本章节以及后续章节的源码,当然也可以从我的github下载,在源码中我自己加了一些中文注释。
一、分类数据
1、背景和目的
表中的一列通常会有重复的包含不同值的小集合的情况。我们已经学过了unique和value_counts,它们可以从数组提取出不同的值,并分别计算频率:

许多数据系统(数据仓库、统计计算或其它应用)都发展出了特定的表征重复值的方法,以进行高效的存储和计算。在数据仓库中,最好的方法是使用所谓的包含不同值的维表(Dimension Table),将主要的参数存储为引用维表整数键:
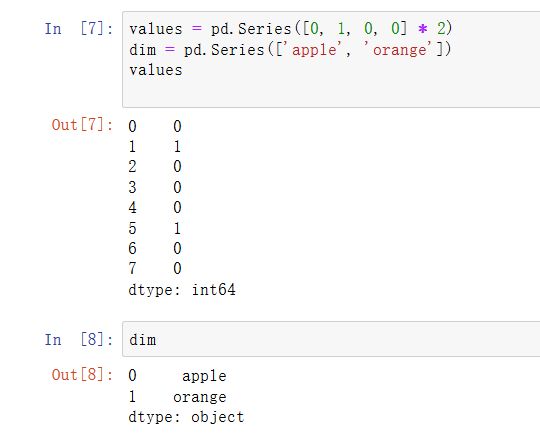
可以使用take方法存储原始的字符串Series:
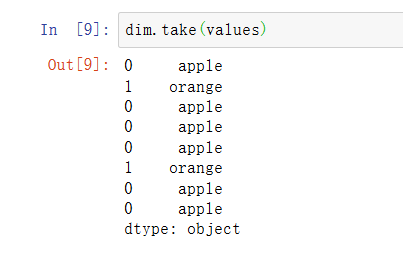
这种用整数表示的方法称为分类或字典编码表示法。不同值得数组称为分类、字典或数据级。表示分类的整数值称为分类编码或简单地称为编码。
分类表示可以在进行分析时大大的提高性能。你也可以在保持编码不变的情况下,对分类进行转换。一些相对简单的转变例子包括:重命名分类。加入一个新的分类,不改变已经存在的分类的顺序或位置。
2、pandas的分类类型
pandas有一个特殊的分类类型,用于保存使用整数分类表示法的数据。
df['fruit']是一个Python字符串对象的数组。我们可以通过调用它,将它转变为分类:
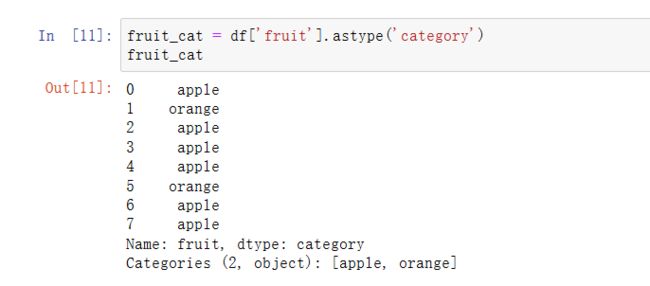
分类对象有categories和codes属性:

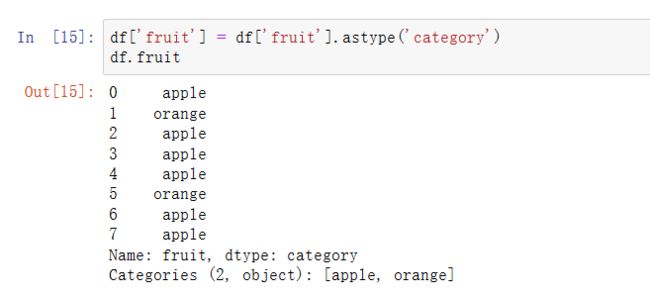
你可将DataFrame的列通过分配转换结果,转换为分类:
从其它Python序列直接创建pandas.Categorical:

如果你已经从其它源获得了分类编码,你还可以使用from_codes构造器:

与显示指定不同,分类变换不认定指定的分类顺序。因此取决于输入数据的顺序,categories数组的顺序会不同。当使用from_codes或其它的构造器时,你可以指定分类一个有意义的顺序:

输出[foo < bar < baz]指明‘foo’位于‘bar’的前面,以此类推。无序的分类实例可以通过as_ordered排序:

要注意,分类数据不需要字符串,尽管我仅仅展示了字符串的例子。分类数组可以包括任意不可变类型。
3、用分类进行计算
与非编码版本(比如字符串数组)相比,使用pandas的Categorical有些类似。某些pandas组件,比如groupby函数,更适合进行分类。还有一些函数可以使用有序标志位。
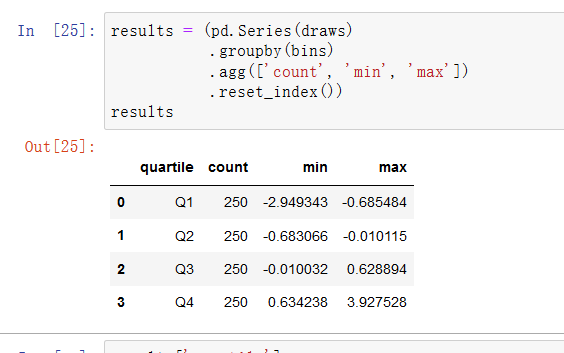
看一些随机的数值数据,使用pandas.qcut面元函数。它会返回pandas.Categorical。计算这个数据的分位面元,提取一些统计信息:

确切的样本分位数与分位的名称相比,不利于生成汇总。我们可以使用labels参数qcut,实现目的:

加上标签的面元分类不包含数据面元边界的信息,因此可以使用groupby提取一些汇总信息:
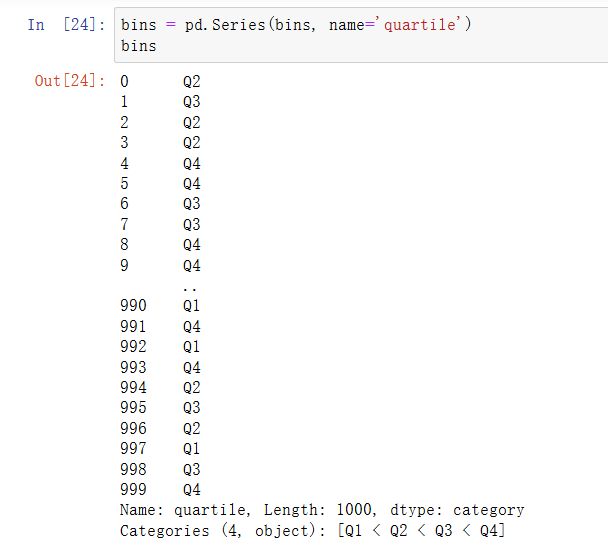
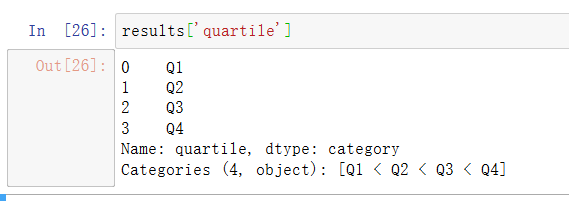
分位数列保存了原始的面元分类信息,包括排序:
4、用分类提高性能
如果你是在一个特定数据集上做大量分析,将其转换为分类可以极大地提高效率。DataFrame列的分类使用的内存通常少的多。来看一些包含一千万元素的Series,和一些不同的分类:
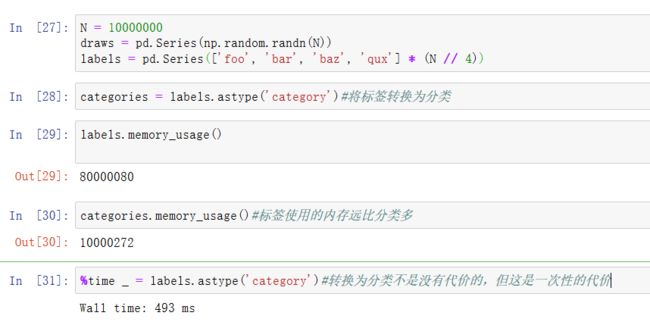
GroupBy使用分类操作明显更快,是因为底层的算法使用整数编码数组,而不是字符串数组。
5、分类方法
包含分类数据的Series有一些特殊的方法,类似于Series.str字符串方法。它还提供了方便的分类和编码的使用方法。
可用的分类方法:
看下面的Series:
特别的cat属性提供了分类方法的入口:

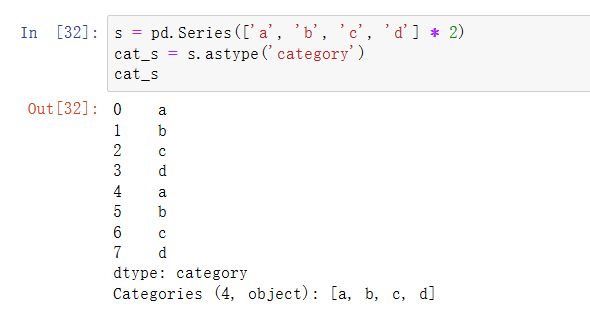
假设我们知道这个数据的实际分类集,超出了数据中的四个值。我们可以使用set_categories方法改变它们:
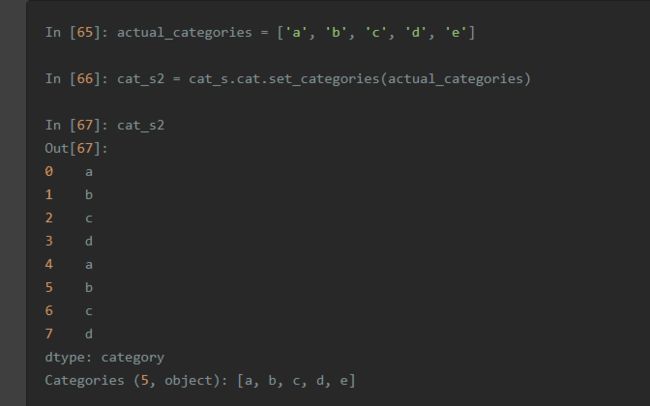
虽然数据看起来没变,新的分类将反映在它们的操作中。
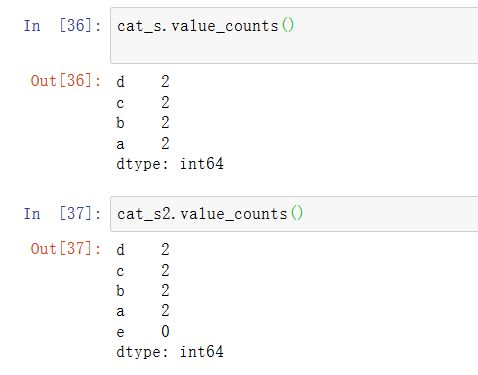
在大数据集中,分类经常作为节省内存和高性能的便捷工具。过滤完大DataFrame或Series之后,许多分类可能不会出现在数据中。我们可以使用remove_unused_categories方法删除没看到的分类:
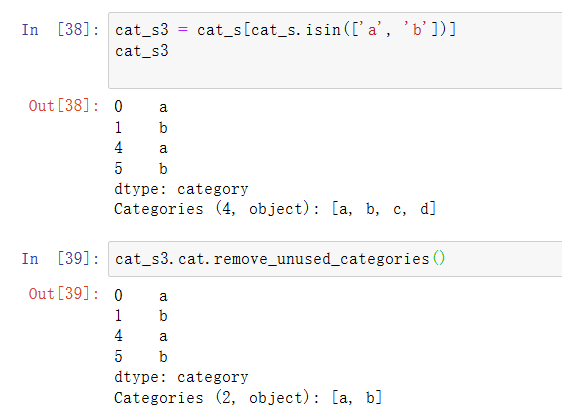
六、为建模创建虚拟变量
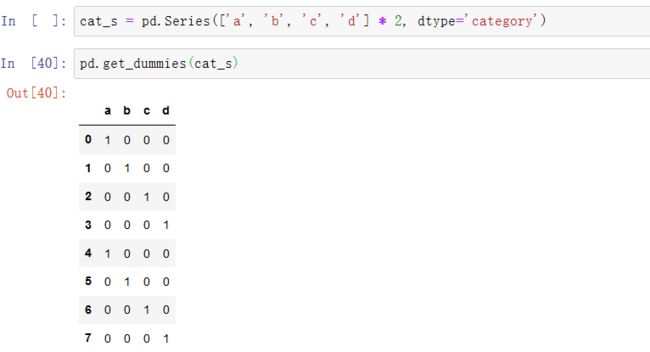
当你使用统计或机器学习工具时,通常会将分类数据转换为虚拟变量,也称为one-hot编码。这包括创建一个不同类别的列的DataFrame;这些列包含给定分类的1s,其它为0。
pandas.get_dummies函数可以转换这个分类数据为包含虚拟变量的DataFrame:
二、GroupBy的高级应用
1、分组转换和解封GroupBy
在分组操作中学习了apply方法,进行转换。还有另一个transform方法,它与apply很像,但是对使用的函数有一定限制:它可以产生向分组形状广播标量值、它可以产生一个和输入组形状相同的对象、它不能修改输入。
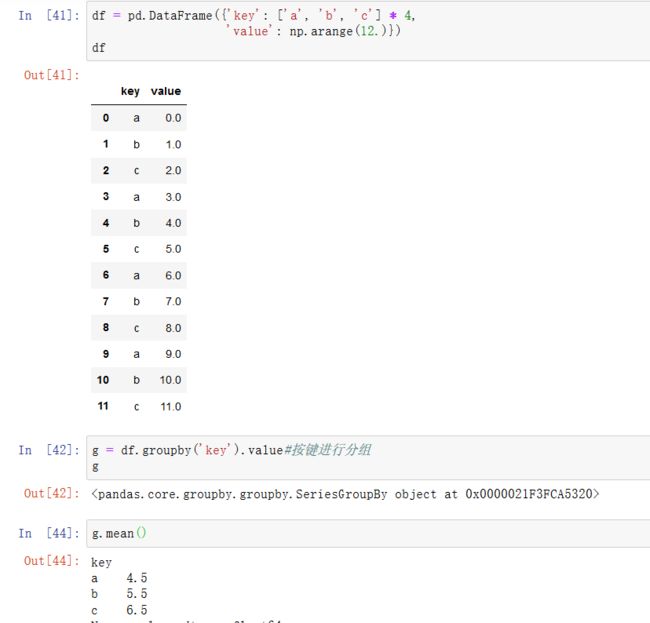
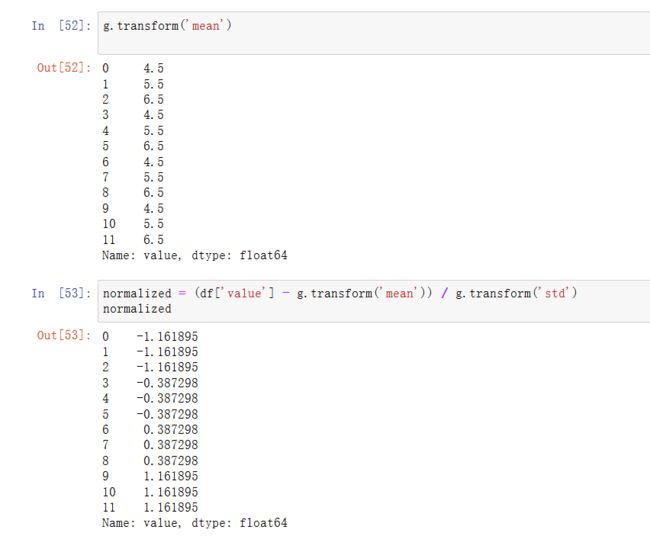
假设我们想产生一个和df['value']形状相同的Series,但值替换为按键分组的平均值。我们可以传递函数lambda x: x.mean()进行转换:

对于内置的聚合函数,我们可以传递一个字符串假名作为GroupBy的agg方法:
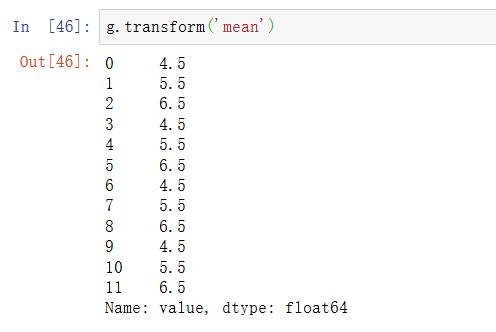
与apply类似,transform的函数会返回Series,但是结果必须与输入大小相同。举个例子,我们可以用lambda函数将每个分组乘以2:
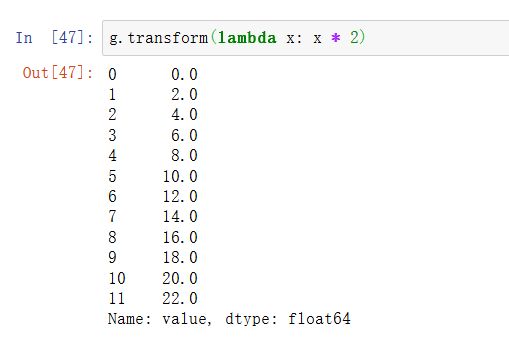
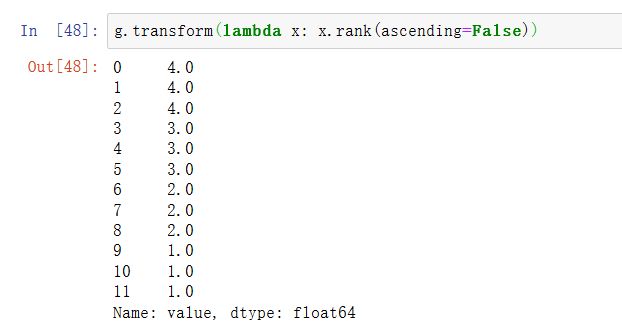
计算每个分组的降序排名:
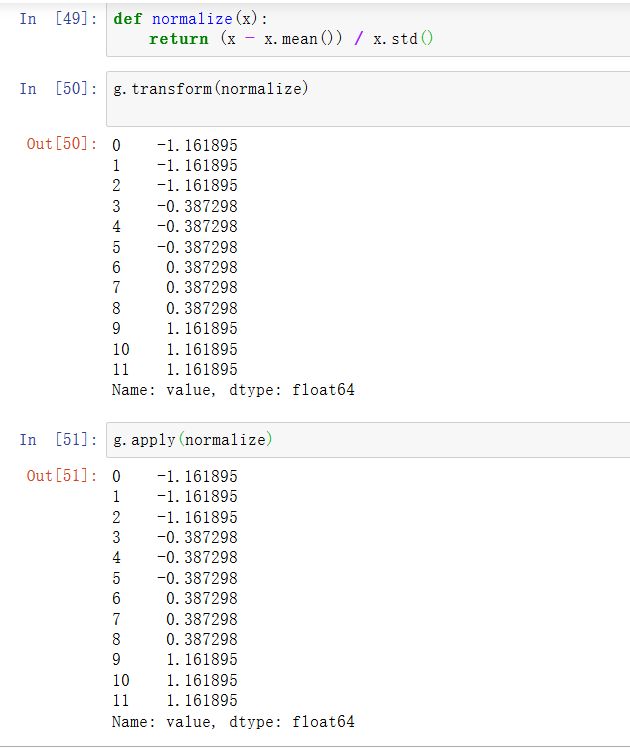
看一个由简单聚合构造的的分组转换函数,用transform或apply可以获得等价的结果:
内置的聚合函数,比如mean或sum,通常比apply函数快,也比transform快。这允许我们进行一个所谓的解封(unwrapped)分组操作:
解封分组操作可能包括多个分组聚合,但是矢量化操作还是会带来收益。
2、分组的时间重采样
对于时间序列数据,resample方法从语义上是一个基于内在时间的分组操作。下面是一个示例表:
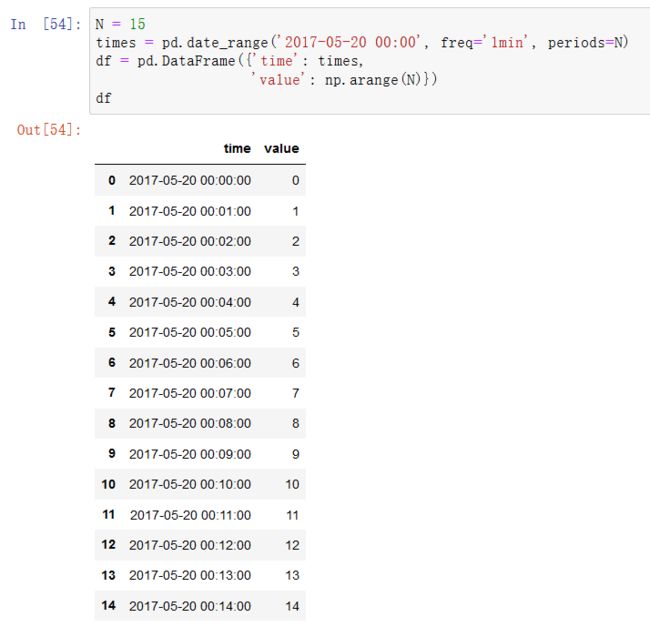
这里,我们可以用time作为索引,然后重采样:

假设DataFrame包含多个时间序列,用一个额外的分组键的列进行标记:
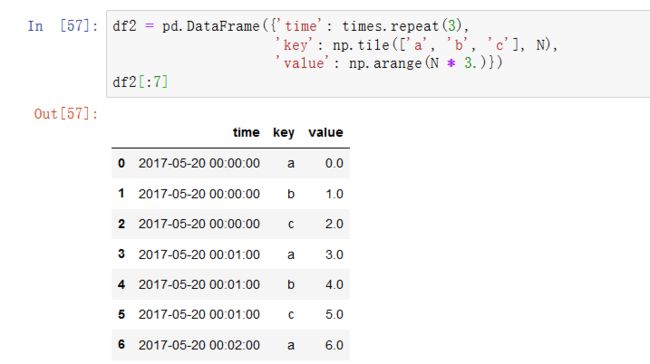
要对每个key值进行相同的重采样,我们引入pandas.TimeGrouper对象:
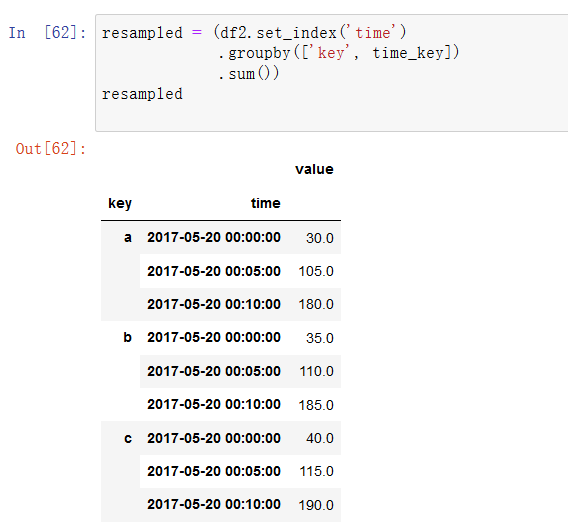
然后设定时间索引,用key和time_key分组,然后聚合:
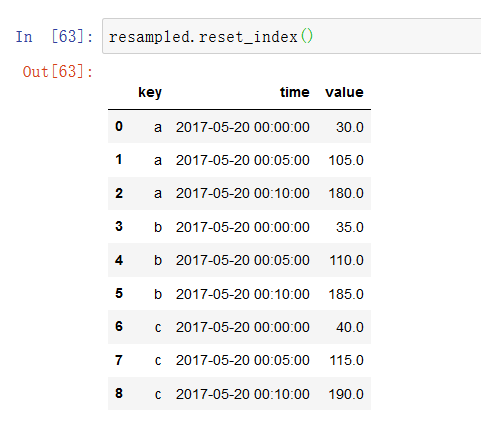
使用TimeGrouper的限制是时间必须是Series或DataFrame的索引。
快速学习:
第一节 NumPy基础(一)
第二节 NumPy基础(二)
第三节 Pandas入门基础
第四节 数据加载、存储
第五节 数据清洗
第六节 数据合并、重塑
第七节 数据聚合与分组运算
第八节 数据可视化
第九节 pandas高级应用
第十节 时间序列
第十一节 Python建模库
数据分析案例--1880-2010年间全美婴儿姓名的处理
数据分析案例--MovieLens 1M数据集
数据分析案例--USA.gov数据
数据分析案例--2012联邦选举委员会数据库
数据分析案例--USDA食品数据库