转载自公众号:FightingCoder
一般情况下我们使用爬虫更多的应该是爬数据或者图片吧,今天在这里和大家分享一下关于使用爬虫技术来进行视频下载的方法,不仅可以方便的下载一些体积小的视频,针对大容量的视频下载同样试用。

先上个
requests模块的iter_content方法
这里我们使用的是python的requests模块作为例子,需要获取文本的时候我们会使用response.text获取文本信息,使用response.content获取字节流,比如下载图片保存到一个文件,而对于大个的文件我们就要采取分块读取的方式了,
requests.get方法的stream
第一步,我们需要设置requests.get的stream参数为True。
默认情况下是stream的值为false,它会立即开始下载文件并存放到内存当中,倘若文件过大就会导致内存不足的情况.
当把get函数的stream参数设置成True时,它不会立即开始下载,当你使用iter_content或iter_lines遍历内容或访问内容属性时才开始下载。需要注意一点:文件没有下载之前,它也需要保持连接。
iter_content:一块一块的遍历要下载的内容
iter_lines:一行一行的遍历要下载的内容
使用上面两个函数下载大文件可以防止占用过多的内存,因为每次只下载小部分数据。
示例代码:
r = requests.get(url_file, stream=True)
f = open("file_path", "wb")
for chunk in r.iter_content(chunk_size=512):
if chunk:
f.write(chunk)
上面的代码表示请求了url_file,这个url_file是一个大文件,所以开启了stream模式,然后通过迭代r对象的iter_content方法,同时指定chunk_size=512(即每次读取512个字节)来进行读取。但是如果仅仅是迭代是不行,如果下载中途出现问题我们之前的努力就白费了,所以我们需要做到一个断点续传的功能。
断点续传
所谓断点续传,也就是要从文件已经下载的地方开始继续下载。在以前版本的 HTTP 协议是不支持断点的,HTTP/1.1 开始就支持了。一般断点下载时会用到 header请求头的Range字段,这也是现在众多号称多线程下载工具(如 FlashGet、迅雷等)实现多线程下载的核心所在。

如何在代码中实现用呢,来接着往下看
HTTP请求头Range
range是请求资源的部分内容(不包括响应头的大小),单位是byte,即字节,从0开始.
如果服务器能够正常响应的话,服务器会返回 206 Partial Content 的状态码及说明.
如果不能处理这种Range的话,就会返回整个资源以及响应状态码为 200 OK .(这个要注意,要分段下载时,要先判断这个)
Range请求头格式
Range: bytes=start-end
Range头域
Range头域可以请求实体的一个或者多个子范围。例如,
表示头500个字节:bytes=0-499
表示第二个500字节:bytes=500-999
表示最后500个字节:bytes=-500
表示500字节以后的范围:bytes=500-
第一个和最后一个字节:bytes=0-0,-1
同时指定几个范围:bytes=500-600,601-999
例如
Range: bytes=10- :第10个字节及最后个字节的数据
Range: bytes=40-100 :第40个字节到第100个字节之间的数据.
注意,这个表示[start,end],即是包含请求头的start及end字节的,所以,下一个请求,应该是上一个请求的[end+1, nextEnd]
下载实例
下面我们通过具体的代码去进一步了解一些细节。
import requests
import tqdm
def download_from_url(url, dst):
response = requests.get(url, stream=True) #(1)
file_size = int(response.headers['content-length']) #(2)
if os.path.exists(dst):
first_byte = os.path.getsize(dst) #(3)
else:
first_byte = 0
if first_byte >= file_size: #(4)
return file_size
header = {"Range": f"bytes={first_byte}-{file_size}"}
pbar = tqdm(
total=file_size, initial=first_byte,
unit='B', unit_scale=True, desc=dst)
req = requests.get(url, headers=header, stream=True) #(5)
with(open(dst, 'ab')) as f:
for chunk in req.iter_content(chunk_size=1024): #(6)
if chunk:
f.write(chunk)
pbar.update(1024)
pbar.close()
return file_size
下面我们开始解读标有注释的代码:
tqdm是一个可以显示进度条的包,具体的用法可以参考官网文档:https://pypi.org/project/tqdm/
(1)设置stream=True参数读取大文件。
(2)通过header的content-length属性可以获取文件的总容量。
(3)获取本地已经下载的部分文件的容量,方便继续下载,当然需要判断文件是否存在,如果不存在就从头开始下载。
(4)本地已下载文件的总容量和网络文件的实际容量进行比较,如果大于或者等于则表示已经下载完成,否则继续。
(5)开始请求视频文件了
(6)循环读取每次读取一个1024个字节,当然你也可以设置512个字节
效果演示
首先调用上面的方法并传入参数。
url = "http://v11-tt.ixigua.com/7da2b219bc734de0f0d04706a9629b61/5c77ed4b/video/m/220d4f4e99b7bfd49efb110892d892bea9011612eb3100006b7bebf69d81/?rc=am12NDw4dGlqajMzNzYzM0ApQHRAbzU6Ojw8MzQzMzU4NTUzNDVvQGgzdSlAZjN1KWRzcmd5a3VyZ3lybHh3Zjc2QHFubHBfZDJrbV8tLTYxL3NzLW8jbyMxLTEtLzEtLjMvLTUvNi06I28jOmEtcSM6YHZpXGJmK2BeYmYrXnFsOiMzLl4%3D"
download_from_url(url, "夏目友人帐第一集.mp4")
在命令行中运行代码之后看到效果如下
如果在pycharm直接运行的话是下面的效果
完全不一样的效果,个人感觉还是在pycharm里看着舒服,后面并发的时候看着也方便。
好了下面我们就打开我们的文件看看结果如何:
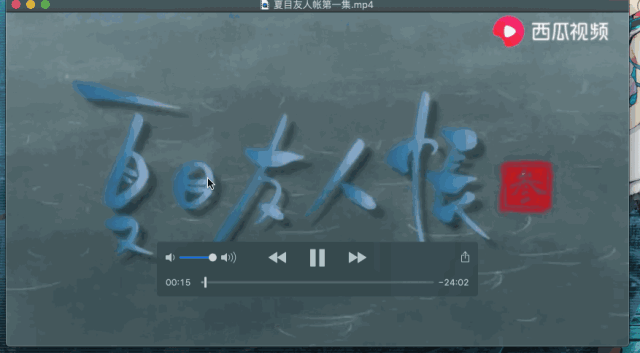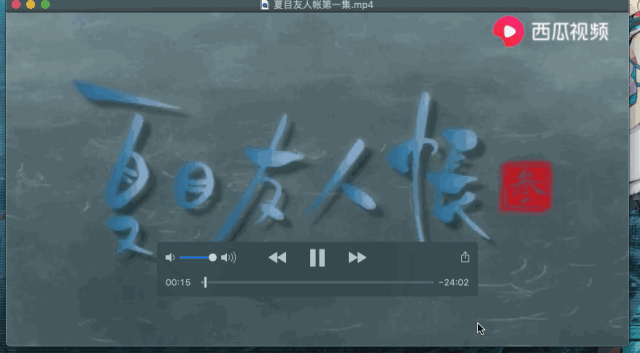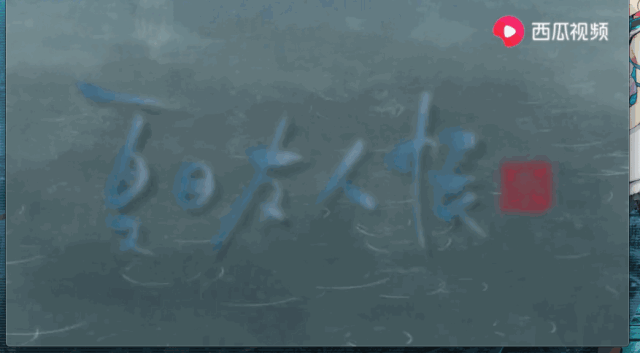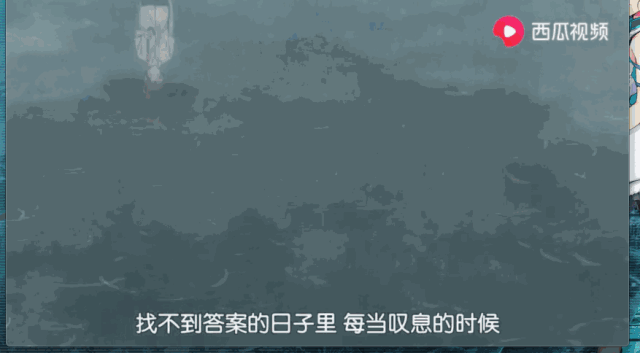
可以发现这个视频被成功的下载下来,怎么样激不动激不动啊。
对于单文件的下载我们就完成,但是对于夏目友人帐这个动漫来说不只有一集,如果我们下载一个系列的话,我们就得使用并发了,这里我使用aiohttp把上面的代码改成并发的版本。
使用aiohttp进行并发下载
import aiohttp
import asyncio
from tqdm import tqdm
async def fetch(session, url, dst, pbar=None, headers=None):
if headers:
async with session.get(url, headers=headers) as req:
with(open(dst, 'ab')) as f:
while True:
chunk = await req.content.read(1024)
if not chunk:
break
f.write(chunk)
pbar.update(1024)
pbar.close()
else:
async with session.get(url) as req:
return req
async def async_download_from_url(url, dst):
'''异步'''
async with aiohttp.connector.TCPConnector(limit=300, force_close=True, enable_cleanup_closed=True) as tc:
async with aiohttp.ClientSession(connector=tc) as session:
req = await fetch(session, url, dst)
file_size = int(req.headers['content-length'])
print(f"获取视频总长度:{file_size}")
if os.path.exists(dst):
first_byte = os.path.getsize(dst)
else:
first_byte = 0
if first_byte >= file_size:
return file_size
header = {"Range": f"bytes={first_byte}-{file_size}"}
pbar = tqdm(
total=file_size, initial=first_byte,
unit='B', unit_scale=True, desc=dst)
await fetch(session, url, dst, pbar=pbar, headers=header)
上面的代码功能和我们的同步代码一样的,不同的是这里是异步的。
并发下载演示
我们首先要拿到MP4的链接,然后进行下面的代码即可
task = [asyncio.ensure_future(async_download_from_url(url, f"{i}.mp4")) for i in range(1, 12)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(task))
loop.close()
这里我同时下载了11次上面的那个视频,命令为1-11,方便演示效果,好了下面我们就来看效果。
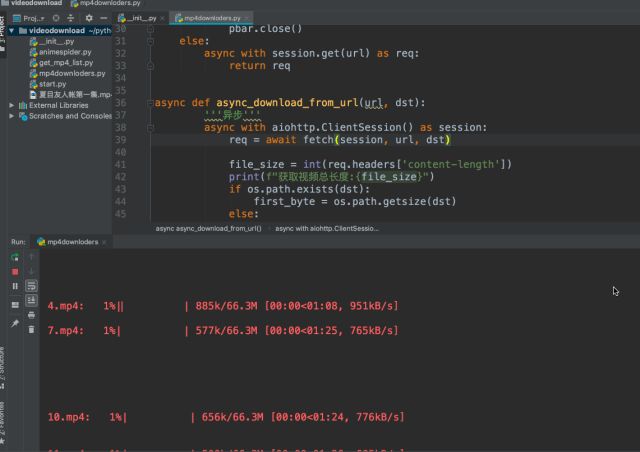
可以发现开始并发的下载了。
完整代码如下:
# -*- coding: utf-8 -*-
# @Time : 2019/2/13 8:17 PM
# @Author : cxa
# @File : mp4downloders.py
# @Software: PyCharm
import requests
from tqdm import tqdm
import os
import aiohttp
import asyncio
try:
import uvloop
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
except ImportError:
pass
async def fetch(session, url, dst, pbar=None, headers=None):
if headers:
async with session.get(url, headers=headers) as req:
with(open(dst, 'ab')) as f:
while True:
chunk = await req.content.read(1024)
if not chunk:
break
f.write(chunk)
pbar.update(1024)
pbar.close()
else:
async with session.get(url) as req:
return req
async def async_download_from_url(url, dst):
'''异步'''
async with aiohttp.ClientSession() as session:
req = await fetch(session, url, dst)
file_size = int(req.headers['content-length'])
print(f"获取视频总长度:{file_size}")
if os.path.exists(dst):
first_byte = os.path.getsize(dst)
else:
first_byte = 0
if first_byte >= file_size:
return file_size
header = {"Range": f"bytes={first_byte}-{file_size}"}
pbar = tqdm(
total=file_size, initial=first_byte,
unit='B', unit_scale=True, desc=dst)
await fetch(session, url, dst, pbar=pbar, headers=header)
def download_from_url(url, dst):
'''同步'''
response = requests.get(url, stream=True)
file_size = int(response.headers['content-length'])
if os.path.exists(dst):
first_byte = os.path.getsize(dst)
else:
first_byte = 0
if first_byte >= file_size:
return file_size
header = {"Range": f"bytes={first_byte}-{file_size}"}
pbar = tqdm(
total=file_size, initial=first_byte,
unit='B', unit_scale=True, desc=dst)
req = requests.get(url, headers=header, timeout=60, stream=True)
with(open(dst, 'ab')) as f:
for chunk in req.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
pbar.update(1024)
pbar.close()
return file_size
if __name__ == '__main__':
# 异步方式下载
url = "http://v11-tt.ixigua.com/7da2b219bc734de0f0d04706a9629b61/5c77ed4b/video/m/220d4f4e99b7bfd49efb110892d892bea9011612eb3100006b7bebf69d81/?rc=am12NDw4dGlqajMzNzYzM0ApQHRAbzU6Ojw8MzQzMzU4NTUzNDVvQGgzdSlAZjN1KWRzcmd5a3VyZ3lybHh3Zjc2QHFubHBfZDJrbV8tLTYxL3NzLW8jbyMxLTEtLzEtLjMvLTUvNi06I28jOmEtcSM6YHZpXGJmK2BeYmYrXnFsOiMzLl4%3D"
task = [asyncio.ensure_future(async_download_from_url(url, f"{i}.mp4")) for i in range(1, 12)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(task))
loop.close()
# 注释部分是同步方式下载。
# url = "http://v11-tt.ixigua.com/7da2b219bc734de0f0d04706a9629b61/5c77ed4b/video/m/220d4f4e99b7bfd49efb110892d892bea9011612eb3100006b7bebf69d81/?rc=am12NDw4dGlqajMzNzYzM0ApQHRAbzU6Ojw8MzQzMzU4NTUzNDVvQGgzdSlAZjN1KWRzcmd5a3VyZ3lybHh3Zjc2QHFubHBfZDJrbV8tLTYxL3NzLW8jbyMxLTEtLzEtLjMvLTUvNi06I28jOmEtcSM6YHZpXGJmK2BeYmYrXnFsOiMzLl4%3D"
#
# download_from_url(url, "夏目友人帐第一集.mp4")