本案例的目标是客户价值识别,即通过航空公司客户数据识别不同价值的客户,识别客户价值应用最广泛的模型是通过3个指标(最近消费时间间隔Recency, 消费频率Frequency, 消费金额Money)来进行客户细分,识别出高价值的客户,所以称为RFM模型。
但本案例使用客户关系长度L,消费时间间隔R,消费频率F,飞行里程M,折扣系数的平均值C五个指标来识别客户价值,简称LRFMC模型。

image.png
本案例将采用K-Means聚类方法识别出最有价值的客户,分析流程为:

image.png
1. 准备数据集
原始数据集有62987行,44列,可以通过pd来加载,然后通过describe()得到基本信息表。
explore=data.describe().T
explore['null_ratio']=(len(data)-explore['count'])/len(data)
explore.drop(['count'],axis=1,inplace=True)
explore
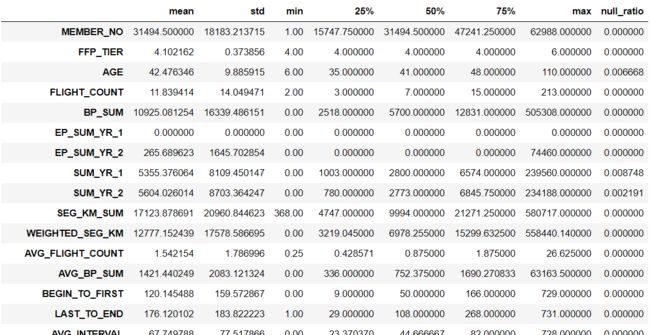
image.png
2. 数据预处理
本案例采用数据清洗,属性规约,数据变换的预处理方法
2.1 数据清洗
由于本数据集含有6.3W个样本,而缺失值样本很少,所以可以直接将缺失值样本删除,此处删除:票价为空的记录,票价为0平均折扣率不为0总飞行公里数大于0的样本。
data = data[data['SUM_YR_1'].notnull() & data['SUM_YR_2'].notnull()]
#票价非空值才保留
#只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录。
index1 = data['SUM_YR_1'] != 0
index2 = data['SUM_YR_2'] != 0
index3 = (data['SEG_KM_SUM'] == 0) & (data['avg_discount'] == 0) #该规则是“与”
data = data[index1 | index2 | index3] #该规则是“或”
最终的样本数为62044.
2.2 属性规约,数据变换
原来的数据集中有44个特征,此处需要构建LRFMC模型,故而首先选择和LRFMC特征相关的几个列,然后计算得到LRFMC特征。
from datetime import datetime
def months(strs):
str2,str1=strs
t1=datetime.strptime(str1, "%Y/%m/%d")
t2=datetime.strptime(str2, "%Y/%m/%d")
return (t2.year-t1.year)*12+(t2.month-t1.month)
data['L']=data[['LOAD_TIME','FFP_DATE']].apply(months,axis=1)
data.rename(columns={'L':'ZL','LAST_TO_END':'ZR','FLIGHT_COUNT':'ZF','SEG_KM_SUM':'ZM','avg_discount':'ZC'},inplace=True)
data=data[['ZL','ZR','ZF','ZM','ZC']]
data=(data-data.mean(axis=0))/data.std(axis=0)
data.head()
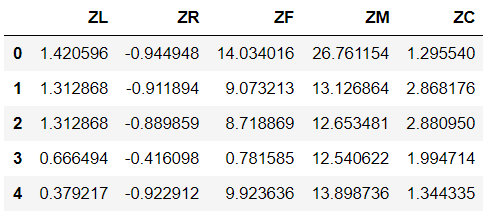
image.png
至此,数据集构建完成,含有5个特征,62044个样本,没有标签,所以需要用无监督学习。
3. 模型构建
客户价值分析模型主要由两个部分组成:每个部分根据航空公司客户5个指标的数据,对客户进行聚类分群,第二部分结合业务对每个客户群进行特征分析,分析其客户价值,并对每个客户群进行排名。
3.1 客户聚类
此处使用KMeans将客户分群,根据业务的理解和分析,客户群为5类。
k = 5 #需要进行的聚类类别数
#调用k-means算法,进行聚类分析
kmodel = KMeans(n_clusters = k, n_jobs = 4) #n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data) #训练模型
kmodel.cluster_centers_ #查看聚类中心
kmodel.labels_ #查看各样本对应的类别

image.png
上面虽然将客户分成了5个类别,但每个类别具有哪些特征还不是很明确,下面通过蛛网图来查看客户群的基本特征,从而对不同的客户群采用不同的营销方法,争取得到利润的最大化。
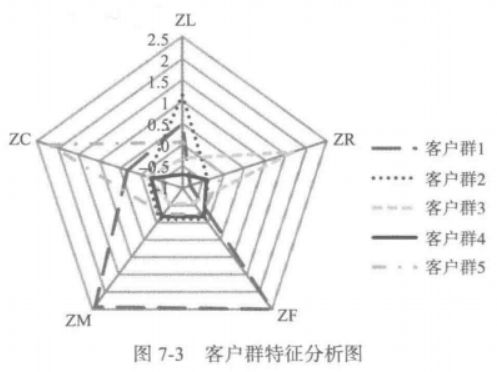
image.png
参考资料:
《Python数据分析和挖掘实战》张良均等