本文基于Spark2.1.0版本
套用官文Tuning Spark中的一句话作为文章的标题:
*Often, choose a serialization type will be the first thing you should tune to optimize a Spark application. *
在Spark的架构中,在网络中传递的或者缓存在内存、硬盘中的对象需要进行序列化操作,序列化的作用主要是利用时间换空间:
- 分发给Executor上的Task
- 需要缓存的RDD(前提是使用序列化方式缓存)
- 广播变量
- Shuffle过程中的数据缓存
- 使用receiver方式接收的流数据缓存
- 算子函数中使用的外部变量
上面的六种数据,通过Java序列化(默认的序列化方式)形成一个二进制字节数组,大大减少了数据在内存、硬盘中占用的空间,减少了网络数据传输的开销,并且可以精确的推测内存使用情况,降低GC频率。
其好处很多,但是缺陷也很明显:
- 把数据序列化为字节数组、把字节数组反序列化为对象的操作,是会消耗CPU、延长作业时间的,从而降低了Spark的性能。
至少默认的Java序列化方式在这方面是不尽如人意的。Java序列化很灵活但性能较差,同时序列化后占用的字节数也较多。
所以官方也推荐尽量使用Kryo的序列化库(版本2)。官文介绍,Kryo序列化机制比Java序列化机制性能提高10倍左右,Spark之所以没有默认使用Kryo作为序列化类库,是因为它不支持所有对象的序列化,同时Kryo需要用户在使用前注册需要序列化的类型,不够方便。
由于 Spark2.1.0默认对Task使用Java序列化(该序列化方式不允许修改,源码如下),
/**
* Helper method to create a SparkEnv for a driver or an executor.
*/
private def create(
conf: SparkConf,
executorId: String,
bindAddress: String,
advertiseAddress: String,
port: Int,
isLocal: Boolean,
numUsableCores: Int,
ioEncryptionKey: Option[Array[Byte]],
listenerBus: LiveListenerBus = null,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {
val isDriver = executorId == SparkContext.DRIVER_IDENTIFIER
...
val serializer = instantiateClassFromConf[Serializer](
"spark.serializer", "org.apache.spark.serializer.JavaSerializer")
logDebug(s"Using serializer: ${serializer.getClass}")
val serializerManager = new SerializerManager(serializer, conf, ioEncryptionKey)
val closureSerializer = new JavaSerializer(conf) --Task闭包函数使用Java序列化库
所以本文主要针对下面这五种数据类型:
- 需要缓存的RDD(前提是使用序列化方式缓存)
- 广播变量
- Shuffle过程中的数据缓存
- 使用receiver方式接收的流数据缓存
- 算子函数中使用的外部变量
其实从Spark 2.0.0版本开始,简单类型、简单类型数组、字符串类型的Shuffling RDDs 已经默认使用Kryo序列化方式了。
下面,我给出具体的流程,来切换到Kryo序列化库。
先介绍几个相关的配置:
| Property Name | Default | Meaning |
|---|---|---|
| spark.serializer | org.apache.spark.serializer.JavaSerializer | Class to use for serializing objects that will be sent over the network or need to be cached in serialized form. The default of Java serialization works with any Serializable Java object but is quite slow, so we recommend using org.apache.spark.serializer.KryoSerializer and configuring Kryo serialization when speed is necessary. |
| spark.kryoserializer.buffer | 64k | Initial size of Kryo's serialization buffer. Note that there will be one buffer per core on each worker. This buffer will grow up to spark.kryoserializer.buffer.max if needed. |
| spark.kryoserializer.buffer.max | 64m | Maximum allowable size of Kryo serialization buffer. This must be larger than any object you attempt to serialize. Increase this if you get a "buffer limit exceeded" exception inside Kryo. |
| spark.kryo.classesToRegister | (none) | If you use Kryo serialization, give a comma-separated list of custom class names to register with Kryo. See the tuning guide for more details. |
| spark.kryo.referenceTracking | true | Whether to track references to the same object when serializing data with Kryo, which is necessary if your object graphs have loops and useful for efficiency if they contain multiple copies of the same object. Can be disabled to improve performance if you know this is not the case. |
| spark.kryo.registrationRequired | false | Whether to require registration with Kryo. If set to 'true', Kryo will throw an exception if an unregistered class is serialized. If set to false (the default), Kryo will write unregistered class names along with each object. Writing class names can cause significant performance overhead, so enabling this option can enforce strictly that a user has not omitted classes from registration. |
| spark.kryo.registrator | (none) | If you use Kryo serialization, give a comma-separated list of classes that register your custom classes with Kryo. This property is useful if you need to register your classes in a custom way, e.g. to specify a custom field serializer. Otherwise spark.kryo.classesToRegister is simpler. It should be set to classes that extend KryoRegistrator. See the tuning guide for more details. |
| spark.kryo.unsafe | false | Whether to use unsafe based Kryo serializer. Can be substantially faster by using Unsafe Based IO. |
配置说明:(当使用Kryo序列化库时)
spark.kryo.classesToRegister:向Kryo注册自定义的的类型,类名间用逗号分隔
spark.kryo.referenceTracking:跟踪对同一个对象的引用情况,这对发现有循环引用或同一对象有多个副本的情况是很有用的。设置为false可以提高性能
spark.kryo.registrationRequired:是否需要在Kryo登记注册?如果为true,则序列化一个未注册的类时会抛出异常
spark.kryo.registrator:为Kryo设置这个类去注册你自定义的类。最后,如果你不注册需要序列化的自定义类型,Kryo也能工作,不过每一个对象实例的序列化结果都会包含一份完整的类名,这有点浪费空间
spark.kryo.unsafe:如果想更加提升性能,可以使用Kryo unsafe方式
spark.kryoserializer.buffer:每个Executor中的每个core对应着一个序列化buffer。如果你的对象很大,可能需要增大该配置项。其值不能超过spark.kryoserializer.buffer.max
spark.kryoserializer.buffer.max:允许使用序列化buffer的最大值
spark.serializer:序列化时用的类,需要申明为org.apache.spark.serializer.KryoSerializer。这个设置不仅控制各个worker节点之间的混洗数据序列化格式,同时还控制RDD存到磁盘上的序列化格式及广播变量的序列化格式。
更多的Kryo配置及使用细节,参考文末的链接
主要的使用过程就三步:
- 设置序列化使用的库
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer"); //使用Kryo序列化库
- 在该库中注册用户定义的类型
conf.set("spark.kryo.registrator", toKryoRegistrator.class.getName()); //在Kryo序列化库中注册自定义的类集合
- 在自定义类中实现KryoRegistrator接口的registerClasses方法
public static class toKryoRegistrator implements KryoRegistrator {
public void registerClasses(Kryo kryo) {
kryo.register(tmp1.class, new FieldSerializer(kryo, tmp1.class)); //在Kryo序列化库中注册自定义的类
kryo.register(tmp2.class, new FieldSerializer(kryo, tmp2.class)); //在Kryo序列化库中注册自定义的类
}
}
具体的源码如下(关键点见源码中的注释):
import java.util.Arrays;
import java.util.Iterator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.serializer.KryoRegistrator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.serializers.FieldSerializer;
import org.apache.spark.storage.StorageLevel;
import java.util.regex.Pattern;
import java.io.IOException;
import java.io.InputStream;
import java.io.FileInputStream;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.spark.broadcast.Broadcast;
public final class javakryoserializer {
private static final Pattern SPACE = Pattern.compile(" ");
// This is our custom class we will configure Kyro to serialize
static class tmp1 implements java.io.Serializable {
public int total_;
public int num_;
}
static class tmp2 implements java.io.Serializable {
public tmp2 (String ss)
{
s = ss;
}
public String s;
}
public static class toKryoRegistrator implements KryoRegistrator {
public void registerClasses(Kryo kryo) {
kryo.register(tmp1.class, new FieldSerializer(kryo, tmp1.class)); //在Kryo序列化库中注册自定义的类
kryo.register(tmp2.class, new FieldSerializer(kryo, tmp2.class)); //在Kryo序列化库中注册自定义的类
}
}
public static void readToBuffer(StringBuffer buffer, String filePath) throws IOException {
InputStream is = new FileInputStream(filePath);
String line; // 用来保存每行读取的内容
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
line = reader.readLine(); // 读取第一行
while (line != null) { // 如果 line 为空说明读完了
buffer.append(line); // 将读到的内容添加到 buffer 中
buffer.append("\n"); // 添加换行符
line = reader.readLine(); // 读取下一行
}
reader.close();
is.close();
}
public static void main(String[] args) throws Exception {
SparkConf conf = new SparkConf().setMaster("local").setAppName("basicavgwithkyro");
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer"); //使用Kryo序列化库,如果要使用Java序列化库,需要把该行屏蔽掉
conf.set("spark.kryo.registrator", toKryoRegistrator.class.getName()); //在Kryo序列化库中注册自定义的类集合,如果要使用Java序列化库,需要把该行屏蔽掉
JavaSparkContext sc = new JavaSparkContext(conf);
StringBuffer sb = new StringBuffer();
javakryoserializer.readToBuffer(sb, args[0]);
final Broadcast stringBV = sc.broadcast(new tmp2(sb.toString()));
JavaRDD rdd1 = sc.textFile(args[1]);
JavaRDD rdd2 = rdd1.flatMap(new FlatMapFunction() {
@Override
public Iterator call(String s) {
return Arrays.asList(SPACE.split(s)).iterator();
}
});
JavaRDD rdd3 = rdd2.map(new Function() {
@Override
public Integer call(String s) {
String length = stringBV.value().s; //只是为了使用广播变量stringBV,没有实际的意义
String tmp = length; //只是为了使用广播变量stringBV,没有实际的意义
return s.length();
}
});
JavaRDD rdd4 = rdd3.map(new Function() {
@Override
public tmp1 call(Integer x) {
tmp1 a = new tmp1(); //只是为了将rdd4中的元素类型转换为tmp1类型的对象,没有实际的意义
a.total_ += x;
a.num_ += 1;
return a;
}
});
rdd4.persist(StorageLevel.MEMORY_ONLY_SER()); //将rdd4以序列化的形式缓存在内存中,因为其元素是tmp1对象,所以使用Kryo的序列化方式缓存
System.out.println("the count is " + rdd4.count());
while (true) {} //调试命令,只是用来将程序挂住,方便在Driver 4040的WEB UI中观察rdd的storage情况
//sc.stop();
}
}
上述源码,涉及了闭包中使用的广播变量stringBV(是tmp2类的对象),以及对rdd4(元素是tmp1类的对象)的持久化,由于RDD的持久化占用的内存看起来比较直观,所以主要对比rdd4使用两种序列化库的区别。
使用默认的Java序列化库的情况:缓存后的 rdd4占用内存空间137.7MB
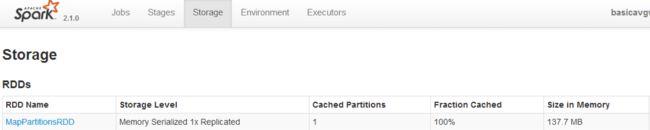
使用Kryo序列化库的情况:缓存后的 rdd4占用内存空间38.5MB
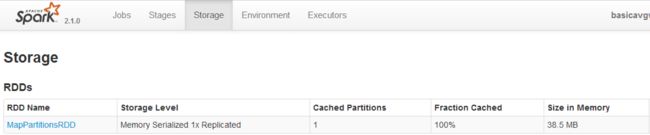
可以看出,使用了Kryo序列化库后,rdd4在内存中占用的空间从137.7MB降低到38.5MB,比使用Java序列化库节省了4倍左右的空间(如果使用其他更适合压缩的对象类型,应该能达到官方的所说的提升10倍的压缩比)
当然,如果想进一步的节省内存、硬盘的空间,减少网络传输的数据量,可以配合的使用Spark支持的压缩方式(目前默认是lz4),广播变量、shuffle过程中的数据都默认使用压缩功能。(注意,RDD默认是不压缩的)
| Property Name | Default | Meaning |
|---|---|---|
| spark.io.compression.codec | lz4 | The codec used to compress internal data such as RDD partitions, broadcast variables and shuffle outputs. By default, Spark provides three codecs: lz4, lzf, and snappy. |
| spark.broadcast.compress | true | Whether to compress broadcast variables before sending them. Generally a good idea. |
| spark.shuffle.compress | true | Whether to compress map output files. Generally a good idea. |
| spark.shuffle.spill.compress | true | Whether to compress data spilled during shuffles. |
| spark.rdd.compress | false | Whether to compress serialized RDD partitions (e.g. for StorageLevel.MEMORY_ONLY_SER in Java and Scala or StorageLevel.MEMORY_ONLY in Python). Can save substantial space at the cost of some extra CPU time. |
RDD持久化操作时使用压缩机制(注意,只有序列化后的RDD才能使用压缩机制)
SparkConf 增加下面的配置
conf.set("spark.rdd.compress", "true");
效果很显著吧!rdd4持久化后在内存中占用的空间降低到1MB左右!
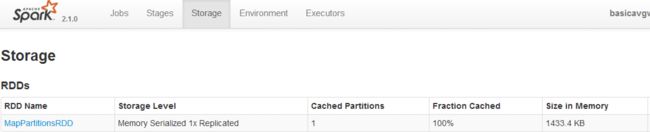
使用压缩机制,也会增加额外的开销,也会影响到性能,这点需要注意。
相关链接
[Tuning Spark] (http://spark.apache.org/docs/latest/tuning.html)
[Spark Configuration] (http://spark.apache.org/docs/latest/configuration.html#compression-and-serialization)
[Kryo] (https://github.com/EsotericSoftware/kryo)