第10章 使用Keras搭建人工神经网络
第11章 训练深度神经网络
第12章 使用TensorFlow自定义模型并训练
第13章 使用TensorFlow加载和预处理数据
第14章 使用卷积神经网络实现深度计算机视觉
第15章 使用RNN和CNN处理序列
第16章 使用RNN和注意力机制进行自然语言处理
第17章 使用自编码器和GAN做表征学习和生成式学习
第18章 强化学习
第19章 规模化训练和部署TensorFlow模型
当阿兰·图灵在1950年设计图灵机时,他的目标是用人的智商来衡量机器。他本可以用其它方法来测试,比如看图识猫、下棋、作曲或逃离迷宫,但图灵选择了一个语言任务。更具体的,他设计了一个聊天机器人,试图迷惑对话者将其当做真人。这个测试有明显的缺陷:一套硬编码的规则可以愚弄粗心人(比如,机器可以针对一些关键词,做出预先定义的模糊响应;机器人可以假装开玩笑或喝醉;或者可以通过反问侥幸过关),忽略了人类的多方面的智力(比如非语言交流,比如面部表情,或是学习动手任务)。但图灵测试强调了一个事实,语言能力是智人最重要的认知能力。我们能创建一台可以读写自然语言的机器吗?
自然语言处理的常用方法是循环神经网络。所以接下来会从 character RNN 开始(预测句子中出现的下一个角色),继续介绍RNN,这可以让我们生成一些原生文本,在过程中,我们会学习如何在长序列上创建TensorFlow Dataset。先使用的是无状态RNN(每次迭代中学习文本中的随机部分),然后创建一个有状态RNN(保留训练迭代之间的隐藏态,可以从断点继续,用这种方法学习长规律)。然后,我们会搭建一个RNN,来做情感分析(例如,读取影评,提取评价者对电影的感情),这次是将句子当做词的序列来处理。然后会介绍用RNN如何搭建编码器-解码器架构,来做神经网络机器翻译(NMT)。我们会使用TensorFlow Addons项目中的 seq2seq API 。
本章的第二部分,会介绍注意力机制。正如其名字,这是一种可以选择输入指定部分,模型在每个时间步都得聚焦的神经网络组件。首先,会介绍如何使用注意力机制提升基于RNN的编码器-解码器架构的性能,然后会完全摒弃RNN,介绍只使用注意力的架构,被称为Transformer(转换器)。最后,会介绍2018、2019两年NLP领域的进展,包括强大的语言模型,比如GPT-2和Bert,两者都是基于Transformer的。
先从一个简单有趣的模型开始,它能写出莎士比亚风格的文字。
使用Character RNN生成莎士比亚风格的文本
在2015年一篇著名的、名为《The Unreasonable Effectiveness of Recurrent Neural Networks》博客中,Andrej Karpathy展示了如何训练RNN,来预测句子中的下一个角色。这个 Char-RNN 可以用来生成小说,每次一名角色。下面是一段简短的、由Char-RNN模型(在莎士比亚全部著作上训练而成)生成的文本:
PANDARUS:
Alas, I think he shall be come approached and the day
When little srain would be attain’d into being never fed,
And who is but a chain and subjects of his death,
I should not sleep.
虽然文笔一般,但只是通过学习来预测一句话中的下一个角色,模型在单词、语法、断句等等方面做的很好。接下来一步一步搭建Char-RNN,从创建数据集开始。
创建训练数据集
首先,使用Keras的get_file()函数,从 Andrej Karpathy 的 Char-RNN 项目,下载所有莎士比亚的作品:
shakespeare_url = "https://homl.info/shakespeare" # shortcut URL
filepath = keras.utils.get_file("shakespeare.txt", shakespeare_url)
with open(filepath) as f:
shakespeare_text = f.read()
然后,将每个角色编码为一个整数。方法之一是创建一个自定义预处理层,就像之前在第13章做的那样。但在这里,使用Keras的Tokenizer会更加简单。首先,将一个将tokenizer拟合到文本:tokenizer能从文本中发现所有的角色,并将所有角色映射到不同的角色ID,映射从1开始(注意不是从0开始,0是用来做遮挡的,后面会看到):
tokenizer = keras.preprocessing.text.Tokenizer(char_level=True)
tokenizer.fit_on_texts([shakespeare_text])
设置char_level=True,以得到角色级别的编码,而不是默认的单词级别的编码。这个tokenizer默认将所有文本转换成了小写(如果不想这样,可以设置lower=False)。现在tokenizer可以将一整句(或句子列表)编码为角色ID列表,这可以告诉我们文本中有多少个独立的角色,以及总角色数:
>>> tokenizer.texts_to_sequences(["First"])
[[20, 6, 9, 8, 3]]
>>> tokenizer.sequences_to_texts([[20, 6, 9, 8, 3]])
['f i r s t']
>>> max_id = len(tokenizer.word_index) # number of distinct characters
>>> dataset_size = tokenizer.document_count # total number of characters
现在对完整文本做编码,将每个角色都用ID来表示(减1使ID从0到38,而不是1到39):
[encoded] = np.array(tokenizer.texts_to_sequences([shakespeare_text])) - 1
继续之前,需要将数据集分成训练集、验证集和测试集。不能大论角色,该怎么处理这种序列式的数据集呢?
如何切分序列数据集
避免训练集、验证集、测试集发生重合非常重要。例如,可以取90%的文本作为训练集,5%作为验证集,5%作为测试集。在这三个数据之间留出空隙,以避免段落重叠也是非常好的主意。
当处理时间序列时,通常按照时间切分:例如,可以将从2000到2012的数据作为训练集,2013年到2015年作为验证集,2016年到2018年作为测试集。但是,在另一些任务中,可以按照其它维度来切分,可以得到更长的时间周期进行训练。例如,10000家公司从2000年到2018年的金融健康数据,可以按照不同公司来切分。但是,很可能其中一些公司是高度关联的(比如,经济领域的公司涨落相同),如果训练集和测试集中有关联的公司,则测试集的意义就不大,泛化误差会存在偏移。
因此,在时间维度上切分更加安全 —— 但这实际是默认RNN可以(在训练集)从过去学到的规律也适用于将来。换句话说,我们假设时间序列是静态的(至少是在一个较宽的区间内)。对于时间序列,这个假设是合理的(比如,化学反应就是这样,化学定理不会每天发生改变),但其它的就不是(例如,金融市场就不是静态的,一旦交易员发现规律并从中牟利,规律就会改变)。要保证时间序列确实是静态的,可以在验证集上画出模型随时间的误差:如果模型在验证集的前端表现优于后段,则时间序列可能就不够静态,最好是在一个更短的时间区间内训练。
总而言之,将时间序列切分成训练集、验证集和测试集不是简单的工作,怎么做要取决于具体的任务。
回到莎士比亚!这里将前90%的文本作为训练集(剩下的作为验证集和测试集),创建一个tf.data.Dataset,可以从这个集和一个个返回每个角色:
train_size = dataset_size * 90 // 100
dataset = tf.data.Dataset.from_tensor_slices(encoded[:train_size])
将序列数据集切分成多个窗口
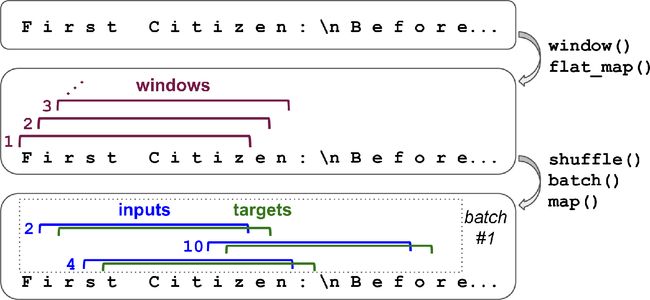
现在训练集包含一个单独的长序列,超过100万的任务,所以不能直接在这个训练集上训练神经网络:现在的RNN等同于一个有100万层的深度网络,只有一个超长的单实例来训练。所以,得使用数据集的window()方法,将这个长序列转化为许多小窗口文本。每个实例都是完整文本的相对短的子字符串,RNN只在这些子字符串上展开。这被称为截断沿时间反向传播。调用window()方法创建一个短文本窗口的数据集:
n_steps = 100
window_length = n_steps + 1 # target = input 向前移动1个角色
dataset = dataset.window(window_length, shift=1, drop_remainder=True)
提示:可以调节
n_steps:用短输入序列训练RNN更为简单,但肯定的是RNN学不到任何长度超过n_steps的规律,所以n_steps不要太短。
默认情况下,window()方法创建的窗口是不重叠的,但为了获得可能的最大训练集,我们设定shift=1,好让第一个窗口包含角色0到100,第二个窗口包含角色1到101,等等。为了确保所有窗口是准确的101个角色长度(为了不做填充而创建批次),设置drop_remainder=True(否则,最后的100个窗口会包含100个角色、99个角色,一直到1个角色)。
window()方法创建了一个包含窗口的数据集,每个窗口也是数据集。这是一个嵌套的数据集,类似于列表的列表。当调用数据集方法处理(比如、打散或做批次)每个窗口时,这样会很方便。但是,不能直接使用嵌套数据集来训练,因为模型要的输入是张量,不是数据集。因此,必须调用flat_map()方法:它能将嵌套数据集转换成打平的数据集。例如,假设 {1, 2, 3} 表示包含张量1、2、3的序列。如果将嵌套数据集 {{1, 2}, {3, 4, 5, 6}} 打平,就会得到 {1, 2, 3, 4, 5, 6} 。另外,flat_map()方法可以接收函数作为参数,可以处理嵌套数据集的每个数据集。例如,如果将函数 lambda ds: ds.batch(2) 传递给 flat_map() ,它能将 {{1, 2}, {3, 4, 5, 6}} 转变为 {[1, 2], [3, 4], [5, 6]} :这是一个张量大小为2的数据集。
有了这些知识,就可以打平数据集了:
dataset = dataset.flat_map(lambda window: window.batch(window_length))
我们在每个窗口上调用了batch(window_length):因为所有窗口都是这个长度,对于每个窗口,都能得到一个独立的张量。现在的数据集包含连续的窗口,每个有101个角色。因为梯度下降在训练集中的实例独立同分布时的效果最好,需要打散这些窗口。然后我们可以对窗口做批次,分割输入(前100个角色)和目标(最后一个角色):
batch_size = 32
dataset = dataset.shuffle(10000).batch(batch_size)
dataset = dataset.map(lambda windows: (windows[:, :-1], windows[:, 1:]))
图16-1总结了数据集准备步骤(窗口长度是11,不是101,批次大小是3,不是32)。
第13章讨论过,类型输入特征通常都要编码,一般是独热编码或嵌入。这里,使用独热编码,因为独立角色不多(只有39):
dataset = dataset.map(
lambda X_batch, Y_batch: (tf.one_hot(X_batch, depth=max_id), Y_batch))
最后,加上预提取:
dataset = dataset.prefetch(1)
就是这样!准备数据集是最麻烦的部分。下面开始搭建模型。
搭建并训练Char-RNN模型
根据前面的100个角色预测下一个角色,可以使用一个RNN,含有两个GRU层,每个128个单元,每个单元对输入(dropout)和隐藏态(recurrent_dropout)的丢失率是20%。如果需要的话,后面可以微调这些超参数。输出层是一个时间分布的紧密层,有39个单元(max_id),因为文本中有39个不同的角色,需要输出每个可能角色(在每个时间步)的概率。输出概率之后应为1,所以使用softmax激活很熟。然后可以使用"sparse_categorical_crossentropy"损失和Adam优化器,编译模型。最后,就可以训练模型几个周期了(训练过程可能要几个小时,取决于硬件):
model = keras.models.Sequential([
keras.layers.GRU(128, return_sequences=True, input_shape=[None, max_id],
dropout=0.2, recurrent_dropout=0.2),
keras.layers.GRU(128, return_sequences=True,
dropout=0.2, recurrent_dropout=0.2),
keras.layers.TimeDistributed(keras.layers.Dense(max_id,
activation="softmax"))
])
model.compile(loss="sparse_categorical_crossentropy", optimizer="Adam")
history = model.fit(dataset, epochs=20)
使用Char-RNN模型
现在就有了可以预测莎士比亚要写的下一个人物的模型了。输入数据之前,先要像之前那样做预处理,因此写个小函数来做预处理:
def preprocess(texts):
X = np.array(tokenizer.texts_to_sequences(texts)) - 1
return tf.one_hot(X, max_id)
现在,用这个模型预测文本中的下一个字母:
>>> X_new = preprocess(["How are yo"])
>>> Y_pred = model.predict_classes(X_new)
>>> tokenizer.sequences_to_texts(Y_pred + 1)[0][-1] # 1st sentence, last char
'u'
预测成功!接下来用这个模型生成文本。
生成假莎士比亚文本
要使用Char-RNN生成新文本,我们可以给模型输入一些文本,让模型预测出下一个字母,将字母添加到文本的尾部,再将延长后的文本输入给模型,预测下一个字母,以此类推。但在实际中,这会导致相同的单词不断重复。相反的,可以使用tf.random.categorical()函数,随机挑选下一个角色,概率等同于估计概率。这样就能生成一些多样且有趣的文本。根据类的对数概率(logits),categorical()函数随机从类索引采样。为了对生成文本的多样性更可控,我们可以用一个称为“温度“的可调节的数来除以对数概率:温度接近0,会利于高概率角色,而高温度会是所有角色概率相近。下面的next_char()函数使用这个方法,来挑选添加进文本中的角色:
def next_char(text, temperature=1):
X_new = preprocess([text])
y_proba = model.predict(X_new)[0, -1:, :]
rescaled_logits = tf.math.log(y_proba) / temperature
char_id = tf.random.categorical(rescaled_logits, num_samples=1) + 1
return tokenizer.sequences_to_texts(char_id.numpy())[0]
然后,可以写一个小函数,重复调用next_char():
def complete_text(text, n_chars=50, temperature=1):
for _ in range(n_chars):
text += next_char(text, temperature)
return text
现在就可以生成一些文本了!先尝试下不同的温度数:
>>> print(complete_text("t", temperature=0.2))
the belly the great and who shall be the belly the
>>> print(complete_text("w", temperature=1))
thing? or why you gremio.
who make which the first
>>> print(complete_text("w", temperature=2))
th no cce:
yeolg-hormer firi. a play asks.
fol rusb
显然,当温度数接近1时,我们的莎士比亚模型效果最好。为了生成更有信服力的文字,可以尝试用更多GRU层、每层更多的神经元、更长的训练时间,添加正则(例如,可以在GRU层中设置recurrent_dropout=0.3)。另外,模型不能学习长度超过n_steps(只有100个角色)的规律。你可以使用更大的窗口,但也会让训练更为困难,甚至LSTM和GRU单元也不能处理长序列。另外,还可以使用有状态RNN。
有状态RNN
到目前为止,我们只使用了无状态RNN:在每个训练迭代中,模型从全是0的隐藏状态开始训练,然后在每个时间步更新其状态,在最后一个时间步,隐藏态就被丢掉,以后再也不用了。如果让RNN保留这个状态,供下一个训练批次使用如何呢?这么做的话,尽管反向传播只在短序列传播,模型也可以学到长时规律。这被称为有状态RNN。
首先,有状态RNN只在前一批次的序列离开,后一批次中的对应输入序列开始的情况下才有意义。所以第一件要做的事情是使用序列且没有重叠的输入序列(而不是用来训练无状态RNN时的打散和重叠的序列)。当创建Dataset时,调用window()必须使用shift=n_steps(而不是shift=1)。另外,不能使用shuffle()方法。但是,准备有状态RNN数据集的批次会麻烦些。事实上,如果调用batch(32),32个连续的窗口会放到一个相同的批次中,后面的批次不会接着这些窗口。第一个批次含有窗口1到32,第二个批次批次含有窗口33到64,因此每个批次中的第一个窗口(窗口1和33),它们是不连续的。最简单办法是使用只包含一个窗口的“批次”:
dataset = tf.data.Dataset.from_tensor_slices(encoded[:train_size])
dataset = dataset.window(window_length, shift=n_steps, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_length))
dataset = dataset.batch(1)
dataset = dataset.map(lambda windows: (windows[:, :-1], windows[:, 1:]))
dataset = dataset.map(
lambda X_batch, Y_batch: (tf.one_hot(X_batch, depth=max_id), Y_batch))
dataset = dataset.prefetch(1)
图16-2展示了处理的第一步。
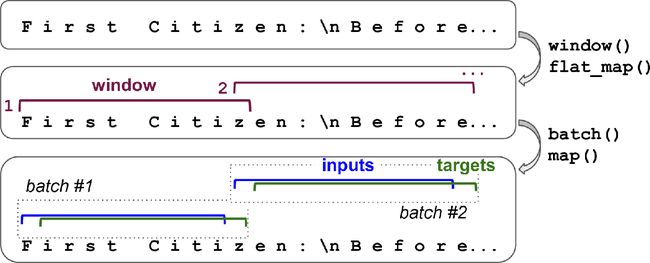
做批次虽然麻烦,但可以实现。例如,我们可以将莎士比亚作品切分成32段等长的文本,每个做成一个连续序列的数据集,最后使用tf.train.Dataset.zip(datasets).map(lambda *windows: tf.stack(windows))来创建合适的连续批次,批次中的nth输入序列紧跟着nth结束的地方(notebook中有完整代码)。
现在创建有状态RNN。首先,创建每个循环层时需要设置stateful=True。第二,有状态RNN需要知道批次大小(因为要为批次中的输入序列保存状态),所以要在第一层中设置batch_input_shape参数。不用指定第二个维度,因为不限制序列的长度:
model = keras.models.Sequential([
keras.layers.GRU(128, return_sequences=True, stateful=True,
dropout=0.2, recurrent_dropout=0.2,
batch_input_shape=[batch_size, None, max_id]),
keras.layers.GRU(128, return_sequences=True, stateful=True,
dropout=0.2, recurrent_dropout=0.2),
keras.layers.TimeDistributed(keras.layers.Dense(max_id,
activation="softmax"))
])
在每个周期之后,回到文本开头之前,需要重设状态。要这么做,可以使用一个小调回:
class ResetStatesCallback(keras.callbacks.Callback):
def on_epoch_begin(self, epoch, logs):
self.model.reset_states()
现在可以编译、训练模型了(周期数更多,是因为每个周期比之前变短了,每个批次只有一个实例):
model.compile(loss="sparse_categorical_crossentropy", optimizer="Adam")
model.fit(dataset, epochs=50, callbacks=[ResetStatesCallback()])
提示:训练好模型之后,只能预测训练时相同大小的批次。为了避免这个限制,可以创建一个相同的无状态模型,将有状态模型的参数复制到里面。
创建了一个角色层面的模型,接下来看看词层面的模型,并做一个常见的自然语言处理任务:情感分析。我们会学习使用遮掩来处理变化长度的序列。
情感分析
如果说MNIST是计算机视觉的“hello world”,那么IMDb影评数据集就是自然语言处理的“hello world”:这个数据集包含50000条英文影评,25000条用于训练,25000条用于测试,是从IMDb网站提取的,并带有影评标签,负(0)或正(1)。和MNIST一样,IMDb影评数据集的流行是有原因的:笔记本电脑上就可以跑起来,不会耗时太长,也具有一定挑战。Keras提供了一个简单的函数加载数据集:
>>> (X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data()
>>> X_train[0][:10]
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65]
影评在哪里?可以看到,数据集已经经过预处理了:X_train包括列表形式的影评,每条都是整数NumPy数组,每个整数代表一个词。所有标点符号都被去掉了,单词转换为小写,用空格隔开,最后用频次建立索引(小整数对应常见词)。整数0、1、2是特殊的:它们表示填充token、序列开始(SSS)token、和未知单词。如果想看到影评,可以如下解码:
>>> word_index = keras.datasets.imdb.get_word_index()
>>> id_to_word = {id_ + 3: word for word, id_ in word_index.items()}
>>> for id_, token in enumerate(("", "", "")):
... id_to_word[id_] = token
...
>>> " ".join([id_to_word[id_] for id_ in X_train[0][:10]])
' this film was just brilliant casting location scenery story'
在真实的项目中,必须要自己预处理文本。你可以使用前面用过的Tokenizer,但要设置char_level=False(其实是默认的)。当编码单词时,Tokenizer会过滤掉许多字符,包括多数标点符号、换行符、制表符(可以通过filters参数控制)。最重要的,Tokenizer使用空格确定单词的边界。这对于英语和其它用空格隔开单词的语言是行得通的,但并不是所有语言都有空格。中文不使用空格,越南语甚至在单词里也有空格,德语经常将几个单词不用空格连在一起。就算在英语中,空格也不总是token文本的最好方法:比如San Francisco或#ILoveDeepLearning。
幸好,有更好的方法。Taku Kudo在2018年的一篇论文中介绍了一种无监督学习方法,在亚词层面tokenize和detokenize文本,与所属语言独立,空格和其它字符等同处理。使用这种方法,就算模型碰到一个之前没见过的单词,模型还是能猜出它的意思。例如,模型在训练期间没见过单词smartest,但学过est词尾是最的意思,然后就可以推断smartest的意思。Google的SentencePiece项目提供了开源实现,见Taku Kudo和John Richardson的论文。
另一种方法,是Rico Sennrich在更早的论文中提出的,探索了其它创建亚单词编码的方法(比如,使用字节对编码)。最后同样重要的,TensorFlow团队在2019年提出了TF.Text库,它实现了多种token化策略,包括WordPiece(字节对编码的变种)。
如果你想将模型部署到移动设备或网页中,又不想每次都写一个不同的预处理函数,最好只使用TensorFlow运算,它可以融进模型中。看看怎么做。首先,使用TensorFlow Datasets加载原始IMDb评论,为文本(字节串):
import tensorflow_datasets as tfds
datasets, info = tfds.load("imdb_reviews", as_supervised=True, with_info=True)
train_size = info.splits["train"].num_examples
然后,写预处理函数:
def preprocess(X_batch, y_batch):
X_batch = tf.strings.substr(X_batch, 0, 300)
X_batch = tf.strings.regex_replace(X_batch, b"", b" ")
X_batch = tf.strings.regex_replace(X_batch, b"[^a-zA-Z']", b" ")
X_batch = tf.strings.split(X_batch)
return X_batch.to_tensor(default_value=b""), y_batch
预处理函数先裁剪影评,只保留前300个字符:这么做可以加速训练,并且不会过多影响性能,因为大多数时候只要看前一两句话,就能判断是正面或侧面的了。然后使用正则表达式替换"Well, I can't变成
""Well I can't"。最后,preprocess()函数用空格分隔影评,返回一个嵌套张量,然后将嵌套张量转变为紧密张量,给所有影评填充上",使其长度相等。
然后,构建词典。这需要使用preprocess()函数再次处理训练集,并使用Counter统计每个单词的出现次数:
from collections import Counter
vocabulary = Counter()
for X_batch, y_batch in datasets["train"].batch(32).map(preprocess):
for review in X_batch:
vocabulary.update(list(review.numpy()))
看看最常见的词有哪些:
>>> vocabulary.most_common()[:3]
[(b'', 215797), (b'the', 61137), (b'a', 38564)]
但是,并不需要让模型知道词典中的所有词,所以裁剪词典,只保留10000个最常见的词:
vocab_size = 10000
truncated_vocabulary = [
word for word, count in vocabulary.most_common()[:vocab_size]]
现在需要加上预处理步骤将每个单词替换为单词ID(即它在词典中的索引)。就像第13章那样,创建一张查找表,使用1000个未登录词(oov)桶:
words = tf.constant(truncated_vocabulary)
word_ids = tf.range(len(truncated_vocabulary), dtype=tf.int64)
vocab_init = tf.lookup.KeyValueTensorInitializer(words, word_ids)
num_oov_buckets = 1000
table = tf.lookup.StaticVocabularyTable(vocab_init, num_oov_buckets)
用这个词表查找几个单词的ID:
>>> table.lookup(tf.constant([b"This movie was faaaaaantastic".split()]))
因为this、movie、was是在词表中的,所以它们的ID小于10000,而faaaaaantastic不在词表中,所以将其映射到一个oov桶,其ID大于或等于10000。
提示:TF Transform提供了一些实用的函数来处理词典。例如,
tft.compute_and_apply_vocabulary()函数:它可以遍历数据集,找到所有不同的词,创建词典,还能生成TF运算,利用词典编码每个单词。
现在,可以创建最终的训练集。对影评做批次,使用preprocess()将其转换为词的短序列,然后使用一个简单的encode_words()函数,利用创建的词表来编码这些词,最后预提取下一个批次:
def encode_words(X_batch, y_batch):
return table.lookup(X_batch), y_batch
train_set = datasets["train"].batch(32).map(preprocess)
train_set = train_set.map(encode_words).prefetch(1)
最后,创建模型并训练:
embed_size = 128
model = keras.models.Sequential([
keras.layers.Embedding(vocab_size + num_oov_buckets, embed_size,
input_shape=[None]),
keras.layers.GRU(128, return_sequences=True),
keras.layers.GRU(128),
keras.layers.Dense(1, activation="sigmoid")
])
model.compile(loss="binary_crossentropy", optimizer="Adam",
metrics=["accuracy"])
history = model.fit(train_set, epochs=5)
第一个层是一个嵌入层,它将所有单词ID变为嵌入。每有一个单词ID(vocab_size + num_oov_buckets),嵌入矩阵就有一行,每有一个嵌入维度,嵌入矩阵就有一列(这个例子使用了128个维度,这是一个可调的超参数)。模型输入是2D张量,形状为 [批次大小, 时间步] ,嵌入层的输出是一个3D张量,形状为 [批次大小, 时间步, 嵌入大小] 。
模型剩下的部分就很简单了:有两个GRU层,第二个只返回最后时间步的输出。输出层只有一个神经元,使用sigmoid激活函数,输出评论是正或负的概率。然后编译模型,利用前面准备的数据集来训练几个周期。
遮掩
在训练过程中,模型会学习到填充token要被忽略掉。但这其实是已知的。为什么不告诉模型直接忽略填充token,将精力集中在真正重要的数据中呢?只需一步就好:创建嵌入层时加上mask_zero=True。这意味着填充token(其ID为0)可以被接下来的所有层忽略。
其中的原理,是嵌入层创建了一个等于K.not_equal(inputs, 0)(其中K = keras.backend)遮掩张量:这是一个布尔张量,形状和输入相同,只要词ID有0,它就等于False,否则为True。模型自动将这个遮掩张量向前传递给所有层,只要时间维度保留着。所以在例子中,尽管两个GRU都接收到了遮掩张量,但第二个GRU层不返回序列(只返回最后一个时间步),遮掩张量不会传递到紧密层。每个层处理遮掩的方式不同,但通常会忽略被遮掩的时间步(遮掩为False的时间步)。例如,当循环神经层碰到被遮掩的时间步时,就只是从前一时间步复制输出而已。如果遮掩张量一直传递到输出(输出为序列的模型),则遮掩也会作用到损失上,所以遮掩时间步不会贡献到损失上(它们的损失为0)。
警告:基于英伟达的cuDNN库,
LSTM层和GRU层针对GPU有优化实现。但是,这个实现不支持遮挡。如果你的模型使用了遮挡,则这些曾会回滚到(更慢的)默认实现。注意优化实现还需要使用几个超参数的默认值:activation、recurrent_activation、recurrent_dropout、unroll、use_bias、reset_after。
所有接收遮挡的层必须支持遮挡(否则会抛出异常)。包括所有的循环层、TimeDistributed层和其它层。所有支持遮挡的层必须有等于True的属性supports_masking。如果想实现自定义的支持遮挡的层,应该给call()方法添加mask参数。另外,要在构造器中设定self.supports_masking = True。如果第一个层不是嵌入层,可以使用keras.layers.Masking层:它设置遮挡为K.any(K.not_equal(inputs, 0), axis=-1),意思是最后一维都是0的时间步,会被后续层遮挡。
对于Sequential模型,使用遮挡层,并自动向前传递遮挡是最佳的。但复杂模型上不能这么做,比如将Conv1D层与循环层混合使用时。对这种情况,需要使用Functional API 或 Subclassing API 显式计算遮挡张量,然后将其传给需要的层。例如,下面的模型等价于前一个模型,除了使用 Functional API 手动处理遮挡张量:
K = keras.backend
inputs = keras.layers.Input(shape=[None])
mask = keras.layers.Lambda(lambda inputs: K.not_equal(inputs, 0))(inputs)
z = keras.layers.Embedding(vocab_size + num_oov_buckets, embed_size)(inputs)
z = keras.layers.GRU(128, return_sequences=True)(z, mask=mask)
z = keras.layers.GRU(128)(z, mask=mask)
outputs = keras.layers.Dense(1, activation="sigmoid")(z)
model = keras.Model(inputs=[inputs], outputs=[outputs])
训练几个周期之后,这个模型的表现就相当不错了。如果使用TensorBoard()调回,可以可视化TensorBoard中的嵌入是怎么学习的:可以看到awesome和amazing这样的词渐渐聚集于嵌入空间的一边,而awful、terrible这样的词聚集到另一边。一些词可能不会像预期那样是正面的,比如good,可能所有负面评论含有not good。模型只基于25000个词就能学会词嵌入,让人印象深刻。如果训练集有几十亿的规模,效果就更好了。但可惜没有,但可以利用在其它大语料(比如,维基百科文章)上训练的嵌入,就算不是影评也可以?毕竟,amazing这个词在哪种语境的意思都差不多。另外,甚至嵌入是在其它任务上训练的,也可能有益于情感分析:因为awesome和amazing有相似的意思,即使对于其它任务(比如,预测句子中的下一个词),它们也倾向于在嵌入空间聚集,所以对情感分析也是有用的。所以看看能否重复利用预训练好的词嵌入。
复用预训练的词嵌入
在TensorFlow Hub上可以非常方便的找到可以复用的预训练模型组件。这些模型组件被称为模块。只需浏览TF Hub 仓库,找到需要的模型,复制代码到自己的项目中就行,模块可以总动下载下来,包含预训练权重,到自己的模型中。
例如,在情感分析模型中使用nnlm-en-dim50句子嵌入模块,版本1:
import tensorflow_hub as hub
model = keras.Sequential([
hub.KerasLayer("https://tfhub.dev/google/tf2-preview/nnlm-en-dim50/1",
dtype=tf.string, input_shape=[], output_shape=[50]),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dense(1, activation="sigmoid")
])
model.compile(loss="binary_crossentropy", optimizer="Adam",
metrics=["accuracy"])
hub.KerasLayer从给定的URL下载模块。这个特殊的模块是“句子编码器”:它接收字符串作为输入,将每句话编码为一个独立矢量(这个例子中是50维度的矢量)。在内部,它将字符串解析(空格分隔),然后使用预训练(训练语料是Google News 7B,一共有70亿个词)的嵌入矩阵来嵌入每个词。然后计算所有词嵌入的平均值,结果是句子嵌入。我们接着可以添加两个简单的紧密层来创建一个出色的情感分析模型。默认,hub.KerasLayer是不可训练的,但创建时可以设定trainable=True,就可以针对自己的任务微调了。
警告:不是所有的TF Hub模块都支持TensorFlow 2。
然后,就可以加载IMDb影评数据集了,不需要预处理(但要做批次和预提取),直接训练模型就成:
datasets, info = tfds.load("imdb_reviews", as_supervised=True, with_info=True)
train_size = info.splits["train"].num_examples
batch_size = 32
train_set = datasets["train"].batch(batch_size).prefetch(1)
history = model.fit(train_set, epochs=5)
注意到,TF Hub 模块的URL的末尾指定了是模型的版本1。版本号可以保证当有新的模型版本发布时,不会破坏自己的模型。如果在浏览器中输入这个URL,能看到这个模块的文档。TF Hub会默认将下载文件缓存到系统的临时目录。你可能想将文件存储到固定目录,以免每次系统清洗后都要下载。要这么做的话,设置环境变量TFHUB_CACHE_DIR就成(比如,os.environ["TFHUB_CACHE_DIR"] = "./my_tfhub_cache")。
截至目前,我们学习了时间序列、用Char-RNN生成文本、用RNN做情感分析、训练自己的词嵌入或复用预训练词嵌入。接下来看看另一个重要的NLP任务:神经网络机器翻译(NMT),我们先使用纯粹的编码器-解码器模型,然后使用注意力机制,最后看看Transformer架构。
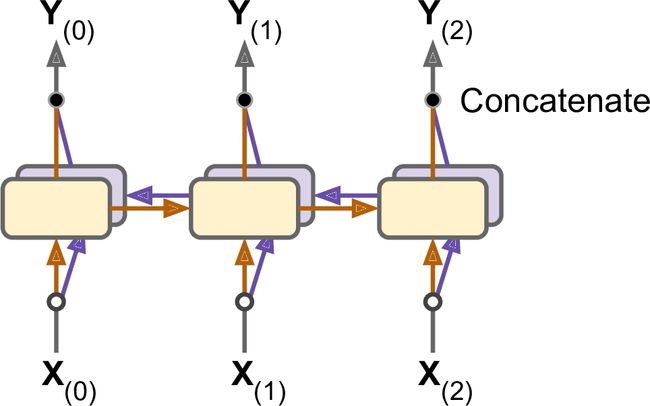
用编码器-解码器做机器翻译
看一个简单的神经网络机器翻译模型,它能将英语翻译为法语(见图16-3)。
简而言之,英语句子输入进编码器,解码器输出法语。注意,法语翻译也作为解码器的输入,但向后退一步。换句话说,解码器将前一步的输出再作为输入(不用管它输出什么)。对于第一个词,给它加上一个序列开始(SOS)token,序列结尾加上序列结束(EOS)token。
英语句子在输入给编码器之前,先做了翻转。例如,“I drink milk”翻转为“milk drink I”。这样能保证英语句子的第一个词是最后一个输入给编码器的,通常也是解码器要翻译的第一个词。
每个单词首先用它的ID来表示(例如,288代表milk)。然后,嵌入层返回单词嵌入。单词嵌入才是输入给编码器和解码器的。
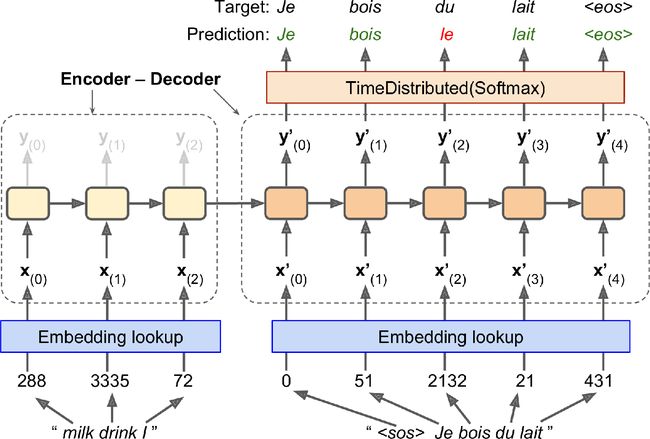
在每一步,解码器输出一个输出词典中每个单词的分数,然后softmax层将分数变为概率。例如,在第一步,“Je”的概率可能为20%,“Tu”的概率可能为1%,等等。概率最高的词作为输出。这特别像一个常规分类任务,所以可以用"sparse_categorical_crossentropy"损失训练模型,跟前面的Char-RNN差不多。
在做推断时,没有目标语句输入进解码器。相反的,只是输入解码器前一步的输出,见图16-4(这需要一个嵌入查找表,图中没有展示)。
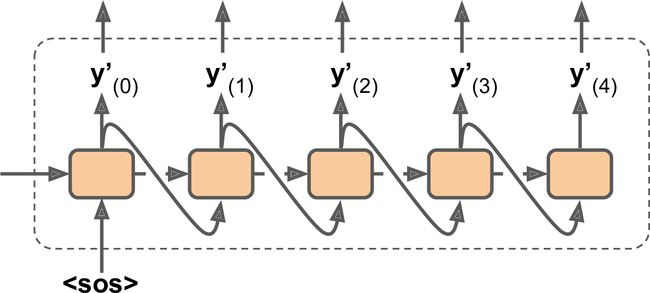
好了,现在知道整体的大概了。但要实现模型的话,还有几个细节要处理:
目前假定所有(编码器和解码器的)输入序列的长度固定。但很显然句子长度是变化的。因为常规张量的形状固定,它们只含有相同长度的句子。可以用遮挡来处理;但如果句子的长度非常不同,就不能像之前情感分析那样截断(因为想要的是完整句子的翻译)。可以将句子放进长度相近的桶里(一个桶放1个词到6个词的句子,一个桶放7个词到12个词的句子,等等),给短句子加填充,使同一个桶中的句子长度相同(见
tf.data.experimental.bucket_by_sequence_length()函数)。例如,“I drink milk” 变为 “milk drink I”。 要忽略所有在EOS token后面的输出,这些输出不能影响损失(遮挡起来)。例如,如果模型输出“Je bois du lait
oui”,忽略最后一个词对损失的影响。 如果输出词典比较大(这个例子就是这样),输出每个词的概率会非常慢。如果目标词典有50000个发语词,则解码器要输出50000维的矢量,在这个矢量上计算softmax非常耗时。一个方法是只查看模型对正确词和非正确词采样的对数概率输出,然后根据这些对数概率计算一个大概的损失。这个采样softmax方法是Sébastien Jean 在2015年提出的。在TensorFlow中,你可以在训练时使用
tf.nn.sampled_softmax_loss(),在推断时使用常规softmax函数(推断时不能使用采样softmax,因为需要知道目标)。
TensorFlow Addons 项目涵盖了许多序列到序列的工具,可以创建准生产的编码器-解码器。例如,下面的代码创建了一个基本的编码器-解码器模型,相似于图16-3:
import tensorflow_addons as tfa
encoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
decoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
sequence_lengths = keras.layers.Input(shape=[], dtype=np.int32)
embeddings = keras.layers.Embedding(vocab_size, embed_size)
encoder_embeddings = embeddings(encoder_inputs)
decoder_embeddings = embeddings(decoder_inputs)
encoder = keras.layers.LSTM(512, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_embeddings)
encoder_state = [state_h, state_c]
sampler = tfa.seq2seq.sampler.TrainingSampler()
decoder_cell = keras.layers.LSTMCell(512)
output_layer = keras.layers.Dense(vocab_size)
decoder = tfa.seq2seq.basic_decoder.BasicDecoder(decoder_cell, sampler,
output_layer=output_layer)
final_outputs, final_state, final_sequence_lengths = decoder(
decoder_embeddings, initial_state=encoder_state,
sequence_length=sequence_lengths)
Y_proba = tf.nn.softmax(final_outputs.rnn_output)
model = keras.Model(inputs=[encoder_inputs, decoder_inputs, sequence_lengths],
outputs=[Y_proba])
这个代码很简单,但有几点要注意。首先,创建LSTM层时,设置return_state=True,以便得到最终隐藏态,并将其传给解码器。因为使用的是LSTM单元,它实际返回两个隐藏态(短时和长时)。TrainingSampler是TensorFlow Addons中几个可用的采样器之一:它的作用是在每一步告诉解码器,前一步的输出是什么。在推断时,采样器是实际输出的token嵌入。在训练时,是前一个目标token的嵌入:这就是为什么使用TrainingSampler的原因。在实际中,一个好方法是,一开始用目标在前一时间步的嵌入训练,然后逐渐过渡到实际token在前一步的输出。这个方法是Samy Bengio在2015年的一篇论文中提出的。ScheduledEmbeddingTrainingSampler可以随机从目标或实际输出挑选,你可以在训练中逐渐调整概率。
双向RNN
在每个时间步,常规循环层在产生输出前,只会查看过去和当下的输入。换句话说,循环层是遵循因果关系的,它不能查看未来。这样的RNN在预测时间序列时是合理的,但对于许多NLP任务,比如机器翻译,在编码给定词时,最好看看后面的词是什么。比如,对于这几个短语“the Queen of the United Kingdom”、“the queen of hearts”、“the queen bee”:要正确编码“queen”,需要向前看。要实现的话,可以对于相同的输入运行两个循环层,一个从左往右读,一个从右往左读。然后将每个时间步的输出结合,通常是连起来。这被称为双向循环层(见图16-5)。
要在Keras中实现双向循环层,可以在keras.layers.Bidirectional层中包一个循环层。例如,下面的代码创建了一个双向GRU层:
keras.layers.Bidirectional(keras.layers.GRU(10, return_sequences=True))
笔记:
Bidirectional层会创建一个GRU层的复制(但方向相反),会运行两个层,并将输出连起来。因此GRU层有10个神经元,Bidirectional层在每个时间步会输出20个值。
集束搜索
假设你用编码器-解码器模型将法语“Comment vas-tu?”翻译为英语。正确的翻译应该是“How are you?”,但得到的结果是“How will you?”。查看训练集,发现许多句子,比如“Comment vas-tu jouer?”翻译成了“How will you play?”。所以模型看到“Comment vas”之后,将其翻译为“How will”并不那么荒唐。但在这个例子中,这就是一个错误,并且模型还不能返回修改,模型只能尽全力完成句子。如果每步都是最大贪心地输出结果,只能得到次优解。如何能让模型返回到之前的错误并改错呢?最常用的方法之一,是使用集束搜索:它跟踪k个最大概率的句子列表,在每个解码器步骤延长一个词,然后再关注其中k个最大概率的句子。参数k被称为集束宽度。
例如,假设使用宽度为3的集束搜索,用模型来翻译句子“Comment vas-tu?”。在第一个解码步骤,模型会输出每个可能词的估计概率。假设前3个词的估计概率是“How”(估计概率是75%)、“What”(3%)、“You”(1%)。这是目前的句子列表。然后,创建三个模型的复制,预测每个句子的下一个词。第一个模型会预测“How”后面的词,假设结果是36%为“will”、32%为“are”、16%为“do”,等等。注意,这是条件概率。第二个模型会预测“What”后面的词:50%为“are”,等等。假设词典有10000个词,每个模型会输出10000个概率。
然后,计算30000个含有两个词的句子的概率。将条件概率相乘。例如,“How will”的概率是75% × 36% = 27%。计算完30000个概率之后,只保留概率最大的3个。假设是“How will” (27%)、“How are” (24%)、“How do” (12%)。现在“How will”的概率最大,但“How are”并没有被删掉。
接着,重复同样的过程:用三个模型预测这三个句子的接下来的词,再计算30000个含有三个词的句子的概率。假设前三名是“How are you” (10%)、“How do you” (8%)、“How will you” (2%)。再下一步的前三名是“How do you do” (7%)、“How are you
TensorFlow Addons可以很容易实现集束搜索:
beam_width = 10
decoder = tfa.seq2seq.beam_search_decoder.BeamSearchDecoder(
cell=decoder_cell, beam_width=beam_width, output_layer=output_layer)
decoder_initial_state = tfa.seq2seq.beam_search_decoder.tile_batch(
encoder_state, multiplier=beam_width)
outputs, _, _ = decoder(
embedding_decoder, start_tokens=start_tokens, end_token=end_token,
initial_state=decoder_initial_state)
首先创建BeamSearchDecoder,它包装所有的解码器的克隆(这个例子中有10个)。然后给每个解码器克隆创建一个编码器的最终状态的复制,然后将状态传给解码器,加上开始和结束token。
有了这些,就能得到不错的短句的翻译了(如果使用预训练词嵌入,效果更好)。但是这个模型翻译长句子的效果很糟。这又是RNN的短时记忆问题。注意力机制的出现,解决了这一问题。
注意力机制
图16-3中,从“milk”到“lait”的路径非常长。这意味着这个单词的表征(还包括其它词),在真正使用之前,要经过许多步骤。能让这个路径短点吗?
这是Dzmitry Bahdanau在2014年的突破性论文中的核心想法。他们引入了一种方法,可以让解码器在每个时间步关注特别的(被编码器编码的)词。例如,在解码器需要输出单词“lait”的时间步,解码器会将注意力关注在单词“milk”上。这意味着从输入词到其翻译结果的路径变的短得多了,所以RNN的短时记忆的限制就减轻了很多。注意力机制革新了神经网络机器翻译(和NLP的常见任务),特别是对于长句子(超过30个词),带来了非凡的进步。
图16-6展示了注意力机制的架构(稍微简化过,后面会说明)。左边是编码器和解码器。不是将编码器的最终隐藏态传给解码器(其实是传了,但图中没有展示),而是将所有的输出传给解码器。在每个时间步,解码器的记忆单元计算所有这些输出的加权和:这样可以确定这一步关注哪个词。权重α(t,i)是第ith个编码器输出在第tth解码器时间步的权重。例如,如果权重α(3,2)比α(3,0)和α(3,1)大得多,则解码器会用更多注意力关注词2(“milk”),至少是在这个时间步。剩下的解码器就和之前一样工作:在每个时间步,记忆单元接收输入,加上上一个时间步的隐藏态,最后(这一步图上没有画出)加上上一个时间步的目标词(或推断时,上一个时间步的输出)。
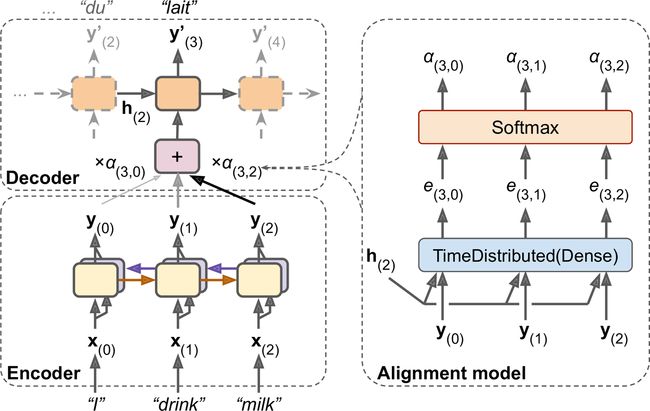
权重α(t,i)是从哪里来的呢?其实很简单:是用一种小型的、被称为对齐模型(或注意力层)的神经网络生成的,注意力层与模型的其余部分联合训练。对齐模型展示在图的右边:一开始是一个时间分布紧密层,其中有一个神经元,它接收所有编码器的输出,加上解码器的上一个隐藏态(即h(2))。这个层输出对每个编码器输出,输出一个分数(或能量)(例如,e(3, 2)):这个分数衡量每个输出和解码器上一个隐藏态的对齐程度。最后,所有分数经过一个softmax层,得到每个编码器输出的最终权重(例如,α(3, 2))。给定解码器时间步的所有权重相加等于1(因为softmax层不是时间分布的)。这个注意力机制称为Bahdanau注意力。因为它将编码器输出和解码器的上一隐藏态连了起来,也被称为连接注意力(或相加注意力)。
笔记:如果输入句子有n个单词,假设输出也是这么多单词,则要计算n2个权重。幸好,平方计算的复杂度不高,因为即使是特别长的句子,也不会有数千个单词。
另一个常见的注意力机制是不久之后,由Minh-Thang Luong在2015年的论文中提出的。因为注意力机制的目标是衡量编码器的输出,和解码器上一隐藏态的相似度,Minh-Thang Luong提出,只要计算这两个矢量的点积,因为点积是有效衡量相似度的手段,并且计算起来很快。要计算的话,两个矢量的维度必须相同。这被称为Luong注意力,或相乘注意力。和Bahdanau注意力一样,点积的结果是一个分数,所有分数(在特定的解码器时间步)通过softmax层,得到最终权重。Luong提出的另一个简化方法是使用解码器在当前时间步的隐藏态,而不是上一时间步,然后使用注意力机制的输出(标记为(t) ),直接计算解码器的预测(而不是计算解码器的当前隐藏态)。他还提出了一个点击的变体,编码器的输出先做线性变换(即,时间分布紧密层不加偏置项),再做点积。这被称为“通用”点积方法。作者比较了点积方盒和连接注意力机制(加上一个缩放参数v),观察到点积方法的变体表现的更好。因为这个原因,如今连接注意力很少使用了。公式16-1总结了这三种注意力机制。
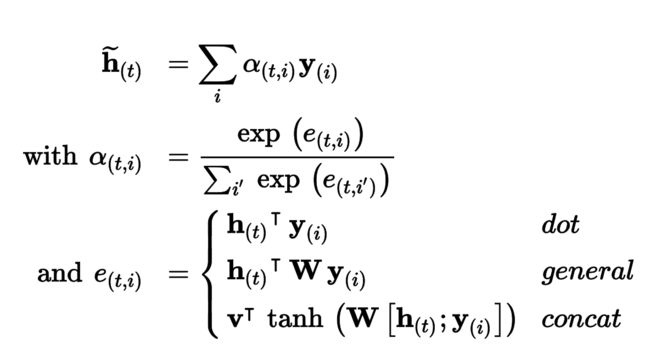
使用TensorFlow Addons将Luong注意力添加到编码器-解码器模型的方法如下:
attention_mechanism = tfa.seq2seq.attention_wrapper.LuongAttention(
units, encoder_state, memory_sequence_length=encoder_sequence_length)
attention_decoder_cell = tfa.seq2seq.attention_wrapper.AttentionWrapper(
decoder_cell, attention_mechanism, attention_layer_size=n_units)
只是将解码器单元包装进AttentionWrapper,然后使用了想用的注意力机制(这里用的是Luong注意力)。
视觉注意力
注意力机制如今应用的非常广泛。最先用途之一是利用视觉注意力生成图片标题:卷积神经网络首先处理图片,生成一些特征映射,然后用带有注意力机制的解码器RNN来生成标题,每次生成一个词。在每个解码器时间步(每个词),解码器使用注意力模型聚焦于图片的一部分。例如,对于图16-7,模型生成的标题是“一个女人正在公园里扔飞盘”,可以看到解码器要输出单词“飞盘”时,注意力关注的图片的部分:显然,注意力大部分聚焦于飞盘。
解释性
注意力机制的的一个额外的优点,是它更容易使人明白是什么让模型产生输出。这被称为可解释性。当模型犯错时,可解释性非常有帮助:例如,如果一张狗在雪中行走的图,被打上了“狼在雪中行走”的标签,你就可以回去查看当模型输出“狼”时,模型聚焦于什么。你可能看到模型不仅关注于狗,还关注于雪地,暗示了一种可能的解释:可能模型判断是根据有没有很多雪,来判断是狗还是狼。然后可以通过用更多没有雪的狼的图片进行训练,来修复模型。这个例子来自于Marco Tulio Ribeiro在2016年的论文,他们使用了不同的可解释性:局部围绕分类器的预测,来学习解释性模型。
在一些应用中,可解释性不仅是调试模型的工具,而是正当的需求(比如一个判断是否进行放贷的需求)。
注意力机制如此强大,以至于只需要注意力机制就能创建出色的模型。
Attention Is All You Need:Transformer架构
在2017年一篇突破性论文中,谷歌的研究者提出了:Attention Is All You Need(只要注意力)。他们创建了一种被称为Transformer(转换器)的架构,它极大的提升了NMT的性能,并且没有使用任何循环或卷积层,只用了注意力机制(加上嵌入层、紧密层、归一化层,和一些其它组件)。这个架构的另一个优点,是训练的更快,且更容易并行运行,花费的时间和精力比之前的模型少得多。
Transformer架构见图16-8。
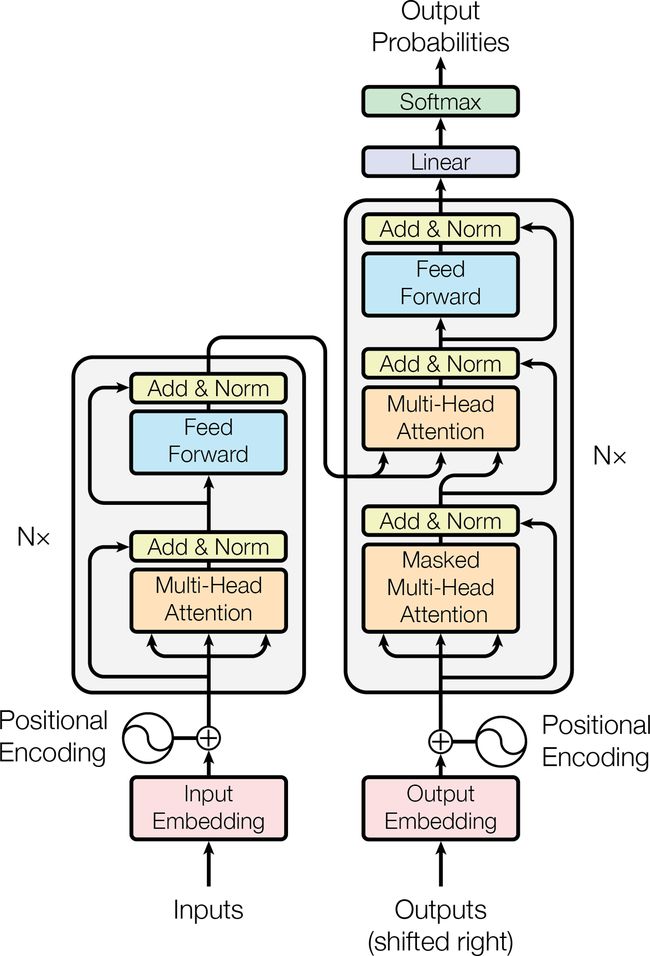
一起看下这个架构:
图的左边和以前一样是编码器,接收的输入是一个批次的句子,表征为序列化的单词ID(输入的形状是 [批次大小, 最大输入句子长度] ),每个单词表征为512维(所以编码器的输出形状是 [批次大小, 最大输入句子长度, 512] )。注意,编码器的头部叠加了N次(论文中,N=6)。
架构的右边是解码器。在训练中,它接收目标句子作为输入(也是表征为序列化的单词ID),向右偏移一个时间步(即,在起点插入一个SOS token)。它还接收编码器的输出(即,来自左边的箭头)。注意,解码器的头部也重叠了N次,编码器的最终输出,传入给解码器重叠层中的每一个部分。和以前一样,在每个时间步,解码器输出每个下一个可能词的概率(输出形状是 [批次大小, 最大输出句子长度, 词典长度] )。
在推断时,解码器不能接收目标,所以输入的是前面的输出词(起点用SOS token)。因此模型需要重复被调用,每一轮预测一个词(预测出来的词在下一轮输入给解码器,直到输出EOS token)。
-
仔细观察下,可以看到其实你已经熟悉其中大部分组件了:两个嵌入层,5 × N 个跳连接,每个后面是一个归一化层,2 × N 个 “Feed Forward” 模块(由两个紧密层组成(第一个使用ReLU激活函数,第二个不使用激活函数),输出层是使用softmax激活函数的紧密层)。所有这些层都是时间分布的,因此每个词是独立处理的。但是一次只看一个词,该如何翻译句子呢?这时就要用到新组件了:
编码器的多头注意力层,编码每个词与句子中其它词的关系,对更相关的词付出更多注意力。例如,输出句子“They welcomed the Queen of the United Kingdom”中的词“Queen”的层的输出,会取决于句子中的所有词,但更多注意力会在“United”和“Kingdom”上。这个注意力机制被称为自注意力(句子对自身注意)。后面会讨论它的原理。解码器的遮挡多头注意力层做的事情一样,但每个词只关注它前面的词。最后,解码器的上层多头注意力层,是解码器用于在输入句子上付出注意力的。例如,当解码器要输出“Queen”的翻译时,解码器会对输入句子中的“Queen”这个词注意更多。
位置嵌入是紧密矢量(类似词嵌入),表示词在句子中的位置。第nth个位置嵌入,添加到每个句子中的第nth个词上。这可以让模型知道每个词的位置,这是因为多头注意力层不考虑词的顺序或位置,它只看关系。因为所有其它层都是时间分布的,它们不知道每个词的(相对或绝对)位置。显然,相对或绝对的词的位置非常重要,因此需要将位置信息以某种方式告诉Transformer,位置嵌入是行之有效的方法。
下面逐一仔细介绍Transformer中的新组件,从位置嵌入开始。
位置嵌入
位置嵌入是一个紧密矢量,它对词在句子中的位置进行编码:第ith个位置嵌入添加到句子中的第ith个词。模型可以学习这些位置嵌入,但在论文中,作者倾向使用固定位置嵌入,用不同频率的正弦和余弦函数来定义。公式16-2定义了位置嵌入矩阵P,见图16-9的底部(做过转置),其中Pp,i是单词在句子的第pth个位置的第ith个嵌入的组件。
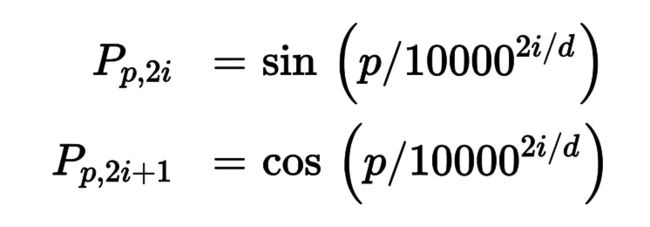
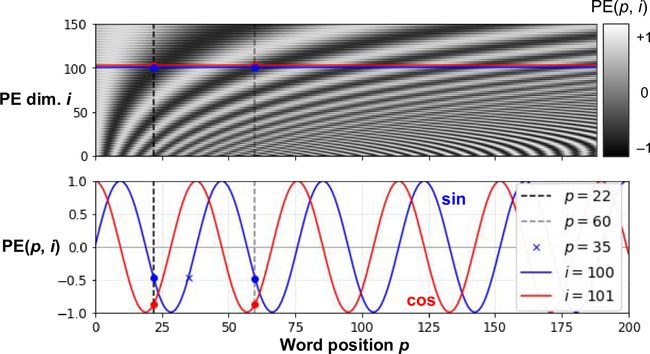
这个方法的效果和学习过的位置嵌入相同,但可以拓展到任意长度的句子上,这是它受欢迎的原因。给词嵌入加上位置嵌入之后,模型剩下的部分就可以访问每个词在句子中的绝对位置了,因为每个值都有一个独立的位置嵌入(比如,句子中第22nd个位置的词的位置嵌入,表示为图16-9中的左下方的垂直虚线,可以看到位置嵌入对这个位置是一对一的)。另外,振动函数(正弦和余弦)选择也可以让模型学到相对位置。例如,相隔38个位置的词(例如,在位置 p=22 和 p=60)总是在嵌入维度 i=100 和 i=101 有相同的位置嵌入值,见图16-9。这解释了对于每个频率,为什么需要正弦和余弦两个函数:如果只使用正弦(蓝线, i=100),模型不能区分位置 p=25 和 p=35 (叉子标记)。
TensorFlow中没有PositionalEmbedding层,但创建很容易。出于效率的考量,在构造器中先计算出位置嵌入(因此需要知道最大句子长度,max_steps,每个词表征的维度,max_dims)。然后调用call()方法裁剪嵌入矩阵,变成输入的大小,然后添加到输入上。因为创建位置嵌入矩阵时,添加了一个大小为1的维度,广播机制可以确保位置矩阵添加到输入中的每个句子上:
class PositionalEncoding(keras.layers.Layer):
def __init__(self, max_steps, max_dims, dtype=tf.float32, **kwargs):
super().__init__(dtype=dtype, **kwargs)
if max_dims % 2 == 1: max_dims += 1 # max_dims must be even
p, i = np.meshgrid(np.arange(max_steps), np.arange(max_dims // 2))
pos_emb = np.empty((1, max_steps, max_dims))
pos_emb[0, :, ::2] = np.sin(p / 10000**(2 * i / max_dims)).T
pos_emb[0, :, 1::2] = np.cos(p / 10000**(2 * i / max_dims)).T
self.positional_embedding = tf.constant(pos_emb.astype(self.dtype))
def call(self, inputs):
shape = tf.shape(inputs)
return inputs + self.positional_embedding[:, :shape[-2], :shape[-1]]
然后可以创建Transformer的前几层:
embed_size = 512; max_steps = 500; vocab_size = 10000
encoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
decoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
embeddings = keras.layers.Embedding(vocab_size, embed_size)
encoder_embeddings = embeddings(encoder_inputs)
decoder_embeddings = embeddings(decoder_inputs)
positional_encoding = PositionalEncoding(max_steps, max_dims=embed_size)
encoder_in = positional_encoding(encoder_embeddings)
decoder_in = positional_encoding(decoder_embeddings)
接下来看看Transformer的核心:多头注意力层。
多头注意力
要搞懂多头注意力层的原理,必须先搞懂收缩点积注意力层(Scaled Dot-Product Attention),多头注意力是基于它的。假设编码器分析输入句子“They played chess”,编码器分析出“They”是主语,“played”是动词,然后用词的表征编码这些信息。假设解码器已经翻译了主语,接下来要翻译动词。要这么做的话,它需要从输入句子取动词。这有点像查询字典:编码器创建了字典{“subject”: “They”, “verb”: “played”, …},解码器想查找键“verb”对应的值是什么。但是,模型没有离散的token来表示键(比如“subject” 或 “verb”);它只有这些(训练中学到的)信息的矢量化表征所以用来查询的键,不会完美对应前面字典中的键。解决的方法是计算查询词和键的相似度,然后用softmax函数计算概率权重。如果表示动词的键和查询词很相似,则键的权重会接近于1。然后模型可以计算对应值的加权和,如果“verb”键的权重接近1,则加权和会接近于词“played”的表征。总而言之,可以将整个过程当做字典查询。Transformer使用点积做相似度计算,和Luong注意力一样。实际上,公式和Luong注意力一样,除了有缩放参数,见公式16-3,是矢量的形式。
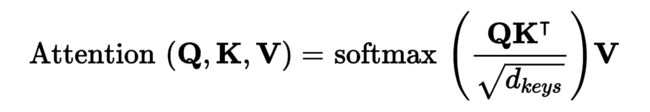
在这个公式中:
Q矩阵每行是一个查询词。它的形状是[nqueries, dkeys],nqueries是查询数,dkeys是每次查询和每个键的维度数。
K矩阵每行是一个键。它的形状是 [nkeys, dkeys],nkeys是键和值的数量。
V矩阵每行是一个值。它的形状是 [nkeys, dvalues],dvalues是每个值的数。
Q KT的形状是 [nqueries, nkeys]:它包含这每个查询/键对的相似分数。softmax函数的输出有相同的形状,且所有行的和是1。最终的输出形状是[nqueries, dvalues] ,每行代表一个查询结果(值的加权和)。
缩放因子缩小了相似度分数,防止softmax函数饱和(饱和会导致梯度变小)。
在计算softmax之前,通过添加一些非常大的负值,到对应的相似度分上,可以遮挡一些键值对。这在遮挡多头机制层中很有用。
在编码器中,这个公式应用到批次中的每个句子,Q、K、V等于输入句中的词列表(所以,句子中的每个词会和相同句中的每个词比较,包括自身)。相似的,在解码器的遮挡注意力层中,这个公式会应用到批次中每个目标句上,但要用遮挡,防止每个词和后面的词比较(因为在推断时,解码器只能访问已经输出的词,所以训练时要遮挡后面的输出token)。在解码器的上边的注意力层,键K矩阵和值V矩阵是斌吗器生成的此列表,查询Q矩阵是解码器生成的词列表。
keras.layers.Attention层实现了缩放点积注意力,它的输入是Q、K、V,除此之外,还有一个批次维度(第一个维度)。
提示:在TensorFlow中,如果A和B是两个维度大于2的张量 —— 比如,分别是 [2, 3, 4, 5] 和 [2, 3, 5, 6] —— 则
then tf.matmul(A, B)会将这两个张量当做 2 × 3 的数组,每个单元都是一个矩阵,它会乘以对应的矩阵。A中第i行、第j列的矩阵,会乘以B的第i行、第j列的矩阵。因为4 × 5矩阵乘以5 × 6矩阵,结果是4 × 6矩阵,所以tf.matmul(A, B)的结果数组的形状是[2, 3, 4, 6]。
如果忽略跳连接、归一化层、Feed Forward块,且这是缩放点积注意力,不是多头注意力,则Transformer可以如下实现:
Z = encoder_in
for N in range(6):
Z = keras.layers.Attention(use_scale=True)([Z, Z])
encoder_outputs = Z
Z = decoder_in
for N in range(6):
Z = keras.layers.Attention(use_scale=True, causal=True)([Z, Z])
Z = keras.layers.Attention(use_scale=True)([Z, encoder_outputs])
outputs = keras.layers.TimeDistributed(
keras.layers.Dense(vocab_size, activation="softmax"))(Z)
use_scale=True参数可以让层学会如何缩小相似度分数。这是和Transformer的一个区别,后者总是用相同的因子()缩小相似度分数。causal=True参数,可以让注意力层的每个输出token只注意前面的输出token。
下面来看看多头注意力层是什么?它的架构见图16-10。
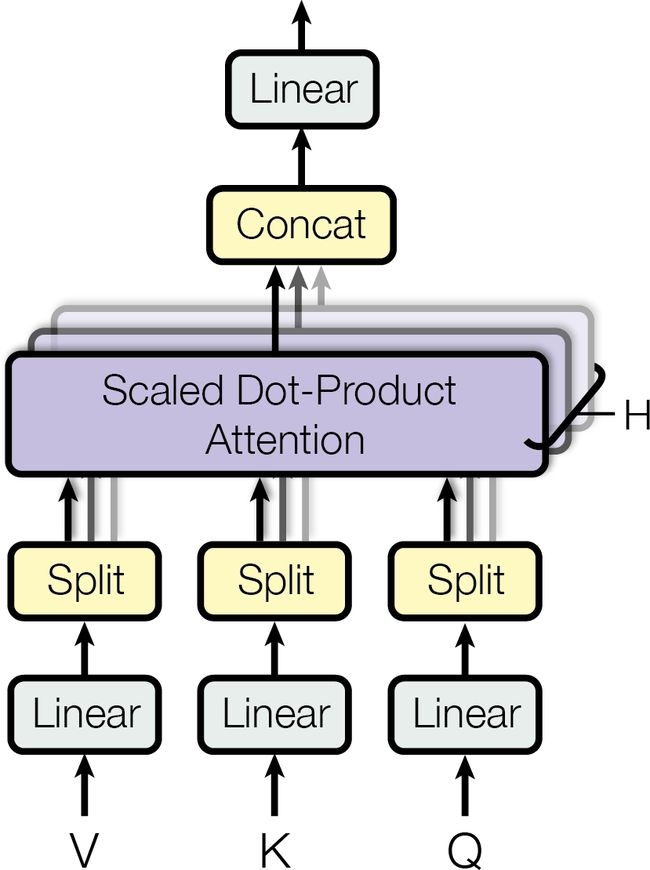
可以看到,它包括一组缩放点积注意力层,每个前面有一个值、键、查询的线性变换(即,时间分布紧密层,没有激活函数)。所有输出简单连接起来,再通过一个最终的线性变换。为什么这么做?这个架构的背后意图是什么?考虑前面讨论过的单词“played”。编码器可以将它是动词的信息做编码。同时,词表征还包含它在文本中的位置(得益于位置嵌入),除此之外,可能还包括了其它有用的信息,比如时态。总之,词表征编码了词的许多特性。如果只用一个缩放点积注意力层,则只有一次机会来查询所有这些特性。这就是为什么多头注意力层使用了多个不同的值、键、查询的线性变换:这可以让模型将词表征投影到不同的亚空间,每个关注于词特性的一个子集。也许一个线性层将词表征投影到一个亚空间,其中的信息是该词是个动词,另一个线性层会提取它是一个过去式,等等。然后缩放点积注意力做查询操作,最后将所有结果串起来,在投射到原始空间。
在写作本书时,TensorFlow 2 还没有Transformer类或MultiHeadAttention类。但是,可以查看TensorFlow的这个教程:创建语言理解的Transformer模型。另外,TF Hub团队正向TensorFlow 2 移植基于Transformer的模块,很快就可以用了。同时,我希望我向你展示了自己实现Transformer并不难,这是一个很好的练习!
语言模型的最新进展
2018年被称为“NLP的ImageNet时刻”:成果惊人,产生了越来越大的基于LSTM和Transformer、且在大数据集上训练过的架构。建议你看看下面的论文,都是2018年发表的:
Matthew Peters的ELMo 论文,介绍了语言模型的嵌入(Embeddings from Language Models (ELMo)):学习深度双向语言模型的内部状态,得到的上下文词嵌入。例如,词“queen”在“Queen of the United Kingdom”和“queen bee”中的嵌入不同。
Jeremy Howard 和 Sebastian Ruder 的ULMFiT 论文,介绍了无监督预训练对NLP的有效性:作者用海量语料,使用自监督学习(即,从数据自动生成标签)训练了一个LSTM语言模型,然后在各种任务上微调模型。他们的模型在六个文本分类任务上取得了优异的结果(将误差率降低了18-24%)。另外,他们证明,通过在100个标签样本上微调预训练模型,可以达到在10000个样本上训练的效果。
Alec Radford 和其他OpenAI人员的GPT 论文,也展示了无监督训练的有效性,但他们使用的是类似Transformer的架构。作者预训练了一个庞大但简单的架构,由12个Transformer模块组成(只使用了遮挡多头注意力机制),也是用自监督训练的。然后在多个语言任务上微调,只对每个任务做了小调整。任务种类很杂:包括文本分类、衔接(句子A是否跟着句子B),相似度(例如,“Nice weather today”和“It is sunny”很像),还有问答(通过阅读几段文字,让模型来回答多选题)。几个月之后,在2019年的二月,Alec Radford、Jeffrey Wu和其它OpenAI的人员发表了GPT-2 论文,介绍了一个相似的架构,但是更大(超过15亿参数),他们展示了这个架构可以在多个任务上取得优异的表现,且不需要微调。这被称为零次学习(zero-shot learning (ZSL))。https://github.com/openai/gpt-2上是一个GPT-2模型的带有预训练权重的小型版本,“只有”1.17亿个参数。
-
Jacob Devlin 和其它Google人员的BERT 论文,也证明了在海量语料上做自监督预训练的有效性,使用的是类似GPT的架构,但用的是无遮挡多头注意力层(类似Transformer的编码器)。这意味着模型实际是双向的这就是BERT(Bidirectional Encoder Representations from Transformers)中的B的含义。最重要的,作者提出了两个预训练任务,用以测试模型能力:
遮挡语言模型(MLM)
句子中的词有15的概率被遮挡。训练模型来预测被遮挡的词。例如,如果原句是“She had fun at the birthday party”,模型的输入是“Shefun at the party”,让模型来预测“had” 和 “birthday”(忽略其它输出)。更加准确些,每个选出的单词有80%的概率被遮挡,10%的概率被替换为随机词(降低预训练和微调的差异,因为模型在微调时看不到 token),10%的概率不变(使模型偏向正确答案)。 预测下一句(NSP)
训练模型预测两句话是否是连续的。例如,模型可以预测“The dog sleeps”和“It snores loudly”是连续的,但是“The dog sleeps” 和 “The Earth orbits the Sun”是不连续的。这是一个有挑战的任务,可以在微调任务,比如问答和衔接上,极大提高模型的性能。
可以看到,2018年和2019年的创新是亚词层面的token化,从LSTM转向Transformer,使用自监督学习预训练语言模型,做细微的架构变动(或不变动)来微调模型。因为进展非常快,每人说得清明年流行的是什么。如今,流行的是Transformer,但明天可能是CNN(Maha Elbayad在2018年的论文,使用了遮挡的2D卷积层来做序列到序列任务)。如果卷土重来的话,也有可能是RNN(例如,Shuai Li在2018年的论文展示了,通过让给定RNN层中的单元彼此独立,可以训练出更深的RNN,能学习更长的序列)。
下一章,我们会学习用自编码器,以无监督的方式学习深度表征,并用生成对抗网络生成图片及其它内容!
练习
有状态RNN和无状态RNN相比,优点和缺点是什么?
为什么使用编码器-解码器RNN,而不是普通的序列到序列RNN,来做自动翻译?
如何处理长度可变的输入序列?长度可变的输出序列怎么处理?
什么是集束搜索,为什么要用集束搜索?可以用什么工具实现集束搜索?
什么是注意力机制?用处是什么?
Transformer架构中最重要的层是什么?它的目的是什么?
什么时候需要使用采样softmax?
Hochreiter 和 Schmidhuber 在关于LSTM的论文中使用了嵌入Reber语法。这是一种人工的语法,用来生成字符串,比如 “BPBTSXXVPSEPE”。查看Jenny Orr对它的介绍。选择一个嵌入Reber语法(比如Jenny Orr的论文中展示的),然后训练一个RNN来判断字符串是否符合语法。你需要先写一个函数来生成训练批次,其中50%符合语法,50%不符合语法。
训练一个编码器-解码器模型,它可以将日期字符串从一个格式变为另一个格式(例如,从“April 22, 2019”变为“2019-04-22”)。
阅读TensorFlow的《Neural Machine Translation with Attention tutorial》。
使用一个最近的语言模型(比如,BERT),来生成一段更具信服力的莎士比亚文字。
参考答案见附录A。
第10章 使用Keras搭建人工神经网络
第11章 训练深度神经网络
第12章 使用TensorFlow自定义模型并训练
第13章 使用TensorFlow加载和预处理数据
第14章 使用卷积神经网络实现深度计算机视觉
第15章 使用RNN和CNN处理序列
第16章 使用RNN和注意力机制进行自然语言处理
第17章 使用自编码器和GAN做表征学习和生成式学习
第18章 强化学习
第19章 规模化训练和部署TensorFlow模型