项目背景:
AT&T运营商拥有海量的用户个人,通话,上网等信息数据。充分利用数据预测客户的流转情况,能帮助挽留用户,保证用户基数和活跃度。
分析需求说明:
分析流程:
1.数据概况分析:数据的行/列数量 缺失值的分布等
2.单变量分析:数字型变量的描述分析、类别型变量的分析、正负样本占比
3.相关性与可视化:按类别交叉对比,变量之间的相关性分析,散点图/热力图观察样本相关性
4.逻辑回归建模:模型建立、训练集与测试集的随机划分、模型的评估与优化。
分类模型基础:
1.分类任务的目标是通过找一个函数,把观测值匹配到相关的类和标签上。
2.在二元分类(binary classification)中,分类算法必须把一个实例配置两个类别。
3.如果对分类数据进行线性回归,结果是基本无法识别出1和0的差别,那我们就会使用分类模型来分析分类数据。
分析过程:
#导入所需要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#读取数据
df = pd.read_csv(r'ATT.csv',index_col = 0)
df.info()
输出结果:

变量说明:
Churn : 客户转化的flag :Yes /No
gender:客户的性别
Partner_att: 客户配偶是否也为AT&T用户
Dependents_att: 客户家人是否也为AT&T用户
landline:是否使用AT&T固话服务
Internet_att/internet_other:使用att的网络服务还是其他的网络服务
StreamingTV/StreamingMovies :是否使用在线视频或电影app
Contract_month/1YR :用户使用月度/年度合约
PaymentBank / PaymentCreditcard / PaymentElectronic :客户的付款方式
MonthlyCharges :每月话费
TotalCharges : 累积话费
预测目标是:Churn 类别型变量 gender也是类别型变量 因此我们在进行建模前需要把两个类别型变量转变成数字型变量
df = pd.get_dummies(df)
df.head()
输出结果:
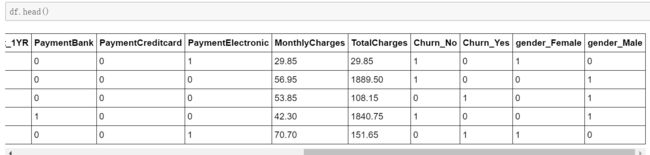
Churn 与 gender两个变量已经完全变成了数值型变量 以 0 1 作为分类。
get_dummies 函数生成了四个标签,Churn_Yes Churn_No 只需要保留一个,gender_Females gender_Male 只需要保留一个
#数据整理,将Churn_yes 保留,将female保留,drop不需要的变量
df.drop(['Churn_No','gender_Male'],axis = 1 , inplace = True)
变量大小写转变给数据清洗过程带来更大的难度,因此我们先将所有的变量的变成小写。
df.columns = df.columns.str.lower()
df.head()

所有的变量名称都转化为小写!!!
将churn_yes重命名,方便后续的变量编写
df = df.rename(columns = {'churn_yes':'flag'})
df.head()
输出结果:

churn_yes已经转化成flag!!!
二分类模型,分析flag 1 和 0 的占比
df.flag.value_counts(1)
输出结果:

其中0 占比73% 1占比26%
summary = df.groupby('flag')
summary.mean()
输出结果:

sns.countplot(y = 'contract_month',hue = 'flag',data = df)
输出结果:
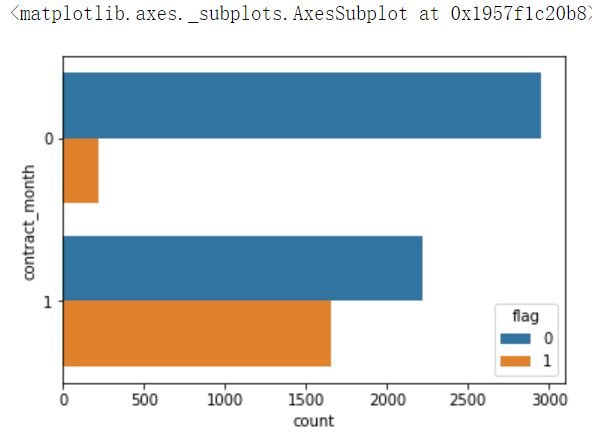
结论:非包年用户的流失率大大高于包年用户的流失率。
多变量分析变量之间的相关性
df.corr()[['flag']].sort_values('flag',ascending =False)
输出结果:
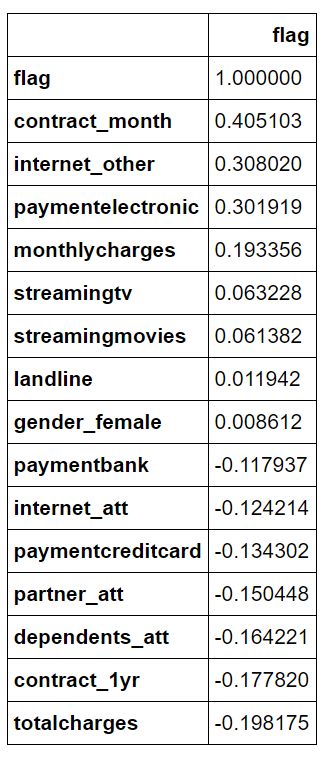
y = df['flag']
x = df[['contract_month','internet_other','paymentelectronic']]
#进行测试集与训练集的切分
from sklearn.model_selection import train_test_split
x_train , x_test , y_train , y_test = train_test_split(x,y,test_size = 0.5 ,random_state = 100)
from sklearn import linear_model
lr = linear_model.LogisticRegression()
lr.fit(x_train,y_train)
输出结果:

lr.intercept_
输出结果:

截距为负,方向关系
lr.coef_ #模型系数
输出结果:

模型解读:
系数为2.0019671:当X(contract_month)为0到1 不流失到流失的概率提升提升为e 的2.0019671(系数越大,影响就越大)
#基于模型的结果,对训练集与测试集中的x的真实值预测对应的y
y_pred_train = lr.predict(x_train)
y_pred_test = lr.predict(x_test)
import sklearn.metrics as metrics #计算评估模型指标的库
metrics.confusion_matrix(y_train , y_pred_train)
输出结果:
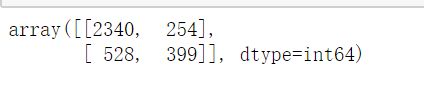
混淆矩阵 正确的预测为2340+399 错误的为254+528
metrics.accuracy_score(y_train,y_pred_train) #训练集的准确率
计算结果:0.7779040045441636
metrics.accuracy_score(y_test,y_pred_test) #测试集的准确率
计算结果:0.768313458262351
from sklearn.metrics import roc_curve,auc
fpr,tpr,threshold = roc_curve(y_train , y_pred_train)
roc_auc = auc(fpr,tpr)
print(roc_auc)
输出结果:
0.666251219518281
系数的解读:
在建模过程中,发现 contract_month的系数是2,我们如何解读这个数据呢?
ln(b/a) 就等于2,也就是说b/a = exp(2) = 7.39
从业务来解释,contract_month = 1的客户,他的流失概率是其他组客户的7.39倍。
我们计算的系数,是对应到的事件发生与不发生的概率比值的log转换,这个转换的结果也被称为odds ratio(比值比)