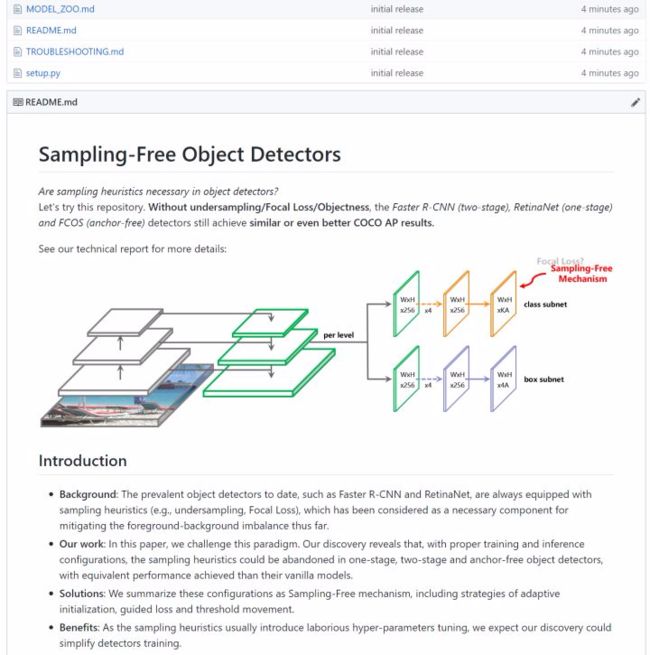
人有悲欢离合,月有阴晴圆缺。中秋佳节,为大家奉上一篇关于目标检测中“阴晴圆缺”不平衡的综述:Imbalance Problems in Object Detection: A Review (https://arxiv.org/abs/1909.00169, under review at TPAMI),同时也结合自己最近在这方面的 Tech Report: Is Sampling Heuristics Necessary in Training Object Detectors? (https://arxiv.org/abs/1909.04868) 进行一些阐述和思考,希望可以给大家以启发。
开源地址:
Imbalance Problems in Object Detection: A Review https://github.com/kemaloksuz/ObjectDetectionImbalance,作者总结了在目标检测领域关于不平衡的大量研究,从古老的 Bootstrapping 到现在的 Libra R-CNN,并且在不平衡的各个维度上列出了相关文献,大而全,值得大力关注。

Are Sampling Heuristics Necessary in Object Detectors?
在 YOLOv3 (one-stage), RetinaNet (one-stage), Faster R-CNN (two-stage), Mask R-CNN (two-stage), FoveaBox (anchor-free), Cascade R-CNN (multi-stage) 上没有使用任何 hard/soft sampling (e.g., objectness, under-sampling, Focal Loss) 方法,但取得甚至更好的 COCO AP,可以尝试一下~ https://github.com/ChenJoya/sampling-free
介绍
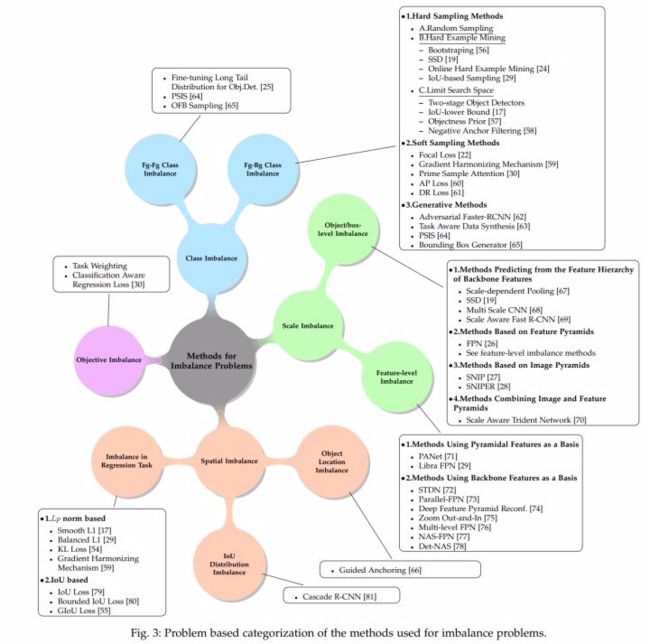
在 Oksuz 等人投向 TPAMI 的这篇论文中,提炼了一个核心观点:目标检测中存在多种多样的不平衡,这些不平衡会影响最终的检测精度,而现有的许多研究可以归结为解决这些不平衡方法。他们将不平衡分为四类:
- Class imbalance:类别不平衡,主要由样本数量上的差别引起。最典型的是 foreground-background imbalance,即训练过程中的正例数量远远小于负例数量引起的不平衡;
- Scale imbalance:尺度不平衡,这种不平衡主要由目标的尺度引起,例如 COCO 中的小物体过多即是一种尺度不平衡;又如将物体分配至 feature pyramid 时的不平衡;
- Spatial imbalance:空间不平衡,如不同样本对 regression 损失贡献的不平衡,IoU 上的不平衡,物体分布位置的不平衡;
- Objective imbalance:多任务损失优化之间的不平衡,最常见存在于 classification and regression losses 之间。
值得一提的是,这篇综述很大程度上应该是受到了 Libra R-CNN 的启发。 Libra R-CNN 发现了 sample level, feature level, and objective level 上的不平衡,而上述四种不平衡中,Spatial imbalance, Scale imbalance,Objective imbalance 似乎都是由其分别引申而来。
下面,我们先从相关研究最少的 Objective imbalance 入手,逐步分析研究工作较多的 Spatial imbalance,Scale imbalance,Class imbalance。
1. Objective imbalance
一般来说,分类任务的损失要比回归任务的损失要大一些,这是因为回归只做 foreground example,而分类要做到所有的 example。其实调过 Faster R-CNN 的小伙伴应该知道,在 RoI-subnetwork 阶段, classification 大约是 regression 的 2~4 倍,就如同下面这张图:

最常见的方法是设置 weighting factor 来调,观察什么样的情况可以达到最佳。另外一个解决方案是 Prime Sample Attention in Object Detection 里的 Classification-Aware Regression Loss,其本意是想让网络更加注意到回归较好的 bounding-boxes,因此让回归损失和分类的 score 相关,从而使得梯度可以从 regression branch 流到 classification branch:

作者在 open issue 章节中也提到,这种关联应该被更加深入的探索。典型的例子就是 Towards Accurate One-Stage Object Detection with AP-Loss,没有改动回归的 branch,但是 AP@75 却涨了 ~3%。
2. Spatial imbalance
Definition. Size, shape, location – relative to both the image or another box – and IoU are spatial attributes of bounding boxes. Any imbalance in such attributes is likely to affect the training and generalization performance. For example, a slight shift in position may lead to drastic changes in the regression (localization) loss, causing an imbalance in the loss values, if a suitable loss function is not adopted. In this section, we discuss these problems specific to the spatial attributes and regression loss
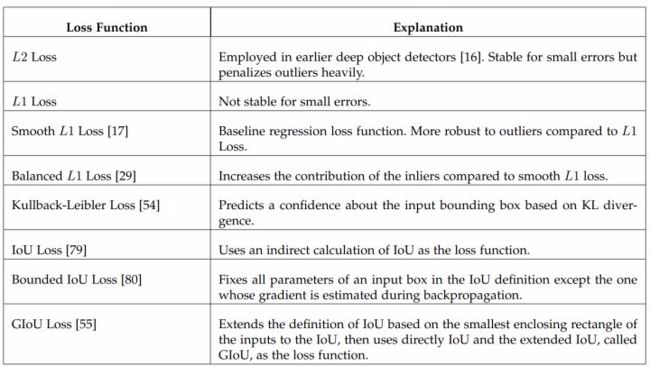
2.1 Imbalance in Regression Loss
在训练过程中,不同正例对于 regression loss 的贡献是不相同的,对于那些 low-quality IoU bounding-boxes, 会产生很大的损失,L1 和 L2 loss 会被它们所主导:

Smooth L1 Loss 由 Fast R-CNN 提出,降权了那些过大损失的样本(可能是 outliers)。Balanced L1 Loss 由 Libra R-CNN 提出,提升了 inliers 的权重,即相当于进一步降低了 outliers 的权重。其他的研究如下所示:
2.2 IoU Distribution Imbalance
IoU Imbalance 是指 bounding boxes 在 IoU 段的分布上呈现出明显不均匀的分布,Libra R-CNN 和 Cascade R-CNN 都探讨过这个问题。在 negatives 上,IoU 在 0~0.1 范围内的样本占据主导;在 positives 上,IoU 在 0.5~0.6 之间的样本占据主导。
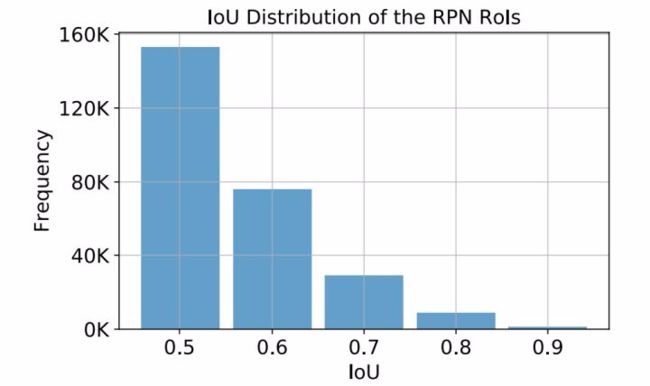
作者推荐的工作是 Cascade R-CNN (Naiyan Wang: CVPR18 Detection文章选介(上)),通过级联结构,逐步调高 IoU threshold,增强正样本的质量,防止 regressor 对单一阈值过拟合。
2.3 Object Location Imbalance
基于 anchor 的检测器 将 anchor boxes 均匀地排布在图像上,但是物体可不服从这种分布,如下所示:
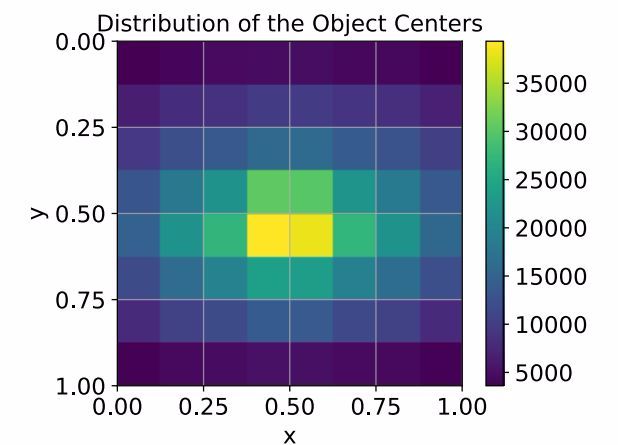 Distribution of the centers of the objects in the MSCOCO dataset over the normalized image
Distribution of the centers of the objects in the MSCOCO dataset over the normalized image
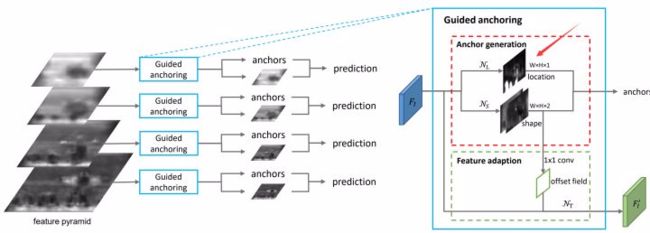
这里作者推荐了 Region Proposal by Guided Anchoring 的工作 (Kai Chen: Guided Anchoring: 物体检测器也能自己学 Anchor)。作为一个 anchor-free 的 RPN,它可以预测出 proposals 的 location,如下图中的箭头:
3. Scale imbalance
3.1 Object/box-level Scale Imbalance
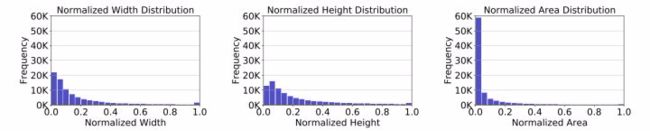
当某个尺度范围内的物体 over-represent 该数据集后,scale imbalance 就会发生。 An Analysis of Scale Invariance in Object Detection - SNIP 中的 investigation 指出这种 imbalance 会极大影响 overall detection performance。下图表达了 COCO 数据集中长宽面积上的不平衡:
为了处理多样性的边界框,pyramid 方法是最常用的。包括 image pyramid (SNIP, SNIPER), feature pyramid(SSD, FPN 等),以及 feature pyramid + image pyramid,作者将 TridentNet (Naiyan Wang: TridentNet:处理目标检测中尺度变化新思路) 列为这方面的典型工作。
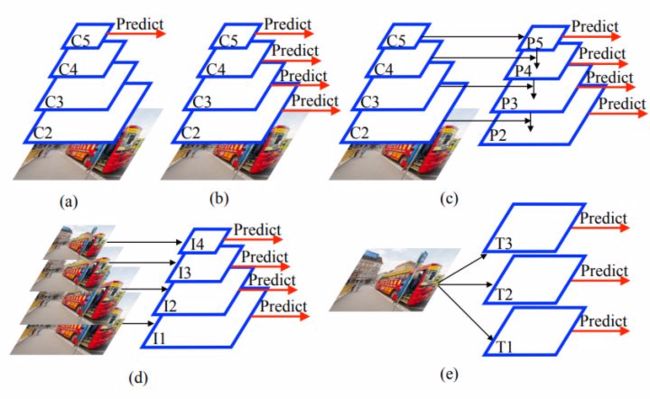 (a) No method. (b) Backbone pyramids. (e.g., SSD). (c) Feature pyramids (e.g., FPN). (d) Image pyramids (e.g., SNIP). (e) Image and feature pyramids. (e.g. TridentNet)
(a) No method. (b) Backbone pyramids. (e.g., SSD). (c) Feature pyramids (e.g., FPN). (d) Image pyramids (e.g., SNIP). (e) Image and feature pyramids. (e.g. TridentNet)
3.2 Feature-level Imbalance
这种不平衡主要是指 FPN-based architecture 里,层级之间特征的不平衡性,Low Level 和 High Level 的特征之间互有定位/语义之间的优缺点,如何 mitigate 这种不平衡来达到最佳的检测效果?而解决方案也大多是结构上的,来看看下面各式各样的连接方法:
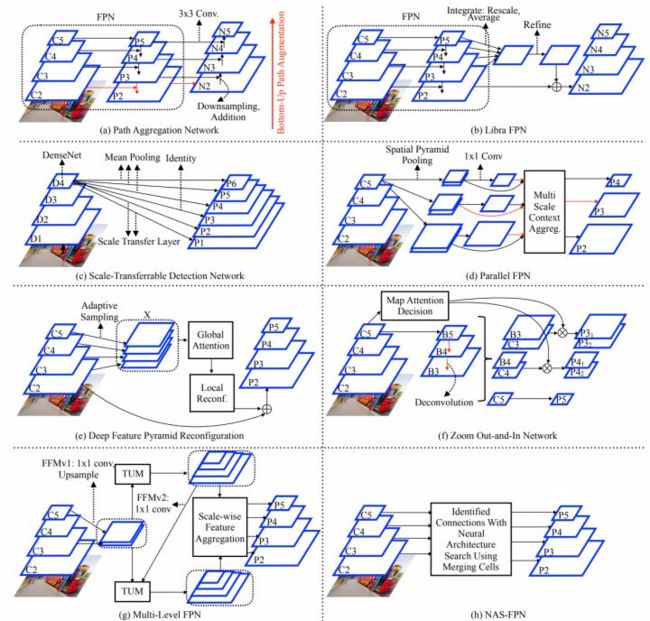
4. Class imbalance
4.1 Foreground-Foreground Class Imbalance
这类不平衡指的是分类类别上的不平衡,在数据集(dataset-level imbalance)或者是一个 batch (mini-batch-level imbalance)中都会存在。但是遗憾的是,这一类的不平衡并没有太大的引起现阶段目标检测研究的重视。
4.2 Foreground-Background Class Imbalance
这是目标检测中研究最广泛,程度最深的一类不平衡。这种平衡并不是由于数据集引起的,而是由于现有目标检测架构引起的:background anchors 远远多于 foreground anchors。似乎自 deep detectors 诞生以来,人们就一直在努力去克服这种不平衡。
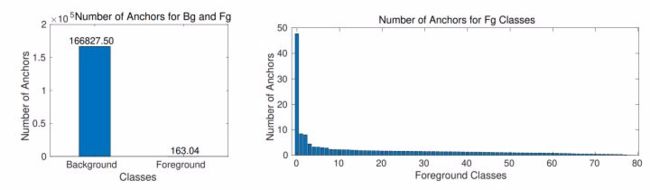
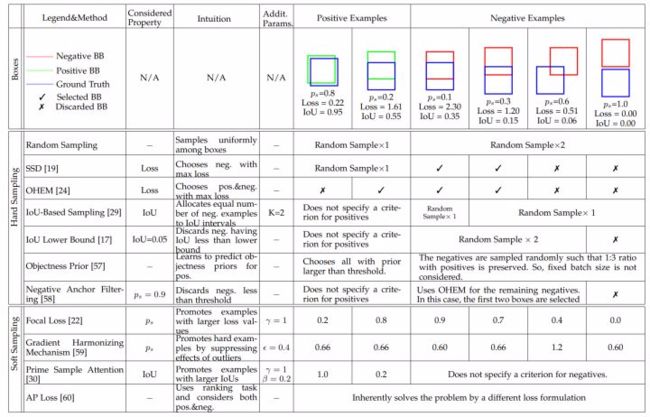
作者将解决这类不平衡的方法分为两类:
(1)hard sampling:可以理解为有偏采样。包括有 mini-batch undersampling (R-CNN 系列标准配置),OHEM,IoU-balanced sampling,PISA 等,作者在这里将类 RPN 的 objectness 方法也归结为了这一类。
(2)soft sampling:可以理解为 loss reweighting。最著名的方法莫过于 Focal Loss。
遗憾的是,由于时间的缘故,这篇综述中并没有对最新的 anchor-free 检测器进行分析。但是个人认为 anchor-free 的 detector 存在着类似的不平衡。例如,anchor-free 的检测器大多基于关键点的检测驱动,如 extreme point,center point,corner point;其中,foreground points 数量比 background points 存在着明显差异,虽然可能不若 anchor boxes 那般造成如此剧烈的不平衡,但是这仍然导致绝大部分的 anchor-free 检测器采用了 Focal Loss 或者其变体来训练网络。
(喝口水,分割线 ←_←)
我们可以看到,几乎所有的 sampling heuristics 都基于启发式,并且具有大量的超参数需要调整。例如,OHEM 需要调 mini-batch size 和 fraction,Focal Loss 需要调 α 与 γ,GHM 有一些必要的前提假设与区间 M 需要调。正如 GHM 文中所说,解决不平衡最佳的策略(分布)是难以定义的。因此,我们重新回顾了 foreground-background imbalance,来探讨 sampling heuristics 是否必要。我们认为,不像一般的,由数据引起的不平衡,foreground-background imbalance 在训练和测试中是具有等同分布的;而使用采样,可能会改变这种分布,并不一定会在测试中取得更好的结果;但不使用采样,就会陷入难以训练的境地。我们发现,从初始化,损失,推理三个方面辅以适当的策略,即可在没有任何 sampling heuristics 的情况下,总是可以达到更好的检测精度。我们开源了相关代码(https://github.com/ChenJoya/sampling-free),希望多多讨论,互相启发 。
5. Conclusions
目标检测中的不平衡问题是一个古老的问题,自检测器诞生之初,人们就在与其战斗。Imbalance Problems in Object Detection: A Review 的作者总结了不平衡的各种类型,并且详细分析了已经出现的研究,还在 open issue 中给出了悬而未解的问题。十分推荐。
文中的错误与纰漏,还请批评指正 ( ^_^ )