本文以TermQuery,GlobalOrdinalsStringTermsAggregator为例,通过代码,分析es,lucene搜索及聚合流程。
1:协调节点收到请求后,将search任务发到相关的各个shard。
相关代码:
TransportSearchAction.executeSearch
TransportSearchAction.searchAsyncAction.start
AbstractSearchAsyncAction.executePhase(SearchQueryThenFetchAsyncAction)
InitialSearchPhase.performPhaseOnShard
SearchQueryThenFetchAsyncAction.executePhaseOnShard
2:数据节点查询及聚合一个shard。
相关代码:
SearchService.executeQueryPhase
2.1:根据request构造SearchContext。
SearchContext
包含Query,Aggregator等重要信息。并将记录查询,聚合结果。
Query
根据request创建具体的query,如:
TermQuery:用于keyword,text字段。索引结构为倒排。
PointRangeQuery:用于数字,日期,ip,point等字段。索引结构为k-d tree。
Aggregator
此时仅根据request创建AggregatorFactory,用于后续创建Aggregator。
相关代码:
SearchService.createAndPutContext
2.2:根据SearchContext构造Aggregator。
根据SearchContext构造具体的Aggregator,如:
GlobalOrdinalsStringTermsAggregator:用于keyword字段,开启global ordinal的term聚合。
StringTermsAggregator:用于keyword字段,关闭global ordinal的term聚合。
LongTermsAggregator:用于long字段的term聚合。
TopScoreDocCollector:用于为doc 评分并取topN。
相关代码:
AggregationPhase.preProcess
2.3:创建GlobalOrdinalsStringTermsAggregator,如果cache中没有GlobalOrdinals,将创建GlobalOrdinals,并cache。当shard下数据发生变化时,应当清空cache。
GlobalOrdinals
将所有segment ,指定field的所有term排序,合并成一个GlobalOrdinals,并创建OrdinalMap。collect时,使用doc的segment ord获取global ord。
OrdinalMap
为每一个segmentValueCount小于globalValueCount的segment,保存了一份segment ord到global ord的mapping(LongValues)。对于segment valueCount等于globalValueCount的segment,原本的segment ord就是global ord,后续获取ord时,直接从SortedSetDV(dvd)中读取。
value count
指的是不同term数量(term集合的大小)。使用globalValueCount 用来在collect时,确定结果集的大小。
举例
segment 1:{sorted terms: [aa, bb, cc],ord:[0, 1, 2]}。
segment 2:{sorted terms: [bb, cc, dd],ord:[0, 1, 2]}。
segment 3:{sorted terms: [aa, bb, cc, dd],ord:[0, 1, 2, 3]}。
GlobalOrdinals:{sorted terms: [aa, bb, cc, dd],ord:[0, 1, 2, 3]}。
ordinalMap:segment1:[0, 1, 2]->[0, 1, 2],segment2:[0, 1, 2]->[1, 2, 3]。segment3则使用原始的segment ord。
docCounts
int[globalValueCount],用来记录ord对应的count。
注:经查询条件过滤后,有些ord可能没有对应doc。
bucketOrds
稀疏(value count多,但doc少)时使用,缩减docCounts size。
LongHash:globalOrd与 id (size)映射。collect时在id处++,build agg时取出id对应的count。
当父聚合是BucketAggregator聚合时,子聚合只对父的某个term聚合,所以doc会减少,使用bucketOrds。
注:按照此逻辑,如果query本身有term过滤条件,也应该启用bucketOrds(global_ordinals_hash)。
相关代码:
TermsAggregatorFactory.doCreateInternal。 //获取globalValueCount决定是否global_ordinals_low_cardinality, global_ordinals_low_cardinality中又因不是ValuesSource.Bytes.FieldData,创建global_ordinals。 ValuesSource$WithOrdinals.globalMaxOrd。 //通过获取一个segment的globalOrdinals,触发如果cache中没有一个shardId+field对应的globalOrdinals,load 所有segment ord,建立global ords。 ValuesSource$FieldData.globalOrdinalsValues。 SortedSetDVOrdinalsIndexFieldData.loadGlobal。 IndicesFieldDataCache$IndexFieldCache.load SortedSetDVOrdinalsIndexFieldData.localGlobalDirect。 GlobalOrdinalsBuilder.build。 //globalOrdinals主要类 GlobalOrdinalsIndexFieldData。 MultiDocValues$OrdinalMap
2.3.1:从docValues中读取单个segment,指定field的ordinals,term等。
相关代码:
SortedSetDVOrdinalsIndexFieldData.load。 SortedSetDVBytesAtomicFieldData.getOrdinalsValues。 //获取segment指定field的SortedSetDocValues DocValues.getSortedSet。 //获取segment的docValuesReader SegmentReader.getDocValuesReader。 //读取field的SortedDocValues Lucene54DocValuesProducer.getSortedSet。
2.3.2:对多个segment的SortedSetDocValues排序,创建OrdinalMap。
具体为获取每个segment的SortedDocValuesTermsEnum。使用多个SortedDocValuesTermsEnum构建成小顶堆,合并成一个。
相关代码:
MultiDocValues$OrdinalMap.build。 MultiTermsEnum TermMergeQueue //获取一个segment的segment ord到global ord的mapping。 MultiDocValues$OrdinalMap.getGlobalOrds
2.4:查询及聚合数据。
相关代码:
QueryPhase.execute。
2.4.1:根据Query创建具体的weight。
weigth将用于query segment,并创建scorer。
scorer将用于评分和collect。
如果需要评分,读取field的fst,查询term,定位postings将提前到这里执行。
相关代码:
IndexSearcher.createNormalizedWeight。
TermQuery.createWeight。
2.4.2:为每个leafReader(segment)创建leafCollector。
创建LeafBucketCollector,获取该segment的globalOrds。
globalOrds
如果segment的value count等于global value count,则返回segment ords(从dvd中读取);
如果不等,则从OrdinalMap中获取该segment的GlobalOrdinalMapping,且该segment的value count改为获取global value count。
singleValues
并判断该field的docValues是否为singleValues(keyword single ord,text则为多term多ord)。
相关代码:
//串行查询及聚合一个分片下的所有segment。 IndexSearcher.search。 IndexSearcher.search.collector.getLeafCollector。 GlobalOrdinalsStringTermsAggregator.getLeafCollector。 //获取指定segment的globalOrdinals,如果cache中没有该shardId+field对应的globalOrdinals,load 所有segment ord,建立global ords。 ValuesSource$FieldData.globalOrdinalsValues //获取一个segment的global ords。 GlobalOrdinalsIndexFieldData$Atomic.getOrdinalsValues //提供获取该segment ord对应的global ord,使用globalOrd获取termBytes等方法。 GlobalOrdinalMapping //singleValues SingletonSortedSetDocValues
2.4.3:query该segment, 获取DocIdSetIterator,并构造scorer。
DocIdSetIterator即查询出的docId集合,对于倒排是PostingsEnum,对于数字使用的是BitSetIterator。
相关代码:
IndexSearcher.search.weight.bulkScorer。 Weight.bulkScorer。 //构造bulkScorer。 TermQuery$TermWeight.scorer。 //查询segment,获取TermsEnum,并根据搜索关键字,定位PostingsEnum位置。 TermQuery$TermWeight.getTermsEnum。
query segment流程如下:
1:根据field读取.tip(fst索引结构,term index)文件,获取该field下所有term前缀构造的索引,并缓存。
FST(Finite State Transducer,有限状态传感器)其他用途:阿里对hbase rowkey索引定位block(类似lucene tip索引term),
自然语言处理中一个单词或汉字下一个状态各个状态的概率。
相关代码: BlockTreeTermsReader.terms。 FieldReader。 //Load a previously saved FST FST。
注:官方lucene在open IndexReader(es recovery shard)时,就要通过构造SegmentReader,BlockTreeTermsReader,构造FieldReader,读取FST。
相关代码:
DirectoryReader.open
2:从fst中查找term,如果能找到的value(fst正常结束),value记录了
该term前缀对应的term dict所在的block(.tim,term dictionary)位置,读取该block,查找具体的term,获取posting所在.doc(postings)的位置。
相关代码:
TermQuery$TermWeight.getTermsEnum.termsEnum.seekExact。 SegmentTermsEnum.seekExact。 SegmentTermsEnumFrame.scanToTerm。 //根据termsEnum(已经设置term)读取postings。 TermQuery$TermWeight.scorer.termsEnum.postings。 SegmentTermsEnum.postings。 //根据termsEnum中的term,设置postings在.doc中位置。 SegmentTermsEnum.postings.currentFrame.decodeMetaData。
3:从.doc中读取postings,返回PostingsEnum(BlockDocsEnum)。
相关代码:
Lucene50PostingsReader.postings。
上述流程如下图:
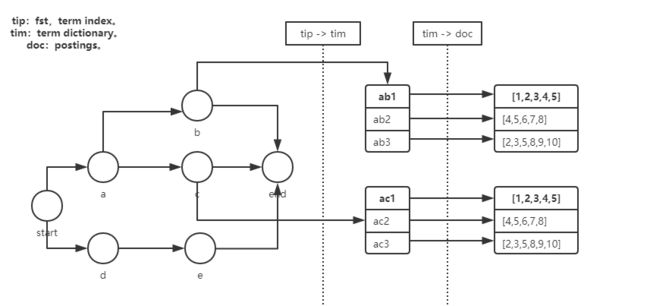
postings
(docID, termFreq, positions), (docID, termFreq, positions),.....
termFreq
term在该文档出现的次数。
用于对文档频分。
positions
term在该文档中每次的位置。
用于短语查询时,多个term是否连续出现,或者小于指定位置。
2.4.4:遍历PostingsEnum(过滤deleted doc),评分及collect数据。
相关代码:
acceptDocs:getLiveDocs IndexSearcher.search.scorer.score。 BulkScorer.score。 DefaultBulkScorer.score。 //在查询结果中前进到>=target的docID,并返回docID。 Lucene50PostingsReader$BlockDocsEnum.advance(target)。 //遍历BlockDocsEnum(PostingsEnum)中的查询结果,collect doc。 DefaultBulkScorer.scoreRange。 //collect一个doc。 MultiCollector$MultiLeafCollector.collect。
TopScoreDocCollector对doc评分,并取topN的流程如下:
为该doc评分,并基于score构建N节点的小顶堆,用于保留TopN。
相关代码:
TopScoreDocCollector$SimpleTopScoreDocCollector.collect。
1:根据设置的Similarity,使用BM25或TFIDF等算法为doc评分。
BM25,TFIDF都使用freq,norms(NumericDocValues),算法不同,可能使用的NumericDocValues也不同。
相关代码:
TermScorer.score。
BM25Similarity$BM25DocScorer.score。
TFIDFSimilarity$TFIDFSimScorer.score。
IndexWriterConfig.setSimilarity。
IndexSearcher.setSimilarity。
NumericDocValues。
2:根据doc得到的score构建N节点的小顶堆。
相关代码:
TopScoreDocCollector$SimpleTopScoreDocCollector.collect。
PriorityQueue.updateTop/downHeap/insertWithOverflow。
GlobalOrdinalsStringTermsAggregator统计各term doc数的流程如下:
1:根据doc是否为singleValues,获取doc的ord或ords。
相关代码:
//singleValues获取ord singleValues.getOrd(doc)。 //获取ords //设置doc。 GlobalOrdinalsStringTermsAggregator$LeafBucketCollector.collect.globalOrds.setDocument(doc) AbstractRandomAccessOrds.setDocument(doc)。 //获取doc对应的term基数。 GlobalOrdinalsStringTermsAggregator$LeafBucketCollector.collect.globalOrds.cardinality()。 GlobalOrdinalMapping.cardinality()。 //遍历doc ords。 GlobalOrdinalsStringTermsAggregator$LeafBucketCollector.collect.globalOrds.ordAt(i)。 GlobalOrdinalMapping.ordAt(i)。
2:docCounts(IntArray)对应的ord count++。
如果启用bucketOrds(稀疏处理,见2.3),则将ord映射到bucketOrd,docCounts的bucketOrd位置 count++。
相关代码:
//将ord对应count++。传入doc,用于sub collect。 GlobalOrdinalsStringTermsAggregator.collectGlobalOrd。
2.4.5:取topDocs。TopScoreDocCollector collect时仅保留topN。在此每次取堆顶元素,得到逆序的topN。
相关代码:
TopDocsCollector.topDocs。
2.4.6:根据聚合数据,按docCount取topN,排序。
根据aggregator的数据,按docCount构建小顶堆。
每次取走堆顶元素,逆序放入数组,得到降序的topN。
设置termBytes。
相关代码:
AggregationPhase.execute。 GlobalOrdinalsStringTermsAggregator.buildAggregation。 PriorityQueue.updateTop/downHeap/insertWithOverflow。 //根据globalOrd从所有segment中获取第一个含有该globalOrd的segment,并从该segment中读取term值BytesRef。 GlobalOrdinalMapping.lookupOrd。
3:协调节点reduce 各个shard返回的结果。
使用各shard返回的有序结果,构造堆,合并聚合,合并TopDocs。
相关代码:
InitialSearchPhase.onShardResult。 InitialSearchPhase.onShardFailure。 //reduce结果 FetchSearchPhase.innerRun.resultConsumer.reduce。 SearchPhaseController.reducedQueryPhase。 SearchPhaseController.sortDocs。 //mergeTopDocs SearchPhaseController.mergeTopDocs。 TopDocs.merge。 TopDocs.mergeAux。 PriorityQueue。
4:fetch数据。
协调发送fecth请求到相关shard,数据节点从stored field中fetch结果。
相关代码:
FetchSearchPhase.innerRun。
参考:
source code: elasticsearch 5.6.12, lucene 6.6.1。
https://www.elastic.co/blog/lucene-points-6.0
PointRangeQuery:abstract class竟然可以有构造方法。