思路
我们的目标是爬取某些关键词在搜狗搜索中能搜到的所有页面。先预热一下:
URL结构
随便打开一个搜狗的搜索页面,它会出现很多奇奇怪怪的参数,比如说:
https://www.sogou.com/web?
query=%E9%98%BF%E7%91%9F%E4%B8%9C&_asf=www.sogou.com&_ast=1529469758&w=01019900&p=40040100&ie=utf8&from=index-
nologin&s_from=index&sut=1505&sst0=1529469758575&lkt=0%2C0%2C0&sugsuv=00D80B85458CAE4B5B299A407EA3A580&sugtime=1529469758575
经过我的测试,大多数是没用的。有三个值比较重要:
- query, 即要搜索的关键词。
- page, 即页数,第一页对应
page=1但有可能不现实。 - tsn,代表过滤的时间范围
0-4分别对应无限制、一天、一周、一月、一年。
暂时我们只需要用到前两个,第三个在后一篇文章中爬取搜狗微信文章中有可能搜的到。因此这次爬取的URL的格式就是:https://www.sogou.com/web?query={关键词}&page={n}。
种子关键词
在爬虫启动的时候,我们需要一些关键词作为种子。这些种子关键词最好是不相干的,这样能降低URL重复的概率。我这里使用的是百度指数和搜狗指数两个页面上的热词。以搜狗指数为例,虽然它不提供类似于热词排行榜之类的东西,但是如果你仔细看搜狗指数的页面,它的背景动画里会有一些词组在不断的出现和消失,这些其实就是当前的热词,它们在网页源代码里的js块里,可以通过正则抓取出来:
def get_sogou_indexs():
headers = {}
headers['host'] = "index.sogou.com"
headers['referer'] = "https://www.sogou.com"
url = "http://index.sogou.com/"
r = requests.ohRequests()
req = r.get(url, headers=headers)
pattern = re.compile('root\.SG\.hot = \[(.*?)\];', re.S)
items = pattern.findall(req.text)
if not items:
return None
items = json.loads('['+items[0]+']')
return [item.get('text') for item in items]
百度指数的逻辑和搜狗指数的差不多,唯一不同的是百度指数采用的是异步请求,不多说,直接上代码:
def get_baidu_indexs():
headers = {}
headers['host'] = "zhishu.baidu.com"
headers['origin'] = "https://zhishu.baidu.com"
headers['referer'] = "https://zhishu.baidu.com/"
url = "https://zhishu.baidu.com/Interface/homePage/pcConfig"
r = requests.ohRequests()
req = r.post(url, headers=headers)
items = json.loads(req.text)
if items.get('status') != 0:
return None
items = items.get('data').get('result').get('keyword')
return [item.get('utf8') for item in items]
这两个页面抓取之后合并并去重,大概可以抓到60个左右不重复的热词。作为种子其实是很好的选择。
如何知道某个关键词对应了多少页面
这个感谢知乎上一个问题的答案:如何爬取搜索引擎下某个关键字对应的所有网站?。实现的方法就是访问一个非常大的页面数,实际的总页数会包含在其返回的页面中。
以关键词特朗普举例,我们访问这样一个URL:https://www.sogou.com/web?query=特朗普&page=1000。它会有一些内容,但是不重要。查看其网页源代码:
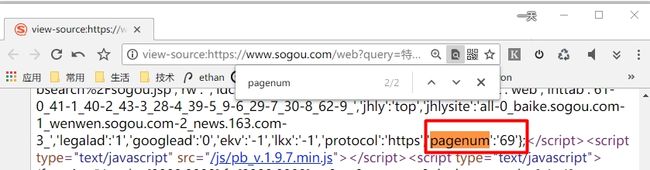
可以看到其总页数是69页,那么我们只要构建如下URL就行了:
https://www.sogou.com/web?query=特朗普&page=1
https://www.sogou.com/web?query=特朗普&page=2
https://www.sogou.com/web?query=特朗普&page=3
....
https://www.sogou.com/web?query=特朗普&page=68
https://www.sogou.com/web?query=特朗普&page=69
以下是关于这部分的代码:
def get_pagenum(keyword, cookies):
url = "https://www.sogou.com/web?query={0:s}&page=750".format(keyword)
headers = {}
headers['referer'] = "https://www.sogou.com/"
r = requests.ohRequests()
req = r.get(url, cookies=cookies)
pattern = re.compile('\'pagenum\':\'(.*?)\'', re.S)
pagenum = pattern.findall(req.text)
pagenum = int(pagenum[0])
print ("关键词[{0:s} -> {1:d}页搜索结果。".format(keyword, pagenum))
return pagenum
抓取更多的关键词
在你搜索关键词的时候,在其页面的最下方有可能会出现相关搜索块。不同页码的相关搜索词是一样的,这里有个技巧,就是把这部分代码合并到获取总页数的代码里面去。

相关的代码是这样的:
soup = BeautifulSoup(req.text, 'lxml')
hintbox = soup.find_all('div', class_='hintBox')
if hintbox:
tds = hintbox[0].find_all('td')
start_indexs += [td.text for td in tds]
print ("{0:s} -> {1:d}个新关键词, 当前关键词列表长度[{2:d}]。".format(keyword, len(tds), len(start_indexs)))
这个start_indexs就是存储所有关键词的列表。
捋一捋头绪
现在已经可以写出大概的框架了:
- 抓取百度指数和搜狗指数,获得初始的关键词。
- 开启若干协程,每个协程处理一个关键词,过程如下:
- 访问一个大页码页面,获取这个关键词的结果的总页数和相关搜索词
- 构建每个页面的URL。
- 爬取每个页面中的内容,每一条搜索结果会放在一个
class为vrwarp或rb的div里。 - 保存到本地。
- 协程处理完一个关键词后会获取下一个关键词,直到关键词列表为空。
有什么问题
正常的逻辑是没有问题的,但是如果按照这样代码后,简单跑一跑你就会发现新的问题,其中最大的一个问题就是反爬虫。
反爬虫-验证码
通过一定的抓包分析,很容易可以看出搜狗搜索的反爬虫是基于Cookie中某些字段的。搜狗搜索的反爬虫的机制是验证码,一旦系统觉得你可疑之后,就会返回一个如:http://www.sogou.com/antispider/?from=%2fweixin%3Ftype%3d2%26query%3d%E6%97%A5%E6%9C%AC%E5%A4%A7%E9%98%AA%E5%9C%B0%E9%9C%87的URL,from`后面就是你原本访问的地址。
页面中会包含一个验证码需要你填写。经过我的测试,不带Cookie的话,大概连续访问80-100次就会触发反爬虫;带Cookie的话,可以访问130-160次左右。
正如上文所说,搜狗搜索的反爬虫是基于Cookie的。在触发反爬虫后,你需要填写正确的验证码来获取新的Cookie值。但是这里我们选择避开这个问题,通过控制Cookie的值,我们可以做到不触发反爬虫机制。那么方法就很简单了:每访问100次更新一次Cookie。
关于验证码的处理,我会在下一篇爬取搜狗微信文章中具体解释。
Cookie值
具体看看有哪些Cookie值。有的时候,页面会返回很多奇奇怪怪的Cookie,比如说:
IPLOC=US; ABTEST=8|1529453119|v17;
SUID=4BAE8C452320940A000000005B299A3F;
SUV=00D80B85458CAE4B5B299A407EA3A580;
SUIR=9B61438AD0CAA0D7422ED70FD00D8985;
SNUID=896F4E87C1C7ADCA017D04E2C25EB76B; browerV=3; osV=1; sogou_vr_newstopic_headnews_lasttab=%E6%97%B6%E8%AE%AF%E7%BD%91;
sogou_vr_newstopic_headnews_showed=%E7%BB%B4%E6%B0%AA%E7%BD%91%7C%E6%97%B6%E8%AE%AF%E7%BD%91;
sogou_vr_newstopic_subnews1_lasttab=%E7%BB%B4%E6%B0%AA%E7%BD%91;
sogou_vr_newstopic_subnews1_showed=%E6%97%B6%E8%AE%AF%E7%BD%91%7C%E7%BB%B4%E6%B0%AA%E7%BD%91;
PHPSESSID=6bfvgh72fpr1oj734tokkeosk2; sct=7;
ld=Mlllllllll2b3NH5lllllV7If5YlllllSYhmvZllll6lllllVllll5@@@@@@@@@@;
LSTMV=1025%2C292; LCLKINT=265; sst0=8
经过我的测试,大部分不重要,常见的几个是:
IPLOC=US;
ABTEST=8|1529453119|v17;
SUID=4BAE8C452320940A000000005B299A3F;
SUV=00D80B85458CAE4B5B299A407EA3A580;
SNUID=896F4E87C1C7ADCA017D04E2C25EB76B;
browerV=3;
osV=1;
ld=Mlllllllll2b3NH5lllllV7If5YlllllSYhmvZllll6lllllVllll5@@@@@@@@@@;
这里面又是SUID、SUV和SNUID最为重要,可以看到这三个值都是32位,看起来很像MD5值。这点我不确定,不过不影响。
SUV实际上是基于当前时间的随机数,但是我测试后发现它的值其实对结果没有影响,因此我们要更新的主要对象就是SUID和SNUID。
如何更新
这里的更新很简单,就是随便访问一个搜索页面,然后将其返回的Cookie值保存下来,这里面是肯定有SUID和SNUID两个值的。之后没爬取100个页面就用同样的方法更新一次Cookie。更新Cookie的代码如下:
def get_one_cookie():
url = "https://www.sogou.com/web?query=%E6%90%9C%E7%8B%97%E8%81%94%E7%9B%9F%E7%99%BB%E5%BD%95&page=1"
r = requests.ohRequests()
req = r.get(url)
cookies = req.cookies.get_dict()
cookies['browerV'] = '3'
cookies['osV'] = '1'
cookies['sct'] = '3'
cookies['sst0'] = '552'
cookies['SUV'] = '005E5558458CAE4B5B248FD6FBCA1033'
return cookies
去重
关于去重,有两种选择,一种是基于关键词去重,一种是基于抓取到的URL去重。个人觉得后者会好一点,我这里用的是md5(抓取对象的标题+URL)。
真实URL解析
抓取到的URL很多时候不会其真实的URL地址,你需要进行额外的一次访问才能获取到其真实的URL。如果你直接访问抓取的URL,会返回一个类似下面的页面:
其真实URL就一目了然了。
主要抓取代码
async def parse():
cnt = 1
cookies = get_one_cookie()
while start_indexs:
index = start_indexs.pop(0)
pn = get_pagenum(index, cookies)
# anti-spider
if pn == 0:
cookies = get_one_cookie()
for i in range(1, int(pn)+1):
keyword = index
page = i
if (cnt-1) % 100 == 0:
cookies = get_one_cookie()
print ("更新Cookies。", cookies)
url = "https://www.sogou.com/web?query={0:s}&page={1:d}".format(keyword, page)
headers = {}
headers['referer'] = "https://www.sogou.com/"
headers['user-agent'] = choice(requests.FakeUserAgents)
async with aiohttp.request('GET', url, cookies=cookies, headers=headers) as response:
req = await response.text()
soup = BeautifulSoup(req, 'lxml')
def is_result_container(css_class):
return css_class in ['vrwrap', 'rb']
vrwraps = soup.find_all('div', class_=is_result_container)
pattern = re.compile('(\d+-\d+-\d+)', re.S)
res = []
for vrwrap in vrwraps:
title = link = time = None
try:
title = vrwrap.find('h3').a.text.strip()
link = vrwrap.find('h3').a.get('href').strip()
time = pattern.findall(vrwrap.find('div', class_='fb').text.strip())[0]
except:
pass
if not title or not link:
continue
md5 = hashlib.md5()
md5.update((title+link).encode('utf8'))
md5 = md5.hexdigest()
res.append((str(md5), keyword, page, url, title, link, time,))
if not res:
cookies = antispider_check(url)
print (cnt, len(res), keyword, page)
async with aiosqlite.connect('sogou.sqlite3') as db:
await db.executemany('INSERT INTO sogou VALUES (?,?,?,?,?,?,?)', res)
await db.commit()
cnt += 1
await asyncio.sleep(randint(1,5)/10)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
coros = []
for i in range(6):
coros.append(parse())
loop.run_until_complete(asyncio.gather(*coros))
使用到的模块有:
import ohRequests as requests
from bs4 import BeautifulSoup
from random import choice, randint
import re
import json
import time
import sqlite3
import hashlib
import asyncio
import aiohttp
import aiosqlite
性能
我这里只跑了一个进程,6个协程。这里如果IP不变的话,简单增加进程数是没有意义的,额外的进程需要使用代理IP才行。
单进程六协程的,每个协程在抓完一个页面后阻塞0.1-0.5秒。每爬取100个页面更新一次Cookie,我跑了4个小时,没有触发一次反爬虫机制。4个小时共抓取了32w条搜索结果。
一个问题
在我跑了4个小时候后,出现了问题:database is locked。我使用了sqlite3作为后端数据库,后来我查了一下,原来sqlite3是不支持多线程写入的(4个小时才出问题算很神奇了)。解决的方法话,如果不想换数据库,可以有两种方法:
- 自己封装实现一个库级锁。
- 将抓取结果写入一个队列,然后再起一个线程专门用来将队列中的数据写入数据库。