写在前面
由于之前在申请专利,所以文章不能发出来,现在发出来帮助有需要的人。
Animoji
苹果在今年的十周年特别版iPhone X发布会上,推出了Animoji功能。该功能基于iPhone X的结构光传感器,捕捉用户的表情变化,生成相应的3D动画表情。本文介绍了基于ARKit + SceneKit的Animoji实现方案。

Animoji原理
在人脸建模后,通过获取人脸追踪与表情捕捉的数据,更新到虚拟形象上,使虚拟形象与用户人脸的位置与表情相同步。
(1) 人脸建模
在高端设备上,借助红外摄像头与结构光点阵投影仪,根据获取的点云数据,结合利用泛光照明器得到的红外图像,通过随机交替获取二者数据,做3D人脸建模。
(2)人脸追踪与表情捕捉
人脸追踪:依据人脸检测算法和SLAM(同步定位与地图构建)算法,实时追踪人脸在图像中的位置变化,并计算人脸在3D空间中的位置。
表情捕捉:依据基于深度学习的表情识别算法,通过匹配用户当前人脸数据到表情库,识别出用户当前表情。
(3)虚拟形象渲染
构建与真实世界相同坐标的虚拟世界,创建虚拟形象并实时计算它与人脸之间的位置映射关系,基于表情捕捉得到的数据来更新虚拟形象的动画表情。
Animoji效果
视频链接
Animoji方案
本方案使用 变形动画+骨骼动画+骨骼控制 来实现Animoji。
变形动画:使用预先制作好的表情基作为变形目标,通过变形的方式来确定模型表面每个顶点最终的位置,使用SceneKit渲染的话,可以用SCNMorpher来实现。
骨骼控制:在设计师刷好骨骼对蒙皮的权重后,就可以通过骨骼控制或者加载骨骼动画来实现非变形部分的动画。
骨骼动画
建立虚拟形象模型
(1)虚拟形象静态模型
虚拟形象分为强表情部分和弱表情部分,以头部举例:脸部为强表情部分,眼睛牙齿耳朵等为弱表情部分。强表情部分用捕捉的表情数据更新,弱表情部分则根据用户头部的运动数据与表情变化来更新。

例如:用户边转头边做鬼脸,强表情部分,即脸部会更新为用户的表情形象,而弱表情部分,如耳朵骨骼会根据用户头部转动的速度变弯曲,舌头会在嘴巴长到一定幅度伸出。
(2)制作表情基
表情基分为普通表情基与混合表情基。表情基与静态模型的强表情部分的拓扑结构完全一致,且在同一个尺度空间下大小相同。不同表情基,模型的网格顶点数一样,多边形一一对应,不同的是顶点的位置不同(如大笑嘴部的顶点就会有位移)。
普通表情基是一些设计好的脸部模型,如图3。普通表情基代表一些固定的人脸表情,如张嘴、眨眼,为了缩减大小,表情基除了几何体没有其他任何信息,并且分割为若干子部分。

混合表情基是若干特定的普通表情基的非线性组合,在运行时计算得出,用以扩展表情的丰富度,理论上有混合表情基的支持,虚拟形象能够模拟无限多个表情,而不是只在普通表情基这个维度,混合表情基的计算方式如下式, B( i )表示第i 个混合表情基,E( j )表示第j个普通表情基。
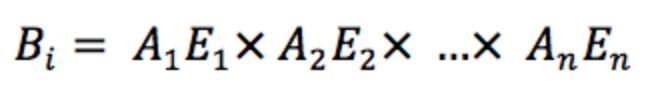
表情分割
本系统将表情分割成5部分,在加载表情时,只使用有效部分,(如眨眼就只加载眼部),缩小了表情的计算量。分割表情时,使用更平滑的顶点法线来避免分割后可能产生的裂缝。

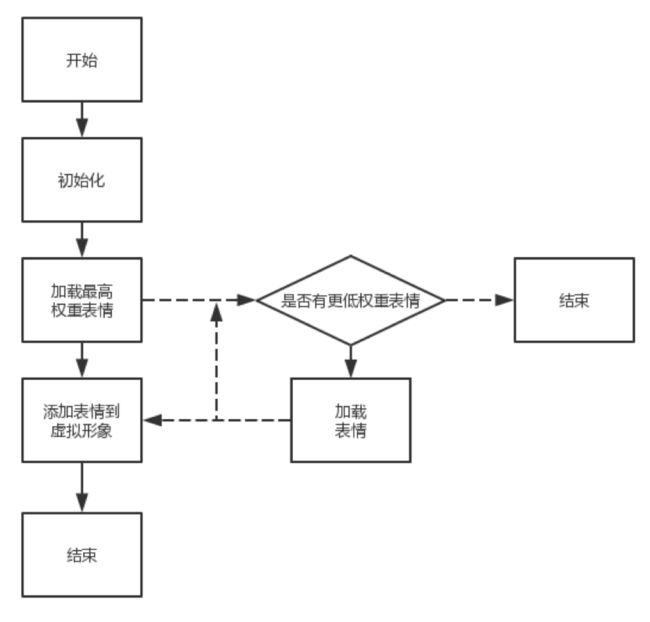
表情权重分配机制
本系统对不同表情分配了不同的权重,在更新时,对于高权重的表情,会先加载先更新,提高每次更新表情的用户体验,缩短关键表情的等待时间,流程图如下。
分包加载
本系统的加载方式采用分包加载的方式,首先将分割好的表情基分布存储在若干文件中,在需要的时候分包加载,模型开始更新的时间是之前的20%。
建立骨骼
对于弱表情部分,他们是根据头部的运动与表情变化来做更新,本系统对弱表情部分建立骨骼来控制它们。当用户向右看时,控制眼球骨骼向右旋转;当用户张嘴时,控制下巴骨骼向下旋转;当用户向右转头时,耳朵会根据转头速度向左旋转。
骨骼动画
除了上一点所说的更新方式,本系统还使用骨骼动画来来做更精致、可运营的表情。骨骼动画与命中逻辑可动态下发。
基于人脸追踪与表情捕捉数据更新虚拟形象
初始化之后,虚拟形象会添加到虚拟世界中,用户人脸在真实世界中的运动会同步到虚拟形象在虚拟世界的运动。同时通过表情捕捉数据,拆解用户表情为普通表情基和混合表情基的线性组合,利用此组合更新虚拟形象的强表情部分。如下式, E(user)是用户当前的表情,E是普通表情基,B是混合表情基。
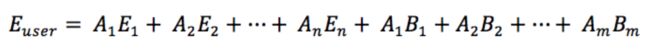
更新方式是:遍历表情基E的网格的每一个顶点,通过下式计算其最终的位置。其中V(i)表示第i 个顶点,V(E1)表示在表情基E1中相应的顶点,A(i)表示表情Ei的权重。
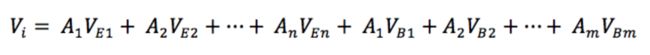
对于弱表情部分,本系统根据头部的运动与表情的变化,通过骨骼控制它们。弱表情部分包括但不限于耳朵、下牙与舌头、眼球。
对于耳朵:
当头部转动时,通过判断转头的速度来控制耳朵骨骼的旋转,从而弯曲耳朵。计算公式如下式,Ear(eulerAngles)为耳朵骨骼的欧拉角,V(x), V(y) 分别为头部转动的偏航角速度、俯仰角速度,A、B分别为计算所需的补偿值,效果如图6。

1) 当用户张大嘴时,耳朵向内弯曲,弯曲幅度由云端控制。
2) 当用户闲置时,耳朵部分播放骨骼动画,动画与触发逻辑由云端下发。
对于下牙与舌头:
1) 当用户张嘴时,下牙与舌头的骨骼配合张嘴表情向下旋转。计算公式如下,Jaw为下牙与舌头骨骼的欧拉角,H 为云端控制的最大俯仰角阈值,A为当前表情的张嘴表情系数。
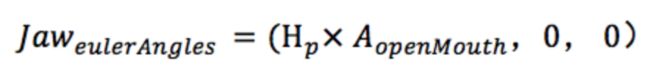
2) 当用户张嘴且下唇特征点出现特定变化,判断用户在张嘴伸舌头,变形舌头并伸出舌头,效果如图9。

3) 当用户张嘴伸舌头时,移动头部,控制舌头左右变形,以符合头部的运动。
对于眼球:
1) 眼球的转动主要根据眼部表情变化来控制,计算方式如下式,Eye为眼球骨骼的欧拉角,S为计算旋转的方向值,H为云端控制的最大俯仰角与偏航角阈值,A为当前表情的眼部表情变化系数。
全景背景与粒子特效
通过下发不同的360全景图片或视频作为背景。当用户做特殊表情或者特殊话语,触发全景背景的更改与粒子特效,当用户旋转手机时,能看到不同的内容,丰富了产品的应用空间,效果如下图。

更进一步
目前模型的体积较大,考虑采用运行时平滑、着色的方式,实现素材包的体积减少,使用运行时加顶点的平滑方式,可以让素材包减小80%左右。
与TTS结合,让用户可以通过语音控制一些彩蛋逻辑。
结合图像处理、深度学习算法,拓宽应用场景,实现更好玩的玩法。