Scrapy框架
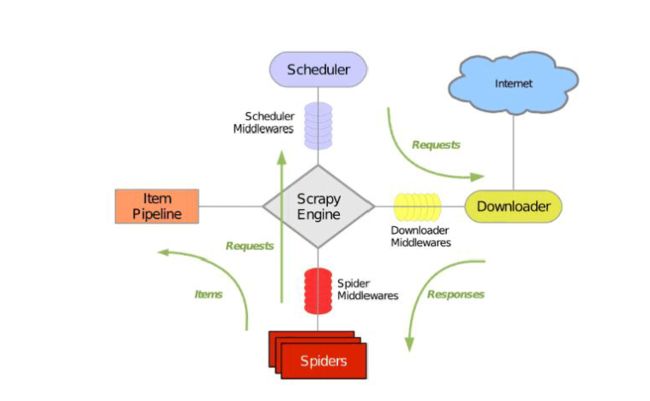
Scrapy Engine:主要负责控制系统各个部件之间的data flow,以及当特定事件发生的时候触发的事件
Scheduler:接受engine发来的request放入队列中,当engine要求的时候再提供给engine
Downloader:负责拉取page并返给engine,engine之后再传递给Spiders
Spider:用户自行编写的代码类,这部分的用户代码主要完成解析response并提取item,或者是跟进页面中获取额外的link url
litem Pipeline:清晰、验证和存储数据
Downloader Middlewares:位于Scrapy引擎和下载器之间的框架,主要处理Scrapy引擎与下载器的请求及响应
Spider Middlewares:主要处理响应的输入和请求输出
Scheduler Middewares:介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应
流程
1、引擎从调度器中取出一个链接(url)用于接下来的抓取
2、引擎把url封装成一个请求(Request)传给下载器
3、下载器把资源下载下来,并封装成应答包(Response)
4、爬虫解析Response
5、解析出实体(ltem),则交给实体管道进行进一步的处理
6、解析出的是链接(url),则把url交给调度器等待抓取
1、工程建立
scrapy startproject hellospider 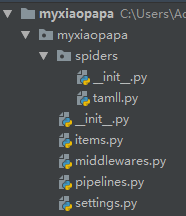
scrapy.cfg:项目的配置文件
myxiaopapa:该项目的python模块,在这里面写代码
myxiaopapa/items.py:需要提取的数据结构定义文件
myxiaopapa/middlewares.py:是和Scrapy的请求/响应处理相关联的框架
myxiaopapa/pipelines.py:用来对items里面提取的数据做进一步处理,如保存等
myxiaopapa/settings.py:项目的配置文件
myxiaopapa/spiders:放置spider代码的目录
2、实现过程
- 在items.py中定义自己要抓取的数据
import scrapy
class MyxiaopapaItem(scrapy.Item):
##抓取商品的标题、价格、状态
title=scrapy.Field()
price=scrapy.Field()
status=scrapy.Fied()- 在spiders目录下编辑自己爬虫文件(我的文叫tamall.py)
import scrapy
from urllib.parse import urlencode
from myxiaopapa import items
class TamllSpider(scrapy.Spider):
'''
name:scrapy唯一定位实例的属性,必须唯一
allowed_domains:允许爬取的域名列表,不设置表示允许爬取所有
start_requests:从start_urls中读取链接,使用make_requests_from_url生成Request,我们可以再start_requests方法中根据自己的需求写入自定义的规律链接
parse:回调函数,处理response并返回处理后的数据跟需要跟进的url
log:打印日志信息
closed:关闭spider
'''
name='tamall'
allowed_domains=['www.tmall.com']
start_urls=['http://httpbin.org/get']
def start_request(self):
for q in self.qs:
self.param={
"自己拼接的路径"
}
url=self.api+urlencode(self.param)
yied scrapy.Request(
url=url,callback=self.gettotalpage,dont_filter=True)
def gettotalpage(self,response):
totalpage = response.css(
'[name="totalPage"]::attr(value)').extract_first()
self.param['totalPage']=int(totalpage)
for i in range(1,self.param['totalPage']+1)
self.param['jumpto']=i
url=self.api+urlencode(self.param)
yield scrapy.Request(
url=url,callback=self.get_info,dont_filter=True)
def get_info(self,response):
product_list=response.css('.product')
for product in product_list:
title=product.css('筛选条件').extract_first()
price=product.css('筛选条件').extract_first()
status=product.css('筛选条件').extract_first()
item=items.MyxiaopapaItem()
item['title']=title
item['price']=price
item['status']=status
yeid item- 在pipelines.py中进行数据库存储
import pymongo
class MyxiaopapaPiepeline(object):
def __init(self,host,port,db,table):
self.host=host
self.port=port
self.db=db
self.table=table
@classmethod
def from_crawler(cls,crawl):
port=crawl.settings.get('PORT')
host=crawl.settings.get('HOST')
db=crawl.settings.get('DB')
table=crawl.settings.get('TABLE')
return cls(host,port,db,table)
def open_spider(self,crawl):
self.client=pymongo.MongoClient(port=self.port,host=self.host)
db_obj=self.client[self.db]
self.table_obj=db_obj[self.table]
def close_spider(self,crawl):
self.client.close()
def process_item(self,item,spider):
self.table_obj.insert(dict(item))
print('存储成功')
return item
- 在settings.py 中对相关配置进行设置
BOT_NAME='myxiaopapa'
SPIDER_MODULES=['myxiaopapa.spiders']
NEWSPIDER_MODULE='myxiaopapa.spiders'
HOST='ip地址'
PORT='端口号'
DB='数据库名'
TABLE='表名'
ROBOTSTXT_OBEY=False
DEFAULT_REQUEST_HEADERS = { 'Accept':'text/html,application/xhtml+xml,application/xml;
q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
"User-Agent": "请求头"
}
DOWNLOADER_MIDDLEWARES = {
'myxiaopapa.middlewares.MyxiaopapaDownloaderMiddleware': 300, # 数值越小,优先级越高
}