我们这节课讲一下RDD的持久化

这段代码我们上午已经看过了,有瑕疵大家看出来了吗?
有什么瑕疵啊?
大家是否还记得我在第二节课的时候跟大家说,RDD实际是不存数据的?

我们再重新讲解一下这段代码
sc.textfile是不是讲数据加载到这个RDD里面去了?
对这个RDD执行一个filter算子过滤,返回一个errors RDD
然后对errorsRDD又经过一次过滤,然后再执行一次count算子,我们把这个job叫做job0
然后第四行,又对这个errors执行了一次filter,然后又count一次,我们把这个job叫做job1
那么在job1里面errors这个RDD,那我们说了RDD里面不存数据,那errors这个RDD里面的数据是通过lines这个RDD计算得来的,那rdd不存数据,那他是不是要重新计算啊?
我再重新说一遍,errors这个RDD由于他不存数据,所以job1这个RDD里面的errors和job0里面的这个RDD,都是通过依赖的RDD计算过来的,他是怎么计算过来的,他是从lines这个RDD计算过来的
那lines这个RDD数据哪来的?他是通过textfile加载过来的
他其实是计算了几遍?计算了两遍对吗?
那我们对他进行优化,怎么优化?优化的时候就让他读一遍就可以了呗?
我们重复是用errors重复使用两次,那如果我们把errors里面的数据持久化一下,把他保存到内存当中去,或者保存到磁盘当中去是不是就可以了?
我job1在使用errors的时候直接从磁盘或者内存当中去读就可以了对吧?
那如果我们想给RDD做持久化,我们就要使用持久化的算子,cache、persist、checkpoint,这些算子都可以将RDD的数据进行持久化
那么这三个算子有什么区别呢?
cache他是persist的一个简化版cache他默认是将RDD的数据持久化到内存里面去
persist这个算子我们可以自己指定持久化的级别,可以自定义,我们可以将RDD的数据持久化到磁盘上,如果你想要把数据持久化到磁盘上 ,必须要使用persist算子
因为cache是默认将数据放到内存
我们现在来写代码测试一下
我们看一下性能有没有提升,我们刚才说使用cache这个算子对刚才这个代码进行优化,看性能有没有提升,
package com.bjsxt.spark.persist
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Albert on 2017/7/15.
*
*
* cache persist注意事项
*
*/
object T01Persist {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("T01Cache")
val sc = new SparkContext(conf)
var rdd = sc.textFile("log.txt")
rdd.cache()
//rdd.persist(StorageLevel.MEMORY_ONLY)
// chche() = persist() = persist(StorageLevel.MEMORY_ONLY)
val st = System.currentTimeMillis()
val count = rdd.count()
val et = System.currentTimeMillis()
println(s"count: $count \t Duration:${et-st}")
val st1 = System.currentTimeMillis()
val count1 = rdd.count()
val et1 = System.currentTimeMillis()
println(s"count: $count1 \t Duration:${et1-st1}")
}
}
这段代码大家都可以理解吧?理解的举手,要给我反馈真实的情况啊,如果不懂的人多了,我再通过其他案例给大家讲
这里给大家总结一下持久化算子的注意事项
cache和persist使用注意事项
1、cache和persist算子都是懒执行的,必须有一个Action算子触发执行
2、cache和persist算子的返回值必须赋值给一个变量,在下一个job中直接使用这个变量就是使用了持久化的数据
提问如果一个Application里面只有一个job有必要使用持久化算子吗?
答案是没有必要对吧?
3、cache和persist算子后面不能紧跟Aciton类算子(不能直接rdd.cache().count())
为什么不能直接点出来Action类算子呢?
我们还记不记得Action类算子,都有什么类型的了呢?我们在讲算子的时候说所有Action类算子,他有三种返回类型:无类型:foreach、HDFS、Scala数据类型
那我们rdd = rdd.cache返回的类型是RDD[]
incorrect: rdd = rdd.cache().count()
correct: val cacheRDD = rdd.cache
rdd.count()
好下面我们来看一下persist各种StorageLevel的级别,我们看一下Spark的源码
如果我们要看源码,我们要先找到这个方法
那cache这个方法在哪里呢?我们是在rdd. cache的这个方法吧?
所以我们去RDD这个类里面找一下
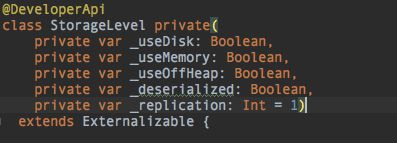
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1)
StorageLevel五个参数的意义
| 参数名称 | 参数意义 |
|---|---|
| _useDisk | 是否使用磁盘 |
| _useMemory | 是否使用内存 |
| _useOffHeap | 是否使用堆外内存 |
| _deserialized | 是否不序列化,注意这里false代表序列化 |
| _replication | 副本数量默认是1 |
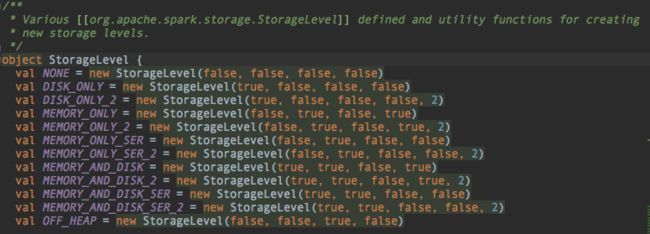
我们看看MEMORY_ONLY 他的参数分别是
new StorageLevel(false, true, false, true)
是否使用磁盘,不使用
是否使用内存,使用
是否使用堆外内存,不使用
是否不序列化,是(意思就是不序列化)
没有参数副本数,所以副本数是1
其他的自己看一下记一下,老师在这着重讲解一下
MEMORY_AND_DISK
MEMORY_AND_DISK他是内存中一份磁盘中一份吗?不是的
大家一定要记住,这个持久化级别,一共就只有一份
这个持久化的级别,会先往内存里面持久化RDD,如果内存不够了,就往硬盘里面持久化
大家记住了吗?
OFF_HEAP
OFF_HEAP 这个持久化级别的意思?
堆外内存?什么是堆外内存,堆以外的内存就是堆外内存对吗?
JVM管理了一块内存对吗?那不受JVM 的GC管理的内存是不是就是堆外内存啊?
- 参考阅读:
什么是堆外内存?堆内内存还是堆外内存?
顺带普及一下内存的知识:
Stack and Heap 堆和栈的区别
我们在第一节课讲了一个
Tachyon现在改名叫Alluxio他是基于内存的一个文件系统,也是Berkeley技术架构下的一个系统,Tachyon可以和Spark进行整合,整合好了以后,如果想用堆外内存来持久化,就需要设置这种类型,明白吗?如果你没有整合Tachyon,在程序里面还使用了这个级别,程序会给你报错。
现在Tachyon用的公司还很少,国内阿里、百度、华为才有一定规模的内存分布式文件系统的集群
另外序列化的数据在持久化的时候会小一些,但带来的就像加解密一样,会影响性能。
有同学会问到,我一直持久化,内存越来越多,我怎么办?
其实还有一个unpersist这个算子,会把rdd的持久化级别设置为StorageLevel.NONE
但一般情况下不需要使用
因为持久化会有一个TTL机制,就是最近不常用的数据,他会自动清除
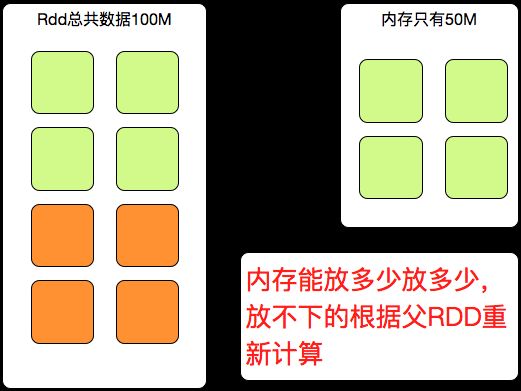
还有另外一个问题,也是同学们经常会问到的,当我内存不够的时候,我还是cache了一个RDD,会不会报OOM?
那我告诉大家一个结论,就是不会,RDD的持久化,有多少内存,他就放多少数据,放不下的数据就不会进行存储
然后我们讲一下checkpoint
checkpoint不仅仅能够持久化数据,还能够将RDD的依赖关系切断
持久化数据
那我们说我们选用persist进行RDD的持久化,我们可以指定持久化的级别,还可以设置数据的副本数,他的数据要么放到内存,要么放到磁盘上,并且还能有备份
那大家考虑一下,我们是用persist给我们持久化到内存硬盘安全,还是使用checkpoint让Spark给我们把数据持久化到hdfs上安全?
持久化到hdfs上更安全一些对吗?
那为什么持久化到HDFS上安全呢?
因为这就是双保险了,所以会更安全对吧?
切断RDD的依赖关系
我们说checkpoint可以切断RDD的依赖关系,当我们业务非常复杂的时候,需要频繁的对RDD转换,频繁的转换,会导致,RDD的依赖lineage特别的长,如果中间某一个RDD的数据坏了,错了,是不是要重新计算啊?
如果我们把RDD的依赖关系给切断,那重新计算就会快了是吧?
我们画图来解释一下这个事情
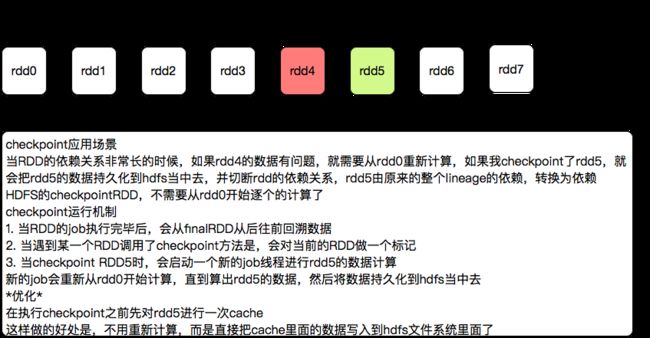
checkpoint应用场景
当RDD的依赖关系非常长的时候,如果rdd4的数据有问题,就需要从rdd0重新计算,如果我checkpoint了rdd5,就会把rdd5的数据持久化到hdfs当中去,并切断rdd的依赖关系,rdd5由原来的整个lineage的依赖,转换为依赖HDFS的checkpointRDD,不需要从rdd0开始逐个的计算了
checkpoint运行机制
- 当RDD的job执行完毕后,会从finalRDD从后往前回溯数据
- 当遇到某一个RDD调用了checkpoint方法是,会对当前的RDD做一个标记
- 当checkpoint RDD5时,会启动一个新的job线程进行rdd5的数据计算
新的job会重新从rdd0开始计算,直到算出rdd5的数据,然后将数据持久化到hdfs当中去
优化
在执行checkpoint之前先对rdd5进行一次cache
这样做的好处是,不用重新计算,而是直接把cache里面的数据写入到hdfs文件系统里面了
下面我通过代码的方式,给大家演示如何使用checkpoint
package com.bjsxt.spark.persist
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Albert on 2017/7/15.
*/
object T03Checkpoint {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("T01Cache")
val sc = new SparkContext(conf)
sc.setCheckpointDir("/Users/AlbertC/checkpointtest")
val rdd = sc.makeRDD(1 to 10)
rdd.checkpoint()
rdd.count()
sc.stop()
}
}
setChectpointDir是设置一个存储路径,这里我用的是我本地电脑的一个路径也可以放到hdfs上面