}
sim = Simulator(taxis)
sim.run(end_time)
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description='Taxi fleet simulator.')
parser.add_argument('-e', '--end-time', type=int,
default=DEFAULT_END_TIME,
help='simulation end time; default = %s'
% DEFAULT_END_TIME)
parser.add_argument('-t', '--taxis', type=int,
default=DEFAULT_NUMBER_OF_TAXIS,
help='number of taxis running; default = %s'
% DEFAULT_NUMBER_OF_TAXIS)
parser.add_argument('-s', '--seed', type=int, default=None,
help='random generator seed (for testing)')
args = parser.parse_args()
main(args.end_time, args.taxis, args.seed)
"""
Sample run from the command line, seed=3, maximum elapsed time=120::
# BEGIN TAXI_SAMPLE_RUN
$ python3 taxi_sim.py -s 3 -e 120
taxi: 0 Event(time=0, proc=0, action='leave garage')
taxi: 0 Event(time=2, proc=0, action='pick up passenger')
taxi: 1 Event(time=5, proc=1, action='leave garage')
taxi: 1 Event(time=8, proc=1, action='pick up passenger')
taxi: 2 Event(time=10, proc=2, action='leave garage')
taxi: 2 Event(time=15, proc=2, action='pick up passenger')
taxi: 2 Event(time=17, proc=2, action='drop off passenger')
taxi: 0 Event(time=18, proc=0, action='drop off passenger')
taxi: 2 Event(time=18, proc=2, action='pick up passenger')
taxi: 2 Event(time=25, proc=2, action='drop off passenger')
taxi: 1 Event(time=27, proc=1, action='drop off passenger')
taxi: 2 Event(time=27, proc=2, action='pick up passenger')
taxi: 0 Event(time=28, proc=0, action='pick up passenger')
taxi: 2 Event(time=40, proc=2, action='drop off passenger')
taxi: 2 Event(time=44, proc=2, action='pick up passenger')
taxi: 1 Event(time=55, proc=1, action='pick up passenger')
taxi: 1 Event(time=59, proc=1, action='drop off passenger')
taxi: 0 Event(time=65, proc=0, action='drop off passenger')
taxi: 1 Event(time=65, proc=1, action='pick up passenger')
taxi: 2 Event(time=65, proc=2, action='drop off passenger')
taxi: 2 Event(time=72, proc=2, action='pick up passenger')
taxi: 0 Event(time=76, proc=0, action='going home')
taxi: 1 Event(time=80, proc=1, action='drop off passenger')
taxi: 1 Event(time=88, proc=1, action='pick up passenger')
taxi: 2 Event(time=95, proc=2, action='drop off passenger')
taxi: 2 Event(time=97, proc=2, action='pick up passenger')
taxi: 2 Event(time=98, proc=2, action='drop off passenger')
taxi: 1 Event(time=106, proc=1, action='drop off passenger')
taxi: 2 Event(time=109, proc=2, action='going home')
taxi: 1 Event(time=110, proc=1, action='going home')
*** end of events ***
# END TAXI_SAMPLE_RUN
"""