深度学习中确实用不到CV。
所以学习CV的目的还是要知道CV能做什么,适用于哪些场景(主要用于数据集小,容易过拟合) 。
CV目的:model selection
可以参考这篇回答:https://stats.stackexchange.com/questions/52274/how-to-choose-a-predictive-model-after-k-fold-cross-validation
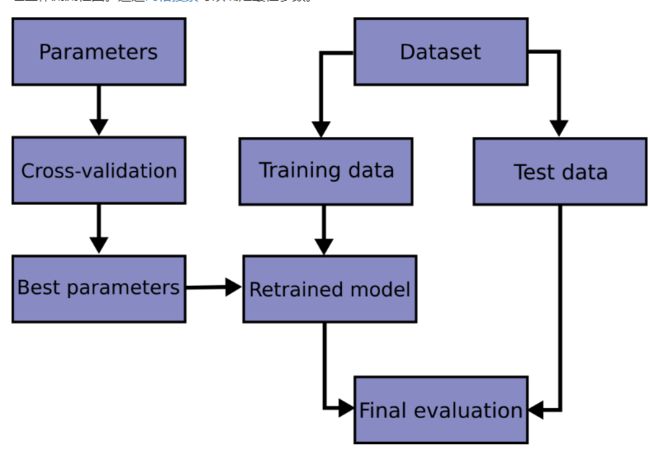
Fig 1 工作流图
CV常用方法:
高级API
(1) cross_val_score
使用交叉验证最简单的方法是在估计器和数据集上调用 cross_val_score 辅助函数。
这个函数基本上是最精简的接口了!
sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=None, verbose=0, fit_params=None, pre_dispatch='2*n_jobs', error_score=nan)
重点关注以下三个参数:
groups:组CV。
scoring:evaluation method。 关于scoring参数列表,参考该文章:https://blog.csdn.net/qq_32590631/article/details/82831613
cv:默认为K-fold,可以自定义传入cv iterator,sklearn也提供了很多cv iterator的方法,如ShuffleSplit等。后面会介绍。

(2) cross_validate
cross_validate 函数与 cross_val_score 在下面的两个方面有些不同 -
- 它允许指定多个指标进行评估.
- 除了测试得分之外,它还会返回一个包含训练得分,拟合次数, score-times (得分次数)的一个字典。 It returns a dict containing training scores, fit-times and score-times in addition to the test score.
对于单个度量评估,其中 scoring 参数是一个字符串,可以调用或 None , keys 将是 - ['test_score', 'fit_time', 'score_time']
而对于多度量评估,返回值是一个带有以下的 keys 的字典 - ['test_
return_train_score 默认设置为 True 。 它增加了所有 scorers(得分器) 的训练得分 keys 。如果不需要训练 scores ,则应将其明确设置为 False 。
你还可以通过设置return_estimator=True来保留在所有训练集上拟合好的估计器。
可以将多个测度指标指定为list,tuple或者是预定义评分器(predefined scorer)的名字的集合。
(3) cross_val_predict
除了返回结果不同,函数 cross_val_predict 具有和 cross_val_score 相同的接口, 对于每一个输入的元素,如果其在测试集合中,将会得到预测结果。交叉验证策略会将可用的元素提交到测试集合有且仅有一次(否则会抛出一个异常)。
警告 :交叉预测可能使用不当
cross_val_predict函数的结果可能会与cross_val_score函数的结果不一样,因为在这两种方法中元素的分组方式不一样。函数cross_val_score在所有交叉验证的折子上取平均。但是,函数cross_val_predict只是简单的返回由若干不同模型预测出的标签或概率。因此,cross_val_predict不是一种适当的泛化错误的度量。
函数cross_val_predict比较适合做下列事儿:
- 从不同模型获得的预测结果的可视化。
- 模型混合: 在集成方法中,当一个有监督估计量的预测被用来训练另一个估计量时
CV ITERATOR
简介:
假设一些数据是独立的和相同分布的 (i.i.d) 假定所有的样本来源于相同的生成过程,并假设生成过程没有记忆过去生成的样本。
在这种情况下可以使用下面的交叉验证器。
注意
尽管 i.i.d 数据是机器学习理论中的一个常见假设,但在实践中很少成立。如果知道样本是使用时间相关的过程生成的,则使用 time-series aware cross-validation scheme 更安全。 同样,如果我们知道生成过程具有 group structure (群体结构)(从不同 subjects(主体) , experiments(实验), measurement devices (测量设备)收集的样本),则使用 group-wise cross-validation 更安全。
(1) KFold方法 k折交叉验证
(2) RepeatedKFold p次k折交叉验证
(3) LeaveOneOut 留一法
(4) LeavePOut 留P法
ShuffleSplit 随机分配
其它特殊情况的数据划分方法
1:对于分类数据来说,它们的target可能分配是不均匀的,比如在医疗数据当中得癌症的人比不得癌症的人少很多,这个时候,使用的数据划分方法有 StratifiedKFold ,StratifiedShuffleSplit
2:对于分组数据来说,它的划分方法是不一样的,主要的方法有 GroupKFold,LeaveOneGroupOut,LeavePGroupOut,GroupShuffleSplit
3:对于时间关联的数据,方法有TimeSeriesSplit
拓展
CV架构:Nested CV 参考:https://www.jianshu.com/p/cdf6df99b44b
代码实战:
Kfold,StratifiedKfold,LBO,GroupKFold不同验证方法的实验结果比较
网址:https://blog.csdn.net/appleyuchi/article/details/100778321
Reference
1. Sklearn API
https://sklearn.apachecn.org/docs/0.21.3/30.html
2. 使用sklearn进行交叉验证
https://www.cnblogs.com/jiaxin359/p/8552800.html