扩展阅读:
- Apache Kylin 概览 -
- 可能是全网最深度的 Apache Kylin 查询剖析 -
一、Overview
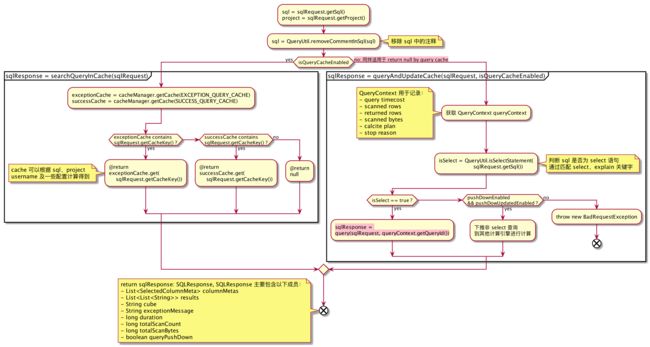
1.1、通过 Kylin 查询
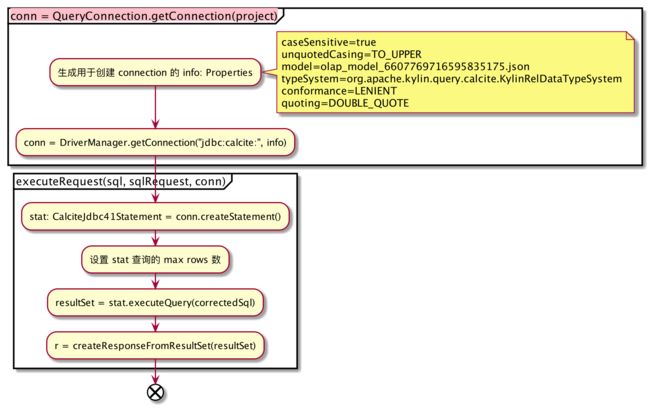
其中 olap_model_6607769716595835175.json 内容如下:
{
"version": "1.0",
"defaultSchema": "DEFAULT",
"schemas": [
{
"type": "custom",
"name": "DEFAULT",
"factory": "org.apache.kylin.query.schema.OLAPSchemaFactory",
"operand": {
"project": "learn_kylin"
},
"functions": [
{
name: 'PERCENTILE',
className: 'org.apache.kylin.measure.percentile.PercentileAggFunc'
},
{
name: 'CONCAT',
className: 'org.apache.kylin.query.udf.ConcatUDF'
},
{
name: 'MASSIN',
className: 'org.apache.kylin.query.udf.MassInUDF'
},
{
name: 'INTERSECT_COUNT',
className: 'org.apache.kylin.measure.bitmap.BitmapIntersectDistinctCountAggFunc'
},
{
name: 'VERSION',
className: 'org.apache.kylin.query.udf.VersionUDF'
},
{
name: 'PERCENTILE_APPROX',
className: 'org.apache.kylin.measure.percentile.PercentileAggFunc'
}
]
}
]
}
最主要的是指定了:
- schema factory class:
org.apache.kylin.query.schema.OLAPSchemaFactory - project: learn_kylin
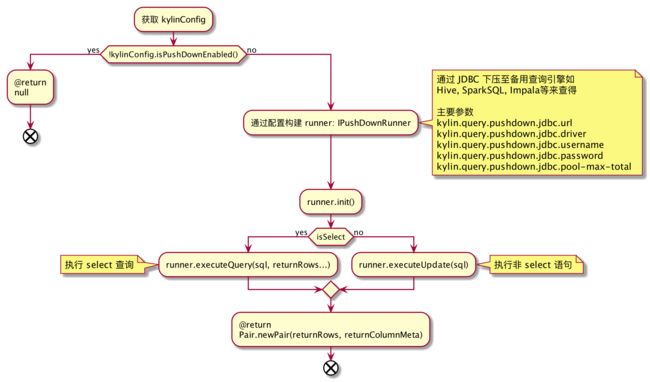
1.2、下推到其他计算引擎
二、OLAPSchemaFactory & OLAPSchema
在上文中提到,通过 calcite jdbc 创建 connection 的时候,指定了 schema facotry 为 org.apache.kylin.query.schema.OLAPSchemaFactory , 即在 validate 的过程中会使用 OLAPSchemaFactory 创建 Scehma。
OLAPSchemaFactory 继承于 calcite SchemaFactory,用于 create Scehma。Scehma 主要用于获取 table、function、subSchema 等元数据,类图如下
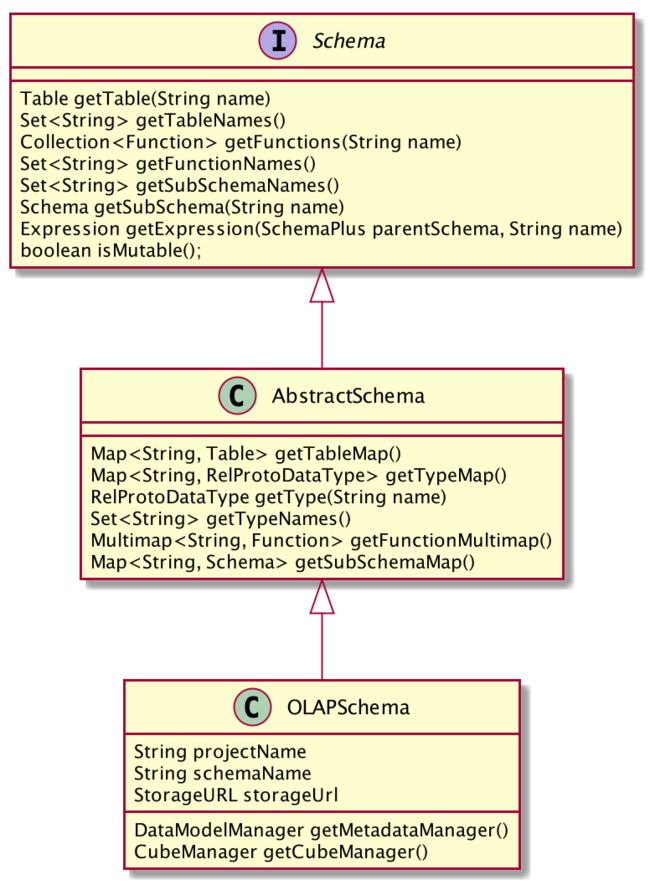
OLAPSchemaFactory#create 如下,创建的 Schema 为 OLAPSchema 类型:
public Schema create(SchemaPlus parentSchema, String schemaName, Map operand) {
String project = (String) operand.get(SCHEMA_PROJECT);
Schema newSchema = new OLAPSchema(project, schemaName, exposeMore(project));
return newSchema;
}
所以在 validate 的过程中,会通过调用 OLAPSchema#getTable 去替换一个 SqlIdentifier,OLAPSchema#getTable 得到的是一个 OLAPTable
2.1、OLAPTable
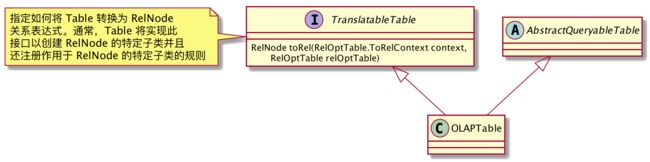
toRel 方法如下,得到一个 OLAPTableScan
public RelNode toRel(ToRelContext context, RelOptTable relOptTable) {
int fieldCount = relOptTable.getRowType().getFieldCount();
int[] fields = identityList(fieldCount);
return new OLAPTableScan(context.getCluster(), relOptTable, this, fields);
}
三、Kylin 自定义 rules 及 RelNode
以下面这条 sql 为例:
SELECT KYLIN_SALES.TRANS_ID, SUM(KYLIN_SALES.PRICE), COUNT(KYLIN_ACCOUNT.ACCOUNT_ID)
FROM KYLIN_SALES
INNER JOIN KYLIN_ACCOUNT ON KYLIN_SALES.BUYER_ID = KYLIN_ACCOUNT.ACCOUNT_ID
WHERE KYLIN_SALES.LSTG_SITE_ID != 1000
GROUP BY KYLIN_SALES.TRANS_ID
ORDER BY TRANS_ID
LIMIT 10;
3.1、SqlNode
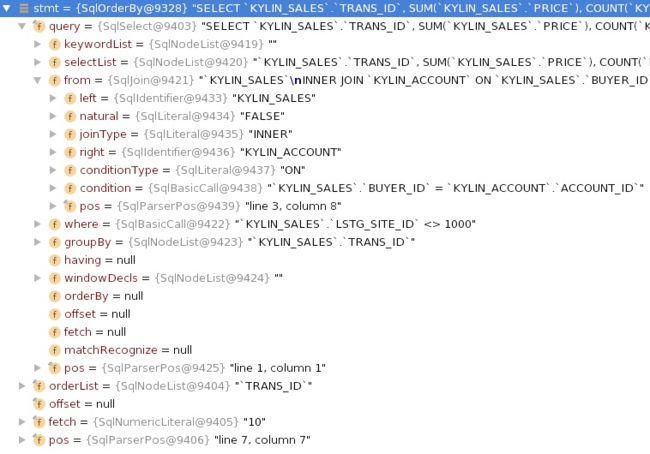
3.2、HepPlanner 优化后的 RelNode
LogicalSort(sort0=[$0], dir0=[ASC], fetch=[10])
LogicalAggregate(group=[{0}], EXPR$1=[SUM($1)], EXPR$2=[COUNT($2)])
LogicalProject(TRANS_ID=[$0], PRICE=[$5], ACCOUNT_ID=[$13])
LogicalFilter(condition=[<>($4, 1000)])
LogicalJoin(condition=[=($7, $13)], joinType=[inner])
OLAPTableScan(table=[[DEFAULT, KYLIN_SALES]], ctx=[], fields=[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]])
OLAPTableScan(table=[[DEFAULT, KYLIN_ACCOUNT]], ctx=[], fields=[[0, 1, 2, 3, 4, 5]])
在 SqlNode 转成 RelNode 的过程中,会调用到 SqlToRelConverter#convertFrom,对于 SqlIdentity 会执行:
- 通过 validator 获取该 idt 的 OLAPTable
- 调用 OLAPTable.toRel 得到 OLAPTableScan(已在上文描述)
这样 SqlIdentity 就转成了 OLAPTableScan,类图如上

3.3、VolcanoPlanner 优化后的 OLAPRelNode
在 optimize 过程中,在真正调用 VolcanoPlanner 进行 optimize 之前,会遍历整个树,对于 TableScan 类型的节点调用其 register 方法。对于 OLAPTableScan 来说,通过 OLAPTableScan#register 将 Kylin 自定义的 OLAP rules 添加到 planner 中(并删除一些不需要的 rules),最终这些 rules 会应用到 RelNode 上。新增的 rules:
- OLAPToEnumerableConverterRule: RelNode -> OLAPToEnumerableConverter
- OLAPFilterRule: LogicalFilter -> OLAPFilterRel
- OLAPProjectRule: LogicalProject -> OLAPProjectRel
- OLAPAggregateRule: LogicalAggregate -> OLAPAggregateRel
- OLAPJoinRule: LogicalJoin -> OLAPJoinRel/OLAPFilterRel
- OLAPLimitRule: Sort -> OLAPLimitRel
- OLAPSortRule: Sort -> OLAPSortRel
- OLAPUnionRule: Union -> OLAPUnionRel
- OLAPWindowRule: Window -> OLAPWindowRel
- OLAPValuesRule: LogicalValues -> OLAPValuesRel
public void register(RelOptPlanner planner) {
// force clear the query context before traversal relational operators
OLAPContext.clearThreadLocalContexts();
// register OLAP rules
addRules(planner, kylinConfig.getCalciteAddRule());
planner.addRule(OLAPToEnumerableConverterRule.INSTANCE);
planner.addRule(OLAPFilterRule.INSTANCE);
planner.addRule(OLAPProjectRule.INSTANCE);
planner.addRule(OLAPAggregateRule.INSTANCE);
planner.addRule(OLAPJoinRule.INSTANCE);
planner.addRule(OLAPLimitRule.INSTANCE);
planner.addRule(OLAPSortRule.INSTANCE);
planner.addRule(OLAPUnionRule.INSTANCE);
planner.addRule(OLAPWindowRule.INSTANCE);
planner.addRule(OLAPValuesRule.INSTANCE);
planner.addRule(AggregateProjectReduceRule.INSTANCE);
// CalcitePrepareImpl.CONSTANT_REDUCTION_RULES
if (kylinConfig.isReduceExpressionsRulesEnabled()) {
planner.addRule(ReduceExpressionsRule.PROJECT_INSTANCE);
planner.addRule(ReduceExpressionsRule.FILTER_INSTANCE);
planner.addRule(ReduceExpressionsRule.CALC_INSTANCE);
planner.addRule(ReduceExpressionsRule.JOIN_INSTANCE);
}
removeRules(planner, kylinConfig.getCalciteRemoveRule());
if (!kylinConfig.isEnumerableRulesEnabled()) {
for (RelOptRule rule : CalcitePrepareImpl.ENUMERABLE_RULES) {
planner.removeRule(rule);
}
}
// since join is the entry point, we can't push filter past join
planner.removeRule(FilterJoinRule.FILTER_ON_JOIN);
planner.removeRule(FilterJoinRule.JOIN);
// since we don't have statistic of table, the optimization of join is too cost
planner.removeRule(JoinCommuteRule.INSTANCE);
planner.removeRule(JoinPushThroughJoinRule.LEFT);
planner.removeRule(JoinPushThroughJoinRule.RIGHT);
// keep tree structure like filter -> aggregation -> project -> join/table scan, implementOLAP() rely on this tree pattern
planner.removeRule(AggregateJoinTransposeRule.INSTANCE);
planner.removeRule(AggregateProjectMergeRule.INSTANCE);
planner.removeRule(FilterProjectTransposeRule.INSTANCE);
planner.removeRule(SortJoinTransposeRule.INSTANCE);
planner.removeRule(JoinPushExpressionsRule.INSTANCE);
planner.removeRule(SortUnionTransposeRule.INSTANCE);
planner.removeRule(JoinUnionTransposeRule.LEFT_UNION);
planner.removeRule(JoinUnionTransposeRule.RIGHT_UNION);
planner.removeRule(AggregateUnionTransposeRule.INSTANCE);
planner.removeRule(DateRangeRules.FILTER_INSTANCE);
planner.removeRule(SemiJoinRule.JOIN);
planner.removeRule(SemiJoinRule.PROJECT);
// distinct count will be split into a separated query that is joined with the left query
planner.removeRule(AggregateExpandDistinctAggregatesRule.INSTANCE);
// see Dec 26th email @ http://mail-archives.apache.org/mod_mbox/calcite-dev/201412.mbox/browser
planner.removeRule(ExpandConversionRule.INSTANCE);
}
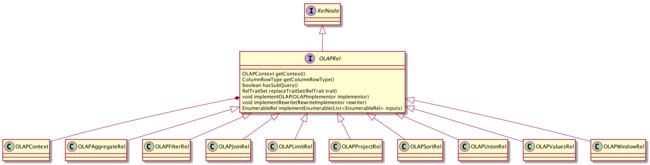
VolcanoPlanner 优化后的 RelNode 如下:
OLAPToEnumerableConverter
OLAPLimitRel(ctx=[], fetch=[10])
OLAPSortRel(sort0=[$0], dir0=[ASC], ctx=[])
OLAPAggregateRel(group=[{0}], EXPR$1=[SUM($1)], EXPR$2=[COUNT($2)], ctx=[])
OLAPProjectRel(TRANS_ID=[$0], PRICE=[$5], ACCOUNT_ID=[$13], ctx=[])
OLAPFilterRel(condition=[<>($4, 1000)], ctx=[])
OLAPJoinRel(condition=[=($7, $13)], joinType=[inner], ctx=[])
OLAPTableScan(table=[[DEFAULT, KYLIN_SALES]], ctx=[], fields=[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]])
OLAPTableScan(table=[[DEFAULT, KYLIN_ACCOUNT]], ctx=[], fields=[[0, 1, 2, 3, 4, 5]])
3.4、各个 OLAPRule、OLAPRel 剖析
四、选择 Realization 逻辑
整个过程封装在 RealizationChooser#attemptSelectRealization 中,核心流程如下图:
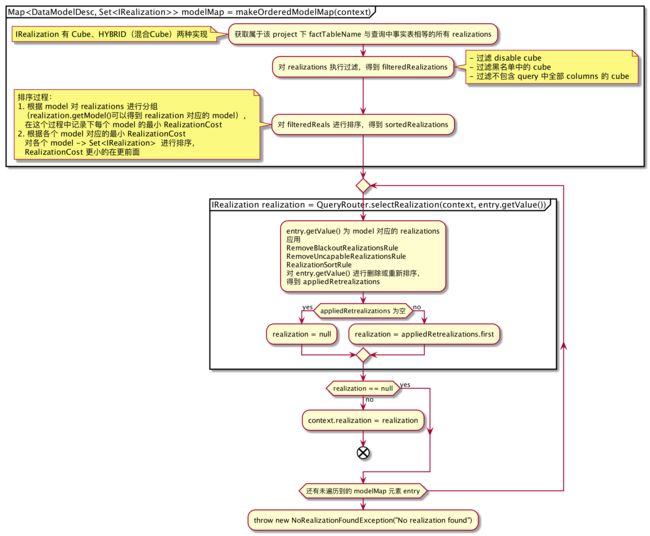
4.1、Realization 分类
分为 Cube 和 HYBRID 两类,其中 HYBRID 是一个或多个其他实现(Cube)的组合。假设用户有一个名为 Cube_V1 的多维数据集,它已经建立了几个月; 现在,用户希望添加新的维度或指标以满足其业务需求; 于是他创建了一个名为 Cube_V2 的新立方体。由于某些原因用户想要保留 Cube_V1 ,并且期望从 Cube_V1 的结束日期开始构建 Cube_V2 ; 可能的原因包括:
- 历史源数据已从 Hadoop 中删除,从一开始就无法构建 Cube_V2
- Cube 很大,重建需要很长时间
- 新维度/指标仅在某一天有效或应用;
对于针对通用维度/指标的查询,用户期望扫描 Cube_V1 和 Cube_V2 以获得完整的结果集; 在这样的背景下,引入 HTBRID(混合模型)来解决这个问题,如下:
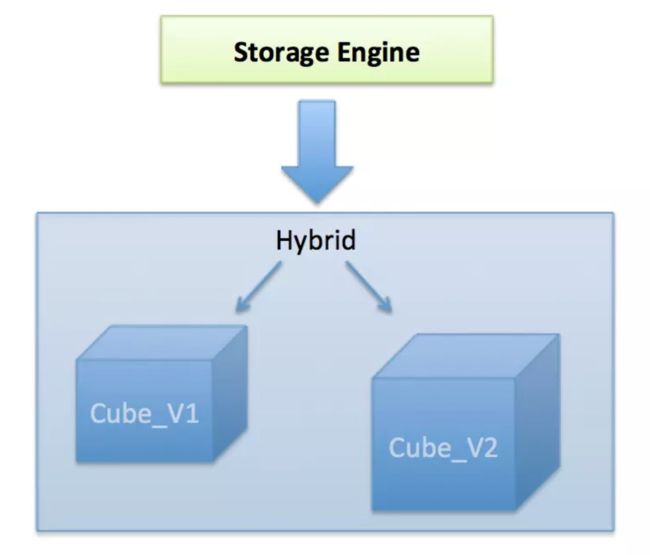
- 混合模型没有真正的存储空间; 它就像在表格上的虚拟数据库视图一样
- 混合实例充当委托者,将请求转发给其子实现,然后在从实例返回时合并结果
- 混合模型的目的是连接历史 Cube 和新 Cube,类似 union
- 若同时有 Cube 和 HYBRID 满足某一个查询,优先使用 HYBRID,因为其数据更全
4.2、RealizationCost 的 cost 如何计算?
public int CubeInstance#getCost() {
// COST_WEIGHT_MEASURE = 1;
// COST_WEIGHT_DIMENSION = 10;
// COST_WEIGHT_INNER_JOIN = 100;
// 组成 rowKey 的 col 个数
int countedDimensionNum = getRowKeyColumnCount();
int c = countedDimensionNum * COST_WEIGHT_DIMENSION + getMeasures().size() * COST_WEIGHT_MEASURE;
DataModelDesc model = getModel();
for (JoinTableDesc join : model.getJoinTables()) {
if (join.getJoin().isInnerJoin())
c += CubeInstance.COST_WEIGHT_INNER_JOIN;
}
return c;
}
public int HybridInstance#getCost() {
int c = Integer.MAX_VALUE;
for (IRealization realization : getRealizations()) {
c = Math.min(realization.getCost(), c);
}
return c;
}
需要讨论:
- 为什么 left join 不像 inner join 会使得 cost 变大?
4.3、RealizationCost 如何比较
- realization 优先级更高的会优先被使用(Cube 类型的 IRealization 优先级小于 HYBRID 类型的 IRealization)
- 若两个 realization 都不存在优先级,则 cost 更小的会被优先使用
-
RemoveBlackoutRealizationsRule:符合以下几种情况的 realization 会被移除:- 黑名单中的
- 当白名单不为空,不在白名单中的
- 被配置
kylin.query.realization-filter过滤的
-
RemoveUncapableRealizationsRule:移除不适用的,详见下文 isCapable 分析 -
RealizationSortRule:对适用(应用RemoveBlackoutRealizationsRule和RemoveUncapableRealizationsRule后还在的)的 realizations 进行排序,排序规则是优先级更高的 realization 排在更前面,若均不存在优先级,则 cost 更小的排在更前面
4.4、CapabilityResult IRealization#isCapable(...)
CapabilityResult 包含:
boolean capableint costIncapableCause incapableCause
CubeInstance#isCapable 主要判断 Cube 所具备的维度和度量是否能满足查询需要的,只有
查询的维度组合是 Cube 的维度组合或其子集
查询的度量组合是 Cube 的度量组合或其子集才能满足,否则 isCapable 均返回 false
若整个 attemptSelectRealization 结束发现没有满足的 realization,则会抛 NoRealizationFoundException 异常
若获取到了 realization,会设置为
olapContext的 realization,会在OLAPEnumerator#queryStorage中使用
五、Cuboid/Segment 查询
OLAPTableScan 真正扫描时会触发 Cuboid/Segment 的查询,核心流程如下:
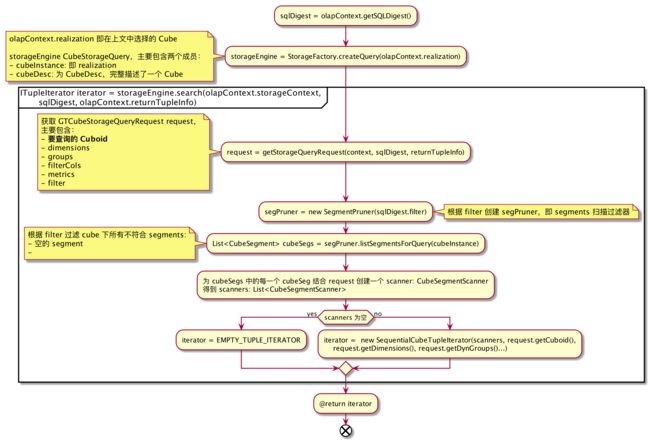
5.1、Cuboid 选择
在 Cuboid#findCuboid 中实现:
public static Cuboid findCuboid(CuboidScheduler cuboidScheduler, Set dimensions,
Collection metrics) {
long cuboidID = toCuboidId(cuboidScheduler.getCubeDesc(), dimensions, metrics);
return Cuboid.findById(cuboidScheduler, cuboidID);
}
cuboidID 计算方式如下:
public static long toCuboidId(CubeDesc cubeDesc, Set dimensions, Collection metrics) {
for (FunctionDesc metric : metrics) {
if (metric.getMeasureType().onlyAggrInBaseCuboid())
return Cuboid.getBaseCuboidId(cubeDesc);
}
long cuboidID = 0;
// dimensions 包含 group 列和 where 条件列
for (TblColRef column : dimensions) {
// 获取维度列在 rowKey 中的 index
int index = cubeDesc.getRowkey().getColumnBitIndex(column);
// 见如下示例
cuboidID |= 1L << index;
}
return cuboidID;
}
下面举个简单的例子,假设表一共有三列ABC,那么所有的 cuboid 组合就是:
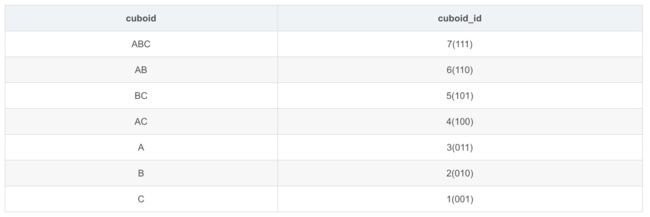
5.2、CubeSegmentScanner 内部流程
SequentialCubeTupleIterator 最终是要调用 CubeSegmentScanner 去获取 Cuboid 数据。
在对每个 segment 进行扫描的时候,首先需要根据筛选到的 cuboid id 去获取相应的 region 信息(主要是起始region id 和 region数)。
这样就可以获取每个 segment 需要扫描的region,由于 Kylin 目前的数据都存储在 HBase 当中,因此扫描的过程都在 HBase中进行。对于每个 region,都会启动一个线程来向 HBase 发送扫描请求,然后将所有扫描的结果返回,聚合之后再返回上一层。为了加快扫描效率,Kylin 还使用了 HBase 的 coprocessor 来对每个region的扫描结果进行预聚合。