写一下个人的es优化经历,主要分下面五个模块,
1. Overview
2. 索引 index
- index优化项
3. 检索 search
- search优化项
4. 系统配置优化项
5. 压测 esrally
6. 监控 marvel
7. 注意事项
8. Reference
9. More
Overview
先来看看es的整体架构图,上面有多个重要模块,今天主要写在lucene上面的index模块与search模块的优化经历,力求简要写出改变了configuration之后,会给es cluster带来什么样的影响。

Index Optimization

上图展示了一个doc index/write请求过来,es为其建立倒排的过程,而index opt.的优化点就主要集中在该posting list building过程,先认识4个组件(heap buff, os cache, transLog, disk),
- 客户端选择一个node发送请求过去,这个node就是coordinating node(默认master,data,ingest都是coord)
- coordinator对doc进行路由,将请求转发给对应的data node(有primary shard)
- 实际的node上的primary shard处理请求,然后将数据同步到replica node
- coordinator如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端
- 为了提高容错,doc双写
- 写入es实例的heap buffer(此时doc未能被search)
- 写入transLog(translog其实也是先写入os cache的,默认每隔5秒刷一次到磁盘中去,最多丢5秒的数据)
- es实例在每个refresh interval里将heap里面的docs刷到Lucene利用着的系统缓存里(此时doc能够被search)
- transLog根据配置的持久化到disk的策略,同步docs到磁盘(顺序写盘)
- transLog的clean up
index优化项
-
mapping禁用不需要的功能- index,倒排索引,not_analyzed,注意是否分词,尽量精简schema字段个数,不会被检索的字段就不要建立倒排。.field("index", "no")
- doc values,正排索引,用于聚合或者排序
- norms,analyzed norms存储了多种正则化算子,用于docs的排序评分,如果不需要排序,可以disable norms
- index_options,有docs(文档有无), freqs(重复出现的文档评分更高), positions(涵盖了前2种,并且多了位置信息,用于临近查询), offsets(全部,用于高亮)四类
- 关闭
_all,让查询匹配到具体schema,可以降低索引大小index.query.default_field:your_schema_replace_all, _all字段会给search带来方便,但是会增加index时间和index尺寸 -
indices.memory,es instance的memory buffer大小,buffer满了/一个refresh周期到了会刷到系统缓存,如果refresh足够大,buffer也足够大,与系统缓存的io次数会越小- The indexing buffer is used to store newly indexed documents it fills up
- indices.memory.index_buffer_size defines the percentage of available heap memory that may be used for indexing operations
- 新doc同时到es heap和transLog/WAL,即双写
-
index.translog.durability,request/async,translog的持久化策略,每个请求都flush/异步flush,flush持久化策略如下,- index.translog.flush_threshold_opts : 10000 (translog每个flush batch的条数)
- index.translog.flush_threshold_size : 5000mb (flush batch size)
-
segment merge,每次refresh/flush都会产生段,lucene会将小段合并至大段,- indices/index.store.throttle.max_bytes_per_sec,限制段合并速度(indices节点级别,index索引级别)
- index.merge.scheduler.max_thread_count,段合并线程数,机械硬盘建议设置为1,减少减少磁头争用
-
refresh_interval,es instance的memory buffer到系统缓存的时间间隔(检索实时性),一次es refresh会产生一个lucene segment;久刷新更能够利用缓存 -
number_of_replicas,首次索引设置为0,index过程中,如果有副本的话,doc也会马上同步到副本中去的,同时进行分词索引等,而index之后再传送就是传index后的内容了,不需要再经历分词索引部分。首次索引完成后再开启,以防node crash- provide high availability,stronger failover
- scale out search volume/throughout since searches can be executed on all replicas in parallel(提高es的查询效率,es会自动在主或副本分片上对检索请求进行负载均衡,提前短路)
- discovery.zen.minimum_master_nodes,如果replica完好,但是脑裂num设置不当,不幸裂开了2个cluster(clusterA与clusterB此时数据一致),此时对读的影响是不大的,但是对写就有问题,因为新写数据可能写在clusterA,也可能写在clusterB,那么下次查的时候就不一定能查到这条新写doc
-
number_of_shards,下面几条供参考,- #shard=(1.5~3) * #node
- 索引分片数=数据总量/单分片容量(单个分片容量建议为20G~30G)
- 索引分片数=数据总条数/单分片条数(单个分片的docs条数建议为5 million)
- 有利于index性能,shard越多,bulk线程越多
- 不利于search性能,因为search request会分发到每个routing shard
- 随着#shard变多,一个node可能有N个shard,node存在OOM风险
- shard结果汇总到coordinator节点的时候,#shard * (from+size),coordinator存在OOM风险
-
auto doc id,如果手动为es doc设置一个id,那么es在每个write req都要去确认那个id是否存在,这个过程是比较耗时的。而如果使用es的自动生成id,那么es就会跳过这个确认步骤,写入性能会更好。而对于业务中的表id/sku_id,可以将其作为es document的一个field。但是如果表id/sku_id不作为es doc id,在实时更新的时候会引入duplication,这时候就需要去重 -
节点分离,master,data,ingest预处理节点,coordinator -
disk storage,SSD固态硬盘,机械硬盘, es heavily uses disk(SSDs, RAID 0) - Spark
入库时,Rdd的partition 的NodeClient一次操作基本会和大部分节点建立连接。建议事先根据shard规则(_id % shard_num/ routing_id % shard_num),将同一shard的数据事先都repartition到同一个partition。这样一个partition只要和一个Node建立连接。rdd.partitionBy(sku_id/cid3) - 分时段
倾斜index线程(增加index线程数,那么search线程数就会减少,类似spark的dynamic memory)- thread pool,size=工作线程数,queue_size=pending队列长度
- thread pool size for index/search/bulk
- _cluster.threadpool.index.queue_size: 1000,index
- _cluster.threadpool.search.queue_size: 100,search
-
index bulk request size,控制好写入批处理的每批大小
Search Optimization
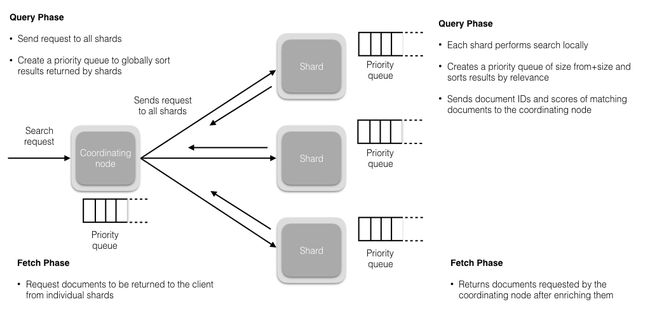
上图展示了一个query request过来,es对应的检索过程,默认是两阶段,首先是query过程,然后是fetch过程,
- 客户端选择一个node发送请求过去,这个node就是coordinating node
- coordinator node accept query search request(默认)
- coordinator根据请求的入参构造优先队列priority queue = (from+size)
- coordinator对routing/doc id进行哈希路由,将
读请求转发到对应的node,此时req会在primary和replica shard中使用round-robin随机轮询算法,从而随机选择一个,让读请求负载均衡,并在每个shard构造(from+size)长的优先队列 - 每个shard执行lucene的倒排查找,然后进行逻辑或非与,计算排序分等,根据排序分将结果sortList(docId, score)写入本地队列中(局部有序)
- 每个shard将本地队列中的结果发送给coordinator
- coordinator接收所有routing shard的队列结果(接收的docs条数 = (from+size) * #shard,谨慎使用深分页,OOM),然后根据score进行全局排序,从from位置开始,挑选(from+size)条里面的size条,结束query阶段
- coordinator将size条docs的id发送到对应的shard,以请求该docId的其余字段信息sortList(docId, score, schema1, ..., schemaN)
- coordinator取到所有命中docId的详细信息后,返回response
search优化项
- 设置
routing- es会将相同routing的数据存放在同一个shard中。后续查询时,在指定routing之后,es只需要查询一个shard就能得到所有需要的数据,而不用去查询所有的shard,shard_num = hash(_routing) % num_primary_shards
- 注意数据倾斜,如果routing的某个值的数据量太大,考虑更换routing_key为其他schema或者是多个schema的union
-
number_of_shards,同上 -
number_of_replicas,同上 -
filter clause,如果不需要lucene的score,使用filter语句而不用query语句 -
mapping的数据类型,选取最小的最合适,keyword, byte, short, integer, long, float, double -
nested比parent-child更友善 - 日期格式注意
取舍精度,now -> now/m -
max_num_segments,一个shard的最大segment数量,值越小,查询时所需打开的segment文件就越小,注意限速segment merge(动态写入更新的index推荐使用默认merge策略) -
more file system cache,让系统内存尽可能容纳更多的Lucene索引段文件index segment file,那么搜索走内存的可能性就更大,与磁盘的io交互就越少 -
doc模型的简单化,使用es的基本term/query/agg功能,而复杂的join, nested, parent-child搜索尽量避免es来做,可以将结果取出来之后,在java/spark client里完成这些复杂聚合操作 -
预先index data,对于一些常用的range查询,可以将range直接作为一个schema,这样可以直接使用term clause,而不需要走agg的range clause,即agg range price -> term price_range -
冷热数据分离, node级别的- node.attr.box_type: hot
- index.routing.allocation.require.box_type: warm
-
节点分离,master node与data node分离- node.master, handle search queries and only contact data nodes as needed
- node.data, handle data related operations like CRUD, search, and aggregations
-
清除删除文档,删除文档参与检索过程,但是返回是会过滤掉,所以如果清理了,就不会参与检索了. only_expunge_deletes = true
提高查询效率
- 增加filesystem cache,操作系统会将磁盘文件里的数据自动缓存到 filesystem cache,这样查询会较少与disk的交互
- 数据预热,如果filesystem cache不足放下所有数据,那么肯定有一部分要放在disk,此时可以开一个定时任务定时主动search hot data,让hot data能够长期驻留在filesystem cache
- 冷热分离,将大量的访问很少、频率很低的冷数据,单独写一个索引,然后将访问很频繁的热数据单独写一个索引。这样可以确保热数据在被预热之后,尽量都让他们留在hot node的filesystem cache里,而不会被冷数据给冲刷掉
- document模型设计(schema选取),es的关联、aggregation都是耗时操作,最好能在ETL入库es前就完成(比如说sum写成一个字段,而不是实时算sum)
- document模型设计2,减少不必要的字段,例如body可以不存放在es内部,而存放在外部的hbase里面,通过doc_id来获取,而es只做倒排。这样可以减少es的data,以便更完全地存放于filesystem cache
- 不要深分页,因为深分页需要算topK的,很容易拉爆coordinator节点。普遍情况是使用
scroll_api和search_after一页一页地拉取,而不是随机跳页
系统配置项
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/system-config.html
- heap size
- GC(CMS, G1)
- thread limits
- disable swapping
- 文件描述符
- 虚拟内存
Stress Test
https://segmentfault.com/a/1190000011174694
https://github.com/elastic/rally
使用esrally进行压测,对比优化前后es cluster的性能。
- track,压测用的数据集和测试策略(赛道)
- car,不同配置的es实例(赛车)
- race,以track与car为前提的一次压测(比赛)
- tournament,多个race组成的一系列压测(系列赛)
- pipeline,压测的步骤过程
| track | 压缩数据大小 | 解压数据大小 | 文档数 |
|---|---|---|---|
| geonames | 252 MB | 3.3 GB | 11396505 |
| geopoint | 482 MB | 2.3 GB | 60844404 |
| logging | 1.2 GB | 31 GB | 247249096 |
| nested | 663 MB | 3.3 GB | 11203029 |
| noaa | 947 MB | 9 GB | 33659481 |
| nyc_taxis | 4.5 GB | 74 GB | 165346692 |
| percolator | 103 KB | 105 MB | 2000000 |
| pmc | 5.5 GB | 22 GB | 574199 |

esrally --distribution-version=5.0.0 --track=geopoint --challenge=append-fast-with-conflicts --car="16gheap"

esrally list pipeline
Monitor
主要通过es的plugin来监控_cat api的metrics,
- kibana
- marvel
- kopf/cerebro
- head
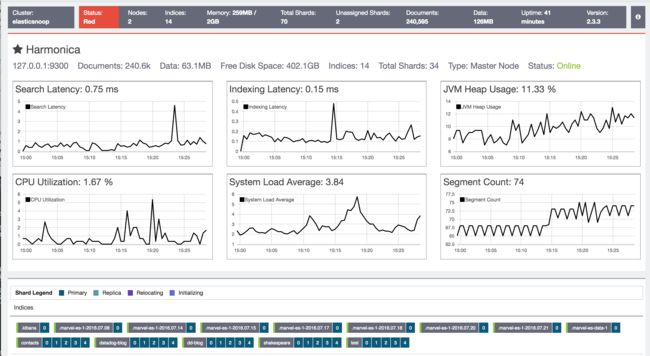
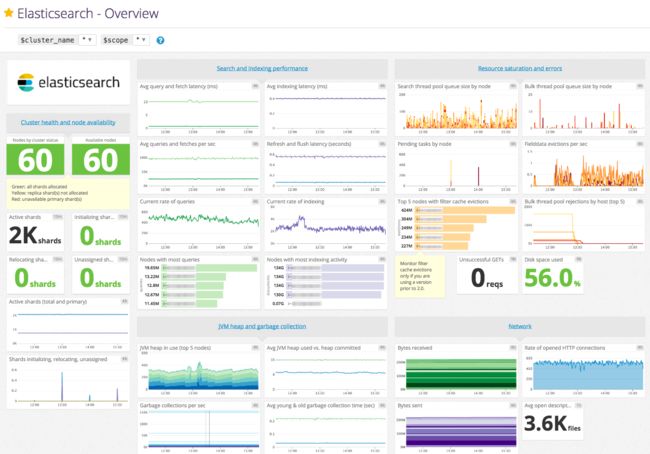
使用marvel查看对应的性能指标,
- search rate
- search latency
- indexing rate
- indexing latency
- index size
- dos count
- fielddata size
- lucene memory
- segment count
- JVM heap usage
- cpu utilization
- system load, etc.
注意事项
elasticsearch的版本迭代快,在实际部署使用前,最好阅读一遍对应版本的document,并了解其相应configuration。
Reference
- How to Maximize Elasticsearch Indexing Performance
- Anatomy of an Elasticsearch Cluster
- Tune for indexing speed
- Tune for search speed
- Elasticsearch: The Definitive Guide
- 将 ELASTICSEARCH 写入速度优化到极限
- ES搜索性能优化
More
- Elasticsearch - Performance Tuning