DEEP LEARNING FOR CHATBOTS, PART 2 – IMPLEMENTING A RETRIEVAL-BASED MODEL IN TENSORFLOW
本文将要实现一个检索式的机器人。检索式架构有预定好的语料答复库。检索式模型的输入是上下文潜在的答复。模型输出对这些答复的打分,可以选择最高分的答案作为回复。
既然生成式的模型更弹性,也不需要预定义的语料,为何不选择它呢?
生成式模型的问题就是实际使用起来并不能好好工作,至少现在是。因为答复比较自由,容易犯语法错误和不相关、不合逻辑的答案,并且需要大量的数据且很难做优化。大量的生产系统上还是采用检索模型或者检索模型和生成模型结合的方式。例如google的smart reply。生成模型是研究的热门领域,但是我们还没到应用它的程度。如果你想要做一个聊天机器人,最好还是选用检索式模型
ubuntu语料库
本文采用了ubuntu语料库(UDC),它是目前公开的最大的数据集。paper介绍了这个语料库建设细节。我们就不重复说这个方面了。但是了解你所用到的语料是非常重要的。
训练数据包含100w的例子,一半是正面(label=1)一半是负面(lable=0),每个例子包含一个上下文,一个正面的标注意味着答复是符合上下文的,负面的标注意味着答复不符合(答复是从其他语料对里去随机挑选搭配过来的)
下面是一些例子:
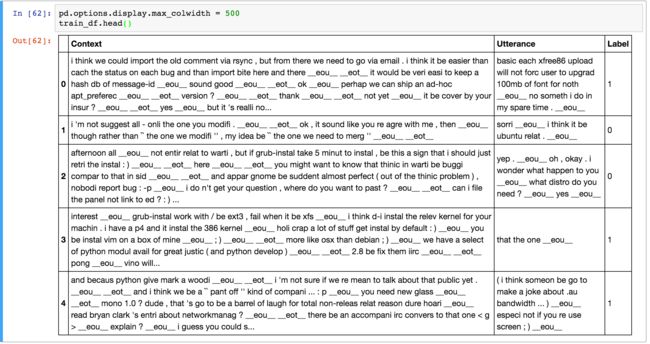
注意下,上面的数据集生成脚本已经使用自然语言开发包 NLTK做了一系列的语料处理包括(分词,提取词干,词意恢复),脚本也做了把名字、地点、组织、URL。系统路径等实体信息用特殊的token来替代。这些预处理不是严格必要的,但是能改善一些系统的表现。语料的上下文平均有86个词语,答复平均有17个词语长。有人做了语料的统计分析:data analysis
数据集有测试和验证集。他们的格式和训练集不一样。每个测试验证集记录包含上下文、正确答复和9个不正确的干扰项。模型的目标是给争取答复打上高分,给干扰项目打上低分
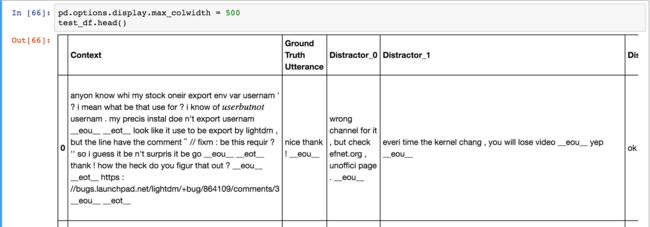
有多个办法评估我们的模型,一种常用的办法是 K召回,它的意思是让模型在10个备选答案(1个正确答案和9个干扰项)里找出最好的K个答案,如果正确的那个答案在K个答案里,就标记为成功案例。所以K越大,模型的任务就越轻松,如果我们让K=10,这就得到一个100%的召回率,因为我们最多就10个备选。如果K=1,模型只有一次机会选中正确答案。
这里你或许好奇9个干扰项目怎么选出来的,这个数据集里是随机的方法选择的。但是现实世界里你可能数百万的可能答复,并且你并不知道答复是否合理正确。你没能力从数百万的可能的答复里去挑选一个得分最高的正确答复。成本太高了! google的smart reply用分布式集群技术计算一系列的可能答复去挑选paper,或者你只有百来个备选答案,可以去评估每一个
BASELINES
在开始梦幻的神经网络模型之前,我们先建立一些简单的基础模型去帮助我们理解我们模型有些什么表现可以期待。将要用下面的函数去评估K召回量化办法:
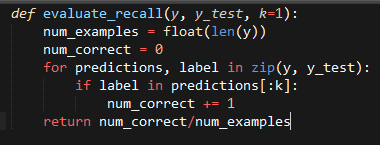
这里y是根据模型预测的分数降序排列的,y_test是数据集里的标注数据。例如y=[0,3,1,2,5,6,4,7,8,9]意味这0是分数最高的预测答案,9是最低分数。也y_test是10个备选答案,且下标为0的答案用于存正确的答案,后面都是干扰项。
直觉的来看,模型完全随机的预测正确答案,在K=1的时候,召回率是10%,K=2的时候,召回率是20%。
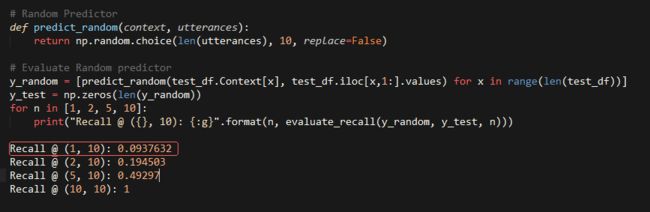
好的,看起来recall运行结果符合预期。当然我们不需要一个随机模型。另外一个基础模型还采用过tf-idf预测tf-idf代表:“term frequency – inverse document” frequency,(词频/文档),它可以量化一个词语在一个文档里的重要程度。这也是和整个语料库相关的指标。不继续深入tf idf,你可以网上找资料看看。含有相似内容的文档有相似的tf idf向量,直觉的看一个上下文问题和答复有相似的词语,更像是合格的问答对。至少比随机的办法好。需要多库都有内置的tf idf库函数实现例如scikit-learn.所以很容易使用,我们可以构造一个tf idf模型来看看表现如何
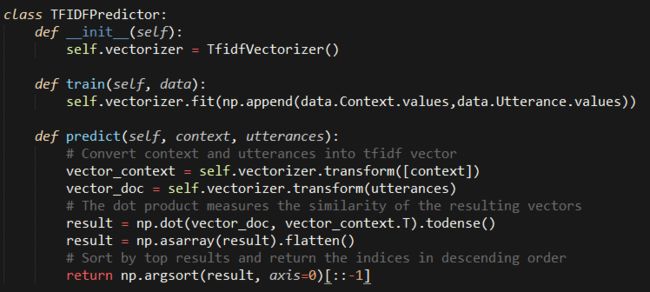
评估:

Recall @ (1, 10): 0.495032
Recall @ (2, 10): 0.596882
Recall @ (5, 10): 0.766121
Recall @ (10, 10): 1
可以看到,tf idf模型表现的比随机模型好非常多。但是这个效果里完美还很远,首先因为我们基于tf-idf是假设问答是相似的,其实正确的答案并不需要和问题相似,其次tfidf忽略了词语的顺序,而这个是一个重要的信息。用神经网络模型可以做的更好一点。
DUAL ENCODER LSTM
本文要构造的深度学习模型:Dual Encoder LSTM ,(双编码LSTM)
这是我们可以应用的神经网络中的一种,并不需要是最好的一个,你也可以继续看看所有的没有使用过的神经网络架构,这是个热门研究领域,例如句子到句子Sequence-to-Sequence Models的模型经常用到机器翻译方面,或许也能做的不错。而我们这次采用双编码的LSTM模型,因为被论文paper证明在这个语料库上表现不错,有相当不错的改进。这就意味着我们知道对这个模型的该有什么期待以及确保我们的实现是正确的。在这个问题上应用其他模型也是很有趣的项目。
双编码LSTM看起来是这样的:
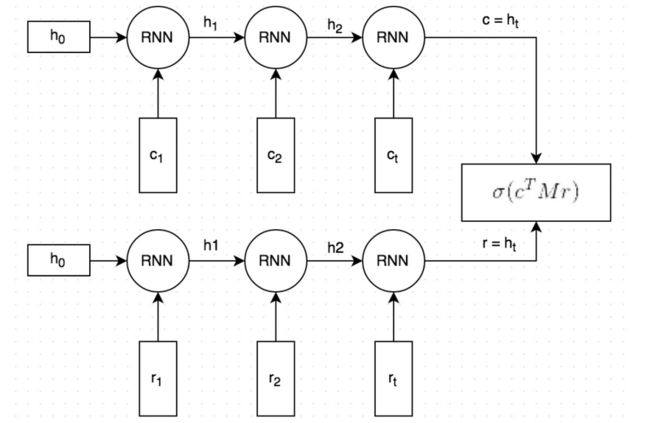
它大致工作原理如下:
1、上下文问题和答案都分成每个词语,每个词语嵌入embedding成向量,词向量首先用standford的Glove工具,并在训练中进行调优(这个是可选项,并没有在上图里表达出来。我也发现用Glove来初始化词向量并没有显著改善模型的表现)
2、向量化后的问题和答案都输入一个词一个词的输入到同一个循环神经网络RNN里,RNN就会产生一个向量,大致可以当作是问题和答案(图里的c和r)的“语义”,我们可以选择向量的维度大小,这里我们用了256维
3、用一个矩阵M乘以c得到一个答案的预测结果r' ,c是一个256d的向量,M就是一个256x256的矩阵,所以结果是另外一个256d的向量,当作是生成的回复。M需要在训练中学习
4、我们计算r'和r的相似度。方法是对向量就点积,点积越大说明向量越相似,这个答案就应该得到更高的分数,然后我们用sigmoid逻辑函数把这个分数转化为一个概率。注意上图里把第三步和第四步放到一起了。
我们需要一个损失(代价)函数来训练网络。将要使用分类问题常用到的二分cross-entropy.对QA对(上下文问题和答复)的真实标注为y,y可以是1(实际答复)或者0(不正确答案),上面第四步计算出来的概率记作 y‘ 。所以这个corss entropy计算公式是:L= −y * ln(y') − (1 − y) * ln(1−y') 公式背后的意义很简单:如果y=1,L = -ln(y'),这就惩罚了那些预测值远离1的情况,如果y=0,L= −ln(1−y'),惩罚了那些预测值远离0的情况。
实现代码上我们使用了numpy pandas tensorflow 以及TF-Learn (有一些对高层次tensorflow函数的组合使用)
DATA PREPROCESSING 数据预处理
数据集本来是CSV格式,虽然我们可以直接使用,但是最好是把数据转化成tensorflow例子用到的格式,(也有tf.SequenceExample,但是看起来tf.learn不支持)用这个格式的好处是允许tensorflow直接load输入数据,并接着完成清洗、批量操作、排队等环节。我们也需要建设一个词库,和意味着需要映射每一个词语为一个整数,例如 cat 这个词语或许可以用 2631表示,TFRecord文件会生成并存储这些数字,而不是存储词语。我们也要存储这个映射表方便用整数找到词语。
每个例子包含下面的字段:
1、上下文(Q):代表上下文文本的一系列词id序列例如[231,2190,737,0,912]
2、上下文长度
3、回复 :同1一样的词id序列
4、回复长度
5、标注:训练数据里才有 0 or 1
6、干扰项[N] 测试/验证集里有,N 属于0-8.都是词id的序列
7、干扰项[N]长度
预处理代码prepare_data.py,产生三个文件train.tfrecords, validation.tfrecords test.tfrecords ,你可以下载UDC数据集自己运行下。
CREATING AN INPUT FUNCTION
创建一个输入函数
为了利用tesorflow内置的支持训练和评估的功能,我们需要创建一个输入函数,输入函数返回输入数据的批量结果。实际上因为训练数据和测试数据格式不同,我们需要分别些对应的输入函数。输入函数应该返回一系列特征和标注(如果允许)例如下面的代码行:

因为需要在训练和评估中用不同的输入函数,且我们讨厌代码拷贝,于是我们创建一个叫做create_input_fn的封装,里面为适当的模式(mode)创建合适的输入函数。当然需要一些其他参数帮忙,下面是我们正在用的定义:

完整的代码可以看udc_inputs.py,概括起来,这个函数实现下列功能:
1、定义了描述example 文件的字段的特征
2、用tf.TFRecordReader从输入文件中读取数据
3、根据字段特征定义解析记录
4、提取训练标注
5、批量处理examples和训练标注
6、返回批量处理好的examples和训练标注
DEFINING EVALUATION METRICS
定义评估标准
我们已经提到要用recall@K来评价模型,幸运的是tensorflow已经提供许多标准的评估办法,包括recall@K, 要使用这些功能,需要创建一个映射评估方法名到一个以预测结果和标注数据作为参数的处理函数的字典。
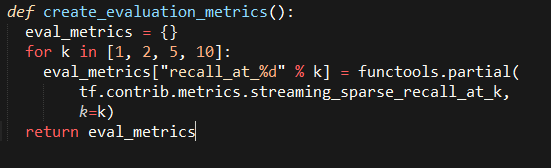
上面我们用到了functools.partial去把一个需要3个参数的函数转化只需要2个参数。别让streaming_sparse_recall_at_k 这个名字把你搞晕了,Streaming(流)只是代表这个量化办法是在多个批量结果上的累加求和,并且sparse(稀疏)和我们的标注格式有关。
这带来一个重要的点:评估期间,到底我们的预测结果是一个什么形式\格式呢?在训练阶段,我们预测样本例子里答复是否正确的概率。但是在评估阶段,我们的目的是给测试样本里的答复和9个干扰项目打分并且挑选最好的1个答案---我们没有简单预测正确或者错误。这就代表我们给每个样本评估的时候要返回一个10个分数的向量,例如
[0.34, 0.11, 0.22, 0.45, 0.01, 0.02, 0.03, 0.08, 0.33, 0.11]
这些分数和10个备选答案各自独立相关,所以概率之和不需要为1。因为在测试样本里下标为0的答案是真的回答。测试集里每个样本的标注数据全是0(译注:这是在介绍数据集格式,有些干扰文章)。 上面这个得分向量结果来看,因为第一个答复是第二大的(第一大的0.45),所以这个样本的测试结果在recall@1里,第一个答复只能算错误,那么测试为模型失败。而在recall@2里,则测试通过。
BOILERPLATE TRAINING CODE
训练代码的范式化
在些实际的神经网络之前,我想要写一个针对训练和评估模型的代码范式。因为一旦你依赖了正确的接口方式,就非常方便更换你用过任何类型神经网络模型。我们假设有一个模型函数model_fn用批量特征、标注数据、模式(训练 或者 评估)为参数,并返回预测结果。那么我们可以写出训练模型的通用代码:
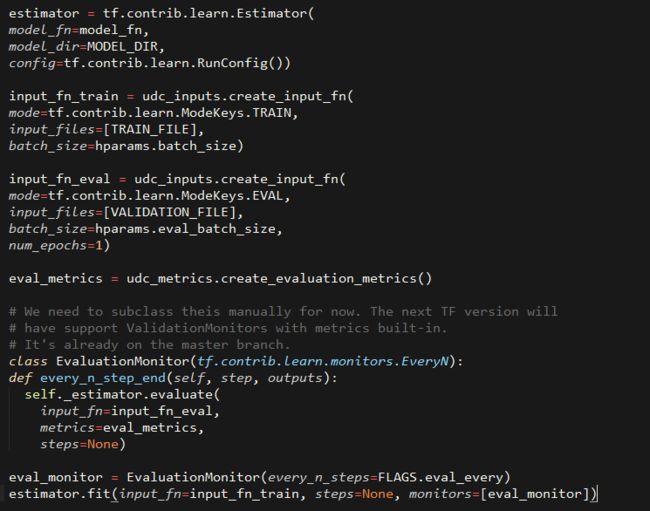
这里我们为模型创建了评估器modle_fn,训练和评估数据的两个输入函数,和我们的评估办法(一堆映射了recall k的函数集合),也定义了一个监视函数,在训练过程中每FLAGS.eval_every评价一下模型。训练程序是无休止的运行,但是tensorflow会自动保存节点数据到MODEL_DIR目录下,所以你可以任何时候停止训练。还有一个非常不错的技术就是early stopping要用上,意味着当验证集结果已经没有什么改善的时候(例如模型开始过拟合了)就要自动停止训练。可以看完整的代码udc_train.py
上面提到FLAGS,关于它我简要提两点:
1、FLAGS是一种拿到命令行方法的途径,类似python的参数解析。
2、hparams是在hparams.py代码里用户自定义的对象,保存了假设参数、网络节点数等我们可以调整模型的数据。这些hparams对象实例化的时候就给到模型。
创建模型
现在我们已经设置好了数据输入、解析、评估、训练方面的代码规范接口,该是我们些DUAL LSTM神经网络模型代码的时候了。我们已经写了一个create_model_fn的封装来透明训练数据和验证数据格式的不同,把数据都转为模型需要的格式。需要一个model_impl作为参数,这是实际做预测的函数,在我们这里就是要用的这个Dual Encoder LSTM,但是我们可以简单更换模型为其他神经网络。我们看看到底是怎样的代码:
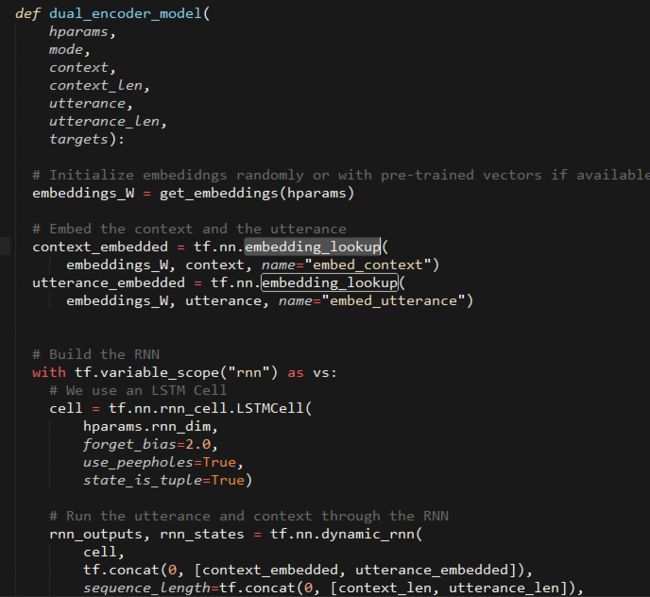
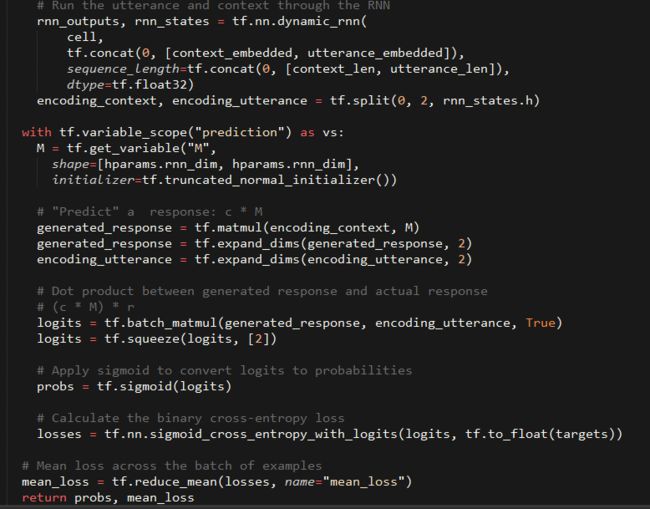
完整的代码在dual_encoder.py,到这里我们可以给训练过程代码udc_train.py实例化模型了。

好了,我们可以运行:
python udc_train.py
它就可以开始训练网络,并时而验证出召回率数据(你可以设置这个验证频率,参数是eval_every),可以运行python udc_train.py --help. 得到我们定义tf.flags和hparams的完整命令行标志列表。
评估模型:
训练完数据后,你可以运行
python udc_test.py --model_dir=$MODEL_DIR_FROM_TRAINING,
例如:.python udc_test.py --model_dir=~/github/chatbot-retrieval/runs/1467389151.
来在测试集上测试模型。这将在测试集而不是验证集上计算recall@K结果。注意训练和测试用到的参数要一致,例如用128维的向量来embbeding,那么测试脚本也要用同样的大小。
训练大概20000轮(快一点的GPU上计算,需要大约一个小时)得到的模型在测试集上的测试结果如下:
recall_at_1 = 0.507581018519
recall_at_2 = 0.689699074074
recall_at_5 = 0.913020833333
recall@1的结果和TFIDF模型接近,recall@2,recall@5有明显的改善,暗示我们的神经网络在正确答案上分配了更高的分数。本文参考的论文汇报的对应recall@1、recall@2、recall@5结果是0.55\0.72\0.92,但是我没法重现这么高的分数。或许数据预处理或者神经网络参数优化可以把分数再提高一点。
MAKING PREDICTIONS
预测
你可以修改和运行udc_predict.py去得到新输入的问题答案的预测得分,例如:
python udc_predict.py --model_dir=./runs/1467576365/
输出
Context: Example context
Response 1: 0.44806
Response 2: 0.481638
你可以给同一个上下文问题输入100个潜在的答复数据去测试分数,然后选择最高分数的那个答案了。
结论:
本文我们已经实现了一个检索式架构的神经网络模型可以给定一个上下文问题下给潜在答复去打分。这里有很多改进空间,可以用其他神经网络替代dual LSTM encoder,也可以在参数优化方面下手,或者在数据预处理上做。本文的代码和数据可以在github上得到 chatbot:code&data