思路
搜狗搜索还有一个非常重要的功能就是对接微信接口。这也是爬虫获取微信文章/公众号的主要途径之一。根据我在网上找到的信息,除了网页接口,至少还有两种方法可以抓取微信文章:
- 微信网页版接口
- 微信手机端,通过订阅要抓取的公众号来获得及时的信息
这两种目前我没试过,有机会看看能不能操作一下。
URL结构
URL的格式和搜狗搜索差不多,不过多了几个过滤字段,简单试一试就能得到,这里就不都列出来了。
搜狗微信的反爬虫
搜狗微信的反爬虫机制和搜狗搜索的原理是一样的,只是更加的苛刻。苛刻在两点:
- 同个Cookie可访问的次数减少了。少到多少具体的值我没测出来,目前我是每40次更新一次Cookie,然后每次抓取后休息8-10秒。测下来效果还可以。但是偶尔也会进入反爬虫流程。
- 第二点是我的感觉,不确定。似乎搜狗一旦怀疑你是爬虫,就会更加频繁的要求你输入验证码。
如何低成本且稳定的抓取搜狗微信文章/公众号
如果要批量抓取搜狗微信文章/公众号,我以为最少需要四个模块:一个待爬取的URL队列、有效的Cookie池、代理IP池和一个后端数据库用于存储抓取结果。当然也要有其他的如日志、预警、去重、监控等辅助模块,以及一个调度器。大概的逻辑框架是这样的:
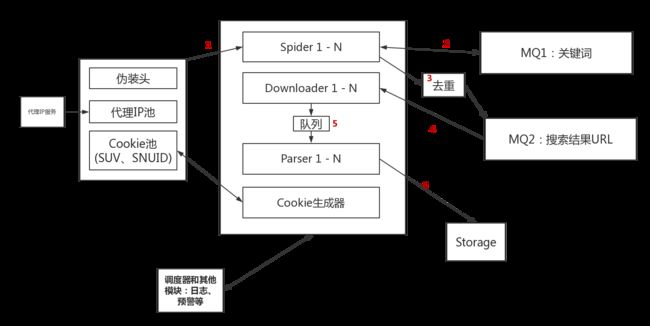
那么它大概的流程是这样的:
- 首先我们需要一些关键词作为种子,放入消息队列MQ1中。这些关键词可以自己抓,也可以直接提供。
- 假设有N个Spider,每个Spider在启动之后会先获取伪装信息、一个代理IP和一个Cookie(包含一对有效的
SUV和SNUID)。然后从关键词消息队列MQ1中拿到一个关键词,先对其进行预处理:获取这个关键词所有搜索结果的总页数和其相关的关键词。前者就是这个Spider所要执行的抓取任务,后者则会被添加到MQ1中供其他Spider继续使用。Spider每隔大约10秒钟进行一次抓取,一旦抓取次数达到阈值或触发反爬虫机制,就重新获取一个代理IP和一个新的Cookie。爬取到的搜索结果的URL在去重后会被放入另一个消息队列MQ2。 - Downloader从MQ2中提取结果的URL,然后将网页内容下载下来,解析器Parser会根据页面的内容进行相应的处理,然后保存到数据库中。
- 另外在这个项目中,Cookie生成器会对Cookie池进行监控,需要保证Cookie池中拥有足量的有效
SUV和SNUID。 - 其他关于日志、预警、监控、调度就略过了。
再说说细节(纸上谈兵):
性能评估
假设现在代理IP池大小为100,不考虑机器的负担,理论上最多可以有100个Spider并行。如果一个Spider每隔10s抓取一次的话(经过我的测试这个间隔最好是在8-10s之间。),相当于大概一分钟6次,一小时360次,一天大概8640次。100个的话,一天大概就是864000次,即使有些请求失败,85W次也是有的。
另外一条请求中,可以解析出8-12条搜索结果。
Spider/Downloader/Parser
这样划分其实只是逻辑上的区分,实际上完全可以一个模块直接完成提取关键词、增加相关搜索词、下载、解析、去重、写入数据库等所有任务。这样写的话,为了最大化效率,之后可以调整每种Worker的数量。
MQ1、MQ2和去重
MQ1、MQ2可以直接使用Redis队列,去重的话则可以通过BloomFilter+Redis来实现。一般一个8G的机器就能保证大概30亿记录的去重任务,误差率不会超过万分之一,完全够用。
Cookies池 - 实际测试过
Cookie池是抓取搜狗微信最重要的一环。根据我的测试,包括后面关于验证码处理的部分我也会解释,其实在诸多Cookie值中真正有用的只有SUV和SNUID。获取新Cookie有两种方法:
- 用一个干净的IP访问任意搜狗微信的搜索页面,将返回的Cookie保存下来。
- 触发并通过反爬虫机制,通过后会得到一个新的Cookie。
为了让Spider保持高效的工作,我的建议是构建一个Cookie池,在池中保存一定量的有效SUV和SNUID值,一旦Spider请求的次数到达阈值(比如说40次),就从池中拿一个新的Cookie继续爬取。
第一种获取新Cookie的方法很简单,这里重点说下第二种,如何处理验证码。
验证码的处理
嫌麻烦可以直接跳到后面整个流程和自动化破解的章节。
一旦触发了反爬虫,页面就会自动跳转到一个验证码的页面:
http://weixin.sogou.com/antispider/?
from=%2fweixin%3Ftype%3d2%26query%3d%E6%97%A5%E6%9C%AC%E5%A4%A7%E9%98%AA%E5%9C%B0%E9%9C%87
和搜狗搜索类似,from后面是你触发反爬虫之前访问的URL,不同的是,这里再URL之前加了%2f。你可以通过类似
if 'antispider' in req.url or '请输入验证码' in req.text:
的代码来判断是否触发了反爬虫机制。触发之后的页面是这样的:

现在我们分析一下整个验证码的交互流程。通过抓包分析,很容易发现在提交正确的验证码后,浏览器会发送一个名为thank.php的请求,关于这个请求的生成可以在static/js/index.min.js?v=0.1.4"中找到:
//static/js/index.min.js?v=0.1.4
function h() {
var a = $("#error-tips"),
b = k.val();
/^[\da-zA-Z]{6}$/.test(b) ? $.ajax({
type: "POST",
url: "thank.php",
data: {
c: b,
r: $("#from").val(),
v: 5
},
dataType: "json",
success: l,
error: n
}) : (a.html("\u9a8c\u8bc1\u7801\u8f93\u5165\u9519\u8bef\uff0c\u8bf7\u91cd\u65b0\u8f93\u5165"), a.show());
k.val("")
}
这里可以看到,在对验证码做了简单的正则校验后(是不是6位)。会触发一个ajax请求,类型是POST;URL是http://weixin.sogou.com/antispider/thank.php;带的参数有三个:c就是你输入的验证码、r是触发反爬虫之前的页面URL、v是某个版本,不重要。POST请求会返回一个json对象,成功的话,会调用一个名为l的方法。注意这里即使验证码是错误的,但是这条请求是成功的,因此仍然会调用l方法。那么接下来看下l方法,它在同一个js文件中:
//static/js/index.min.js?v=0.1.4
function l(a) {
var b = a.code,
d = $("#error-tips"),
e = new Date,
f = location.hostname,
g = "sogou.com"; - 1 < f.indexOf("sogo.com") ? g = "sogo.com" : "snapshot.sogoucdn.com" === f && (g = "snapshot.sogoucdn.com");
if (0 === b || 1 === b) getCookie("SUV") || setCookie("SUV", 1E3 * e.getTime() + Math.round(1E3 * Math.random()), "Sun, 29 July 2046 00:00:00 UTC", g, "/"), e.setTime(e.getTime() + 31536E6), setCookie("SNUID", a.id, e.toGMTString(), g, "/");
switch (b) {
//.........
}
}
可以看到,这里其实是对SUV和SNUID两个值进行了操作。新的SUV值等于1E3 * e.getTime() + Math.round(1E3 * Math.random(),新的SNUID等于a.id。
setCookie方法在另一个文件中,不过没什么特别的地方:
//static/js/antispider.min.js?v=2
function setCookie(a, b, c, d, e) {
if (a && b) return a = [a, "=", b], c && a.push(";expires=", c), d && a.push(";domain=", d), e && a.push(";path=", e), document.cookie = a.join(""), a.join("")
}
再来看下thank.php这个异步请求的返回内容,上文说过,它是一个json对象,如果你输入了正确的验证码:
{"code": 0,"msg": "解封成功,正在为您跳转来源地址...", "id": "AE4869A0E6E389E9261E1177E6734EA7"}
如果验证码错误,code和msg的值都会改变,而第三个id的值就是新的SNUID的值。
到这里,其实流程就很清晰了,不过在页面的源代码里,还有一段js可以提供一些信息:
function() {
function checkSNUID() {
var cookieArr = document.cookie.split('; '),
count = 0;
for(var i = 0, len = cookieArr.length; i < len; i++) {
if (cookieArr[i].indexOf('SNUID=') > -1) {
count++;
}
}
return count > 1;
}
if(checkSNUID()) {
var date = new Date(), expires;
date.setTime(date.getTime() -100000);
expires = date.toGMTString();
document.cookie = 'SNUID=1;path=/;expires=' + expires;
document.cookie = 'SNUID=1;path=/;expires=' + expires + ';domain=.www.sogo.com';
document.cookie = 'SNUID=1;path=/;expires=' + expires + ';domain=.weixin.sogo.com';
document.cookie = 'SNUID=1;path=/;expires=' + expires + ';domain=.sogo.com';
document.cookie = 'SNUID=1;path=/;expires=' + expires + ';domain=.www.sogou.com';
document.cookie = 'SNUID=1;path=/;expires=' + expires + ';domain=.weixin.sogou.com';
document.cookie = 'SNUID=1;path=/;expires=' + expires + ';domain=.sogou.com';
document.cookie = 'SNUID=1;path=/;expires=' + expires + ';domain=.snapshot.sogoucdn.com';
sendLog('delSNUID');
}
整个流程
这里可以看到,整个流程大概是这样的:
- 检查原本Cookie中是否包含
SNUID字段,如果有,删除。 - 当用户点击提交时,校验用户的输入是否是6位的字母数字组合,不是的话直接报错。是的话,发送一条URL是
thank.php的XHR,其中包含用户输入的验证码、跳转之前的页面内容等。 - 解析服务器返回的json对象,如果验证码是正确的,则更新
SUV和SNUID的值。否则会在页面上展示相应的错误信息。
自动化破解
我直接给出相应的Python 3.6的代码,这里我采用的是手工输入验证码,你也可以很容易的接入其他打码平台:
def unlock(antiurl, oldcookies):
retries = 0
while retries < 3:
r = requests.ohRequests()
tc = int(round(time.time() * 1000))
captcha = r.get('http://weixin.sogou.com/antispider/util/seccode.php?tc={}'.format(tc), cookies=oldcookies)
with open('captcha.jpg', 'wb') as file:
file.write(captcha.content)
c = input("请输入captcha.jpg中的验证码:")
thank_url = 'http://weixin.sogou.com/antispider/thank.php'
formdata = {
'c': c,
'r': '%2F' + antiurl,
'v': 5
}
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Referer': 'http://weixin.sogou.com/antispider/?from=%2f' + antiurl
}
resp = r.post(thank_url, data=formdata, headers=headers, cookies=oldcookies)
resp = json.loads(resp.text)
if resp.get('code') != 0:
print ("解锁失败。重试次数:{0:d}".format(3-retries))
retries += 1
continue
oldcookies['SNUID'] = resp.get('id')
oldcookies['SUV'] = '00D80B85458CAE4B5B299A407EA3A580'
#print ("更新Cookies。", oldcookies)
return oldcookies
到这里也许有人会问,为什么SUV是直接给的,而不是获取的。其实可以获取,执行一下这样的js代码就行:
function getSUV(){
e = new Date;
return 1E3 * e.getTime() + Math.round(1E3 * Math.random())
}
最后这SUV的值是MD5(getSUV())。1E3就是1乘10的三次方即1000,Math.random()是一个0-1的小数,那么Math.round(1E3 * Math.random())就是一个0-1000的整数,e.getTime()会是一个类似1540996915223的整数,然后乘以1000,再加上之前那个0-1000的整数,得到一个类似1540996915223XXX的数。
个人认为这里直接写死也没事,但是爬虫的原则之一就是尽量模拟真实的用户行为,所以看着办就行了。