处理流之一:缓冲流
1.为了提高数据读写的速度,Java API提供了带缓冲功能的流类,在使用这些流类时,
会创建一个内部缓冲区数组,缺省使用8192个字节(8Kb)的缓冲区。

2.缓冲流要“套接”在相应的节点流之上,根据数据操作单位可以把缓冲流分为:
➢BufferedInputStream 和 BufferedOutputStream
➢BufferedReader 和 BufferedWriter
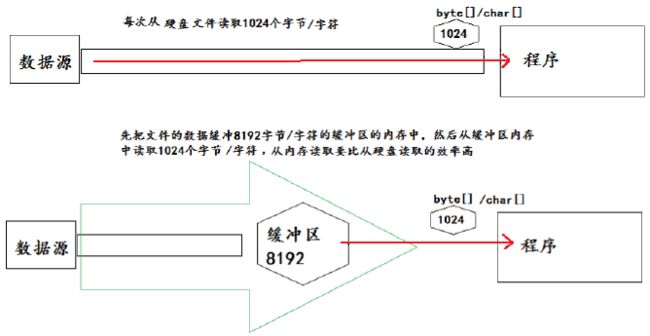
1.当读取数据时,数据按块读入缓冲区,其后的读操作则直接访问缓冲区。
2.当使用BufferedInputStream读取字节文件时,BufferedInputStream会一次性从文件中读取8192个(8Kb),
存在缓冲区中,直到缓冲区装满了,才重新从文件中读取下一个8192个字节数组。
3.向流中写入字节时,不会直接写到文件,先写到缓冲区中直到缓冲区写满,
BufferedOutputStream才会把缓冲区中的数据一次性写到文件里。
4.使用方法lush()可以强制将缓冲区的内容全部写入输出流。
关闭流的顺序和打开流的顺序相反。只要关闭最外层流即可,关闭最外层流也会相应关闭内层节点流。
5.flush()方法的使用:手动将buffer中内容写入文件。
6.如果是带缓冲区的流对象的close()方法,不但会关闭流,还会在关闭流之前刷新缓冲区,关闭后不能再写出。
处理流之二:转换流
1.转换流提供了在字节流和字符流之间的转换。
2.Java API提供了两个转换流:
➢InputStreamReader:将InputStream转 换为Reader。
➢OutputStreamWriter:将Writer转 换为OutputStream。
3.字节流中的数据都是字符时,转成字符流操作更高效。
4.很多时候我们使用转换流来处理文件乱码问题。实现编码和解码的功能。
InputStreamReader概述:
●实现将字节的输入流按指定字符集转换为字符的输入流。
●需要和InputStream “套接”。
●构造器:
➢public InputStreamReader(InputStream in)
➢public InputSreamReader(InputStream in,String charsetName)
如:Reader isr = new InputStreamReader(System.in, 'gbk" );gbk为指定字符集。
OutputStreamWriter概述:
●实现将字符的输出流按指定字符集转换为字节的输出流。
●需要和OutputStream“套接”。
●构造器:
➢public OutputStreamWriter(OutputStream out)
➢public OutputSreamWriter(OutputStream out, String charsetName)
处理流之三:标准输入、输出流
1.System.in和System.out分别代表了系统标准的输入和输出设备。
2.默认输入设备是:键盘,输出设备是:显示器。
3.System.in的类型是InputStream。
4.System.out的类型是PrintStream,其是OutputStream的子类
FilterOutputStream的子类。
5.重定向:通过System类的setIn,setOut方法对默认 设备进行改变。
➢public static void setln(InputStream in)
➢public static void setOut(PrintStream out)
1 public static void main(String[] args) { 2 BufferedReader br = null; 3 try { 4 InputStreamReader isr = new InputStreamReader(System.in); 5 br = new BufferedReader(isr); 6 7 while (true) { 8 System.out.println("请输入字符串:"); 9 String data = br.readLine(); 10 if ("e".equalsIgnoreCase(data) || "exit".equalsIgnoreCase(data)) { 11 System.out.println("程序结束"); 12 break; 13 } 14 15 String upperCase = data.toUpperCase(); 16 System.out.println(upperCase); 17 18 } 19 } catch (IOException e) { 20 e.printStackTrace(); 21 } finally { 22 if (br != null) { 23 try { 24 br.close(); 25 } catch (IOException e) { 26 e.printStackTrace(); 27 } 28 29 } 30 } 31 }
处理流之四:打印流
●实现将基本数据类型的数据格式转化为字符串输出。
●打印流: PrintStream和PrintWriter。
➢提供了一系列重载的print()和printn()方法,用于多种数据类型的输出。
➢PrintStream和PrintWriter的输 出不会抛出IOException异常。
➢PrintStream和PrintWriter有 自动flush功能。
➢PrintStream打印的所有字符都使用平台的默认字符编码转换为字节。
在需要写入字符而不是写入字节的情况下,应该使用PrintWriter类。
➢System.out返 回的是PrintStream的实例。
1 public void test() { 2 PrintStream ps = null; 3 try { 4 FileOutputStream fos = new FileOutputStream(new File("D:\\IO\\text.txt")); 5 // 创建打印输出流,设置为自动刷新模式(写入换行符或字节 '\n' 时都会刷新输出缓冲区) 6 ps = new PrintStream(fos, true); 7 if (ps != null) {// 把标准输出流(控制台输出)改成文件 8 System.setOut(ps); 9 } 10 11 12 for (int i = 0; i <= 255; i++) { // 输出ASCII字符 13 System.out.print((char) i); 14 if (i % 50 == 0) { // 每50个数据一行 15 System.out.println(); // 换行 16 } 17 } 18 19 20 } catch (FileNotFoundException e) { 21 e.printStackTrace(); 22 } finally { 23 if (ps != null) { 24 ps.close(); 25 } 26 } 27 28 }
处理流之五:数据流

处理流之六:对象流



使用对象流序列化对象:

java.io.Serializable接口:
●实现了Serializable接口的对象,可将它们转换成一系列字节,
并可在以后完全恢复回原来的样子。这一过程亦可通过网络进行。
这意味着序列化机制能自动补偿操作系统间的差异。
●可以先在Windows机器上创建一个对象,对其序列化,然后通过网络发给一 台Unix机器,
然后在那里准确无误地重新“装配”。不必关心数据在不同机器上如何表示,
也不必关心字节的顺序或者其他任何细节。
●由于大部分作为参数的类如String、 Integer等都实现 了java.io.Serializable的接口,
也可以利用多态的性质,作为参数使接口更灵活。