1.模块化的优点:低耦合 高内聚 方便维护 防止代码冲突(命名冲突)
2.nodejs实现模块化是用闭包。
3.CMD(seajs)--就近依赖 AMD(requirejs)--依赖前置 浏览器端的模块化
4.node基于规范commonjs 文件读写,node天生自带模块化
----1).定义如何创建一个模块 一个js文件你就是一个模块
----2).如何使用一个模块 require文件
----3).如何引用一个模块 exports 或者 moudle.exports
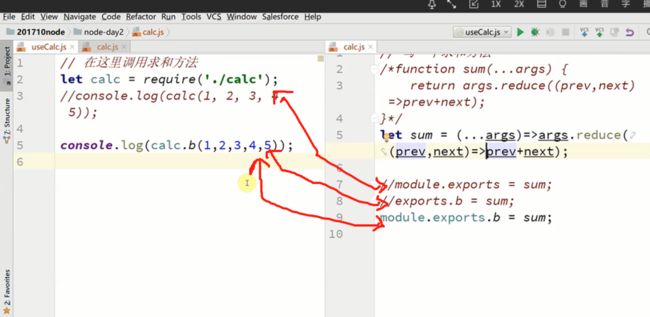
方法文件global.sum = sum,,,调用文件:global.sum(1,2,3,4)
6.require具有缓存功能,多次引用只执行一次
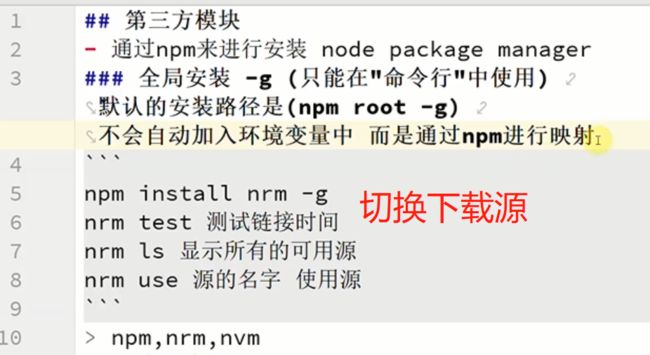
7.第三方模块,要通过npm安装 ---node pacakge manager
------全局安装 - g (只能在命令行中使用)默认的安装路径是node_modules(查看默认安装路径npm root -g)
------本地安装 没有-g参数,安装之前需要初始化文件,记录安装文件 npm init -y --->生成package.json ,目录不能有中文或特殊字符或大写 ===>本地安装又分两种:
一是开发依赖(开发时使用,上线还需要),npm install jQuery(老版要加--save,新版可不加)
二是项目依赖(开发时使用,线上不使用),npm install jquery --save-dev
7.发布包:先切换到国外:nrm use npm ;包名不能和已有的包一样; 入口文件(main),做整合用的; 注册账号:npm addUSer ,有账号就是登陆,没有就是注册,新用户需要校验邮箱; 最后发布:npm publish
8.核心模块(重点来了,放大点)
fs: (let fs = require('fs'),既有同步,又有异步方法,异步有callback)
读取:文件不许存在,不存在会报错。不能通过‘/’读取内容,‘/’表示根目录
1.读取的默认类型是buffer
-----fs.readFile('1.txt','utf8',function(){})异步读取文件(同步用fs.readFileSync('1.txt','utf8')),异步有回调函数,同步没有
2.异步调用,太多容易导致回调地狱 ----> 解决办法:promise resolve成功 reject失败
3.es7的async和await,node版本至少是7.9,,async后面只能跟promise,同时async必须和await同时出现
4.promise.all方法,promise.all[read(),add()].then(function(){}) 都成功调用then,只要有一个失败就掉失败
5.promise解决两个问题:一是毁掉地狱问题,二是合并异步返回结果,
写操作
1.读取都是buffer,写都是utf8,读取文件文件必须存在,写的时候不存在实惠自动创建,有内容会被覆盖,不能直接反对向,需要调用tostring方法。
2.fs.writeFile('1.txt', '南京',function(){}),同步用writeFileSync
3. 同步读写和异步读写函数封装
let fs = require("fs")
// 同步 拷贝
function copySync(source, target) {
// writeFileSync
let res = fs.readFileSync(source)
fs.writeFileSync(target, res)
}
copySync('1.txt', '2.txt')
// 异步拷贝
function copy(source, target, callback) {
fs.readFile(source, function(err, data) {
if (err) {
return callback(err)
} else {
fs.writeFile(target, data, function(err) {})
}
})
}
copy('1.txt', '3.txt', function(err) {
console.log(err)
})
4.文件状态
let fs = require("fs")
fs.start('/', function(err, stats) { ‘/’ 是根路径
console.log(stats)
// atime 访问时间
// mtime 修改时间
// ctime change时间(和mtime大一样,ctime范围更大)
// barthtime 出生日期
if (err) { // 文件不存在,不存在不能读取 }
else {
console.log(stats.isFile()); // 是不是文件
console.log(stats.isDirctory()); // 是不是文件夹
}
})
5. 创建目录,不能调剂创建,也就是没有aaa,就创建不了aaa/bbb
fs.mkdir('aaa', function(err) {
console.log(err)
})
// 递归创建多层目录
function makep(url, callback) {
// a/b/c/d,首先将字符串分成4部分,第一步创建a,第二部创建b...
let urlArr = url.split('/') //[a,b,c,d]
let idx = 0
function make(p){
// 循环完了,把递归停掉,不然会一直循环
if (urlArr.length < idx) return
// 在创建前看是否存在,如果不存在创建,存在继续下一次创建
fs.Stats.apply(p, function(err) {
if (err) {
// err是不存在,创建
fs.mkdir(p, function(err) {
if (err) return console.log(err)
idx++
// 必须要将上一次创建的目录拼接上,不然递归出的结果就是a,b,c,d四个目录
make(urlArr.slice(0, idx+1).join('/'))
})
} else {
// 如果存在,调到下一次创建
idx++
make(urlArr.slice(0, idx+1).join('/'))
}
})
}
make(urlArr[idx])
}
makep('a/b/c/d', function(err) {
console.log('创建成功')
})
path模块
1.path.join,path.reslove方法(特别重要)
let path = require('path')
// 拼一个路径出来,path.join方法
console.log(path.join('./a', './b')) // 结果:a/b
console.log(path.join(__dirname, './b')) // __dirname当前文件的目录,并且是绝对路径,怎样能生成投绝对路径,结果:C:\Users\chao.wang\Desktop\NODE\ZFPX\b
console.log(path.join(__dirname, './b', '..')) // b变为绝对路径,在提到上一级, 结果:C:\Users\chao.wang\Desktop\NODE\ZFPX
// path.reslove方法 (解析一个绝对路径出来,就是你给他一个相对,他返回一个绝对给你)
console.log(path.resolve('./a', './b')) // 结果:C:\Users\chao.wang\Desktop\NODE\ZFPX\a\b
// 可以看出:path.resolve('./a', './b') 和 path.join(__dirname, './b') 返回的结果相同,可相互替换
2.path.delimiter,环境变量分隔符(还是可能有用的,比如看是mac还是win环境还是Linux环境)
console.log(path.delimiter)
console.log(path.win32.delimiter)
console.log(path.posix.sep)
9.事件,上面fs和path其实就是流,流基于事件
* 事件的发布订阅
let EventEmitter = require('events')
let {inherits} = require('util') // 实现继承
function Person() {
}
let boy = new Person()
inherits(Person, EventEmitter) // 继承
boy.on('smile', function(parm) { // on就是事件的订阅(绑定)
console.log(parm)
console.log('哈哈')
})
// 执行
boy.emit('smile', '这里是参数') // 事件的发布(执行)
// 移除
boy.removeListener('smile') // removeAllListener,移除所有事件
es6写EventEmitter
class EventEmitter {
// 'smile':[eat, cry, shopping]
constructor() {
this._events = {}
}
on(eventName, callback) {
// 判断是否有这个事件
if (!this._events[eventName]) {
// 有
this._events[eventName] = [callback]
} else {
// 没有这个事件,放入
this._events[eventName].push(callback)
}
}
emit(eventName) {
this._events[eventName].forEach(cb => cb())
}
}
let e = new EventEmitter()
let haha = () =>{
console.log('smile')
}
e.on('smile', haha) // 绑定几次执行几次
e.emit('smile')
流的介绍(可读流和可写流)
1.可读流 (on('data'), on('err'), on('end'), resume, pause5个方法)
let fs = require('fs')
// 读文件必须存在,每次能读多少,默认64k。 读取默认是buffer
let rs = fs.createReadStream('1.txt')
// 需要监听事件(流失基于事件),数据到来的事件 rs.emit('data', 数据)
// 默认是非流动模式,监听事件后变为流动模式
let arr = []
rs.on('data',function(data) {
arr.push (data)
rs.pause() // 暂停,暂停的是on('data)的触发
// 恢复触发 rs.resume()
setTimeout(function(){
rs.resume()
},1000)
})
// 默认data事件是不停的触发,知道文件的数据被全部读出来,,所有有一个读取结束的方法
rs.on('end', function() {
console.log('end')
// 拿最终数据
console.log(Buffer.concat(arr).toString())
})
// 报错
res.on('err', function(err){
console.log(err)
})
// rs.pause()
// 暂停,暂停的是on('data)的触发
// 恢复触发 rs.resume()
1.可写流createWriteStream
let fs = require('fs')
// 可写流默认占用16k
let ws = fs.createWriteStream('./4.txt',{highWaterMark: 5}) // 新建了个文件4.txt
console.log(ws)
// 可写流的两个方法 write 和 end, 也是异步的,可接受回调函数
// 可写流写数据,必须是字符串类型或者buffer类型
ws.write('12', fn) // 调用下就会往文件里写一下,调用3次,4.txt内容121212
console.log(ws.write('12', fn)) // false ---> 和设置的highWaterMark有关,及如果空间不够的前一步开始返回false
ws.write('12', fn)
console.log(ws.write('12', fn)) //false
ws.write('12', fn)
console.log(ws.write('12', fn)) //false
// 结束调用end,调用end后,不能再用write,同时会把所有write中的内容以最快的速度写入文件
ws.end('结束', fn) // end内容也会写入文件,
function fn() {
console.log(1)
}
// drain事件,当读入的文件全部写入后,就恢复读取(如果end方法调用了,就不会执行了,end会让内容快速写入)
ws.on('drain', function() {
console.log('处理完了')
})
关于流注意:
一个300k文件,一次读64k,就需要读6次,在读取的第一次就开始写,但写一次只能写入16k,所以暂停读取,但调用drain后再恢复读取,就是读64k等写完后再读取64k.....
写个方法
// 30b 读取4b 5次 读取一次就开始写,只能写1b
let fs = require('fs')
function pipe(source, target) {
let rs = fs.createReadStream(source, {highWaterMark: 4})
let ws = fs.createWriteStream(target, {highWaterMark: 1})
// 开启可读流
rs.on('data', function(chunk) {
// 如果可写流不能继续写入了,就暂停读取
if (ws.write(chunk) === false) {
rs.pause()
}
})
// 当当前读入的内容都写入到了文件中,调用继续读取
ws.on('drain', function() {
console.log(`打印几次就读了几次`)
rs.resume()
})
// 当读取完毕,强制将内存中未写入的内容写入到文件中,关闭文件
rs.on('end', function() {
ws.end()
})
}
pipe('4.txt', '5.txt')
换一种快捷写法
let fs = require('fs')
function pipe(source, target) {
let rs = fs.createReadStream(source, {highWaterMark: 4})
let ws = fs.createWriteStream(target, {highWaterMark: 1})
rs.pipe(ws) // 可读流.pipe(可写流),会自动调用write和end方法
}
pipe('4.txt', '5.txt')