本文翻译自2018年最热门的Python金融教程 Python For Finance: Algorithmic Trading。
这篇 Python 金融教程向您介绍算法交易等内容。
技术已成为金融领域的一项资产:金融机构已不仅仅是单纯的金融机构了,它正向着技术公司演进。除了技术带来的创新速度和竞争优势以外,金融交易的速度、频率和大数据量,使得金融机构对技术的关注度日益提高,技术确已成为金融业的主要推动力。
在最热门的金融编程语言中,有R语言、Python,还有C++、C#和Java。在本教程中,你将学习如何开始使用Python进行金融分析,其内容如下:
- Python金融入门必备基础知识:对于那些刚接触金融的人,首先要了解有关股票和交易策略的知识,什么是时间序列数据,以及如何设置工作空间。
- 常见的金融分析方法:介绍时间序列数据和常见的金融分析方法,比如使用Python包Pandas进行移动窗口、波动率计算等等。
- 简单的动量策略开发:首先逐步完成开发过程,然后开始编写简单的算法交易策略。
- 回溯测试策略:使用Pandas、zipline和Quantopian回溯测试制定的交易策略。
- 评估交易策略:优化策略使之获得更好的表现,并最终评估策略的性能和稳健性。
从这里下载本教程的 Jupyter notebook 代码。
Python 金融入门
在进入交易策略学习之前,最好先来了解基础知识。本教程的第一部分将着重于介绍入门所需的Python基础知识。但这并不意味着你将完全从零开始:你至少需要完成 DataCamp 的免费课程 Intro to Python for Data Science course,从而学会如何使用Python列表、包和NumPy。此外,尽管不是必需,但仍希望你能了解Pandas的基本知识,这是众所周知的Python数据处理包。
然后我建议你参加DataCamp的课程 Intro to Python for Finance,学习Python金融的基本知识。如果你还想要把新学的Python数据科学技能用于真实的金融数据,可以考虑参加 Importing and Managing Financial Data in Python 课程。
股票和交易
当一家公司想要扩张或承接新项目时,它可以发行股票来募集资金。股票代表在公司所有权中占的份额,并以金钱兑换的形式发放。股票可以买入和卖出:买卖双方交易现存的曾发行的股票。卖出股票的价格独立于公司业绩,股价反应的是供需关系。这意味着,每当一只股票因为成功、受欢迎等原因被认为是‘值得的’,那么它的股价就会上涨。
请注意,股票和债券并不完全相同。债券是公司通过借贷的形式筹集资金,无论是作为银行贷款还是发行债券。
正如你刚才读到的那样,买卖或者交易是我们谈论股票所不可避免的,但当然不仅限于此:交易是一种买卖资产的行为,可以是像股票、债券这样的金融证券,或者是如黄金、石油这样的有形资产。
股票交易是这样一个过程:买入股票就是将现金转换成公司所有权的股份,反之,卖出股票就是将股份换回现金。这一切交易都希望能从中获取利润。现在,为了获得丰厚的利润,在市场上要么做多,要么做空:要么你认为股价会上涨并在将来的高价位上卖出股票,要么卖出你的股票,期望在低价位上买回而盈利。当你按照固定的计划在市场上做多或做空时,你就有了一个交易策略。
开发交易策略需要经历若干阶段,就如同构建机器学习模型那样:首先制定一个策略,并以能在电脑上测试的形式实现它,然后进行初步测试或回溯测试,优化你的策略,最后评估策略的性能和稳健性。
交易策略通常通过回溯测试来验证:根据策略制定的规则,使用历史数据,重构过去可能发生的交易。通过这种方式,你能够了解策略的有效性,并在将其应用于真实市场前,把它作为策略优化的起点。当然,这通通依赖于以下信念:任何在过去表现良好的策略,也会在将来取得好的成绩,同样,任何在过去表现差劲的策略,在将来也不可能有好的表现。
时间序列数据
时间序列是在连续的、等间距的时间点上取得的一系列数据点。在投资中,时间序列跟踪选定数据点(如股票价格)的变动,它是在特定的时间跨度内,等间隔地记录数据点。如果你还是疑惑它到底长什么样子,来看看下面的例子:
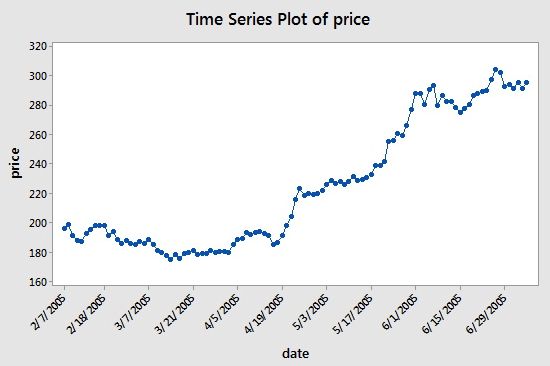
x轴代表日期,y轴代表价格。在上图中,“连续的、等间距的时间点” 就是x轴上以14天为间隔的时间刻度:注意 3/7/2005 和它的下一个点 3/31/2005 之间的差值,以及 4/5/2005 和 4/19/2005 等等。
然而,你常见的股票数据不仅仅只有时间和价格这两列,大部分时候有5列,包括时间、开盘价、最高价、最低价和收盘价。这意味着,如果时间间隔设置为天,你将会得到某只股票那一天的开盘价、收盘价,以及最高、最低价。
现在,你具备了学习完本教程的基本概念。接下来这些概念马上又会出现,并在后续的学习中变得更深入。
设置工作空间
准备工作空间是一项简单的工作:基本上只需确保你的系统运行了Python和集成开发环境(IDE)。然而仍有些办法可以让你更容易地开始。
以Anaconda为例,它是Python和R的高性能发行版本,包含了超过100个最受欢迎的Python、R和Scala数据科学包。此外,安装Anaconda将使你能通过conda轻松地安装超过720个包,这里conda是集成在Anaconda中的著名管理器,用于管理包、依赖项和环境。除此之外,Anaconda还包含了Jupyter Notebook和Spyder集成开发环境。
听起来不错,对吧?
你可以从这里下载安装Anaconda,同时不要忘了通过这篇教程Jupyter Notebook Tutorial: The Definitive Guide查看如何设置Jupyter Notebook。
当然,Anaconda并不是你唯一的选择:你可以尝试收费的 Canopy Python 发行版本,或者是 Quant Platform。
Quant Platform 相比于 Jupyter 或 Spyder IDE 更有优势,因为它向你提供了在浏览器中进行金融分析所需的一切。通过 Quant Platform,你可以访问基于图形用户界面的金融工程,进行基于Python的交互式金融分析,以及使用你自己的Python分析库。更重要的是,你还可以通过论坛与小伙伴们讨论问题和解决方案。
Python金融基础:Pandas
当你使用Python进行金融分析,会经常使用到数据处理包 Pandas。但当你深入时,也会涉及诸如 NumPy、SciPy、Matplotlib 这些包。
现在,让我们只关注 Pandas 并使用它分析时间序列数据。本节将介绍如何使用 Pandas 导入、探索以及处理数据。最重要的是,你将了解如何对导入的数据进行常见的金融分析。
将金融数据导入Python
pandas-datareader包允许从谷歌、雅虎财经、世界银行等数据源中读取数据。如果你想知道此函数提供的最新的数据源列表,可参阅此文档。在本教程中,你将使用pandas-datareader包读取雅虎财经的数据。首先请确保安装了此包的最新版本,可通过 pip with pip install pandas-datareader 命令实现。
提示:如果你想安装最新的开发版本,或者遇到任何问题,都可以在这里查看安装说明。
import pandas_datareader as pdr
import datetime
aapl = pdr.get_data_yahoo('AAPL',
start=datetime.datetime(2006, 10, 1),
end=datetime.datetime(2012, 1, 1))
请注意雅虎API端口最近已更改,如果你已经开始使用该库,则需要安装一个临时的修复补丁,直到该补丁被合并到主干中才能使用pandas-datareader包从雅虎财经获取数据。在你开始之前,请确保查阅了此问题 。
无需担心,在本教程中数据已提前为你加载好,所以你在使用Pandas学习Python金融时不会遇到任何问题。
即便pandas-datareader提供了向Python导入数据的许多选择,它也不是唯一能获取金融数据的包:比如Quandl 库,就可以获取谷歌金融数据:
import quandl
aapl = quandl.get("WIKI/AAPL", start_date="2006-10-01", end_date="2012-01-01")
更多关于如何使用 Quandl 获取金融数据的信息,可参考此网页。
最后,如果你已经在金融领域工作了一段时间,你可能知道最常用的数据处理工具是Excel。在这种情况下,你需要了解如何将Excel集成到Python中。
查看 DataCamp 的教程 Python Excel Tutorial: The Definitive Guide ,获取更多相关知识。
使用时间序列数据
当你最终将数据导入工作空间后,首先要做的事情就是将手弄脏(指清洗、整理数据——译者注)。然而,现在要处理的是时间序列数据,这看起来可能不那么简单,因为索引是日期时间数据。
即便如此也不用担心。让我们一步步来,首先使用函数来探索数据。如果你先前已经有R或者Pandas的编程经验,那么对于这些函数就不陌生了。
没关系,你将发现这很容易!
如上述代码块所示,使用pandas_datareader将数据导入工作空间。所得到的对象 aapl 是数据框,一个二维数据结构,其每一列可以是不同类型的数据。现在当你手头有了一个常规的数据框时,首先要做的事情之一是运行 head() 和 tail() 函数来查看开始和结束的几行数据。幸运的是,当你使用时间序列数据时,这一点并不会改变。
提示:请务必使用 describe() 函数来查看数据的统计摘要信息。
# 查看`aapl`数据的前几行
print(aapl.head())
High Low Open Close Volume Adj Close
Date
2006-10-02 10.838572 10.614285 10.728572 10.694285 178159800 7.161565
2006-10-03 10.707143 10.455714 10.635715 10.582857 197677200 7.086947
2006-10-04 10.780000 10.451428 10.585714 10.768572 207270700 7.211311
2006-10-05 10.880000 10.590000 10.647142 10.690000 170970800 7.158698
2006-10-06 10.720000 10.544286 10.631429 10.602858 116739700 7.100338
# 查看`aapl`数据的最后几行
print(aapl.tail())
High Low Open Close Volume Adj Close
Date
2011-12-23 57.655716 57.070000 57.098572 57.618572 67349800 38.585011
2011-12-27 58.441429 57.574287 57.585712 58.075714 66269000 38.891148
2011-12-28 58.321430 57.334286 58.127144 57.520000 57165500 38.519012
2011-12-29 57.950001 57.215714 57.628571 57.874287 53994500 38.756252
2011-12-30 58.040001 57.641430 57.644287 57.857143 44915500 38.744774
# 查看`aapl` 数据的统计信息
print(aapl.describe())
High Low Open Close Volume \
count 1323.000000 1323.000000 1323.000000 1323.000000 1.323000e+03
mean 29.237566 28.507684 28.901012 28.889151 1.882896e+08
std 14.199012 14.029758 14.123131 14.119734 1.027007e+08
min 10.568571 10.371428 10.488571 10.461429 3.937360e+07
25% 17.752857 17.182143 17.457857 17.431429 1.122037e+08
50% 25.642857 24.725714 25.260000 25.120001 1.629866e+08
75% 39.132858 38.351429 38.777143 38.699999 2.316230e+08
max 60.957142 59.427143 60.251427 60.320000 8.432424e+08
Adj Close
count 1323.000000
mean 19.345990
std 9.455460
min 7.005628
25% 11.673178
50% 16.821934
75% 25.915947
max 40.394054
正如介绍中所述,这一数据包含四列,分别是苹果股票每天的开盘价、收盘价,以及最高、最低价。此外还有另外两列,成交量和调整的收盘价。
成交量(Volume)这一列记录每天交易的股票数量。调整的收盘价(Adj Close)是将当天的收盘价进行调整,以包含第二天开盘前的任何举措。可以使用此列检查或深入分析历史回报情况。
注意索引或行标签如何包含日期,以及列或列标签如何包含数值。
提示:可以使用Pandas中的 to_csv() 函数将该数据保存为csv文档,并且通过 read_csv() 函数将数据重新读回到Python中。当因雅虎API端口被更改而无法获取数据时,这一方法是非常方便的。
import pandas as pd
aapl.to_csv('data/aapl_ohlc.csv') # 注意事先要在当前工作目录下创建data文件夹
df = pd.read_csv('data/aapl_ohlc.csv', header=0, index_col='Date', parse_dates=True)
现在你已经简单地查看了数据的前几行以及一些统计信息,是时候更深入一些了。
一种方法是检查索引和列,并选择某列的最后10行数据。后者被称为构造子集,因为你选择了数据中的一小部分。构造子集得到一个序列(Series),它是一个可以存储任何数据类型的一维数组。
请记住数据框结构是一个二维数组,它的每一列可以存储不同的数据类型。
让我们在接下来的练习中检查上面所说的一切。首先,使用 index 和 columns 属性来查看数据的索引和列。接着选取数据集中 Close 列的最后10个观测量。使用方括号 [] 挑出最后10个数值。你也许从其他编程语言(比如R语言)中获知了这一构造子集的方法。最后,将后者指定给变量 ts,并使用 type() 函数查看 ts 的类型。
# 查看索引
aapl.index
DatetimeIndex(['2006-10-02', '2006-10-03', '2006-10-04', '2006-10-05',
'2006-10-06', '2006-10-09', '2006-10-10', '2006-10-11',
'2006-10-12', '2006-10-13',
...
'2011-12-16', '2011-12-19', '2011-12-20', '2011-12-21',
'2011-12-22', '2011-12-23', '2011-12-27', '2011-12-28',
'2011-12-29', '2011-12-30'],
dtype='datetime64[ns]', name='Date', length=1323, freq=None)
# 查看列
aapl.columns
Index(['High', 'Low', 'Open', 'Close', 'Volume', 'Adj Close'], dtype='object')
# 选择Close列的最后10个数值
ts = aapl['Close'][-10:]
print(ts)
Date
2011-12-16 54.431427
2011-12-19 54.601429
2011-12-20 56.564285
2011-12-21 56.635715
2011-12-22 56.935715
2011-12-23 57.618572
2011-12-27 58.075714
2011-12-28 57.520000
2011-12-29 57.874287
2011-12-30 57.857143
Name: Close, dtype: float64
# 查看ts的类型
type(ts)
pandas.core.series.Series
方括号可以很好的对数据取子集,但它可能不是Pandas中最惯用的方法。这就是你还需学习 loc() 和 iloc() 函数的原因:前者用于基于标签的索引,后者用于位置索引。
实际上,这意味着你可以将行标签,如 2007 和 2006-11-01 传递给 loc() 函数,而将整数 22 和 43 传递给 iloc() 函数。
完成下面的练习来了解 loc() 和 iloc() 的工作方式。
# 查看2006年11、12月数据的前几行
print(aapl.loc[pd.Timestamp('2006-11-01'):pd.Timestamp('2006-12-31')].head())
High Low Open Close Volume Adj Close
Date
2006-11-01 11.625714 11.194285 11.585714 11.308572 152798100 7.572930
2006-11-02 11.331429 11.214286 11.274285 11.282857 116370800 7.555712
2006-11-03 11.361428 11.112857 11.337143 11.184286 107972200 7.489699
2006-11-06 11.437143 11.204286 11.278571 11.387143 108644200 7.625546
2006-11-07 11.571428 11.447143 11.492857 11.501429 131483100 7.702079
# 查看2007年数据的前几行
print(aapl.loc['2007'].head())
High Low Open Close Volume Adj Close
Date
2007-01-03 12.368571 11.700000 12.327143 11.971429 309579900 8.016820
2007-01-04 12.278571 11.974286 12.007143 12.237143 211815100 8.194759
2007-01-05 12.314285 12.057143 12.252857 12.150000 208685400 8.136404
2007-01-08 12.361428 12.182858 12.280000 12.210000 199276700 8.176582
2007-01-09 13.282857 12.164286 12.350000 13.224286 837324600 8.855811
# 查看2006年11月数据的前几行
print(aapl.iloc[22:43].head())
High Low Open Close Volume Adj Close
Date
2006-11-01 11.625714 11.194285 11.585714 11.308572 152798100 7.572930
2006-11-02 11.331429 11.214286 11.274285 11.282857 116370800 7.555712
2006-11-03 11.361428 11.112857 11.337143 11.184286 107972200 7.489699
2006-11-06 11.437143 11.204286 11.278571 11.387143 108644200 7.625546
2006-11-07 11.571428 11.447143 11.492857 11.501429 131483100 7.702079
# 查看2006-11-01 和 2006-12-01 两天的开盘价和收盘价
print(aapl.iloc[[22,43], [2, 3]])
Open Close
Date
2006-11-01 11.585714 11.308572
2006-12-01 13.114285 13.045714
提示:如果仔细查看子集数据,你会发现某些天的数据是缺失的;如果你更仔细地观察其模式,你会发现经常是缺失两或三天;这些天是周末或者假日,所以并不包含在你的数据中。没什么可担心的:这很正常,也无需填补缺失的日期。
除了索引,你可能还想研究其他技术来更好的了解数据。你永远不知道还会发生什么。让我们尝试从数据集中采集20行数据样本,然后按月而不是天对数据 aapl 进行重新采样。可以使用 sample() 和 resample() 函数来实现:
# 采样20行数据
sample = aapl.sample(20)
# 输出`sample`
print(sample)
High Low Open Close Volume Adj Close
Date
2011-08-15 54.995716 54.012856 54.232857 54.772858 115136000 36.679344
2007-03-19 13.078571 12.798572 12.891429 13.018572 178240300 8.718055
2007-11-28 25.799999 25.049999 25.260000 25.745714 287728000 17.240946
2010-09-17 39.708572 39.097141 39.669998 39.338570 158619300 26.343573
2010-03-11 32.214287 31.902857 31.987143 32.214287 101425100 21.572710
2007-01-18 13.158571 12.721429 13.157143 12.724286 591151400 8.520981
2007-06-05 17.527143 17.214285 17.344286 17.524286 230196400 11.735363
2011-03-04 51.470001 51.107143 51.438572 51.428570 113316700 34.439796
2009-12-15 28.215714 27.610001 27.975714 27.738571 104864900 18.575493
2006-12-15 12.745714 12.475715 12.717143 12.531428 184984800 8.391831
2007-08-27 19.237143 18.871429 19.055714 18.892857 176859900 12.651844
2009-01-16 12.054286 11.485714 12.042857 11.761429 261906400 7.876194
2007-03-01 12.615714 11.964286 12.004286 12.437143 353882200 8.328694
2010-05-05 36.877144 35.532856 36.147144 36.570000 220775800 24.489573
2010-09-08 37.770000 37.014286 37.111427 37.560001 131637800 25.152536
2009-07-16 21.145714 20.795713 20.822857 21.074286 98392700 14.112666
2007-06-06 17.721428 17.421429 17.471428 17.662857 278060300 11.828161
2009-05-05 18.980000 18.731428 18.821428 18.958570 99563800 12.695851
2011-09-28 57.677143 56.644287 57.169998 56.715714 107409400 37.980404
2007-04-19 13.035714 12.832857 12.884286 12.895715 106478400 8.635779
# 按月重新采样
monthly_aapl = aapl.resample('M').mean()
# 输出 `monthly_aapl` 的前几行
print(monthly_aapl.head())
High Low Open Close Volume \
Date
2006-10-31 11.123766 10.893117 11.002922 11.017987 1.634995e+08
2006-11-30 12.314626 12.028980 12.161565 12.192109 1.647010e+08
2006-12-31 12.546500 12.205571 12.415857 12.353071 2.111349e+08
2007-01-31 12.880857 12.522572 12.722357 12.697357 3.401223e+08
2007-02-28 12.382932 12.111804 12.252105 12.246842 1.805573e+08
Adj Close
Date
2006-10-31 7.378336
2006-11-30 8.164602
2006-12-31 8.272392
2007-01-31 8.502948
2007-02-28 8.201255
非常直截了当,不是吗?
resample() 函数使用频繁,因为它为时间序列的频率转换提供了精细而灵活的控制:除了指定新的时间间隔,处理缺失数据以外,还能选择对数据重新采样的方式,如上述代码所示。asfreq() 方法与之类似,不过只能实现前两项功能。
提示:在 IPython 控制台中尝试代码 aapl.asfreq("M", method="bfill"),并查看其输出结果。
最后,在进行数据可视化和常见的金融分析这些进阶的数据探索之前,你可能已经开始计算每天开盘价和收盘价之间的差值了。在Pandas的帮助下,可以轻易地实现这一算数运算;只需将 aapl 数据的 Open 列数值减去该数据的 Close 列数值即可。换言之,就是从 aapl.Open 中减去 aapl.Close。将结果存入 aapl 数据框中新的一列 diff 中,另外可以使用 del 将其删除:
# 在`aapl` 中新增一列`diff`
aapl['diff'] = aapl.Open - aapl.Close
# 删除`diff` 列
#del aapl['diff']
提示:请确保注释掉最后一行代码,这样 aapl 数据框的新列不会被删除,并且你可以检查算术运算的结果!
当然,了解绝对收益可帮助你知道自己是否做了一个好的投资。但是作为一名定量分析者,你可能对使用相对方法衡量股票价值更感兴趣,比如某只股票上涨或下跌的幅度。计算每日的百分比变化便是这样一种方法。
现在知道这一点很好,不过也不用担心,接下来你将会越来越深入地进行了解。
本节介绍了在开始预分析之前,进行数据探索的一些方法。但是仍有可提高的余地,如果你想了解更多,可阅读 Python Exploratory Data Analysis 这篇教程。
可视化时间序列数据
在使用 head(), tail(),索引等方法探索数据之后,你大概想要可视化时间序列数据。多亏了Pandas的绘图功能整合了 Matplotlib 包,使这项任务变得容易了;只要使用 plot() 函数并传递给它相关的参数即可。另外,也可以使用 grid 参数来为图片添加网格背景。
让我们检查并运行以下代码,看看如何绘制这样一幅图!
# 导入Matplotlib包的`pyplot` 模块,简写为 `plt`
import matplotlib.pyplot as plt
# 绘制收盘价曲线
aapl['Close'].plot(grid=True)
# 显示绘图
plt.show()
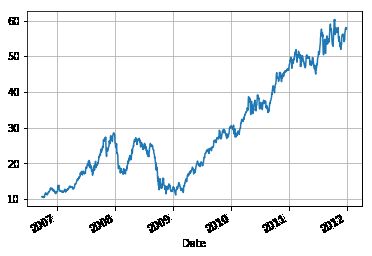
如果你想进一步了解 Matplotlib 包,并学习如何开始使用它,那么可以查看 DataCamp的课程 Intermediate Python for Data Science。
译者注:本教程由以下五部分内容构成:
Python金融入门(本文)
常见的金融分析方法
简单的动量策略开发
回溯测试策略
- 评估交易策略
将分五篇文章发出,本文是该教程的第一部分。