一、摘要
在《深入剖析Java关键字之volatile》的文章中,我们知道volatile关键字能够解决多线程编程中的可见性,顺序性这两大问题,但是不能解决原子性的问题。那么,Java中是否有关键字能解决原子性问题呢?这就是我们接下来需要介绍的synchronized关键字,它是并发编程中的线程安全的重要保障方式之一,它能保证可见性,顺序性和原子性的问题。而且在《JMM之happens-before详解》这篇文章中,我们知道了happens-before规则中的有一条是监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。那么,JVM是如何实现synchronized这些比较厉害的特性的呢?本文将从原理层面介绍synchronized的特性。
二、synchronized的使用方式
synchronized关键字最主要的三种应用方式如下:
- 修饰实例方法,锁是当前实例对象,进入同步代码前要获得当前实例的锁;
- 修饰静态方法,锁是当前类的Class对象,进入同步代码前要获得当前类对象的锁;
-
修饰代码块,锁是Synchonized括号里配置的对象,指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁;
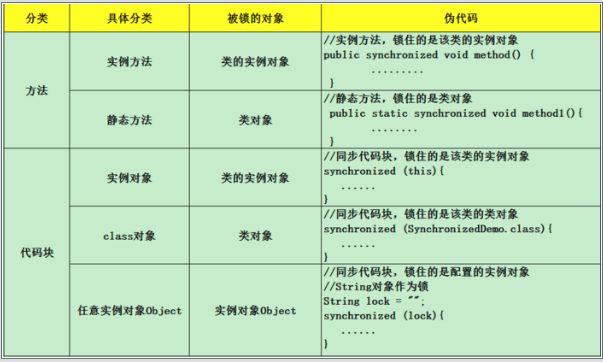
下面 依次来举例说明synchronized关键字的三种使用方式;
2.1 synchronized作用于实例方法
使用synchronized标记实例方法时(非静态方法),只有获得该方法对应类实例的锁才能执行,否则所属线程将被阻塞,方法一旦执行,就独占该锁,直到该方法执行完毕将锁释放,被阻塞的线程才能获得锁从而执行。这种机制确保了同一时刻该类同一个实例,所有声明为synchronized的函数中只有一个方法处于可执行状态,从而有效避免了类实例成员变量访问冲突。举例如下:
/**
* synchronized作用于类实例方法
*
* @author Sunny
* @version 1.0
* @taskId:
* @createDate 2019/02/27 14:31
* @see com.sunny.concurrent.synchronizedkey
*/
public class SynchronizedMethod implements Runnable{
private static int count = 0;
public synchronized void increase() {
count++;
}
@Override
public void run() {
for (int i = 0; i < 1000000; i++) {
increase();
System.out.println(Thread.currentThread().getName() + " : " + count);
}
}
public static void main(String[] args) throws InterruptedException {
SynchronizedMethod sm = new SynchronizedMethod();
Thread t1 = new Thread(sm);
Thread t2 = new Thread(sm);
Thread t3 = new Thread(sm);
t1.start();
t2.start();
t3.start();
t1.join();
t2.join();
t3.join();
System.out.println(count);
}
}
以上程序输出如下:
...............................
Thread-0 : 2999990
Thread-0 : 2999991
Thread-0 : 2999992
Thread-0 : 2999993
Thread-0 : 2999994
Thread-0 : 2999995
Thread-0 : 2999996
Thread-0 : 2999997
Thread-0 : 2999998
Thread-0 : 2999999
Thread-0 : 3000000
3000000
多次执行,不能保证每个线程每次打印的值是一样的,但是一定能保证最后一次打印出count的值是3000000;上面的程序,我们开启了三个线程操作同一个共享变量count,由于count++操作并不具备原子性,该操作是先读取值,然后写会一个新值,相当于原来的值加上1,分两步完成;如果其他线程在第一个线程读取旧值和写会新值期间读取count的值,那么其他线程就会与第一个线程一起看到同一个值,并执行相同值的加1操作,这也就造成了线程安全失败,因此对于increase方法必须使用synchronized修饰来保证线程安全,这个与volatile文章的分析类似。
注意: 当synchronized修饰实例方法时,同一个类的不同对象实例,具有不同的锁,同一个类的同一个实例具有相同的锁,此时的锁是锁住的对象实例。当一个线程正在访问一个对象的 synchronized 实例方法,那么其他线程不能访问该对象的其他 synchronized 方法,毕竟一个对象实例只有一把锁,当一个线程获取了该对象实例的锁之后,其他线程无法获取该对象实例的锁,所以无法访问该对象实例的其他synchronized实例方法,但是其他线程还是可以访问该实例对象的其他非synchronized方法,当然如果是一个线程 A 需要访问对象实例 object1 的 synchronized 方法 f1(当前对象锁是object1 ),另一个线程 B 需要访问实例对象 object12的 synchronized 方法 f2(当前对象锁是object2),这样是允许的,因为两个实例对象锁并不同相同,此时如果两个线程操作数据并非共享的,线程安全是有保障的,遗憾的是如果两个线程操作的是共享数据,那么线程安全就有可能无法保证了,我们把上面的程序稍微做一下改造,如下:
/**
* synchronized作用于类实例方法,因为每个线程是不同的实例对象,所以synchronized并不能生效
*
* @author Sunny
* @version 1.0
* @taskId:
* @createDate 2019/02/27 14:31
* @see com.sunny.concurrent.synchronizedkey
*/
public class SynchronizedMethodIncorrect implements Runnable{
private static int count = 0;
public synchronized void increase(){
count++;
}
@Override
public void run() {
for (int i = 0; i < 1000000; i++) {
increase();
System.out.println(Thread.currentThread().getName() + " : " + count);
}
}
public static void main(String[] args) throws InterruptedException {
SynchronizedMethodIncorrect smi1 = new SynchronizedMethodIncorrect();
SynchronizedMethodIncorrect smi2 = new SynchronizedMethodIncorrect();
SynchronizedMethodIncorrect smi3 = new SynchronizedMethodIncorrect();
Thread t1 = new Thread(smi1);
Thread t2 = new Thread(smi2);
Thread t3 = new Thread(smi3);
t1.start();
t2.start();
t3.start();
t1.join();
t2.join();
t3.join();
System.out.println(count);
}
}
上面程序的输出如下:
...............................
Thread-0 : 2999987
Thread-0 : 2999988
Thread-0 : 2999989
Thread-0 : 2999990
Thread-0 : 2999991
Thread-0 : 2999992
Thread-0 : 2999993
Thread-0 : 2999994
Thread-0 : 2999995
Thread-0 : 2999996
Thread-0 : 2999997
2999997
2999997并不是我们想要的结果,上面的程序我们实例化了三个SynchronizedMethodIncorrect 对象,每个对象由于每个线程获取的对象实例的锁是不同的实例对象,所以synchronized并不能生效;
2.2 synchronized作用于静态方法
在《Java运行时内存区域》中我们知道静态方法存放在方法区(当然,JDK1.8之后做了调整,静态方法应该也存储在Java的堆中),而且静态方法与类实例的方法不一样,它是属于类的,不属于任何一个对象实例,因此,对静态方法进行加锁,锁住的是当前类的Class对象。我们对2.1节中不正确的例子稍微做一些改造,在increase方法上面增加static进行修饰,如下:
/**
* synchronized作用于静态方法
*
* @author Sunny
* @version 1.0
* @taskId:
* @createDate 2019/02/27 14:31
* @see com.sunny.concurrent.synchronizedkey
*/
public class SynchronizedStatic implements Runnable{
private static int count = 0;
public synchronized static void increase() {
count++;
}
@Override
public void run() {
for (int i = 0; i < 1000000; i++) {
increase();
System.out.println(Thread.currentThread().getName() + " : " + count);
}
}
public static void main(String[] args) throws InterruptedException {
SynchronizedStatic sm1 = new SynchronizedStatic();
SynchronizedStatic sm2 = new SynchronizedStatic();
SynchronizedStatic sm3 = new SynchronizedStatic();
Thread t1 = new Thread(sm1);
Thread t2 = new Thread(sm2);
Thread t3 = new Thread(sm3);
t1.start();
t2.start();
t3.start();
t1.join();
t2.join();
t3.join();
System.out.println(count);
}
}
以上程序输出结果如下:
...............................
Thread-0 : 2999974
Thread-0 : 2999975
Thread-0 : 2999976
Thread-0 : 2999977
Thread-0 : 2999978
Thread-0 : 2999979
Thread-0 : 2999980
Thread-0 : 2999981
Thread-0 : 2999982
Thread-0 : 2999983
Thread-0 : 2999984
Thread-0 : 2999985
Thread-0 : 2999986
Thread-0 : 2999987
Thread-0 : 2999988
Thread-0 : 2999989
Thread-0 : 2999990
Thread-0 : 2999991
Thread-0 : 2999992
Thread-0 : 2999993
Thread-0 : 2999994
Thread-0 : 2999995
Thread-0 : 2999996
Thread-0 : 2999997
Thread-0 : 2999998
Thread-0 : 2999999
Thread-0 : 3000000
3000000
不管程序执行多少次,最后得到的结果一定是3000000,这究竟是为什么呢?这是因为synchronized修饰静态方法的时候,而static方法是全局的,此时锁的是SynchronizedStatic类的Class类,不管实例化多少个SynchronizedStatic的对象,在执行increase方法的时候肯定是针对所有对象实例都是互斥的。
需要注意的是如果一个线程A调用一个实例对象的非static synchronized方法,而线程B需要调用这个实例对象所属类的static synchronized方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的class对象,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。
2.3 synchronized作用于代码块
通常情况下,我们应用中所写的方法会比较长,而我们仅仅需要对方法中涉及到访问共享资源的逻辑进行同步处理,此时如果还是使用同步方法对性能影响将会比较大,这时,可以使用同步代码块的方式,如下:
/**
* synchronized作用于代码块
*
* @author Sunny
* @version 1.0
* @taskId:
* @createDate 2019/02/27 14:31
* @see com.sunny.concurrent.synchronizedkey
*/
public class SynchronizedCodeBlock implements Runnable{
private static int count = 0;
public void increase() {
synchronized (this) {
count++;
}
}
@Override
public void run() {
for (int i = 0; i < 1000000; i++) {
increase();
System.out.println(Thread.currentThread().getName() + " : " + count);
}
}
public static void main(String[] args) throws InterruptedException {
SynchronizedCodeBlock sm = new SynchronizedCodeBlock();
Thread t1 = new Thread(sm);
Thread t2 = new Thread(sm);
Thread t3 = new Thread(sm);
t1.start();
t2.start();
t3.start();
t1.join();
t2.join();
t3.join();
System.out.println(count);
}
}
以上代码输出如下:
....................................
Thread-1 : 2999986
Thread-1 : 2999987
Thread-1 : 2999988
Thread-1 : 2999989
Thread-1 : 2999990
Thread-1 : 2999991
Thread-1 : 2999992
Thread-1 : 2999993
Thread-1 : 2999994
Thread-1 : 2999995
Thread-1 : 2999996
Thread-1 : 2999997
Thread-1 : 2999998
Thread-1 : 2999999
Thread-1 : 3000000
3000000
不管代码执行多少次,跟同步实例方法达到的效果是一致的。当没有明确的对象作为锁,只是想让一段代码同步时,可以创建一个特殊的对象来充当锁:
class Test implements Runnable
{
private byte[] lock = new byte[0]; // 特殊的instance变量
public void method()
{
synchronized(lock) {
// todo 同步代码块
}
}
public void run() {
}
}
说明:零长度的byte数组对象创建起来将比任何对象都经济――查看编译后的字节码:生成零长度的byte[]对象只需3条操作码,而Object lock = new Object()则需要7行操作码。
当然,如果使用这种方式,也不能new出多个不同实例对象出来啦。如果你非要想new两个不同对象出来,又想保证线程同步的话,那么synchronized后面的括号中可以填入SynchronizedCodeBlock.class,表示这个Class对象作为锁,自然就能保证线程同步,这样跟static的方法上面使用synchronized修饰的效果类似。如下:
public void increase() {
synchronized (SynchronizedCodeBlock.class) {
count++;
}
}
通过演示3种不同锁的使用,让大家对synchronized有了初步的认识。当一个线程试图访问带有synchronized修饰的同步代码块或者方法时,必须要先获得锁。当方法执行完毕退出以后或者出现异常的情况下会自动释放锁。如果大家认真看了上面的三个案例,那么应该知道锁的范围控制是由对象的作用域决定的。对象的作用域越大,那么锁的范围也就越大,因此我们可以得出一个初步的猜想,synchronized和对象有非常大的关系。那么,接下来就去剖析一下锁的原理。
三、synchronized实现原理
问题:当一个线程尝试访问synchronized修饰的代码块时,它首先要获得锁,那么这个锁到底存在哪里呢?
3.1 对象在内存中的布局
synchronized实现的锁是存储在Java对象头里,什么是对象头呢?在Hotspot虚拟机中,对象在内存中的存储布局,可以分为三个区域:对象头(Header)、实例数据(Instance Data)、对齐填充(Padding)
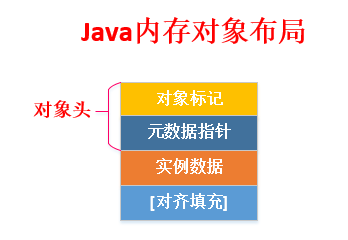
当我们在Java代码中,使用new创建一个对象实例的时候,(Hotspot虚拟机)JVM层面实际上会创建一个instanceOopDesc对象。
Hotspot虚拟机采用OOP-Klass二分模型来描述Java对象实例,其中OOP(Ordinary Object Point)指的是普通对象指针,它用来表示对象的实例信息,看起来像个指针实际上是藏在指针里的对象;而 Klass 则包含 元数据和方法信息,用来描述 Java 类。Hotspot采用instanceOopDesc和arrayOopDesc来描述对象头,arrayOopDesc对象用来描述数组类型。
那么为何要设计这样一个一分为二的对象模型呢?这是因为 HotSopt JVM 的设计者不想让每个对象中都含有一个 vtable(虚函数表),所以就把对象模型拆成 klass 和 oop,其中 oop 中不含有任何虚函数,而 klass 就含有虚函数表,可以进行 method dispatch。这个模型其实是参照的 Strongtalk VM 底层的对象模型。
instanceOopDesc的定义在Hotspot源码中的instanceOop.hpp文件中,另外,arrayOopDesc的定义对应arrayOop.hpp
// An instanceOop is an instance of a Java Class
// Evaluating "new HashTable()" will create an instanceOop.
class instanceOopDesc : public oopDesc {
public:
// aligned header size.
static int header_size() { return sizeof(instanceOopDesc)/HeapWordSize; }
// If compressed, the offset of the fields of the instance may not be aligned.
static int base_offset_in_bytes() {
// offset computation code breaks if UseCompressedClassPointers
// only is true
return (UseCompressedOops && UseCompressedClassPointers) ?
klass_gap_offset_in_bytes() :
sizeof(instanceOopDesc);
}
static bool contains_field_offset(int offset, int nonstatic_field_size) {
int base_in_bytes = base_offset_in_bytes();
return (offset >= base_in_bytes &&
(offset-base_in_bytes) < nonstatic_field_size * heapOopSize);
}
};
#endif // SHARE_VM_OOPS_INSTANCEOOP_HPP
从instanceOopDesc代码中可以看到 instanceOopDesc继承自oopDesc,oopDesc的定义载Hotspot源码中的 oop.hpp文件中
class oopDesc {
friend class VMStructs;
friend class JVMCIVMStructs;
private:
volatile markOop _mark;
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
public:
inline markOop mark() const;
inline markOop mark_raw() const;
inline markOop* mark_addr_raw() const;
inline void set_mark(volatile markOop m);
inline void set_mark_raw(volatile markOop m);
static inline void set_mark_raw(HeapWord* mem, markOop m);
inline void release_set_mark(markOop m);
inline markOop cas_set_mark(markOop new_mark, markOop old_mark);
inline markOop cas_set_mark_raw(markOop new_mark, markOop old_mark, atomic_memory_order order = memory_order_conservative);
// Used only to re-initialize the mark word (e.g., of promoted
// objects during a GC) -- requires a valid klass pointer
inline void init_mark();
inline void init_mark_raw();
inline Klass* klass() const;
inline Klass* klass_or_null() const volatile;
inline Klass* klass_or_null_acquire() const volatile;
static inline Klass** klass_addr(HeapWord* mem);
static inline narrowKlass* compressed_klass_addr(HeapWord* mem);
inline Klass** klass_addr();
inline narrowKlass* compressed_klass_addr();
inline void set_klass(Klass* k);
static inline void release_set_klass(HeapWord* mem, Klass* klass);
// For klass field compression
inline int klass_gap() const;
inline void set_klass_gap(int z);
static inline void set_klass_gap(HeapWord* mem, int z);
// For when the klass pointer is being used as a linked list "next" field.
inline void set_klass_to_list_ptr(oop k);
inline oop list_ptr_from_klass();
// size of object header, aligned to platform wordSize
static int header_size() { return sizeof(oopDesc)/HeapWordSize; }
// Returns whether this is an instance of k or an instance of a subclass of k
inline bool is_a(Klass* k) const;
// Returns the actual oop size of the object
inline int size();
// Sometimes (for complicated concurrency-related reasons), it is useful
// to be able to figure out the size of an object knowing its klass.
inline int size_given_klass(Klass* klass);
// type test operations (inlined in oop.inline.hpp)
inline bool is_instance() const;
inline bool is_array() const;
inline bool is_objArray() const;
inline bool is_typeArray() const;
// type test operations that don't require inclusion of oop.inline.hpp.
bool is_instance_noinline() const;
bool is_array_noinline() const;
bool is_objArray_noinline() const;
bool is_typeArray_noinline() const;
protected:
inline oop as_oop() const { return const_cast(this); }
public:
// field addresses in oop
inline void* field_addr(int offset) const;
inline void* field_addr_raw(int offset) const;
// Need this as public for garbage collection.
template inline T* obj_field_addr_raw(int offset) const;
template inline size_t field_offset(T* p) const;
// Standard compare function returns negative value if o1 < o2
// 0 if o1 == o2
// positive value if o1 > o2
inline static int compare(oop o1, oop o2) {
void* o1_addr = (void*)o1;
void* o2_addr = (void*)o2;
if (o1_addr < o2_addr) {
return -1;
} else if (o1_addr > o2_addr) {
return 1;
} else {
return 0;
}
}
inline static bool equals(oop o1, oop o2) { return Access<>::equals(o1, o2); }
// Access to fields in a instanceOop through these methods.
template
oop obj_field_access(int offset) const;
oop obj_field(int offset) const;
void obj_field_put(int offset, oop value);
void obj_field_put_raw(int offset, oop value);
void obj_field_put_volatile(int offset, oop value);
Metadata* metadata_field(int offset) const;
void metadata_field_put(int offset, Metadata* value);
Metadata* metadata_field_acquire(int offset) const;
void release_metadata_field_put(int offset, Metadata* value);
jbyte byte_field(int offset) const;
void byte_field_put(int offset, jbyte contents);
jchar char_field(int offset) const;
void char_field_put(int offset, jchar contents);
jboolean bool_field(int offset) const;
void bool_field_put(int offset, jboolean contents);
jint int_field(int offset) const;
void int_field_put(int offset, jint contents);
jshort short_field(int offset) const;
void short_field_put(int offset, jshort contents);
jlong long_field(int offset) const;
void long_field_put(int offset, jlong contents);
jfloat float_field(int offset) const;
void float_field_put(int offset, jfloat contents);
jdouble double_field(int offset) const;
void double_field_put(int offset, jdouble contents);
address address_field(int offset) const;
void address_field_put(int offset, address contents);
oop obj_field_acquire(int offset) const;
void release_obj_field_put(int offset, oop value);
jbyte byte_field_acquire(int offset) const;
void release_byte_field_put(int offset, jbyte contents);
jchar char_field_acquire(int offset) const;
void release_char_field_put(int offset, jchar contents);
jboolean bool_field_acquire(int offset) const;
void release_bool_field_put(int offset, jboolean contents);
jint int_field_acquire(int offset) const;
void release_int_field_put(int offset, jint contents);
jshort short_field_acquire(int offset) const;
void release_short_field_put(int offset, jshort contents);
jlong long_field_acquire(int offset) const;
void release_long_field_put(int offset, jlong contents);
jfloat float_field_acquire(int offset) const;
void release_float_field_put(int offset, jfloat contents);
jdouble double_field_acquire(int offset) const;
void release_double_field_put(int offset, jdouble contents);
address address_field_acquire(int offset) const;
void release_address_field_put(int offset, address contents);
// printing functions for VM debugging
void print_on(outputStream* st) const; // First level print
void print_value_on(outputStream* st) const; // Second level print.
void print_address_on(outputStream* st) const; // Address printing
// printing on default output stream
void print();
void print_value();
void print_address();
// return the print strings
char* print_string();
char* print_value_string();
// verification operations
void verify_on(outputStream* st);
void verify();
// locking operations
inline bool is_locked() const;
inline bool is_unlocked() const;
inline bool has_bias_pattern() const;
inline bool has_bias_pattern_raw() const;
// asserts and guarantees
static bool is_oop(oop obj, bool ignore_mark_word = false);
static bool is_oop_or_null(oop obj, bool ignore_mark_word = false);
#ifndef PRODUCT
inline bool is_unlocked_oop() const;
#endif
// garbage collection
inline bool is_gc_marked() const;
// Forward pointer operations for scavenge
inline bool is_forwarded() const;
inline void forward_to(oop p);
inline bool cas_forward_to(oop p, markOop compare, atomic_memory_order order = memory_order_conservative);
// Like "forward_to", but inserts the forwarding pointer atomically.
// Exactly one thread succeeds in inserting the forwarding pointer, and
// this call returns "NULL" for that thread; any other thread has the
// value of the forwarding pointer returned and does not modify "this".
inline oop forward_to_atomic(oop p, atomic_memory_order order = memory_order_conservative);
inline oop forwardee() const;
inline oop forwardee_acquire() const;
// Age of object during scavenge
inline uint age() const;
inline void incr_age();
// mark-sweep support
void follow_body(int begin, int end);
// Garbage Collection support
#if INCLUDE_PARALLELGC
// Parallel Compact
inline void pc_follow_contents(ParCompactionManager* cm);
inline void pc_update_contents(ParCompactionManager* cm);
// Parallel Scavenge
inline void ps_push_contents(PSPromotionManager* pm);
#endif
template
inline void oop_iterate(OopClosureType* cl);
template
inline void oop_iterate(OopClosureType* cl, MemRegion mr);
template
inline int oop_iterate_size(OopClosureType* cl);
template
inline int oop_iterate_size(OopClosureType* cl, MemRegion mr);
template
inline void oop_iterate_backwards(OopClosureType* cl);
inline static bool is_instanceof_or_null(oop obj, Klass* klass);
// identity hash; returns the identity hash key (computes it if necessary)
// NOTE with the introduction of UseBiasedLocking that identity_hash() might reach a
// safepoint if called on a biased object. Calling code must be aware of that.
inline intptr_t identity_hash();
intptr_t slow_identity_hash();
// Alternate hashing code if string table is rehashed
unsigned int new_hash(juint seed);
// marks are forwarded to stack when object is locked
inline bool has_displaced_mark_raw() const;
inline markOop displaced_mark_raw() const;
inline void set_displaced_mark_raw(markOop m);
static bool has_klass_gap();
// for code generation
static int mark_offset_in_bytes() { return offset_of(oopDesc, _mark); }
static int klass_offset_in_bytes() { return offset_of(oopDesc, _metadata._klass); }
static int klass_gap_offset_in_bytes() {
assert(has_klass_gap(), "only applicable to compressed klass pointers");
return klass_offset_in_bytes() + sizeof(narrowKlass);
}
};
#endif // SHARE_VM_OOPS_OOP_HPP
在普通实例对象中,oopDesc的定义包含两个成员,分别是_mark和_metadata。_mark表示对象标记、属于markOop类型,也就是接下来要讲解的Mark Word,它记录了对象和锁的有关信息。_metadata表示类元信息,类元信息存储的是对象指向它的类元数据(Klass)的首地址,其中Klass表示普通指针、_compressed_klass表示压缩类指针。
3.2 Mark Word
在前面我们提到过,普通对象的对象头由两部分组成,分别是markOop以及类元信息,markOop官方称为Mark Word 在Hotspot中,markOop的定义在 markOop.hpp文件中,代码如下:
typedef class markOopDesc* markOop;
而markOopDesc的定义如下:
class markOopDesc: public oopDesc {
private:
// Conversion
uintptr_t value() const { return (uintptr_t) this; }
public:
// Constants
enum { age_bits = 4,
lock_bits = 2,
biased_lock_bits = 1,
max_hash_bits = BitsPerWord - age_bits - lock_bits - biased_lock_bits,
hash_bits = max_hash_bits > 31 ? 31 : max_hash_bits,
cms_bits = LP64_ONLY(1) NOT_LP64(0),
epoch_bits = 2
};
// The biased locking code currently requires that the age bits be
// contiguous to the lock bits.
enum { lock_shift = 0,
biased_lock_shift = lock_bits,
age_shift = lock_bits + biased_lock_bits,
cms_shift = age_shift + age_bits,
hash_shift = cms_shift + cms_bits,
epoch_shift = hash_shift
};
enum { lock_mask = right_n_bits(lock_bits),
lock_mask_in_place = lock_mask << lock_shift,
biased_lock_mask = right_n_bits(lock_bits + biased_lock_bits),
biased_lock_mask_in_place= biased_lock_mask << lock_shift,
biased_lock_bit_in_place = 1 << biased_lock_shift,
age_mask = right_n_bits(age_bits),
age_mask_in_place = age_mask << age_shift,
epoch_mask = right_n_bits(epoch_bits),
epoch_mask_in_place = epoch_mask << epoch_shift,
cms_mask = right_n_bits(cms_bits),
cms_mask_in_place = cms_mask << cms_shift
#ifndef _WIN64
,hash_mask = right_n_bits(hash_bits),
hash_mask_in_place = (address_word)hash_mask << hash_shift
#endif
};
// Alignment of JavaThread pointers encoded in object header required by biased locking
enum { biased_lock_alignment = 2 << (epoch_shift + epoch_bits)
};
#ifdef _WIN64
// These values are too big for Win64
const static uintptr_t hash_mask = right_n_bits(hash_bits);
const static uintptr_t hash_mask_in_place =
(address_word)hash_mask << hash_shift;
#endif
enum { locked_value = 0,
unlocked_value = 1,
monitor_value = 2,
marked_value = 3,
biased_lock_pattern = 5
};
enum { no_hash = 0 }; // no hash value assigned
enum { no_hash_in_place = (address_word)no_hash << hash_shift,
no_lock_in_place = unlocked_value
};
enum { max_age = age_mask };
enum { max_bias_epoch = epoch_mask };
// Biased Locking accessors.
// These must be checked by all code which calls into the
// ObjectSynchronizer and other code. The biasing is not understood
// by the lower-level CAS-based locking code, although the runtime
// fixes up biased locks to be compatible with it when a bias is
// revoked.
bool has_bias_pattern() const {
return (mask_bits(value(), biased_lock_mask_in_place) == biased_lock_pattern);
}
JavaThread* biased_locker() const {
assert(has_bias_pattern(), "should not call this otherwise");
return (JavaThread*) ((intptr_t) (mask_bits(value(), ~(biased_lock_mask_in_place | age_mask_in_place | epoch_mask_in_place))));
}
// Indicates that the mark has the bias bit set but that it has not
// yet been biased toward a particular thread
bool is_biased_anonymously() const {
return (has_bias_pattern() && (biased_locker() == NULL));
}
// Indicates epoch in which this bias was acquired. If the epoch
// changes due to too many bias revocations occurring, the biases
// from the previous epochs are all considered invalid.
int bias_epoch() const {
assert(has_bias_pattern(), "should not call this otherwise");
return (mask_bits(value(), epoch_mask_in_place) >> epoch_shift);
}
markOop set_bias_epoch(int epoch) {
assert(has_bias_pattern(), "should not call this otherwise");
assert((epoch & (~epoch_mask)) == 0, "epoch overflow");
return markOop(mask_bits(value(), ~epoch_mask_in_place) | (epoch << epoch_shift));
}
markOop incr_bias_epoch() {
return set_bias_epoch((1 + bias_epoch()) & epoch_mask);
}
// Prototype mark for initialization
static markOop biased_locking_prototype() {
return markOop( biased_lock_pattern );
}
// lock accessors (note that these assume lock_shift == 0)
bool is_locked() const {
return (mask_bits(value(), lock_mask_in_place) != unlocked_value);
}
bool is_unlocked() const {
return (mask_bits(value(), biased_lock_mask_in_place) == unlocked_value);
}
bool is_marked() const {
return (mask_bits(value(), lock_mask_in_place) == marked_value);
}
bool is_neutral() const { return (mask_bits(value(), biased_lock_mask_in_place) == unlocked_value); }
// Special temporary state of the markOop while being inflated.
// Code that looks at mark outside a lock need to take this into account.
bool is_being_inflated() const { return (value() == 0); }
// Distinguished markword value - used when inflating over
// an existing stacklock. 0 indicates the markword is "BUSY".
// Lockword mutators that use a LD...CAS idiom should always
// check for and avoid overwriting a 0 value installed by some
// other thread. (They should spin or block instead. The 0 value
// is transient and *should* be short-lived).
static markOop INFLATING() { return (markOop) 0; } // inflate-in-progress
// Should this header be preserved during GC?
inline bool must_be_preserved(oop obj_containing_mark) const;
inline bool must_be_preserved_with_bias(oop obj_containing_mark) const;
// Should this header (including its age bits) be preserved in the
// case of a promotion failure during scavenge?
// Note that we special case this situation. We want to avoid
// calling BiasedLocking::preserve_marks()/restore_marks() (which
// decrease the number of mark words that need to be preserved
// during GC) during each scavenge. During scavenges in which there
// is no promotion failure, we actually don't need to call the above
// routines at all, since we don't mutate and re-initialize the
// marks of promoted objects using init_mark(). However, during
// scavenges which result in promotion failure, we do re-initialize
// the mark words of objects, meaning that we should have called
// these mark word preservation routines. Currently there's no good
// place in which to call them in any of the scavengers (although
// guarded by appropriate locks we could make one), but the
// observation is that promotion failures are quite rare and
// reducing the number of mark words preserved during them isn't a
// high priority.
inline bool must_be_preserved_for_promotion_failure(oop obj_containing_mark) const;
inline bool must_be_preserved_with_bias_for_promotion_failure(oop obj_containing_mark) const;
// Should this header be preserved during a scavenge where CMS is
// the old generation?
// (This is basically the same body as must_be_preserved_for_promotion_failure(),
// but takes the Klass* as argument instead)
inline bool must_be_preserved_for_cms_scavenge(Klass* klass_of_obj_containing_mark) const;
inline bool must_be_preserved_with_bias_for_cms_scavenge(Klass* klass_of_obj_containing_mark) const;
// WARNING: The following routines are used EXCLUSIVELY by
// synchronization functions. They are not really gc safe.
// They must get updated if markOop layout get changed.
markOop set_unlocked() const {
return markOop(value() | unlocked_value);
}
bool has_locker() const {
return ((value() & lock_mask_in_place) == locked_value);
}
BasicLock* locker() const {
assert(has_locker(), "check");
return (BasicLock*) value();
}
bool has_monitor() const {
return ((value() & monitor_value) != 0);
}
ObjectMonitor* monitor() const {
assert(has_monitor(), "check");
// Use xor instead of &~ to provide one extra tag-bit check.
return (ObjectMonitor*) (value() ^ monitor_value);
}
bool has_displaced_mark_helper() const {
return ((value() & unlocked_value) == 0);
}
markOop displaced_mark_helper() const {
assert(has_displaced_mark_helper(), "check");
intptr_t ptr = (value() & ~monitor_value);
return *(markOop*)ptr;
}
void set_displaced_mark_helper(markOop m) const {
assert(has_displaced_mark_helper(), "check");
intptr_t ptr = (value() & ~monitor_value);
*(markOop*)ptr = m;
}
markOop copy_set_hash(intptr_t hash) const {
intptr_t tmp = value() & (~hash_mask_in_place);
tmp |= ((hash & hash_mask) << hash_shift);
return (markOop)tmp;
}
// it is only used to be stored into BasicLock as the
// indicator that the lock is using heavyweight monitor
static markOop unused_mark() {
return (markOop) marked_value;
}
// the following two functions create the markOop to be
// stored into object header, it encodes monitor info
static markOop encode(BasicLock* lock) {
return (markOop) lock;
}
static markOop encode(ObjectMonitor* monitor) {
intptr_t tmp = (intptr_t) monitor;
return (markOop) (tmp | monitor_value);
}
static markOop encode(JavaThread* thread, uint age, int bias_epoch) {
intptr_t tmp = (intptr_t) thread;
assert(UseBiasedLocking && ((tmp & (epoch_mask_in_place | age_mask_in_place | biased_lock_mask_in_place)) == 0), "misaligned JavaThread pointer");
assert(age <= max_age, "age too large");
assert(bias_epoch <= max_bias_epoch, "bias epoch too large");
return (markOop) (tmp | (bias_epoch << epoch_shift) | (age << age_shift) | biased_lock_pattern);
}
// used to encode pointers during GC
markOop clear_lock_bits() { return markOop(value() & ~lock_mask_in_place); }
// age operations
markOop set_marked() { return markOop((value() & ~lock_mask_in_place) | marked_value); }
markOop set_unmarked() { return markOop((value() & ~lock_mask_in_place) | unlocked_value); }
uint age() const { return mask_bits(value() >> age_shift, age_mask); }
markOop set_age(uint v) const {
assert((v & ~age_mask) == 0, "shouldn't overflow age field");
return markOop((value() & ~age_mask_in_place) | (((uintptr_t)v & age_mask) << age_shift));
}
markOop incr_age() const { return age() == max_age ? markOop(this) : set_age(age() + 1); }
// hash operations
intptr_t hash() const {
return mask_bits(value() >> hash_shift, hash_mask);
}
bool has_no_hash() const {
return hash() == no_hash;
}
// Prototype mark for initialization
static markOop prototype() {
return markOop( no_hash_in_place | no_lock_in_place );
}
// Helper function for restoration of unmarked mark oops during GC
static inline markOop prototype_for_object(oop obj);
// Debugging
void print_on(outputStream* st) const;
// Prepare address of oop for placement into mark
inline static markOop encode_pointer_as_mark(void* p) { return markOop(p)->set_marked(); }
// Recover address of oop from encoded form used in mark
inline void* decode_pointer() { if (UseBiasedLocking && has_bias_pattern()) return NULL; return clear_lock_bits(); }
// These markOops indicate cms free chunk blocks and not objects.
// In 64 bit, the markOop is set to distinguish them from oops.
// These are defined in 32 bit mode for vmStructs.
const static uintptr_t cms_free_chunk_pattern = 0x1;
// Constants for the size field.
enum { size_shift = cms_shift + cms_bits,
size_bits = 35 // need for compressed oops 32G
};
// These values are too big for Win64
const static uintptr_t size_mask = LP64_ONLY(right_n_bits(size_bits))
NOT_LP64(0);
const static uintptr_t size_mask_in_place =
(address_word)size_mask << size_shift;
#ifdef _LP64
static markOop cms_free_prototype() {
return markOop(((intptr_t)prototype() & ~cms_mask_in_place) |
((cms_free_chunk_pattern & cms_mask) << cms_shift));
}
uintptr_t cms_encoding() const {
return mask_bits(value() >> cms_shift, cms_mask);
}
bool is_cms_free_chunk() const {
return is_neutral() &&
(cms_encoding() & cms_free_chunk_pattern) == cms_free_chunk_pattern;
}
size_t get_size() const { return (size_t)(value() >> size_shift); }
static markOop set_size_and_free(size_t size) {
assert((size & ~size_mask) == 0, "shouldn't overflow size field");
return markOop(((intptr_t)cms_free_prototype() & ~size_mask_in_place) |
(((intptr_t)size & size_mask) << size_shift));
}
#endif // _LP64
};
#endif // SHARE_VM_OOPS_MARKOOP_HPP
Mark Word记录了对象和锁有关的信息,当某个对象被synchronized关键字当成同步锁时,那么围绕这个锁的一系列操作都和Mark Word有关系。Mark Word在32位虚拟机的长度是32bit、在64位虚拟机的长度是64bit。
32位JVM的Mark Word的默认存储结构(无锁状态)
在运行期间,Mark Word里存储的数据会随着锁标志位的变化而变化(32位)

64位JVM的Mark Word的默认存储结构(对于32位无锁状态,有25bit没有使用)

Mark Word里面存储的数据会随着锁标志位的变化而变化,Mark Word可能变化为存储以下5种情况:

锁标志位的表示意义:
- 锁标识lock=00标识轻量级锁
- 锁标识lock=10标识重量级锁
- 偏向锁标识biased_lock=1标识偏向锁
- 偏向锁标识biased_lock=0标识无锁状态
综上所述,synchronized(lock)中的lock可以用Java中任何一个对象来表示,而锁标识的存储实际上就是在lock这个对象中的对象头内。
其实前面只提到了锁标志位的存储,但是为什么任意一个Java对象都能成为锁对象呢?
Java中的每个对象都派生自Object类,而每个Java Object在JVM内部都有一个native的C++对象oop/oopDesc进行对应。其次,线程在获取锁的时候,实际上就是获得一个监视器对象(monitor),monitor可以认为是一个同步对象,所有的Java对象是天生携带monitor。在hotspot源码的markOop.hpp文件中,可以看到下面这段代码。
ObjectMonitor* monitor() const {
assert(has_monitor(), "check");
// Use xor instead of &~ to provide one extra tag-bit check.
return (ObjectMonitor*) (value() ^ monitor_value);
}
多个线程访问同步代码块时,相当于去争抢对象监视器修改对象中的锁标识,上面的代码中ObjectMonitor这个对象和线程争抢锁的逻辑有密切的关系。
3.3 锁优化与升级
前面提到了锁的几个概念,偏向锁、轻量级锁、重量级锁。在JDK1.6之前,synchronized是一个重量级锁,性能比较差。在JDK1.6之后,为了减少获得锁和释放锁带来的性能消耗,synchronized进行了优化,引入了偏向锁和轻量级锁的概念。所以从JDK1.6开始,锁一共会有四种状态,锁的状态根据竞争激烈程度从低到高分别是:无锁状态 -> 偏向锁状态 -> 轻量级锁状态 -> 重量级锁状态。这几个状态会随着锁竞争的情况逐步升级。为了提高获得锁和释放锁的效率,锁可以升级但是不能降级。锁可以升级但是不能降级意味着偏向锁升级成轻量级锁后不能降级成偏向锁。
3.3.1 偏向锁
Hotspot的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。偏向锁的意思是如果一个线程获得了一个偏向锁,如果在接下来的一段时间中没有其他线程来竞争锁,那么持有偏向锁的线程再次进入或者退出同一个同步代码块,不需要再次进行抢占锁和释放锁的操作。偏向锁可以通过 -XX:+UseBiasedLocking开启或者关闭
偏向锁的获取
偏向锁的获取过程非常简单,当一个线程访问同步块获取锁时,会在对象头和栈帧的锁记录里存储偏向锁的线程ID,表示哪个线程获得了偏向锁,结合前面的Mark Word来分析一下偏向锁的获取逻辑:
- 首先获取目标对象的Mark Word,根据锁的标识为epoch去判断当前是否处于可偏向的状态;
- 如果为可偏向状态,则通过CAS操作将自己的线程ID写入到Mark Word,如果CAS操作成功,则表示当前线程成功获取到偏向锁,继续执行同步代码块;
- 如果是已偏向状态,先检测Mark Word中存储的threadID和当前访问线程的threadID是否相等,如果相等,表示当前线程已经获得了偏向锁,则不需要在获得锁直接执行同步代码;如果不相等,则证明当前锁偏向于其他线程,需要撤销偏向锁。
偏向锁的撤销
偏向锁使用了一种等到竞争出现才释放锁的机制,所以当其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁。偏向锁的撤销,需要等到全局安全点(在这个时间点上没有正在执行的字节码)。
- 首先会暂停拥有偏向锁的线程并检查该线程是否存活:
1.1 如果线程非活动状态,则将对象头设置为无锁状态(其他线程会重新获取该偏向锁)
1.2 如果线程是活动状态,拥有偏向锁的栈会被执行,遍历偏向对象的锁记录,并将对栈中的锁记录和对象头的MarkWord进行重置:
- 要么重新偏向于其他线程(即将偏向锁交给其他线程,相当于当前线程"被"释放了锁)
- 要么恢复到无锁或者标记锁对象不适合作为偏向锁(此时锁会被升级为轻量级锁)
- 最后唤醒暂停的线程,被阻塞在安全点的线程继续往下执行同步代码块
偏向锁的关闭
- 偏向锁在JDK1.6以上默认开启,开启后程序启动几秒后才会被激活
- 有必要可以使用JVM参数来关闭延迟 -XX:BiasedLockingStartupDelay = 0
- 如果确定锁通常处于竞争状态,则可通过JVM参数 -XX:-UseBiasedLocking=false 关闭偏向锁,那么默认会进入轻量级锁
偏向锁的获取流程图

偏向锁的注意事项
- 优势:偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令,其余时刻不需要CAS指令(相比其他锁)
- 隐患:由于一旦出现多线程竞争的情况就必须撤销偏向锁,所以偏向锁的撤销操作的性能损耗必须小于节省下来的CAS原子指令的性能消耗(这个通常只能通过大量压测才可知)
- 对比:轻量级锁是为了在线程交替执行同步块时提高性能,而偏向锁则是在只有一个线程执行同步块时进一步提高性能
3.3.2 轻量级锁
当存在超过一个线程在竞争同一个同步代码块时,会发生偏向锁的撤销,而撤销偏向锁的时候就是当锁对象不适合作为偏向锁的时候会被升级为轻量级锁,这个就是我们接下来需要介绍的轻量级锁。
轻量级锁加锁
- 线程在执行同步代码块之前,JVM会先在当前线程的栈帧中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中(Displaced Mark Word - 即被取代的Mark Word)做一份拷贝
- 拷贝成功后,线程尝试使用CAS将对象头的Mark Word替换为指向锁记录的指针(将对象头的Mark Word更新为指向锁记录的指针,并将锁记录里的Owner指针指向Object Mark Word)
- 如果更新成功,当前线程获得轻量级锁,继续执行同步方法
- 如果更新失败,表示其他线程竞争锁,当前线程便尝试使用自旋(CAS)来获取锁,当自旋超过指定次数(可以自定义)时仍然无法获得锁,此时锁会膨胀升级为重量级锁
轻量级锁解锁
- 尝试CAS操作将锁记录中的Mark Word替换会对象头中
- 如果成功,表示没有竞争发生
- 如果失败,表示当前锁存在竞争,锁会膨胀成重量级锁
一旦锁升级成重量级锁,就不会再恢复到轻量级锁状态。当锁处于重量级锁状态,其他线程尝试获取锁时,都会被阻塞,也就是 BLOCKED状态。当持有锁的线程释放锁之后会唤醒这些线程,被唤醒之后的线程会进行新一轮的竞争
轻量级锁获取锁的流程

轻量级锁的注意事项
-
隐患: 对于轻量级锁有个使用前提是”没有多线程竞争环境”,一旦越过这个前提,除了互斥开销外,还会增加额外的CAS操作的开销,在多线程竞争环境下,轻量级锁甚至比重量级锁还要慢
3.3.3 重量级锁
重量级锁依赖对象内部的monitor(可以研究下Monitor Object机制)锁来实现,而monitor又依赖操作系统的MutexLock(互斥锁)
大家如果对MutexLock有兴趣,可以抽时间去了解,假设Mutex变量的值为1,表示互斥锁空闲,这个时候某个线程调用lock可以获得锁,而Mutex的值为0表示互斥锁已经被其他线程获得,其他线程调用lock只能挂起等待。
为什么重量级锁的开销比较大呢?
原因是当系统检查到是重量级锁之后,会把等待想要获取锁的线程阻塞,被阻塞的线程不会消耗CPU,但是阻塞或者唤醒一个线程,都需要通过操作系统来实现,也就是相当于从用户态转化到内核态,而转化状态是需要消耗时间的。
四、总结
synchronized是通过monitor监视器锁来实现可见性、顺序性以及原子性、而monitor是依赖于操作系统的mutex(互斥锁,每个对象都对应于一个可称为" 互斥锁" 的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象)。这里简单介绍下mutex的操作步骤:
申请mutex
如果成功,则持有该mutex
如果失败,则进行spin自旋. spin的过程就是在线等待mutex, 不断发起mutex gets, 直到获得mutex或者达到spin_count限制为止
依据工作模式的不同选择yiled还是sleep
若达到sleep限制或者被主动唤醒或者完成yield, 则重复1)~4)步,直到获得为止
参考引用
https://www.processon.com/view/5c25db87e4b016324f447c95
方腾飞《Java并发编程的艺术》