MongoDB作为实时流水查询的存储适用性分析
MongoDB作为时下最流行的NoSQL数据库,凭借其优秀的性能,强大的可扩展能力,易于上手的开发,可靠的技术支持,活跃的社区讨论,在国内外各个领域有着广泛的应用。关于其概况和其他技术细节可以参考新框架搭建相关的两篇文章《NoSQL的热门数据库简介》《MongoDB,HBase,Cassandra详解和对比》的MongoDB部分的说明以及相关引文,另外可以参阅官方文档,MongoDB中文社区,阿里云栖社区,腾讯云社区的相关文章。
本文主要针对实时流水查询这个需求,讨论MongoDB的索引机制、存储引擎、性能表现,并且对MongoDB对于需求的适用性进行初步分析。
MongoDB的索引机制
MongoDB是基于文档存储的,默认对文档id创建索引,但是面对多样的查询条件,仅有文档id的索引是不够的,我们需要对文档中其他字段建立索引来加速查询。
MongoDB支持单索引,复合索引,文本索引,hash索引,地理位置索引等多种索引方式。
本文示例文档数据模型如下:
restaurant信息
{
"_id" : ObjectId("59b8e70b51a8cd453447c648"),
"name" : "Café Con Leche",
"contact" : {
"phone" : "228-555-0149",
"email" : "[email protected]",
"location" : [
-73.92502,
40.8279556
]
},
"stars" : 10,
"categories" : [
"Bakery",
"Coffee",
"Pastries"
]
}
其中,_id字段可以自己指定,也可以不指定,这时系统将自动生成由time+machine+pid+inc构成的十六进制字符串。
单索引
单索引可以对任意字段建立索引,比如最常用的是按name查询,我们就可以对name创建索引,Java代码如下:
collection.createIndex(Indexes.ascending("name"));
复合索引
很多情况下,查询条件不只是一个,这时候就需要对多个字段建立索引。比如,对name和star进行索引:
collection.createIndex(Indexes.compoundIndex(Indexes.descending("stars"), Indexes.ascending("name")));
文本索引
有时候我们只想查询包含某一字符串的一系列结果,这时候就需要建立文本索引:
collection.createIndex(Indexes.text("name"));
其他
MongoDB还支持诸如hashed index,geosptial index等等,在不同的应用场景下也能够大幅提升查询性能。另外,还有TTL,Sparse等丰富的选项,可以用来调优。
参考文献
- MongoDB官方文档——Index
- MongoDB Java Driver文档——Create Indexes
WiredTiger存储引擎
MongoDB 3.2版本发布后,WiredTiger正式取代MMAPv1,成为默认存储引擎。新增压缩、文档级锁等特性,如下图所示
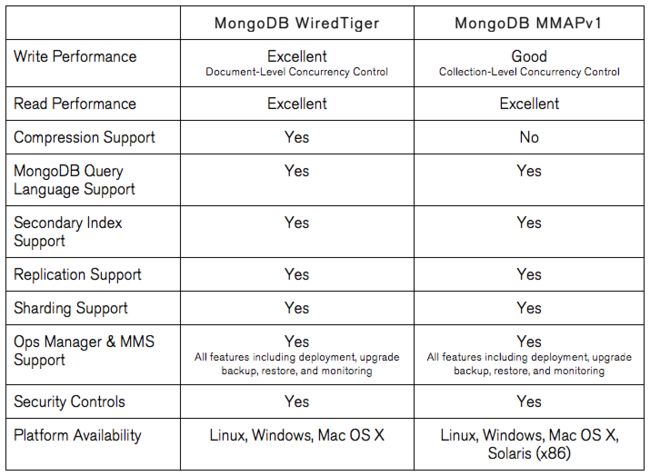
文档级锁
从MMAPv1的集合级锁,细化到文档级锁,大幅提升了写入性能,官方号称有7到10被的写入性能提升。
压缩
WiredTiger提供了snappy,zlib和none三种压缩选项。
- Snappy(以前称Zippy)是Google基于LZ77的思路用C++语言编写的快速数据压缩与解压程序库,并在2011年开源。它的目标并非最大压缩率或与其他压缩程序库的兼容性,而是非常高的速度和合理的压缩率。使用一个运行在64位模式下的酷睿i7处理器的单个核心,压缩速度250 MB/s,解压速度500 MB/s。压缩率比gzip低20-100%。
- 也可以使用zlib,来获得更高的压缩比。
WiredTiger默认开启Snappy选项,一般来讲,达到了性能和存储空间的平衡。
另外,WiredTiger对索引默认开启了前缀压缩。
压缩前后的性能对比见下一部分。
性能情况
这里没有进行实机测试,参考的是腾讯云的文章,文章列表如下。
- 数据库评测报告第二期:MongoDB-3.2
该篇文章对MongoDB的读写性能进行了比较系统的测试,包括写入和查询性能和线程数的关系,不同的读写比例对性能有怎样的影响,不同的数据规模(百万级、千万级、亿级)下的吞吐率和延迟的情况。并且给出了实验环境和测试细节。以下是文章得出的结论。
MongoDB读性能优于写性能(吞吐率、稳定性);
MongoDB在TS90上的针对中小数据量的读写,以128线程为最优,对于大数据量的读写,以64线程为最优;
MongoDB写操作对整体吞吐率的影响,随着数据量的增加而越发明显;
写操作比读操作更容易造成系统延迟,并且随着数据量的增大,造成的影响越发明显;
单个集合达到亿级数据量时,MongoDB的读写性能均有明显下降,设计集合时,应尽量将集合的文档数量控制在亿级以下。
- mongodb 3.4与 mongodb 3.2性能对比
MongoDB 3.4又引入了一些全新的特性,这篇文章对这些特性进行了介绍,并测试了写入速度,80%写入、20%读取情况下的系统吞吐,混合读写情况下系统读取平均响应耗时。得出如下结论:
在当前测试的并发场景下,100 并发时, mongdodb3.4 和 3.2 的表现性能最优;
写入性能上,mongodb3.4 和 3.2 提升有限,约 2%;
混合场景中,mongodb3.4 吞吐高于 3.2,约 7%;
虽然 mongodb3.4 相较于 3.2 在读写性能上提升有限,但 WT 引擎一直在不断优化,且如文初描述 3.4 新版本在同步性能、Aggregation 操作、视图、分片规范和安全性上还是有很多改动,对同步压力大、嵌套 query 较多等业务场景依然建议予以升级尝试。
- MongoDB第二期:压缩与索引
这篇文章针对WiredTiger引入的数据压缩特性进行了压缩比测试,以及索引的空间开销进行了测试,得出了如下结论。
MongoDB的Wired Tiger存储引擎在数据压缩(主要是文本数据)的能力出色,基本上能达到压缩55%左右的存储空间,极大程度上提升了磁盘空间的使用率。
MongoDB的Wired Tiger存储引擎压缩从小规模数据的压缩到海量数据的压缩其性能保持稳定,压缩率均在54%~55%。可以说明数据量的增大不会成为其压缩功能的瓶颈。
随着数据量的增大,建立索引的时间开销将不断增大,故数据集合最初的设计极为重要,在海量数据生成后中建立索引,有一定的时间开销。
在建立索引的时间开销上:普通索引 < 复合索引(2个)< 唯一索引。
适用性分析
首先,看一下我们目前的应用场景,实际上就是实时和非实时的流水查询。非实时流失只需要将实时流水分桶处理,甚至可以降低一致性强度以提升写入效率。因此,这里只讨论实时的流水查询。又由于,每一种流水查询大同小异,这里只讨论比较重要的且比较典型的实时充值流水查询,其具体需求见下图。
这里假设所有字段都存在一个文档中。
如此多的查询条件选项,将其全部作为索引显然是效率低下且浪费空间的,实际上只需对四个必选项建立复合索引就可以了。这样可以最大程度的减少空间浪费,并且尽可能的提高了查询效率。
对于压缩选项,可以选择默认的snappy加前缀压缩的模式,兼顾查询效率与空间占用。也可以测试一下zlib的压缩方式的性能,如果可以接受的话,也可以选择。