
2014年R-CNN横空出世,首次将卷积神经网络带入目标检测领域。受SPPnet启发,rbg在15年发表Fast R-CNN,它的构思精巧,流程更为紧凑,大幅提高目标检测速度。
在同样的最大规模网络上,Fast R-CNN和R-CNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。在PASCAL VOC 2007上的准确率相差无几,约在66%-67%之间。
一.Fast R-CNN所解决R-CNN的三个问题
关于R-CNN的一些总结见我另一篇文章 https://www.jianshu.com/p/c1696c27abf8
1.测试速度慢
R-CNN中用CNN对每一个候选区域反复提取特征,而一张图片的2000个候选区域之间有大量重叠部分,这一设定造成特征提取操作浪费大量计算。
Fast R-CNN将整个图像归一化后直接送入CNN网络,卷积层不进行候选区的特征提取,而是在最后一个池化层加入候选区域坐标信息,进行特征提取的计算。
2.训练速度慢
同上
3.训练所需空间大
R-CNN中目标分类与候选框的回归是独立的两个操作,并且需要大量特征作为训练样本。
Fast R-CNN将目标分类与候选框回归统一到CNN网络中来,不需要额外存储特征。
二.Fast R-CNN网络结构

相比R-CNN最大的区别,在于RoI池化层和全连接层中目标分类与检测框回归微调的统一。
1.RoI池化层
RoI池化层可以说是SPP(spatial pyramid pooling)的简化版,关于SPPnet的总结见我的另一篇文章 https://www.jianshu.com/p/90f9d41c6436。RoI池化层去掉了SPP的多尺度池化,直接用MxN的网格,将每个候选区域均匀分成M×N块,对每个块进行max pooling。从而将特征图上大小不一的候选区域转变为大小统一的特征向量,送入下一层。
2.特征提取方式
Fast R-CNN在特征提取上可以说很大程度借鉴了SPPnet,首先将图片用选择搜索算法(selective search)得到2000个候选区域(region proposals)的坐标信息。另一方面,直接将图片归一化到CNN需要的格式,整张图片送入CNN(本文选择的网络是VGG),将第五层的普通池化层替换为RoI池化层,图片然后经过5层卷积操作后,得到一张特征图(feature maps),开始得到的坐标信息通过一定的映射关系转换为对应特征图的坐标,截取对应的候选区域,经过RoI层后提取到固定长度的特征向量,送入全连接层。
3.联合候选框回归与目标分类的全连接层
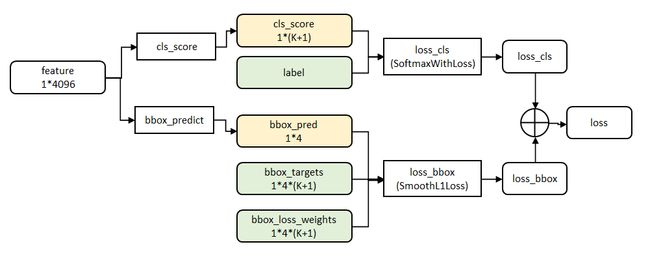
在R-CNN中的流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression进行候选框的微调;Fast R-CNN则是将候选框目标分类与bbox regression并列放入全连接层,形成一个multi-task模型。
cls_ score层用于分类,输出K+1维数组p,表示属于K类和背景的概率。 bbox_predict层用于调整候选区域位置,输出4*K维数组t,表示分别属于K类时,应该平移缩放的参数。
网络的代价函数细节如下图所示:
三.Fast R-CNN的训练与测试
1.训练
首先用ILSVRC 20XX数据集进行预训练,预训练是进行有监督的分类的训练。然后在PASCAL VOC样本上进行特定调优(fine tunning),调优的数据集中25%的正样本(与真实框IoU在0.5-1的候选框)、75%的负样本(与真实框IoU在0.1-0.5的候选框)。PASCAL VOC数据集中既有物体类别标签,也有物体位置标签,有20种物体;正样本仅表示前景,负样本仅表示背景;回归操作仅针对正样本进行。
在调优训练时,每一个mini-batch中首先加入N张完整图片,而后加入从N张图片中选取的R个候选框。这R个候选框可以复用N张图片前5个阶段的网络特征,文章中N=2,R=128。微调前,需要对有监督预训练后的模型进行3步转化:
RoI池化层取代有监督预训练后的VGG-16网络最后一层池化层;
两个并行层取代上述VGG-16网络的最后一层全连接层和softmax层,并行层之一是新全连接层1+原softmax层1000个分类输出修改为21个分类输出【20种类+背景】,并行层之二是新全连接层2+候选区域窗口回归层;
上述网络由原来单输入:一系列图像修改为双输入:一系列图像和这些图像中的一系列候选区域;
2.测试

四.其他亮点
1.SVD全连接层加速网络
图像分类任务中,用于卷积层计算的时间比用于全连接层计算的时间多,而在目标检测任务中,selective search算法提取的建议框比较多【约2k】,几乎有一半的前向计算时间被花费于全连接层,就Fast R-CNN而言,RoI池化层后的全连接层需要进行约2k次【每个建议框都要计算】,因此在Fast R-CNN中可以采用SVD分解加速全连接层计算,具体实现如下:
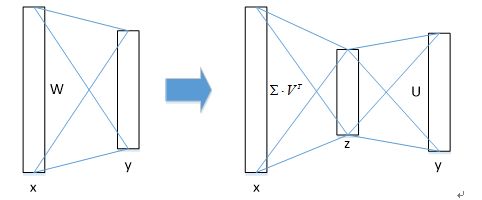
① 物体分类和窗口回归都是通过全连接层实现的,假设全连接层输入数据为x,输出数据为y,全连接层参数为W,尺寸为u×v,那么该层全连接计算为:
y=Wx(计算复杂度为u×v)
② 若将W进行SVD分解,并用前t个特征值近似代替,即:
W=U∑VT≈U(u,1:t)⋅∑(1:t,1:t)⋅V(v,1:t)T
那么原来的前向传播分解成两步:
y=Wx=U⋅(∑⋅VT)⋅x=U⋅z
计算复杂度为u×t+v×t,若t 在实现时,相当于把一个全连接层拆分为两个全连接层,第一个全连接层不含偏置,第二个全连接层含偏置;实验表明,SVD分解全连接层能使mAP只下降0.3%的情况下提升30%的速度,同时该方法也不必再执行额外的微调操作。 R-CNN和SPPnet中采用RoI-centric sampling:从所有图片的所有候选区域中均匀取样,这样每个SGD的mini-batch中包含了不同图像的样本,不同图像之间不能共享卷积计算和内存,运算开销大。 Fast R-CNN中采用image-centric sampling: mini-batch采用层次采样,即先对图像采样【N个】,再在采样到的图像中对候选区域采样【每个图像中采样R/N个,一个mini-batch共计R个候选区域样本】,同一图像的候选区域卷积共享计算和内存,降低了运算开销。 image-centric sampling方式采样的候选区域来自于同一图像,相互之间存在相关性,可能会减慢训练收敛的速度,但是作者在实际实验中并没有出现这样的担忧,反而使用N=2,R=128的image-centric sampling方式比R-CNN收敛更快。 这里解释一下为什么SPPnet不能更新spatial pyramid pooling层前面的卷积层,而只能更新后面的全连接层? 一种说法解释卷积特征是线下计算的,从而无法在微调阶段反向传播误差;另一种解释是,反向传播需要计算每一个RoI感受野的卷积层梯度,通常所有RoI会覆盖整个图像,如果用RoI-centric sampling方式会由于计算too much整幅图像梯度而变得又慢又耗内存。 有的时候,好的成果并不一定全都是首创,Fast R-CNN就是一个很好的说明,SPPnet的池化思想在Fast上得到了简化与发扬,同时作者rbg在R-CNN的基础上进一步将检测框回归整合到了神经网络中来,使得Fast的训练测试速率得到非常大的提升。 论文原文: 参考文章:
2.图片中心化采样image-centric sampling
五.小结
https://www.semanticscholar.org/paper/Fast-R-CNN-Girshick/3dd2f70f48588e9bb89f1e5eec7f0d8750dd920a
https://blog.csdn.net/shenxiaolu1984/article/details/51036677