一、Pandas文件读写
pandas很核心的一个功能就是数据读取、导入,pandas支援大部分主流的数据储存格式,并在导入的时候可以做筛选、预处理。在读取数据时的选项有超过50个参数,可见pandas对于各式各样的数据都能有非常好的应对能力。下面先介绍基本的读取指令。

前面两个read_csv和read_table是用的比较多的两种。下面为实际操作的范例。


当然大部分的时候数据导入不会这么顺利,因为源数据里可能会有多种的分离方式,里面还会夹杂一些脏数据,所以pandas附上了一些选项来帮助导入的数据可以更整洁,像是上面就是用了sep选项将逗号“,”设定为分隔符号。pandas还可以自定索引、列名称等,这边就不逐个介绍,因为我在用的时候也不常去用这些功能,真的需要再查就可以了。下面列了一些比较常用的导入选项。也是需要的时候再查看就行。

当文件数据量很大的时候,我们有时候不想每次都将所有的数据显示出来,可以用下面的指令只显示前面5个和后面5个。

或是在读取的时候只读取前面几个,节省导入时间
![]()
Pandas文件导出
除了读取数据,pandas也可以将整理好的数据导出,指令为 to_csv

本书还提到了几种格式的数据导入导出,例如JSON、HTML、HDF5、EXCEL、SQL,我个人觉得看看就好,知道可以用pandas导入,等要用的时候再细看就好。
二、数据清洗
Pandas另外一个强大的功能就是对数据进行清洗和准备分析数据。在传统数据分析上面这个部分往往是最消耗时间的,因为许多行业的原始数据多多少少都会有些脏数据、缺失数据,如果没及时发现会影响整个分析的结果,而pandas提供的数据清洗工具都是由实际需求和问题转化而来的,基本上可以因应大部分数据清洗、准备遇到的问题。
1、缺失值
当表中数据缺失时,会用NaN来表示,对于缺失数据的操作,如下表所示,可以使用isnull来查是否有缺失,fillna将缺失值填入指定数据,dropna会丢弃含有NaN的行。

对于缺失数据的处理方式一般有三种,1、抛弃行 2、抛弃列 3、填充。dropna就是抛弃行的方式,但大部分的情况下,我们会希望我们的数据是完整、数量多的,所以填充是比较常见的处理方式,下面的指令就是将所有的缺失数据以“0”表示,取代NaN
![]()
也可以对每一列填上不同的填充数字,如下图,将1的列填上0.5,2的列填上0

另外一个常用的就是填入平均数,因为对于某些数据,例如商品价格,如果填入0可能对分析结果会有比较大的影像,而填入平均数则可以将缺失数据的影响降低。

2、重复数据
跟缺失数据一样,重复数据的处理指令也是有查看重复数据duplicated(),丢弃重复数据drop_duplicates(),也是有许多选项可以设定的。
3、数据映射
如果想要将两个表的数据合并,首先要先找到对应值,然后用map的方法join过去,下面范例由于其中一个表的对应值混有大写,所以要先对对应值进行处理(小写化),再投映过去,不然电脑会认为两边的对应值不同,造成部分数据投映不过去。当然,也可以投映过去后发现是哪些数据没有弄到,再查看原因解决也行。


4、数据替换
有些表会用其他元素取代NaN代表缺失数据,但这些预设的填充值可能会影响分析结果,所以需要先把这些数据替换成其他的数据,可以使用replace,下面就是将原本-999的数替换成NaN。
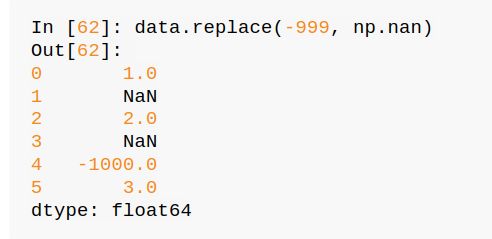
或是可以用字典的方式进行替换,下图是将-999替换为NaN,-1000替换成0

也可以对行列名称进行替换,这边用rename

5、排序和采样
在训练机器的时候,我们不希望将所有的数据都用来做训练,所以必须要做采样,代码为下,n为采样数。

但是随机采样有可能采集到的数比较偏,不能代表整体,对此,我们必须先做分层,并在每层按比例采取样本,训练出的结果会比较符合群体。pandas提供了cut这个功能来对样本进行分层,分层最重要的是以哪个维度作为分层的依据,下面的代码依照年龄作为分层的依据。
![]()
6、检测和过滤异常
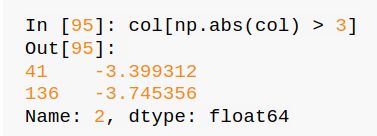
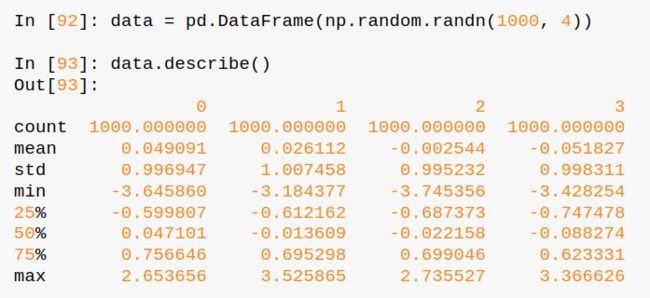
用describe()可以将数据做简单的统计展示,如下
然后可以输入一些条件指令来检查是否有符合条件的数据,如下图是检查是否有绝对值大于3的数