概述
greenDAO 主要使用起来方便的地方,就是使用 @Entity 注解实体类后,只需要build工程,DaoMaster、DaoSession和对应的 Dao 文件就会自动生成,所以对于 greenDAO 来说,需要分析的主要就是 DaoMaster、DaoSession 和 xxDAO 这几部分。
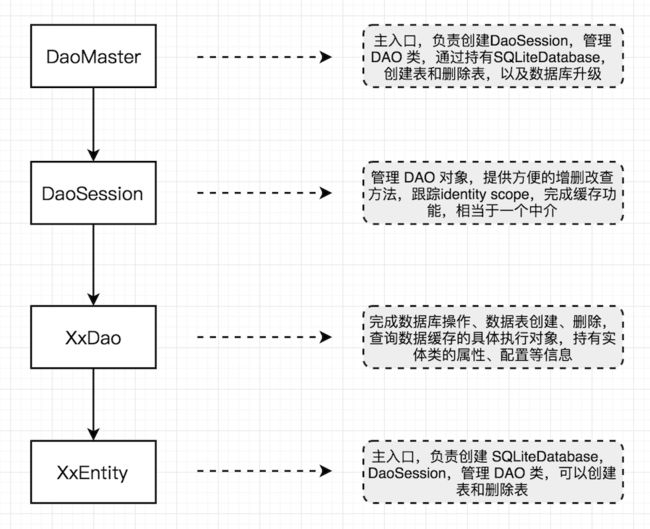
DaoMaster:使用 greenDAO 的切入点。 DaoMaster 保存数据库对象(SQLiteDatabase)并管理特定模式的 DAO 类(而不是对象)。 它有静态方法来创建表或删除它们。 它的内部类 OpenHelper 和 DevOpenHelper 都是 SQLiteOpenHelper 的实现,用来在 SQLite 数据库中创建和升级等操作。
DaoSession:管理特定模式的所有可用 DAO 对象,你可以使用其中一个的 getter 方法获取 DAO 对象。 DaoSession 还为实体提供了一些通用的持久性方法,如插入,加载,更新,刷新和删除。 最后,DaoSession 对象也跟踪 identity scope。
xxDAO:数据访问对象(DAO),用于实体的持久化和查询。 对于每个实体,greenDAO 会生成一个 DAO。 它比 DaoSession 拥有更多的持久化方法,例如:count,loadAll 和 insertInTx。
下面就对着源码具体分析一下这几部分。这里以下面这个实体类为例。
@Entity
public class SampleDBEntity {
@Id(autoincrement = true)
private long id;
@Unique
private String entityId;
private String entityJson;
@Generated(hash = 1099150035)
public SampleDBEntity(long id, String entityId, String entityJson) {
this.id = id;
this.entityId = entityId;
this.entityJson = entityJson;
}
@Generated(hash = 1957180818)
public SampleDBEntity() {
}
public long getId() {
return this.id;
}
public void setId(long id) {
this.id = id;
}
public String getEntityId() {
return this.entityId;
}
public void setEntityId(String entityId) {
this.entityId = entityId;
}
public String getEntityJson() {
return this.entityJson;
}
public void setEntityJson(String entityJson) {
this.entityJson = entityJson;
}
}
DaoMaster
DaoMaster 是 greenDAO 的入口,继承自 AbstractDaoMaster,AbstractDaoMaster 的源码很少,个人理解,DaoMaster 相当于一个 Boss,统领大局,但是具体的工作会交给 DaoSession 和 xxDAO 执行。
1、在 AbstractDaoMaster 中主要持有一个数据库对象 Database,数据库版本 schemaVersion 和 Map
2、registerDaoClass(...) 方法是将 greenDAO 自动生成的具体的 xxDAO 对象添加到上面提到的 map 中,DaoConfig 下面再具体分析。
public abstract class AbstractDaoMaster {
protected final Database db;
protected final int schemaVersion;
protected final Map>, DaoConfig> daoConfigMap;
public AbstractDaoMaster(Database db, int schemaVersion) {
this.db = db;
this.schemaVersion = schemaVersion;
daoConfigMap = new HashMap>, DaoConfig>();
}
protected void registerDaoClass(Class> daoClass) {
DaoConfig daoConfig = new DaoConfig(db, daoClass);
daoConfigMap.put(daoClass, daoConfig);
}
public int getSchemaVersion() {
return schemaVersion;
}
/** Gets the SQLiteDatabase for custom database access. Not needed for greenDAO entities. */
public Database getDatabase() {
return db;
}
public abstract AbstractDaoSession newSession();
public abstract AbstractDaoSession newSession(IdentityScopeType type);
}
分析完父类 AbstractDaoMaster,再来看一下 DaoMaster,首先看构造函数。
1、参数中需要有一个 Database 对象,其中 StandardDatabase 和 EncryptedDatabase 都实现了 Database 接口,从名字也能够看出这两个的区别,EncryptedDatabase 属于加密的数据库。无论 StandardDatabase 还是 EncryptedDatabase,其内部都有一个 Android 原生数据库 SQLiteDatabase 实例 作为代理,这样有了 SQLiteDatabase 实例就可以对数据进行增删改查,所以 greenDAO 是基于 Android 原生数据库的一个封装。
2、构造方法中还需要完成父类中的 registerDaoClass() 方法,在这个方法中,有多少 xxDAO 就注册多少,xxDAO 对应我们使用 @Entity 注解的实体类,这也是 DaoMaster 需要动态生成的原因。registerDaoClass() 方法在父类中,上面我们已经看过。
// 参数需要一个数据库对象
public DaoMaster(SQLiteDatabase db) {
this(new StandardDatabase(db));
}
public DaoMaster(Database db) {
super(db, SCHEMA_VERSION);
registerDaoClass(SampleDBEntityDao.class);
}
DaoMaster 中还有两个静态方法,创建所有的数据表和删除数据表,具体的创建和删除是由 xxDAO 来完成的,其中删除是在数据库升级时会调用。
public static void createAllTables(Database db, boolean ifNotExists) {
SampleDBEntityDao.createTable(db, ifNotExists);
}
public static void dropAllTables(Database db, boolean ifExists) {
SampleDBEntityDao.dropTable(db, ifExists);
}
那么数据库如何升级呢?在 DaoMaster 中还有两个静态辅助类,准确说是一个,其中一个继承另一个。
DevOpenHelper --> OpenHelper -- > DatabaseOpenHelper -- > SQLiteOpenHelper
上面就是继承关系链,最终继承的是 SQLiteOpenHelper,SQLiteOpenHelper 是 Android 原生的数据库操作辅助类,主要用于数据库的创建和版本变更,升级等操作。
DaoMaster 还有一个很重的职责,就是创建 DaoSession,实际上 DaoMaster 这个 Boss 开始将工作交出去了,接下来就交给 DaoSession,需要交代的信息就是上面注册各种 xxDAO 的 daoConfigMap,DaoSession 有了这个信息才能够干活。
public DaoSession newSession() {
return new DaoSession(db, IdentityScopeType.Session, daoConfigMap);
}
public DaoSession newSession(IdentityScopeType type) {
return new DaoSession(db, type, daoConfigMap);
}
DaoSession
DaoSession 对象在 DaoMaster 中创建,会接收 DaoMaster 传过来的 Database 和 Map
public class DaoSession extends AbstractDaoSession {
// DaoSession 拥有对应的 DaoConfig
private final DaoConfig sampleDBEntityDaoConfig;
// DaoSession 持有 xxDAO
private final SampleDBEntityDao sampleDBEntityDao;
public DaoSession(Database db, IdentityScopeType type, Map>, DaoConfig>
daoConfigMap) {
super(db);
sampleDBEntityDaoConfig = daoConfigMap.get(SampleDBEntityDao.class).clone();
sampleDBEntityDaoConfig.initIdentityScope(type);
// 注册 xxDAO
registerDao(SampleDBEntity.class, sampleDBEntityDao);
}
}
构造方法最后还有一个注册方法,registerDao(),它是父类 AbstractDaoSession 的一个方法,是将实体类和对应的 xxDAO 注册到父类的一个 Map
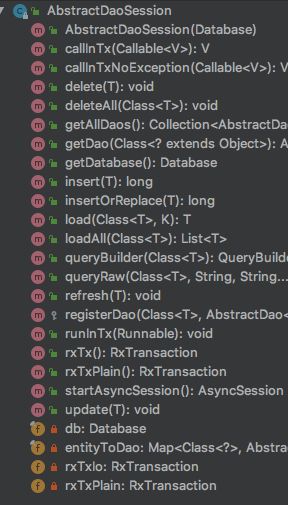
为什么说是方便的,一是 DaoSession 中操作数据库的方法不全,仅仅给出一个操作接口;二是方法中具体的操作还是交给 xxDAO 去完成。我们看一个插入方法。
public long insert(T entity) {
@SuppressWarnings("unchecked")
AbstractDao dao = (AbstractDao) getDao(entity.getClass());
return dao.insert(entity);
}
这也就知道为什么还要有一个 registerDao() 方法,就是需要持有 xxDAO,然后调用 xxDAO 完成增删改查,xxDAO 中有操作数据更多的方法,DaoSession 仅仅是提供一些方便的入口。所以,可以看出 DaoSession 也相当与 Boss 手下的一个 Leader,也会参与一些事物,但是干活的还是最底层的员工 xxDAO,哈哈哈!
xxDAO
xxDAO 是底层干活的,那么就来它是如何漂亮的完成工作的。
/** Creates the underlying database table. */
public static void createTable(Database db, boolean ifNotExists) {
String constraint = ifNotExists? "IF NOT EXISTS ": "";
db.execSQL("CREATE TABLE " + constraint + "\"SAMPLE_DBENTITY\" (" + //
"\"_id\" INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL ," + // 0: id
"\"ENTITY_ID\" TEXT UNIQUE ," + // 1: entityId
"\"ENTITY_JSON\" TEXT);"); // 2: entityJson
}
/** Drops the underlying database table. */
public static void dropTable(Database db, boolean ifExists) {
String sql = "DROP TABLE " + (ifExists ? "IF EXISTS " : "") + "\"SAMPLE_DBENTITY\"";
db.execSQL(sql);
}
1、这两个方法在 DaoMaster 中见过,这是 Boss 交给的任务,必须完成,数据表的创建和删除,也是通过 Android 原生的 Database。
2、xxDAO 构造函数中有一个参数 DaoConfig,这里就来看下 DaoConfig 中有哪些信息。
// 原生数据库 db
public final Database db;
// 数据库表名
public final String tablename;
// 实体类每个变量对应的 Property
public final Property[] properties;
// 所有字段名,主键字段名,非主键字段名
public final String[] allColumns;
public final String[] pkColumns;
public final String[] nonPkColumns;
// 主键属性
public final Property pkProperty;
// 主键是否是数字
public final boolean keyIsNumeric;
// 用来将对象转成数据库的字段的辅助类
public final TableStatements statements;
// 用来进行缓存的接口
private IdentityScope identityScope;
DaoConfig 中有表名,实体类每个变量对应的 Property,所有存储的字段名,主键字段和非主键字段,用来将对象转成数据库的字段的辅助类 TableStatements 和用来进行缓存的接口 IdentityScope。
SQLite 是一个关系数据库,Java 对象要存到数据库中需要进行转换,TableStatements 中的 DatabaseStatement 提供了这个作用。转换过程也不复杂,数据库的列对应 Java 对象里的参数就行。DatabaseStatement 有两个比较关键的作用:
- 将实体类对象中的参数转成数据库中的字段
- 将拼接的数据库的增删改查语句保存下来
public class TableStatements {
...
private DatabaseStatement insertStatement;
private DatabaseStatement insertOrReplaceStatement;
private DatabaseStatement updateStatement;
private DatabaseStatement deleteStatement;
private DatabaseStatement countStatement;
...
}
可以看到 TableStatements 有多个 DatabaseStatement,每个 DatabaseStatement 对应一种操作。那么 DatabaseStatement是如何保存 sql 语句和对应的字段值呢?其实 DatabaseStatement 是一个接口,和上面讲到的 Database 接口一样,也是有两个实现 StandardDatabaseStatement 和 EncryptedDatabaseStatement,这两个实现中都有一个代理 SQLiteStatement,SQLiteStatement 是封装了对数据库操作和相关数据的对象,由原生 Android 提供的,这样就又回到了原生 Android 的 SQLite 的操作,SQLiteStatement 继承 SQLiteProgram,从 SQLiteProgram 的变量中看到 mSql 和 mBindArgs,mBindArgs 用来保存实体类中的对应的参数值,mSql 就是执行的数据库的原生语句。所以这里看出数据库的操作由 DatabaseStatement 来完成,DatabaseStatement 的子类有 StandardDatabaseStatement 和 EncryptedDatabaseStatement,他们由交给其内部的代理 SQLiteStatement,这样就回到了原生 Android 的SQLite 操作。
public abstract class SQLiteProgram extends SQLiteClosable {
private final SQLiteDatabase mDatabase;
private final String mSql;
private final boolean mReadOnly;
private final String[] mColumnNames;
private final int mNumParameters;
private final Object[] mBindArgs;
...
}
下面我们以插入操作,看下具体的流程。
insert 流程分析
1、通过上面的分析,知道 AbstractDaoSession 中有方便的增删改查,那就从这里开始
/** Convenient call for {@link AbstractDao#insert(Object)}. */
public long insert(T entity) {
@SuppressWarnings("unchecked")
AbstractDao dao = (AbstractDao) getDao(entity.getClass());
return dao.insert(entity);
}
2、AbstractDaoSession 中的 insert 操作交给 xxDAO 来执行。执行过程也不复杂,涉及到线程安全,执行过程实际上就是两个对象,实体类对象和上面提到的 DatabaseStatement insertStatement 对象。DatabaseStatement 对象的获取在步骤一中通过调用 TableStatements 的 getInsertStatement() 方法获取。
// 步骤一
public long insert(T entity) {
return executeInsert(entity, statements.getInsertStatement(), true);
}
// 步骤二
private long executeInsert(T entity, DatabaseStatement stmt, boolean setKeyAndAttach) {
long rowId;
if (db.isDbLockedByCurrentThread()) {
rowId = insertInsideTx(entity, stmt);
} else {
// Do TX to acquire a connection before locking the stmt to avoid deadlocks
db.beginTransaction();
try {
// 插入操作
rowId = insertInsideTx(entity, stmt);
db.setTransactionSuccessful();
} finally {
db.endTransaction();
}
}
if (setKeyAndAttach) {
updateKeyAfterInsertAndAttach(entity, rowId, true);
}
return rowId;
}
// 步骤三
private long insertInsideTx(T entity, DatabaseStatement stmt) {
synchronized (stmt) {
// 正常情况下我们使用的是 StandardDatabase 或者 EncryptedDatabase
// 没有使用原生的 SQLiteDatabase,所以 isStandardSQLite = false
if (isStandardSQLite) {
SQLiteStatement rawStmt = (SQLiteStatement) stmt.getRawStatement();
bindValues(rawStmt, entity);
return rawStmt.executeInsert();
} else {
// 正常走这里
bindValues(stmt, entity);
return stmt.executeInsert();
}
}
}
3、TableStatements 中获取插入的 DatabaseStatement,是一个单例模式,通过 SqlUtils 拼接数据库插入语句,最终保存到 mSql 中,得到的是 DatabaseStatement 的接口实现 StandardDatabaseStatement 或者 EncryptedDatabaseStatement,EncryptedDatabaseStatement 是加密数据库时用到的。
public DatabaseStatement getInsertStatement() {
if (insertStatement == null) {
String sql = SqlUtils.createSqlInsert("INSERT INTO ", tablename, allColumns);
DatabaseStatement newInsertStatement = db.compileStatement(sql);
synchronized (this) {
if (insertStatement == null) {
insertStatement = newInsertStatement;
}
}
if (insertStatement != newInsertStatement) {
newInsertStatement.close();
}
}
return insertStatement;
}
4、有了 DatabaseStatement,如何将实体类参数转换到数据库中的字段呢?看步骤三中的 bindValues(stmt, entity) 方法,这个方法就是转换过程。它是 AbstractDao 中的一抽象方法,由子类 xxDAO 来实现。这个过程也比较简单,根据实体类中参数类型,调用 DatabaseStatement 对应的 bindXX 方法,通过上面 DatabaseStatement 的分析,知道最终是调用 SQLiteStatement 的 bind 方法,将实体类的所有字段保存到 mBindArgs 数组中。
@Override
protected final void bindValues(DatabaseStatement stmt, SampleDBEntity entity) {
stmt.clearBindings();
stmt.bindLong(1, entity.getId());
String entityId = entity.getEntityId();
if (entityId != null) {
stmt.bindString(2, entityId);
}
String entityJson = entity.getEntityJson();
if (entityJson != null) {
stmt.bindString(3, entityJson);
}
}
5、执行插入数据过程,步骤三中 stmt.executeInsert() 方法。当然了,实际操作还是由 SQLiteStatement 这个代理来完成,执行插入过程也应该是它,下面的就是执行的过程,获取执行语句 mSql 和 保存的值 mBindArgs,然后就是执行 SQL 原生语句,这里就不具体分析了。
public long executeInsert() {
acquireReference();
try {
return getSession().executeForLastInsertedRowId(
getSql(), getBindArgs(), getConnectionFlags(), null);
} catch (SQLiteDatabaseCorruptException ex) {
onCorruption();
throw ex;
} finally {
releaseReference();
}
}
小结:上面就是插入语句的详细过程,开始调用 DaoSession 的 insert 方法,实际由 xxDAO 来执行,具体是由哪一个 xxDAO,通过 getDao(entity.getClass()) 来获取,因为在创建 DaoSession 时我们已经注册过所有的 xxDAO;接着 xxDAO 通过其内部的 DaoConfig 获取到 DatabaseStatement,最终交给 DatabaseStatement 去执行,实际上就像是一层一层代理的过程。
数据缓存
上面在创建 DaoSession,提到一个参数 IdentityScopeType,现在来看下这个参数。它是一个枚举类型,有两种类型, Session 和 None,Session 标识使用缓存,None 不适用缓存,每次查询时都从数据库中读取。默认情况下是使用缓存的。
public enum IdentityScopeType {
Session, None
}
创建 DaoSession 时,会获取相应的 DaoConfig,然后调用 initIdentityScope 方法来设置缓存,设置缓存依据的原则是如果主键是数字类型的,使用数字类型缓存 IdentityScopeLong,其次使用 IdentityScopeObject 类型缓存。
public void initIdentityScope(IdentityScopeType type) {
if (type == IdentityScopeType.None) {
identityScope = null;
} else if (type == IdentityScopeType.Session) {
if (keyIsNumeric) {
identityScope = new IdentityScopeLong();
} else {
identityScope = new IdentityScopeObject();
}
} else {
throw new IllegalArgumentException("Unsupported type: " + type);
}
}
缓存的机制也比较简单,通过 Map 来保存主键和实体类,操作也就是 get 和 put 方法,分为加锁和为加锁版本,IdentityScopeLong 和 IdentityScopeObject 实现了同一个接口 IdentityScope,具体实现就不分析了。
public interface IdentityScope {
T get(K key);
void put(K key, T entity);
T getNoLock(K key);
void putNoLock(K key, T entity);
boolean detach(K key, T entity);
void remove(K key);
void remove(Iterable key);
void clear();
void lock();
void unlock();
void reserveRoom(int count);
}
数据查询与缓存
缓存一般用在数据查询时,下面来看下,在进行数据查询时,看看缓存是如何工作的。直接看 AbstractDao 的 load 方法。
1、如果设置了缓存,并且不是第一次查找,则直接从缓存中取出数据 identityScope.get(key)
public T load(K key) {
assertSinglePk();
if (key == null) {
return null;
}
if (identityScope != null) {
T entity = identityScope.get(key);
if (entity != null) {
return entity;
}
}
String sql = statements.getSelectByKey();
String[] keyArray = new String[]{key.toString()};
Cursor cursor = db.rawQuery(sql, keyArray);
return loadUniqueAndCloseCursor(cursor);
}
2、设置缓存,并且是第一次查询,此时还没有缓存,需要从数据库中查询,然后在存入缓存。上面代码中先从 statements 中拿到数据库查询语句和查询的主键,交给 rawQuery 查询,得到Cursor。通过主键查询,如果数据存在,则查到的数据是唯一的。loadUniqueAndCloseCursor 调用 loadUnique,最终调用 loadCurrent。loadCurrent 会先尝试从缓存里获取数据,如果没有读取到,则从游标中取数据,然后再存储到缓存中,代码虽然有点长,但是逻辑还是相对简单的。
final protected T loadCurrent(Cursor cursor, int offset, boolean lock) {
// (1) 如果是数字主键缓存的数据,先从数字主键的缓存中取数据,速度更快
if (identityScopeLong != null) {
if (offset != 0) {
// Occurs with deep loads (left outer joins)
if (cursor.isNull(pkOrdinal + offset)) {
return null;
}
}
long key = cursor.getLong(pkOrdinal + offset);
T entity = lock ? identityScopeLong.get2(key) : identityScopeLong.get2NoLock(key);
if (entity != null) {
return entity;
} else {
entity = readEntity(cursor, offset);
attachEntity(entity);
if (lock) {
identityScopeLong.put2(key, entity);
} else {
identityScopeLong.put2NoLock(key, entity);
}
return entity;
}
}
// (2) 尝试从 IdentityScopeObject 获取,获取到就返回
// 如果没有获取到,就先从游标中读取,然后通过 attachEntity(key, entity, lock) 方法存储到缓存中
else if (identityScope != null) {
K key = readKey(cursor, offset);
if (offset != 0 && key == null) {
// Occurs with deep loads (left outer joins)
return null;
}
T entity = lock ? identityScope.get(key) : identityScope.getNoLock(key);
if (entity != null) {
return entity;
} else {
entity = readEntity(cursor, offset);
attachEntity(key, entity, lock);
return entity;
}
}
// (3)没有缓存,只能通过游标读取数据库
else {
// Check offset, assume a value !=0 indicating a potential outer join, so check PK
if (offset != 0) {
K key = readKey(cursor, offset);
if (key == null) {
// Occurs with deep loads (left outer joins)
return null;
}
}
T entity = readEntity(cursor, offset);
attachEntity(entity);
return entity;
}
}
条件查询
QueryBuilder 使用链式结构构建 Query,灵活地支持 where、or、join、distinct、limit 等约束的添加。构建 Query 后通过调用 list() 或 lazeList 方法就可以进行查询,这些条件最终会拼接成 sql 语句,最后通过 SQLiteDatabase 执行数据库语句得到游标 Cursor,然后调用 AbstractDao 的 loadAllFromCursor。也可以通过 Query 的 unique 操作查询数据,这个操作和上面的 load 一样。
protected List loadAllFromCursor(Cursor cursor) {
int count = cursor.getCount();
if (count == 0) {
return new ArrayList();
}
List list = new ArrayList(count);
CursorWindow window = null;
boolean useFastCursor = false;
// (1) 获取 Android 提供的 CursorWindow,构造快速查询 Cursor
if (cursor instanceof CrossProcessCursor) {
window = ((CrossProcessCursor) cursor).getWindow();
if (window != null) { // E.g. Robolectric has no Window at this point
if (window.getNumRows() == count) {
cursor = new FastCursor(window);
useFastCursor = true;
} else {
DaoLog.d("Window vs. result size: " + window.getNumRows() + "/" + count);
}
}
}
// (2) 遍历游标查询结果数据集
if (cursor.moveToFirst()) {
if (identityScope != null) {
identityScope.lock();
identityScope.reserveRoom(count);
}
try {
if (!useFastCursor && window != null && identityScope != null) {
loadAllUnlockOnWindowBounds(cursor, window, list);
} else {
do {
list.add(loadCurrent(cursor, 0, false));
} while (cursor.moveToNext());
}
} finally {
if (identityScope != null) {
identityScope.unlock();
}
}
}
return list;
}
(1) 处尝试使用 Android 提供的 CursorWindow 以获取一个更快的 Cursor。SQLiteDatabase 将查询结果保存在 CursorWindow 所指向的共享内存中,然后通过 Binder 把这片共享内存传递到查询端。
(2) 处通过移动 Cursor,利用 loadCurrent 进行批量操作,结果保存在List中返回。
总结
理解了 DaoMaster、DaoSession、xxDAO 这个几个类, greenDAO 也就基本理解了,这里给出一个比喻,DaoMaster 相当于一个 Boss,统领大局,但是具体的工作会交给 DaoSession, DaoSession 相当于一个 Leader,会负责管理一些 xxDAO,当然也可以有多个 DaoSession,DaoSession 会提供数据库操作的一些方便的入口方法,其内部具体的执行会交给 xxDAO 执行,xxDAO 负责自己对应的实体类对象的增删改查,其中执行过程中需要 DaoConfig 和 DatabaseStatement,拿到拼接的 sql 语句和要存储的实体类的参数值,最终会通过原生数据库完成操作,基本就是这样一个过程,可以理解为职责一步步向下传递的过程。
参考
greenDAO
Android | 分析greenDAO 3.2实现原理