0x00 前言
数据倾斜是大数据领域绕不开的拦路虎,当你所需处理的数据量到达了上亿甚至是千亿条的时候,数据倾斜将是横在你面前一道巨大的坎。
迈的过去,将会海阔天空!迈不过去,就要做好准备:很可能有几周甚至几月都要头疼于数据倾斜导致的各类诡异的问题。
郑重声明:
- 话题比较大,技术要求也比较高,笔者尽最大的能力来写出自己的理解,写的不对和不好的地方大家一起交流。
- 有些例子不是特别严谨,一些小细节对文章理解没有影响,不要太在意。(比如我在算机器内存的时候,就不把Hadoop自身的进程算到使用内存中)
- 总的来讲个人感觉写的还是比较干货的。
文章结构
- 先大致解释一下什么是数据倾斜
- 再根据几个场景来描述一下数据倾斜产生的情况
- 详细分析一下在Hadoop和Spark中产生数据倾斜的原因
- 如何解决(优化)数据倾斜问题?
0x01 什么是数据倾斜
简单的讲,数据倾斜就是我们在计算数据的时候,数据的分散度不够,导致大量的数据集中到了一台或者几台机器上计算,这些数据的计算速度远远低于平均计算速度,导致整个计算过程过慢。
一、关键字:数据倾斜
相信大部分做数据的童鞋们都会遇到数据倾斜,数据倾斜会发生在数据开发的各个环节中,比如:
- 用Hive算数据的时候reduce阶段卡在99.99%
- 用SparkStreaming做实时算法时候,一直会有executor出现OOM的错误,但是其余的executor内存使用率却很低。
这些问题经常会困扰我们,辛辛苦苦等了几个小时的数据就是跑不出来,心里多难过啊。
例子很多,这里先随便举两个,后文会详细的说明。
二、关键字:千亿级
为什么要突出这么大数据量?先说一下笔者自己最初对数据量的理解:
数据量大就了不起了?数据量少,机器也少,计算能力也是有限的,因此难度也是一样的。凭什么数据量大就会有数据倾斜,数据量小就没有?
这样理解也有道理,但是比较片面,举两个场景来对比:
- 公司一:总用户量1000万,5台64G内存的的服务器。
- 公司二:总用户量10亿,1000台64G内存的服务器。
两个公司都部署了Hadoop集群。假设现在遇到了数据倾斜,发生什么?
公司一的数据分时童鞋在做join的时候发生了数据倾斜,会导致有几百万用户的相关数据集中到了一台服务器上,几百万的用户数据,说大也不大,正常字段量的数据的话64G还是能轻松处理掉的。
公司二的数据分时童鞋在做join的时候也发生了数据倾斜,可能会有1个亿的用户相关数据集中到了一台机器上了(相信我,这很常见),这时候一台机器就很难搞定了,最后会很难算出结果。
0x02 数据倾斜长什么样
笔者大部分的数据倾斜问题都解决了,而且也不想重新运行任务来截图,下面会分几个场景来描述一下数据倾斜的特征,方便读者辨别。
由于Hadoop和Spark是最常见的两个计算平台,下面就以这两个平台说明:
一、Hadoop中的数据倾斜
Hadoop中直接贴近用户使用使用的时Mapreduce程序和Hive程序,虽说Hive最后也是用MR来执行(至少目前Hive内存计算并不普及),但是毕竟写的内容逻辑区别很大,一个是程序,一个是Sql,因此这里稍作区分。
Hadoop中的数据倾斜主要表现在、ruduce阶段卡在99.99%,一直99.99%不能结束。
这里如果详细的看日志或者和监控界面的话会发现:
- 有一个多几个reduce卡住
- 各种container报错OOM
- 读写的数据量极大,至少远远超过其它正常的reduce
伴随着数据倾斜,会出现任务被kill等各种诡异的表现。
经验:Hive的数据倾斜,一般都发生在Sql中Group和On上,而且和数据逻辑绑定比较深。
二、Spark中的数据倾斜
Spark中的数据倾斜也很常见,这里包括Spark Streaming和Spark Sql,表现主要有下面几种:
- Executor lost,OOM,Shuffle过程出错
- Driver OOM
- 单个Executor执行时间特别久,整体任务卡在某个阶段不能结束
- 正常运行的任务突然失败
补充一下,在Spark streaming程序中,数据倾斜更容易出现,特别是在程序中包含一些类似sql的join、group这种操作的时候。 因为Spark Streaming程序在运行的时候,我们一般不会分配特别多的内存,因此一旦在这个过程中出现一些数据倾斜,就十分容易造成OOM。
0x03 数据倾斜的原理
一、数据倾斜产生的原因
我们以Spark和Hive的使用场景为例。他们在做数据运算的时候会设计到,countdistinct、group by、join等操作,这些都会触发Shuffle动作,一旦触发,所有相同key的值就会拉到一个或几个节点上,就容易发生单点问题。
二、万恶的shuffle
Shuffle是一个能产生奇迹的地方,不管是在Spark还是Hadoop中,它们的作用都是至关重要的。关于Shuffle的原理,这里不再讲述,看看Hadoop相关的论文或者文章理解一下就ok。这里主要针对,在Shuffle如何产生了数据倾斜。
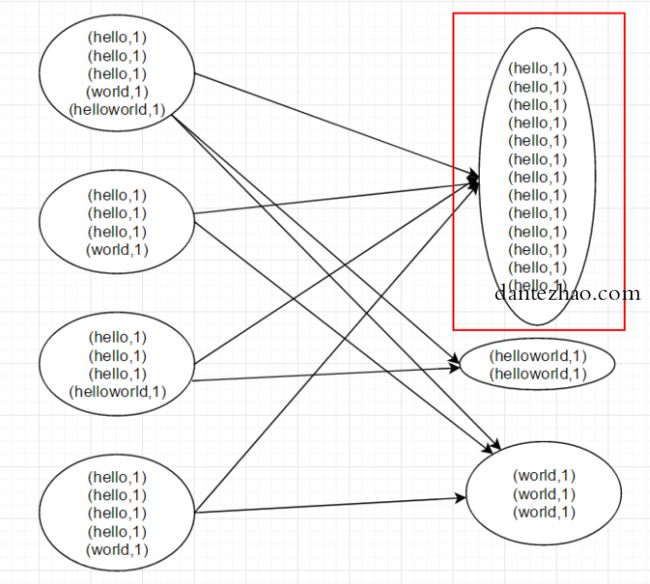
Hadoop和Spark在Shuffle过程中产生数据倾斜的原理基本类似。如下图。
大部分数据倾斜的原理就类似于下图,很明了,因为数据分布不均匀,导致大量的数据分配到了一个节点。
三、从数据角度来理解数据倾斜
我们举一个例子,就说数据默认值的设计吧,假设我们有两张表:
- user(用户信息表):userid,register_ip
- ip(IP表):ip,register_user_cnt
这可能是两个不同的人开发的数据表,如果我们的数据规范不太完善的话,会出现一种情况,user表中的register_ip字段,如果获取不到这个信息,我们默认为null,但是在ip表中,我们在统计这个值的时候,为了方便,我们把获取不到ip的用户,统一认为他们的ip为0。
两边其实都没有错的,但是一旦我们做关联了会出现什么情况,这个任务会在做关联的阶段,也就是sql的on的阶段卡死。
四、从业务计角度来理解数据倾斜
数据往往和业务是强相关的,业务的场景直接影响到了数据的分布。
再举一个例子,比如就说订单场景吧,我们在某一天在北京和上海两个城市多了强力的推广,结果可能是这两个城市的订单量增长了10000%,其余城市的数据量不变。
然后我们要统计不同城市的订单情况,这样,一做group操作,可能直接就数据倾斜了。
0x04 如何解决
数据倾斜的产生是有一些讨论的,解决它们也是有一些讨论的,本章会先给出几个解决数据倾斜的思路,然后对Hadoop和Spark分别给出一些解决数据倾斜的方案。
注意: 很多数据倾斜的问题,都可以用和平台无关的方式解决,比如更好的数据预处理, 异常值的过滤等,因此笔者认为,解决数据倾斜的重点在于对数据设计和业务的理解,这两个搞清楚了,数据倾斜就解决了大部分了。
一、几个思路
解决数据倾斜有这几个思路:
- 业务逻辑,我们从业务逻辑的层面上来优化数据倾斜,比如上面的例子,我们单独对这两个城市来做count,最后和其它城市做整合。
- 程序层面,比如说在Hive中,经常遇到
count(distinct)操作,这样会导致最终只有一个reduce,我们可以先group 再在外面包一层count,就可以了。 - 调参方面,Hadoop和Spark都自带了很多的参数和机制来调节数据倾斜,合理利用它们就能解决大部分问题。
二、从业务和数据上解决数据倾斜
很多数据倾斜都是在数据的使用上造成的。我们举几个场景,并分别给出它们的解决方案。
数据分布不均匀:
前面提到的“从数据角度来理解数据倾斜”和“从业务计角度来理解数据倾斜”中的例子,其实都是数据分布不均匀的类型,这种情况和计算平台无关,我们能通过设计的角度尝试解决它。
- 有损的方法:
- 找到异常数据,比如ip为0的数据,过滤掉
- 无损的方法:
- 对分布不均匀的数据,单独计算
- 先对key做一层hash,先将数据打散让它的并行度变大,再汇集
- 数据预处理
三、Hadoop平台的优化方法
列出来一些方法和思路,具体的参数和用法在官网看就行了。
- mapjoin方式
- count distinct的操作,先转成group,再count
- 万能膏药:hive.groupby.skewindata=true
- left semi jioin的使用
- 设置map端输出、中间结果压缩。(不完全是解决数据倾斜的问题,但是减少了IO读写和网络传输,能提高很多效率)
四、Spark平台的优化方法
列出来一些方法和思路,具体的参数和用法在官网看就行了。
- mapjoin方式
- 设置rdd压缩
- 合理设置driver的内存
- Spark Sql中的优化和Hive类似,可以参考Hive
0xFF 总结
数据倾斜的坑还是很大的,如何处理数据倾斜是一个长期的过程,希望本文的一些思路能提供帮助。
文中一些内容没有细讲,比如Hive Sql的优化,数据清洗中的各种坑,这些留待后面单独的分享,会有很多的内容。
另外千亿级别的数据还会有更多的难点,不仅仅是数据倾斜的问题,这一点在后面也会有专门的分享。
参考
- https://hive.apache.org/
- http://spark.apache.org/
- http://www.jianshu.com/p/17baa9f96ca7
- 还有网上的一些博客也提供的一些思路,不过都没有经验和痛带来的感悟多。
作者:dantezhao | | CSDN | GITHUB
个人主页:http://dantezhao.com
文章可以转载, 但必须以超链接形式标明文章原始出处和作者信息