上一章写了如何使用DOM来解析和生成xml
接下来这章将讲解SAX方式解析和生成xml
下面我们看下DOM和SAX的优缺点分析
- DOM(文件对象模型)解析:解析器读入整个文档,然后构建一个驻留内存的树结构,然后代码就可以根据DOM接口来操作这个树结构了。
- 优点:整个文档读入内存,方便操作:支持修改、删除和重现排列等多种功能。
- 缺点:将整个文档读入内存中,保留了过多的不需要的节点,浪费内存和空间。
- 使用场合:一旦读入文档,还需要多次对文档进行操作,并且在硬件资源充足的情况下(内存,CPU)。
- 为了解决DOM解析存在的问题,就出现了SAX解析。其特点为:
- 优点:不用实现调入整个文档,占用资源少。尤其在嵌入式环境中,如android,极力推荐使用SAX解析。
- 缺点:不像DOM解析一样将文档长期驻留在内存中,数据不是持久的。如果事件过后没有保存数据,数据就会丢失。
- 使用场合:机器有性能限制。
一、SAX解析XML
下面是SAX实现实体解析的步骤
- //下面使用XMLReader 来解析
- (一)第一步:新建一个工厂类SAXParserFactory,代码如下:
- SAXParserFactory factory = SAXParserFactory.newInstance();
- (二)第二步:让工厂类产生一个SAX的解析类SAXParser,代码如下:
- SAXParser parser = factory.newSAXParser();
- (三)第三步:从SAXPsrser中得到一个XMLReader实例,代码如下:
- XMLReader reader = parser.getXMLReader();
- (四)第四步:把自己写的handler注册到XMLReader中,一般最重要的就是ContentHandler,代码如下:
- reader.setContentHandler(this);
- (五)第五步:将一个xml文档或者资源变成一个java可以处理的InputStream流后,解析正式开始,代码如下:
- reader.parse(new InputSource(is));
- //下面使用SAXParser来解析
- (一)第一步:新建一个工厂类SAXParserFactory,代码如下:
- SAXParserFactory factory = SAXParserFactory.newInstance();
- (二)第二步:让工厂类产生一个SAX的解析类SAXParser,代码如下:
- SAXParser parser = factory.newSAXParser();
- (三)第三步:将一个xml文档或者资源变成一个java可以处理的InputStream流后,解析正式开始,代码如下:
- parser.parse(is,this);
估计大家都看到了ContentHandler ,下面具体的讲下
解析开始之前,需要向XMLReader/SAXParser 注册一个ContentHandler,也就是相当于一个事件监听器,在ContentHandler中定义了很多方法
- //设置一个可以定位文档内容事件发生位置的定位器对象
- public void setDocumentLocator(Locator locator)
- //用于处理文档解析开始事件
- public void startDocument()throws SAXException
- //处理元素开始事件,从参数中可以获得元素所在名称空间的uri,元素名称,属性类表等信息
- public void startElement(String namespacesURI , String localName , String qName , Attributes atts) throws SAXException
- //处理元素结束事件,从参数中可以获得元素所在名称空间的uri,元素名称等信息
- public void endElement(String namespacesURI , String localName , String qName) throws SAXException
- //处理元素的字符内容,从参数中可以获得内容
- public void characters(char[] ch , int start , int length) throws SAXException
顺便介绍下XMLReader中的方法。
- //注册处理XML文档解析事件ContentHandler
- public void setContentHandler(ContentHandler handler)
- //开始解析一个XML文档
- public void parse(InputSorce input) throws SAXException
下面是流程图
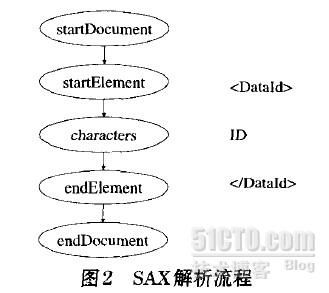
大概的讲的差不多了 接下来开始讲解解析的步骤
我们还是用上一章的代码
首先 我们创建一个Person类 用来存储用户的信息
- package com.example.demo;
- import java.io.Serializable;
- public class Person implements Serializable {
- /**
- *
- */
- private static final long serialVersionUID = 1L;
- private String _id;
- private String _name;
- private String _age;
- public String get_id() {
- return _id;
- }
- public void set_id(String _id) {
- this._id = _id;
- }
- public String get_name() {
- return _name;
- }
- public void set_name(String _name) {
- this._name = _name;
- }
- public String get_age() {
- return _age;
- }
- public void set_age(String _age) {
- this._age = _age;
- }
- }
接下来 我们要实现一个ContentHandler 用来解析XML
实现一个ContentHandler 一般需要下面几个步骤
- 1、声明一个类,继承DefaultHandler。DefaultHandler是一个基类,这个类里面简单实现了一个ContentHandler。我们只需要重写里面的方法即可。
- 2、重写 startDocument() 和 endDocument(),一般将正式解析之前的初始化放到startDocument()里面,收尾的工作放到endDocument()里面。
- 3、重写startElement(),XML解析器遇到XML里面的tag时就会调用这个函数。经常在这个函数内是通过对localName的值进行判断而操作一些数据。
- 4、重写characters()方法,这是一个回调方法。解析器执行完startElement()后,解析节点的内容后就会执行这个方法,并且参数ch[]就是节点的内容。
- 5、重写endElement()方法,这个方法与startElement()相对应,解析完一个tag节点后,执行这个方法,解析一个tag后,调用这个处理还原和清除相关信息
首先 新建一个类 继承DefaultHandler 并重写以下几个方法
- public class SAX_parserXML extends DefaultHandler {
- /**
- * 当开始解析xml文件的声明的时候就会触发这个事件, 可以做一些初始化的工作
- * */
- @Override
- public void startDocument() throws SAXException {
- // TODO Auto-generated method stub
- super.startDocument();
- }
- /**
- * 当开始解析元素的开始标签的时候,就会触发这个事件
- * */
- @Override
- public void startElement(String uri, String localName, String qName,
- Attributes attributes) throws SAXException {
- // TODO Auto-generated method stub
- super.startElement(uri, localName, qName, attributes);
- }
- /**
- * 当读到文本元素的时候要触发这个事件.
- * */
- @Override
- public void characters(char[] ch, int start, int length)
- throws SAXException {
- // TODO Auto-generated method stub
- super.characters(ch, start, length);
- }
- /**
- * 当读到结束标签的时候 就会触发这个事件
- * */
- @Override
- public void endElement(String uri, String localName, String qName)
- throws SAXException {
- // TODO Auto-generated method stub
- super.endElement(uri, localName, qName);
- }
- }
首先 我们创建一个list 用来保存解析出来的person数据
- List
persons;
但是?在哪里初始化呢?我们可以在startDocument()里面初始化,因为当开始解析xml文件的声明的时候就会触发这个事件所以放在这里比较合适
- /**
- * 当开始解析xml文件的声明的时候就会触发这个事件, 可以做一些初始化的工作
- * */
- @Override
- public void startDocument() throws SAXException {
- // TODO Auto-generated method stub
- super.startDocument();
- // 初始化list
- persons = new ArrayList
(); - }
接下来 就要开始解析了
- /**
- * 当开始解析元素的开始标签的时候,就会触发这个事件
- * */
- @Override
- public void startElement(String uri, String localName, String qName,
- Attributes attributes) throws SAXException {
- // TODO Auto-generated method stub
- super.startElement(uri, localName, qName, attributes);
- // 如果读到是person标签 开始存储
- if (localName.equals("person")) {
- person = new Person();
- person.set_id(attributes.getValue("id"));
- }
- curNode = localName;
- }
上面的代码中 localName表示当前解析到的元素名
- //步骤
- //1.判断是否是person元素
- //2.创建新的Person对象
- //3.获取id 添加到Person对象中
curNode 用来保存当前的元素名 在characters中会使用到
- /**
- * 当读到文本元素的时候要触发这个事件.
- * */
- @Override
- public void characters(char[] ch, int start, int length)
- throws SAXException {
- // TODO Auto-generated method stub
- super.characters(ch, start, length);
- if (person != null) {
- //取出目前元素对应的值
- String txt = new String(ch, start, length);
- //判断元素是否是name
- if (curNode.equals("name")) {
- //将取出的值添加到person对象
- person.set_name(txt);
- } else if (curNode.equals("age")) {
- person.set_age(txt);
- }
- }
- }
接下来是介绍标签结束的时候需要做的事情
- /**
- * 当读到结束标签的时候 就会触发这个事件
- * */
- @Override
- public void endElement(String uri, String localName, String qName)
- throws SAXException {
- // TODO Auto-generated method stub
- super.endElement(uri, localName, qName);
- // 如果是 并且person不为空,添加到list
- if (localName.equals("person") && person != null) {
- persons.add(person);
- person = null;
- }
- curNode = "";
- }
解析的事情结束了 大概流程就是
- 1.一个元素开始时 会调用startElement方法
- 2.接下来会调用到characters方法,可以用来获取元素的值
- 3.一个元素结束时 会调用到endElement方法
解析结束之后 我们需要写一个方法 用来获取解析后保存的list
- public List
ReadXML(InputStream is) { - SAXParserFactory factory = SAXParserFactory.newInstance();
- try {
- SAXParser parser = factory.newSAXParser();
- // 第一种方法
- // parser.parse(is, this);
- // 第二种方法
- XMLReader reader = parser.getXMLReader();
- reader.setContentHandler(this);
- reader.parse(new InputSource(is));
- } catch (Exception e) {
- // TODO: handle exception
- e.printStackTrace();
- }
- return persons;
- }
上面的代码就不解释了 只要将inputStream对象传入 就可以解析出内容
看完了代码,我来给出完整的代码
- package com.example.demo.Utils;
- import java.io.InputStream;
- import java.util.ArrayList;
- import java.util.List;
- import javax.xml.parsers.SAXParser;
- import javax.xml.parsers.SAXParserFactory;
- import org.xml.sax.Attributes;
- import org.xml.sax.InputSource;
- import org.xml.sax.SAXException;
- import org.xml.sax.XMLReader;
- import org.xml.sax.helpers.DefaultHandler;
- import com.example.demo.Person;
- public class SAX_parserXML extends DefaultHandler {
- List
persons; - Person person;
- // 当前节点
- String curNode;
- public List
ReadXML(InputStream is) { - SAXParserFactory factory = SAXParserFactory.newInstance();
- try {
- SAXParser parser = factory.newSAXParser();
- // 第一种方法
- // parser.parse(is, this);
- // 第二种方法
- XMLReader reader = parser.getXMLReader();
- reader.setContentHandler(this);
- reader.parse(new InputSource(is));
- } catch (Exception e) {
- // TODO: handle exception
- e.printStackTrace();
- }
- return persons;
- }
- /**
- * 当开始解析xml文件的声明的时候就会触发这个事件, 可以做一些初始化的工作
- * */
- @Override
- public void startDocument() throws SAXException {
- // TODO Auto-generated method stub
- super.startDocument();
- // 初始化list
- persons = new ArrayList
(); - }
- /**
- * 当开始解析元素的开始标签的时候,就会触发这个事件
- * */
- @Override
- public void startElement(String uri, String localName, String qName,
- Attributes attributes) throws SAXException {
- // TODO Auto-generated method stub
- super.startElement(uri, localName, qName, attributes);
- // 如果读到是person标签 开始存储
- if (localName.equals("person")) {
- person = new Person();
- person.set_id(attributes.getValue("id"));
- }
- curNode = localName;
- }
- /**
- * 当读到文本元素的时候要触发这个事件.
- * */
- @Override
- public void characters(char[] ch, int start, int length)
- throws SAXException {
- // TODO Auto-generated method stub
- super.characters(ch, start, length);
- if (person != null) {
- // 取出目前元素对应的值
- String txt = new String(ch, start, length);
- // 判断元素是否是name
- if (curNode.equals("name")) {
- // 将取出的值添加到person对象
- person.set_name(txt);
- } else if (curNode.equals("age")) {
- person.set_age(txt);
- }
- }
- }
- /**
- * 当读到结束标签的时候 就会触发这个事件
- * */
- @Override
- public void endElement(String uri, String localName, String qName)
- throws SAXException {
- // TODO Auto-generated method stub
- super.endElement(uri, localName, qName);
- // 如果是person结尾 并且person不为空,添加到list
- if (localName.equals("person") && person != null) {
- persons.add(person);
- person = null;
- }
- curNode = "";
- }
- }
写个方法调用下这个类
- List
persons = new SAX_parserXML().ReadXML(is);- StringBuffer buffer = new StringBuffer();
- for (int i = 0; i < persons.size(); i++) {
- Person person =persons.get(i);
- buffer.append("id:" + person.get_id() + " ");
- buffer.append("name:" + person.get_name() + " ");
- buffer.append("age:" + person.get_age() + "\n");
- }
- Toast.makeText(activity, buffer, Toast.LENGTH_LONG).show();
如果你看到下面的界面 说明解析成功了~

解析的问题 就讲到这里 如果有缺少的 有问题的 可以留言 会在博客中补充
二、SAX生成XML
Sax方式创建XML,应用了标准xml构造器 javax.xml.transform.sax.TransformerHandler 事件来创建 XML 文档
首先,SAXTransformerFactory.newInstance() 创建一个工厂实例 factory
接着,factory.newTransformerHandler() 获取 TransformerHandler 的 handler 对象
然后,通过 handler 事件创建handler.getTransformer()、 handler.setResult(result),以及 startDocument()、startElement、characters、endElement、endDocument()等
写代码之前 我们来讲下几个会用到的类
SAXTransformerFactory
此类扩展了 TransformerFactory 以提供特定于 SAX 的工厂方法。它提供两种类型的 ContentHandler,一种用于创建 Transformer,另一种用于创建 Templates 对象。
如果应用程序希望设置转换期间所使用的 XMLReader 的 ErrorHandler 或 EntityResolver,那么它应使用 URIResolver 来返回提供了(通过 getXMLReader)对 XMLReader 引用的 SAXSource。
newTemplatesHandler() |
获取能够将 SAX ContentHandler 事件处理为 Templates 对象的 TemplatesHandler 对象。 |
newTransformerHandler() |
获取能够将 SAX ContentHandler 事件处理为 Result 的 TransformerHandler 对象。 |
newTransformerHandler(Source src) |
基于参数所指定的转换指令,获取能够将 SAX ContentHandler 事件处理为 Result 的 TransformerHandler 对象。 |
newTransformerHandler(Templates templates) |
基于 Templates 参数,获取能够将 SAX ContentHandler 事件处理为 Result 的 TransformerHandler 对象。 |
newXMLFilter(Source src) |
创建使用给定 Source 作为转换指令的 XMLFilter |
newXMLFilter(Templates templates) |
基于 Templates 参数,创建 XMLFilter |
TransformerHandler
侦听 SAX ContentHandler 解析事件,并将它们转换为 Result 的 TransformerHandler
getTransformer() |
获取与此处理程序关联的 Transformer,用于设置参数和输出属性。 |
setResult(Result result) |
设置与用于转换的此 TransformerHandler 关联的 Result。 |
首先 我们来创建一个工程实例
- SAXTransformerFactory factory = (SAXTransformerFactory) SAXTransformerFactory
- .newInstance();
接下来 获取handler对象
- TransformerHandler handler = factory.newTransformerHandler();
通过handler.getTransformer()获取Transformer对象 ,然后设置xml的属性
- // 获取与此处理程序关联的 Transformer,用于设置参数和输出属性。
- Transformer info = handler.getTransformer();
- // 是否自动添加额外的空白
- info.setOutputProperty(OutputKeys.INDENT, "yes");
- // 设置字符编码
- info.setOutputProperty(OutputKeys.ENCODING, "utf-8");
- info.setOutputProperty(OutputKeys.VERSION, "1.0");
创建一个StreamResult对象用来保存创建的xml
- StringWriter stringWriter = new StringWriter();
- // 创建一个StreamResult对象用来保存创建的xml
- StreamResult result = new StreamResult(stringWriter);
- handler.setResult(result);
下面开始处理生成xml,先创建测试数据
- private List
getTestValues() { - List
persons = new ArrayList (); - Person person = new Person();
- person.set_id("23");
- person.set_name("李磊");
- person.set_age("30");
- persons.add(person);
- person = new Person();
- person.set_id("20");
- person.set_name("韩梅梅");
- person.set_age("25");
- persons.add(person);
- return persons;
- }
来看下最后生成的xml是什么样子的?
- xml version="1.0" encoding="UTF-8"?>
- <persons>
- <person id="23">
- <name>李磊name>
- <age>30age>
- person>
- <person id="20">
- <name>韩梅梅name>
- <age>25age>
- person>
- persons>
调用startDocument()表示开始 ,调用endDocument()表示结束,所以 写代码的时候直接把两个都写上,以防万一最后忘记
- // 开始xml
- handler.startDocument();
- /*代码写在start和end之间*/
- // 结束xml
- handler.endDocument();
接下来开始写xml 第一步 创建根节点persons,同样的,接下来的代码卸载start和end之间
- AttributesImpl impl = new AttributesImpl();
- impl.clear();
- handler.startElement("", "", "persons", impl);
- //创建要对应结束 所以写完start 马上补充end
- handler.endElement("", "", "persons");
创建完根节点之后 开始创建person元素 person中含有一个id属性
- impl.clear();
- impl.addAttribute("", "", "id", "", person.get_id());
- handler.startElement("", "", "person", impl);
- /*在这里创建name和age元素*/
- handler.endElement("", "", "person");
下面创建name和age元素
- impl.clear();
- handler.startElement("", "", "name", impl);
- String txt = person.get_name();
- handler.characters(txt.toCharArray(), 0, txt.length());
- handler.endElement("", "", "name");
- impl.clear();
- handler.startElement("", "", "age", impl);
- txt = person.get_age();
- handler.characters(txt.toCharArray(), 0, txt.length());
- handler.endElement("", "", "age");
看下完整代码
- public String createXML() {
- // TODO Auto-generated method stub
- StringWriter stringWriter = new StringWriter();
- // 创建测试数据
- List
persons = getTestValues(); - try {
- // 创建工厂
- SAXTransformerFactory factory = (SAXTransformerFactory) SAXTransformerFactory
- .newInstance();
- TransformerHandler handler = factory.newTransformerHandler();
- Transformer info = handler.getTransformer();
- // 是否自动添加额外的空白
- info.setOutputProperty(OutputKeys.INDENT, "yes");
- // 设置字符编码
- info.setOutputProperty(OutputKeys.ENCODING, "utf-8");
- info.setOutputProperty(OutputKeys.VERSION, "1.0");
- // 保存创建的xml
- StreamResult result = new StreamResult(stringWriter);
- handler.setResult(result);
- // 开始xml
- handler.startDocument();
- AttributesImpl impl = new AttributesImpl();
- impl.clear();
- handler.startElement("", "", "persons", impl);
- for (int i = 0; i < persons.size(); i++) {
- Person person = persons.get(i);
- impl.clear();
- impl.addAttribute("", "", "id", "", person.get_id());
- handler.startElement("", "", "person", impl);
- impl.clear();
- handler.startElement("", "", "name", impl);
- String txt = person.get_name();
- handler.characters(txt.toCharArray(), 0, txt.length());
- handler.endElement("", "", "name");
- impl.clear();
- handler.startElement("", "", "age", impl);
- txt = person.get_age();
- handler.characters(txt.toCharArray(), 0, txt.length());
- handler.endElement("", "", "age");
- handler.endElement("", "", "person");
- }
- handler.endElement("", "", "persons");
- // 结束xml
- handler.endDocument();
- return stringWriter.toString();
- } catch (Exception e) {
- // TODO: handle exception
- e.printStackTrace();
- }
- return null;
- }
调用方法 查看返回的String是不是xml格式的 如果是的 表示调用成功了
我要讲解了 也就结束了
个人语言水平有限 不懂的 可以留言 我修改
下面一章会讲解pull解析和生成xml