本文记录了语义分割准确性评价指标的总结以及代码实现
对于像素级别的分类,最常用的评价指标是Pixel Accuracy(像素准确率)和Mean Inetersection over Union(平均交并比),二者的计算都是建立在混淆矩阵的基础上的。因此首先来介绍一下混淆矩阵,之后分别介绍PA,MPA,MIoU,FWIoU,最后附上代码实现。
首先假定数据集中有n+1类(0~n),0通常表示背景。使用Pii表示原本为i类同时预测为i类,即真正(TP)和真负(TN), Pij表示原本为i类被预测为j类,即假正(FP)和假负(FN),如果第i类为正类,i!=j时,那么Pii表示TP,Pjj表示TN,Pij表示FP,Pji表示FN。
像素准确率(PA)
像素准确率是所有分类正确的像素数占像素总数的比例。公式化如下:
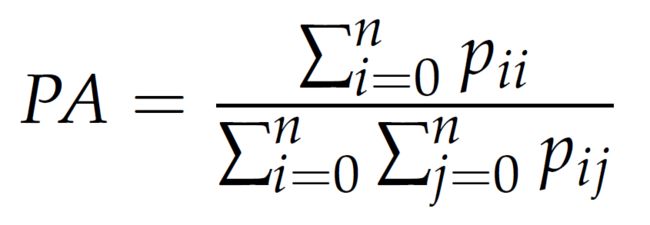
利用混淆矩阵计算则为(对角线元素之和除以矩阵所有元素之和)
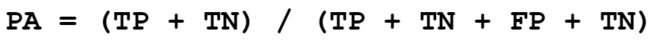
平均像素准确率(MPA)
平均像素准确率是分别计算每个类别分类正确的像素数占所有预测为该类别像素数的比例,即精确率,然后累加求平均。公式化如下:
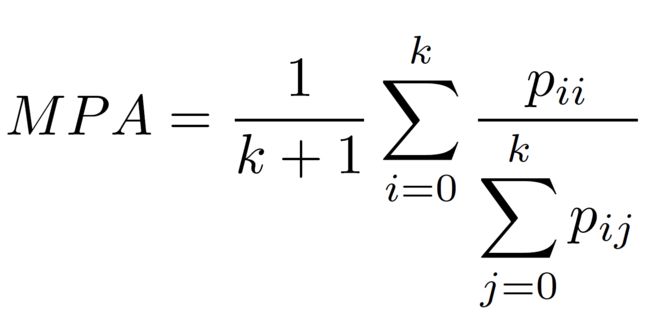
利用混淆矩阵计算公式为(每一类的精确率Pi都等于对角线上的TP除以对应列的像素数)
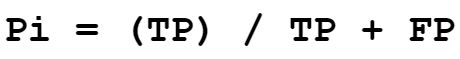
平均交并比(mloU)
平均交并比是对每一类预测的结果和真实值的交集与并集的比值求和平均的结果。公式化如下
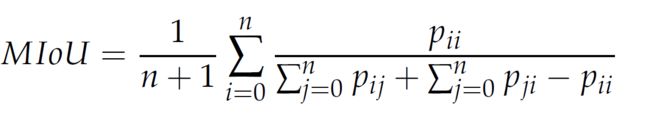
IoU利用混淆矩阵计算:

解释如下:
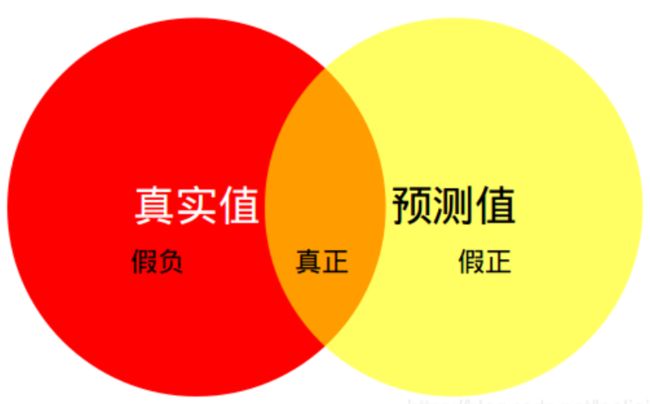
如图所示,仅仅针对某一类来说,红色部分代表真实值,真实值有两部分组成TP,FN;黄色部分代表预测值,预测值有两部分组成TP,FP;白色部分代表TN(真负);
所以他们的交集就是TP+FP+FN,并集为TP
频权交并比(FWloU)
频权交并比是根据每一类出现的频率设置权重,权重乘以每一类的IoU并进行求和。公式化如下:
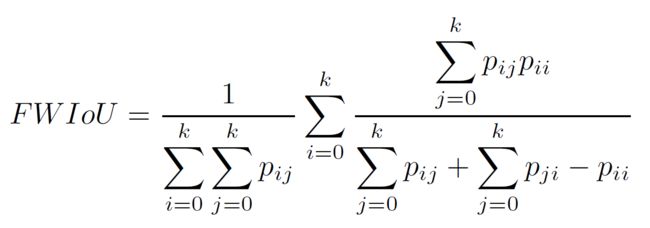
利用混淆矩阵计算:每个类别的真实数目为TP+FN,总数为TP+FP+TN+FN,其中每一类的权重和其IoU的乘积计算公式如下,在将所有类别的求和即可
![]()
代码实现
"""
refer to https://github.com/jfzhang95/pytorch-deeplab-xception/blob/master/utils/metrics.py
"""
import numpy as np
__all__ = ['SegmentationMetric']
"""
confusionMetric
P\L P N
P TP FP
N FN TN
"""
class SegmentationMetric(object):
def __init__(self, numClass):
self.numClass = numClass
self.confusionMatrix = np.zeros((self.numClass,)*2)
def pixelAccuracy(self):
# return all class overall pixel accuracy
# acc = (TP + TN) / (TP + TN + FP + TN)
acc = np.diag(self.confusionMatrix).sum() / self.confusionMatrix.sum()
return acc
def classPixelAccuracy(self):
# return each category pixel accuracy(A more accurate way to call it precision)
# acc = (TP) / TP + FP
classAcc = np.diag(self.confusionMatrix) / self.confusionMatrix.sum(axis=1)
return classAcc
def meanPixelAccuracy(self):
classAcc = self.classPixelAccuracy()
meanAcc = np.nanmean(classAcc)
return meanAcc
def meanIntersectionOverUnion(self):
# Intersection = TP Union = TP + FP + FN
# IoU = TP / (TP + FP + FN)
intersection = np.diag(self.confusionMatrix)
union = np.sum(self.confusionMatrix, axis=1) + np.sum(self.confusionMatrix, axis=0) - np.diag(self.confusionMatrix)
IoU = intersection / union
mIoU = np.nanmean(IoU)
return mIoU
def genConfusionMatrix(self, imgPredict, imgLabel):
# remove classes from unlabeled pixels in gt image and predict
mask = (imgLabel >= 0) & (imgLabel < self.numClass)
label = self.numClass * imgLabel[mask] + imgPredict[mask]
count = np.bincount(label, minlength=self.numClass**2)
confusionMatrix = count.reshape(self.numClass, self.numClass)
return confusionMatrix
def Frequency_Weighted_Intersection_over_Union(self):
# FWIOU = [(TP+FN)/(TP+FP+TN+FN)] *[TP / (TP + FP + FN)]
freq = np.sum(self.confusion_matrix, axis=1) / np.sum(self.confusion_matrix)
iu = np.diag(self.confusion_matrix) / (
np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -
np.diag(self.confusion_matrix))
FWIoU = (freq[freq > 0] * iu[freq > 0]).sum()
return FWIoU
def addBatch(self, imgPredict, imgLabel):
assert imgPredict.shape == imgLabel.shape
self.confusionMatrix += self.genConfusionMatrix(imgPredict, imgLabel)
def reset(self):
self.confusionMatrix = np.zeros((self.numClass, self.numClass))
if __name__ == '__main__':
imgPredict = np.array([0, 0, 1, 1, 2, 2])
imgLabel = np.array([0, 0, 1, 1, 2, 2])
metric = SegmentationMetric(3)
metric.addBatch(imgPredict, imgLabel)
acc = metric.pixelAccuracy()
mIoU = metric.meanIntersectionOverUnion()
print(acc, mIoU)