一文看懂PCA主成分分析中介绍了PCA分析的原理和分析的意义(基本简介如下,更多见博客),今天就用数据来实际操练一下。
在生信宝典公众号后台回复“PCA实战”,获取测试数据。
一、PCA应用
# 加载需要用到的R包library(psych)
library(reshape2)
library(ggplot2)
library(factoextra)
1. 数据初始化
# 基因表达数据
exprData <- "ehbio_salmon.DESeq2.normalized.symbol.txt"
# 非必须
sampleFile <- "sampleFile"
2. 数据读入
# 为了保证文章的使用,文末附有数据的新下载链接,以防原链接失效
data <- read.table(exprData, header=T, row.names=NULL,sep="\t")
# 处理重复名字,谨慎处理,先找到名字重复的原因再决定是否需要按一下方式都保留
rownames_data <- make.names(data[,1],unique=T)
data <- data[,-1,drop=F]
rownames(data) <- rownames_data
data <- data[rowSums(data)>0,]
# 去掉方差为0 的行,这些本身没有意义,也妨碍后续运算
data <- data[apply(data, 1, var)!=0,]
3. 数据预处理(可选)
# 计算中值绝对偏差 (MAD, median absolute deviation)度量基因表达变化幅度
# 在基因表达中,尽管某些基因很小的变化会导致重要的生物学意义,
# 但是很小的观察值会引入很大的背景噪音,因此也意义不大。
# 可以选择根据mad值过滤,取top 50, 500等做分析
mads <- apply(data, 1, mad)data <- data[rev(order(mads)),]
# 此处未选
# data <- data[1:500,]
dim(data)
4. PCA分析
# Pay attention to the format of PCA input
# Rows are samples and columns are variables
data_t <- t(data)
variableL <- ncol(data_t)
if(sampleFile != "") {
sample <- read.table(sampleFile,header = T, row.names=1,sep="\t")
data_t_m <- merge(data_t, sample, by=0)
rownames(data_t_m) <- data_t_m$Row.names
data_t <- data_t_m[,-1]
}
# By default, prcomp will centralized the data using mean.
# Normalize data for PCA by dividing each data by column standard deviation.# Often, we would normalize data.
# Only when we care about the real number changes other than the trends,
# `scale` can be set to TRUE.
# We will show the differences of scaling and un-scaling effects.
pca <- prcomp(data_t[,1:variableL], scale=T)
# sdev: standard deviation of the principle components.
# Square to get variance
# percentVar <- pca$sdev^2 / sum( pca$sdev^2)
# To check what's in pca
print(str(pca))
5. PCA结果展示
# PCA结果提取和可视化神器
# http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/112-pca-principal-component-analysis-essentials/
library(factoextra)
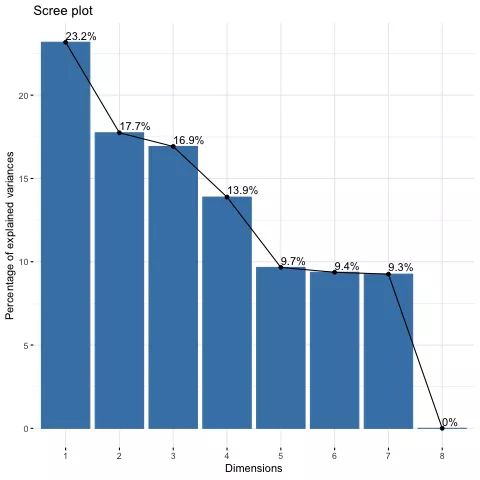
1. 碎石图展示每个主成分的贡献
# 如果需要保持,去掉下面第1,3行的注释
#pdf("1.pdf")
fviz_eig(pca, addlabels = TRUE)
#dev.off()
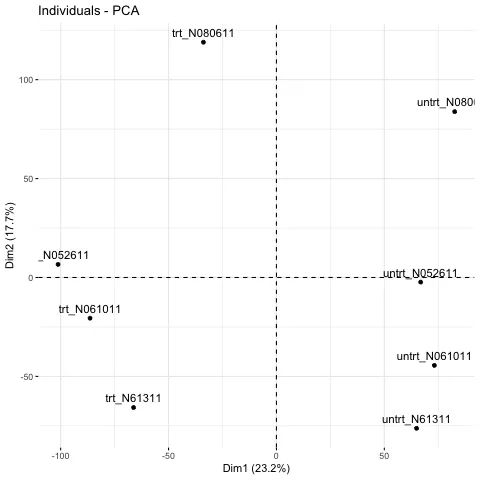
2. PCA样品聚类信息展示
# repel=T,自动调整文本位置
fviz_pca_ind(pca, repel=T)
3. 根据样品分组上色
# 根据分组上色并绘制
fviz_pca_ind(pca, col.ind=data_t$conditions, mean.point=F, addEllipses = T, legend.title="Groups")
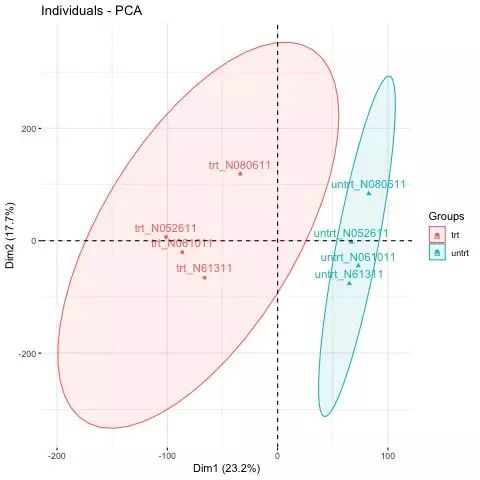
4. 增加不同属性的椭圆
“convex”: plot convex hull of a set o points.
“confidence”: plot confidence ellipses around group mean points as the function coord.ellipse() [in FactoMineR].
“t”: assumes a multivariate t-distribution.
“norm”: assumes a multivariate normal distribution.
“euclid”: draws a circle with the radius equal to level, representing the euclidean distance from the center. This ellipse probably won’t appear circular unless coord_fixed() is applied.
# 根据分组上色并绘制95%置信区间
fviz_pca_ind(pca, col.ind=data_t$conditions, mean.point=F, addEllipses = T, legend.title="Groups", ellipse.type="confidence", ellipse.level=0.95)

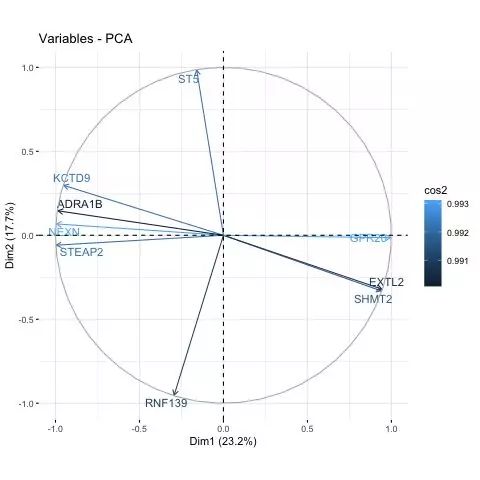
5. 展示贡献最大的变量 (基因)
1) 展示与主坐标轴的相关性大于0.99的变量 (具体数字自己调整)
# Visualize variable with cos2 >= 0.99
fviz_pca_var(pca, select.var = list(cos2 = 0.99), repel=T, col.var = "cos2", geom.var = c("arrow", "text") )
2)展示与主坐标轴最相关的10个变量
# Top 10 active variables with the highest cos2
fviz_pca_var(pca, select.var= list(cos2 = 10), repel=T, col.var = "contrib")
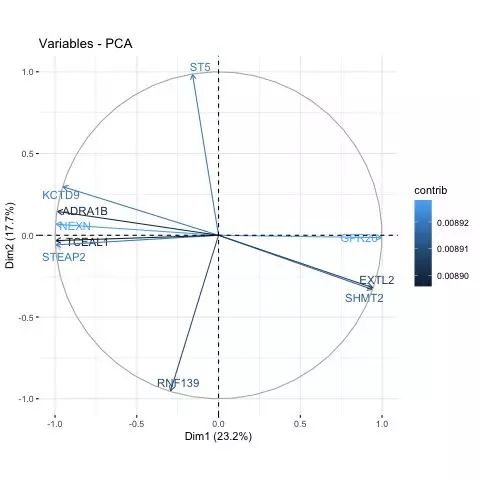
3)展示自己关心的变量(基因)与主坐标轴的相关性分布
# Select by names
# 这里选择的是MAD值最大的几个基因
name <- list(name = c("FN1", "DCN", "CEMIP","CCDC80","IGFBP5","COL1A1","GREM1"))
fviz_pca_var(pca, select.var = name)
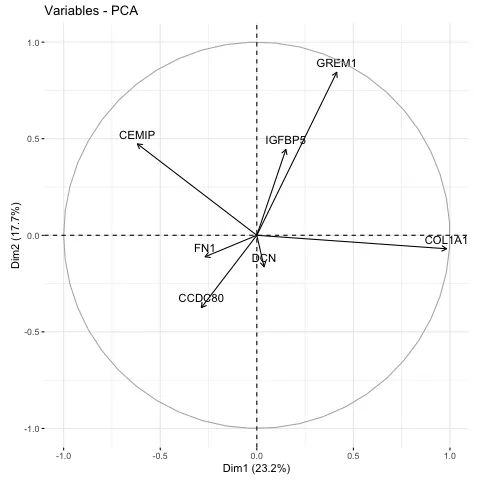
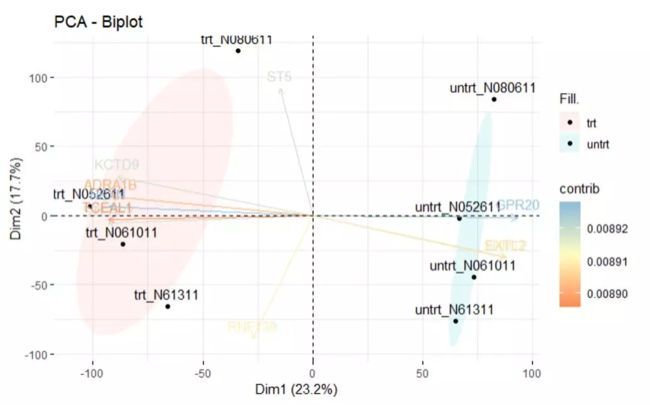
6. biPLot同时展示样本分组和关键基因
# top 5 contributing individuals and variable
fviz_pca_biplot(pca,
fill.ind=data_t$conditions,
palette="joo",
addEllipses = T,
ellipse.type="confidence",
ellipse.level=0.95,
mean.point=F,
col.var="contrib",
gradient.cols = "RdYlBu",
select.var = list(contrib = 10),
ggtheme = theme_minimal())
二、PCA分析注意事项
一般说来,在PCA之前原始数据需要中心化(centering,数值减去平均值)。中心化的方法很多,除了平均值中心化(mean-centering)外,还包括其它更稳健的方法,比如中位数中心化等。
除了中心化以外,定标 (Scale, 数值除以标准差) 也是数据前处理中需要考虑的一点。如果数据没有定标,则原始数据中方差大的变量对主成分的贡献会很大。数据的方差与其量级成指数关系,比如一组数据
(1,2,3,4)的方差是1.67,而(10,20,30,40)的方差就是167,数据变大10倍,方差放大了100倍。但是定标(scale)可能会有一些负面效果,因为定标后变量之间的权重就是变得相同。如果我们的变量中有噪音的话,我们就在无形中把噪音和信息的权重变得相同,但PCA本身无法区分信号和噪音。在这样的情形下,我们就不必做定标。
一般而言,对于度量单位不同的指标或是取值范围彼此差异非常大的指标不直接由其协方差矩阵出发进行主成分分析,而应该考虑对数据的标准化。比如度量单位不同,有万人、万吨、万元、亿元,而数据间的差异性也非常大,小则几十大则几万,因此在用协方差矩阵求解主成分时存在协方差矩阵中数据的差异性很大。在后面提取主成分时发现,只提取了一个主成分,而此时并不能将所有的变量都解释到,这就没有真正起到降维的作用。此时就需要对数据进行定标(scale),这样提取的主成分可以覆盖更多的变量,这就实现主成分分析的最终目的。但是对原始数据进行标准化后更倾向于使得各个指标的作用在主成分分析构成中相等。对于数据取值范围不大或是度量单位相同的指标进行标准化处理后,其主成分分析的结果与仍由协方差矩阵出发求得的结果有较大区别。这是因为对数据标准化的过程实际上就是抹杀原有变量离散程度差异的过程,标准化后方差均为1,而实际上方差是对数据信息的重要概括形式,也就是说,对原始数据进行标准化后抹杀了一部分重要信息,因此才使得标准化后各变量在主成分构成中的作用趋于相等。因此,对同度量或是取值范围在同量级的数据还是直接使用非定标数据求解主成分为宜。
中心化和定标都会受数据中离群值(outliers)或者数据不均匀(比如数据被分为若干个小组)的影响,应该用更稳健的中心化和定标方法。
PCA也存在一些限制,例如它可以很好的解除线性相关,但是对于高阶相关性就没有办法了,对于存在高阶相关性的数据,可以考虑Kernel PCA,通过Kernel函数将非线性相关转为线性相关,关于这点就不展开讨论了。另外,PCA假设数据各主特征是分布在正交方向上,如果在非正交方向上存在几个方差较大的方向,PCA的效果就大打折扣了。
参考资料
https://www.zhihu.com/question/20998460
http://blog.csdn.net/zhongkelee/article/details/44064401
http://www.xiaolingzi.com/?p=963
http://wenku.baidu.com/link?url=hsnzR5gUvsPBwkwwcWU4T3aTSC_fsZDxAmaGGBPfumsIW_I0TJAdJEWhFyiQgw7uA58DKukR-9g5x0DyzE97kHddMaXOxk_iZBjoIdbdB6e
http://stackoverflow.com/questions/22092220/plot-only-y-axis-but-nothing-else
http://www.sthda.com/english/wiki/scatterplot3d-3d-graphics-r-software-and-data-visualization
http://dong.farbox.com/32
http://www.nlpca.org/pca_principal_component_analysis.html
http://gastonsanchez.com/how-to/2014/01/15/Center-data-in-R/
http://www.statpower.net/Content/310/R Stuff/SampleMarkdown.html
http://www2.edu-edu.com.cn/lesson_crs78/self/02198/resource/contents/ch_05/ch_05.html
http://www.sthda.com/english/wiki/principal-component-analysis-in-r-prcomp-vs-princomp-r-software-and-data-mining
http://stackoverflow.com/questions/1249548/side-by-side-plots-with-ggplot2
https://satijalab.org/seurat/pbmc3k_tutorial.html
http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/112-pca-principal-component-analysis-essentials/
R统计和作图
在R中赞扬下努力工作的你,奖励一份CheatShet
别人的电子书,你的电子书,都在bookdown
R语言 - 入门环境Rstudio
R语言 - 热图绘制 (heatmap)
R语言 - 基础概念和矩阵操作
R语言 - 热图简化
R语言 - 热图美化
R语言 - 线图绘制
R语言 - 线图一步法
R语言 - 箱线图(小提琴图、抖动图、区域散点图)
R语言 - 箱线图一步法
R语言 - 火山图
R语言 - 富集分析泡泡图
R语言 - 散点图绘制
R语言 - 韦恩图
R语言 - 柱状图
R语言 - 图形设置中英字体
R语言 - 非参数法生存分析
R语言 - 绘制seq logo图
WGCNA分析,简单全面的最新教程
一文看懂PCA主成分分析
富集分析DotPlot,可以服
基因共表达聚类分析和可视化
R中1010个热图绘制方法
还在用PCA降维?快学学大牛最爱的t-SNE算法吧, 附Python/R代码
一个函数抓取代谢组学权威数据库HMDB的所有表格数据
文章用图的修改和排版
network3D: 交互式桑基图
network3D 交互式网络生成
Seq logo 在线绘制工具——Weblogo
生物AI插图素材获取和拼装指导
ggplot2高效实用指南 (可视化脚本、工具、套路、配色)
图像处理R包magick学习笔记
SOM基因表达聚类分析初探
利用gganimate可视化全球范围R-Ladies(R社区性别多样性组织)发展情况
一分钟绘制磷脂双分子层:AI零基础入门和基本图形绘制
AI科研绘图(二):模式图的基本画法
你知道R中的赋值符号箭头(<-)和等号(=)的区别吗?
R语言可视化学习笔记之ggridges包
利用ComplexHeatmap绘制热图(一)
ggplot2学习笔记之图形排列
R包reshape2,轻松实现长、宽数据表格转换
更多阅读
画图三字经生信视频生信系列教程
心得体会癌症数据库LinuxPython
高通量分析在线画图测序历史超级增强子
培训视频PPTEXCEL文章写作ggplot2
海哥组学可视化套路基因组浏览器
色彩搭配图形排版互作网络