本文由 yanglbme 原创,首发于公众号“Doocs开源社区”,禁止未授权转载。
Google 搜索自动补全功能的强大,相信不少朋友都能感受到,它帮助我们更快地“补全”我们所要输入的搜索关键字。那么,它怎么知道我们要输入什么内容?它又是如何工作的?在这篇文章里,我带你一起看看。
使用自动补全
Google 搜索的自动补全功能可以在 Google 搜索应用的大多数位置使用,包括 Google 主页、适用于 IOS 和 Android 的 Google 应用,我们只需要在 Google 搜索框上开始键入关键字,就可以看到联想词了。

在上图示例中,我们可以看到,输入关键字 juej,Google 搜索会联想到“掘金”、“掘金小册”、“绝句”等等,好处就是,我们无须输入完整的关键字即可轻松完成针对这些 topics 的搜索。
谷歌搜索的自动补全功能对于使用移动设备的用户来说特别有用,用户可以轻松在难以键入的小屏幕上完成搜索。当然,对于移动设备用户和台式机用户而言,这都节省了大量的时间。根据 Google 官方报告,自动补全功能可以减少大约 25% 的打字,累积起来,预计每天可以节省 200 多年的打字时间。是的,每天!
注意,本文所提到的“联想词”与“预测”,是同一个意思。
基于“预测”而非“建议”
Google 官方将自动补全功能称之为“预测”,而不是“建议”,为什么呢?其实是有充分理由的。自动补全功能是为了帮助用户完成他们打算进行的搜索,而不是建议用户要执行什么搜索。
那么,Google 是如何确定这些“预测”的?其实,Google 会根据趋势搜索 trends 给到我们这些“预测”。简单来说,哪个热门、哪个搜索频率高,就更可能推给我们。当然,这也与我们当前所处的位置以及我们的搜索历史相关。
另外,这些“预测”也会随着我们键入的关键字的变更而更改。例如,当我们把键入的关键字从 juej 更改为 juex 时,与“掘金”相关的预测会“消失”,同时,与“觉醒”、“决心”相关联的词会出现。
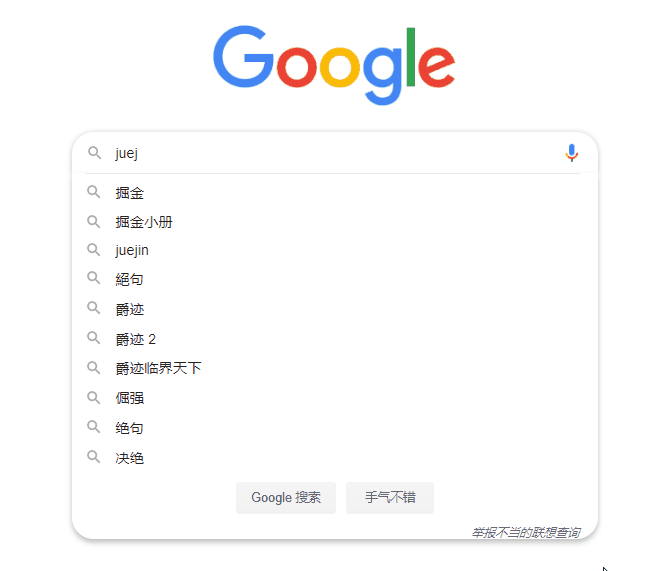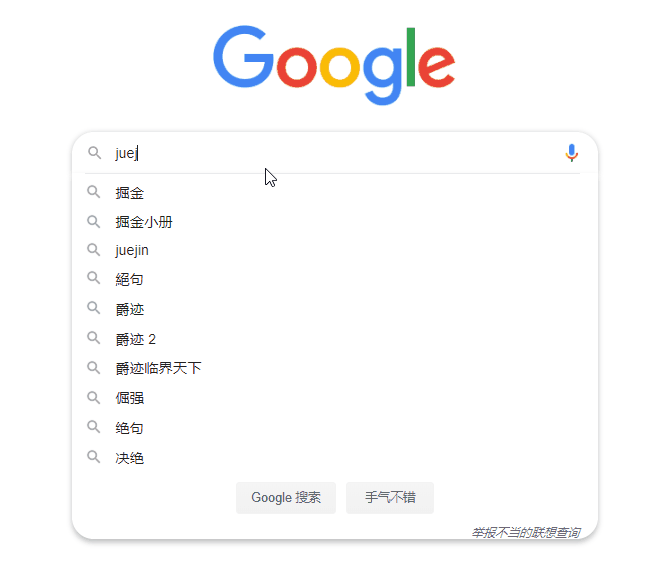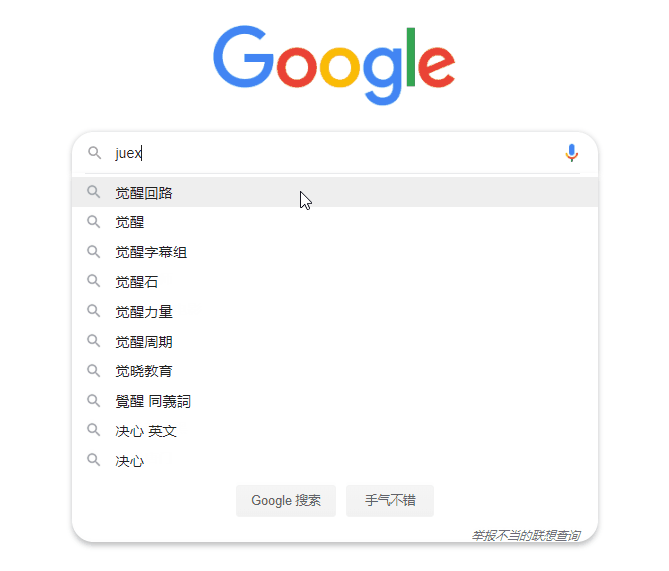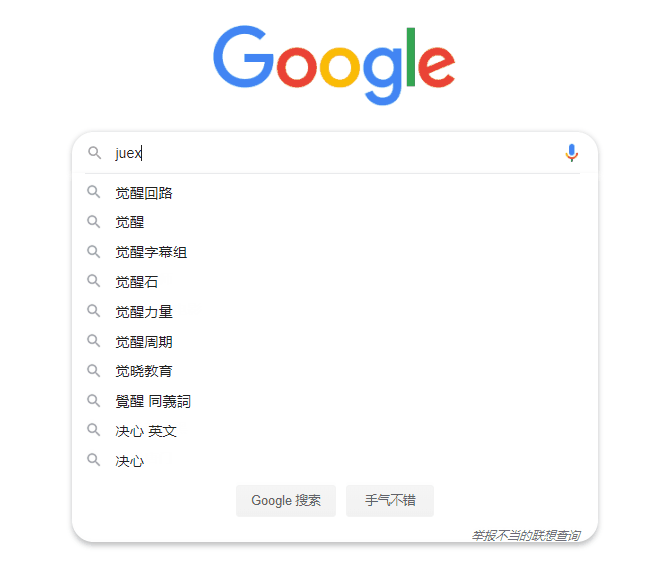
为什么我们看不到某些联想词?
如果我们在输入某个关键字时看不到联想词,那么表明 Google 的算法可能检测到:
- 这个关键字不是热门字词;
- 搜索的字词太新了,我们可能需要等待几天或几周才能看到联想词;
- 这是一个侮辱性或敏感字词,这个搜索字词违反了 Google 的相关政策。更加详细的情况,可以了解 Google 搜索自动补全政策。
为什么我们会看到某些不当的联想词?
Google 拥有专门设计的系统,可以自动捕获不适当的预测结果而不显示出来。然而,Google 每天需要处理数十亿次搜索,这意味着 Google 每天会显示数十亿甚至上百亿条预测。再好的系统,也可能存在缺陷,不正确的预测也可能随时会出现。
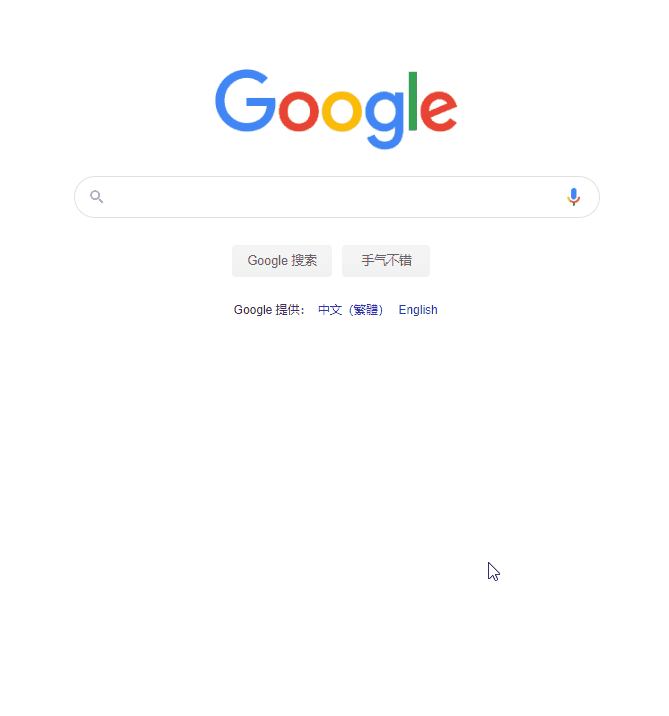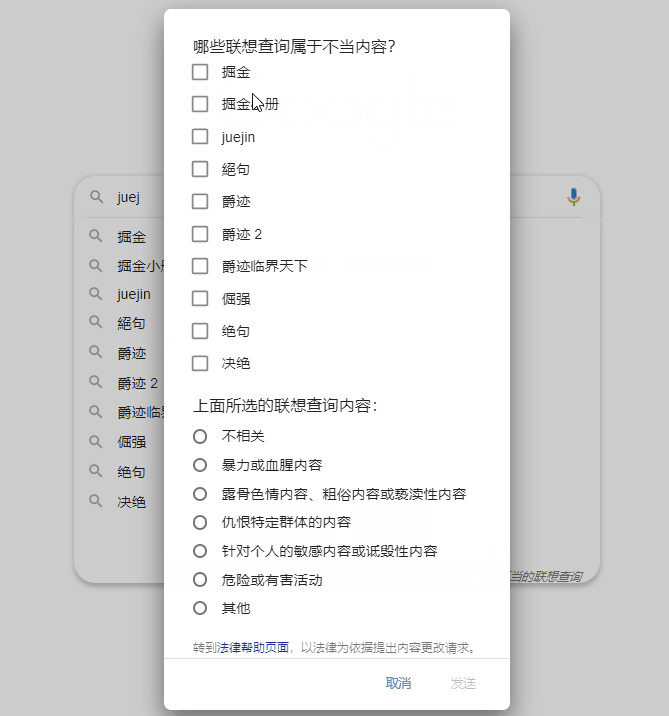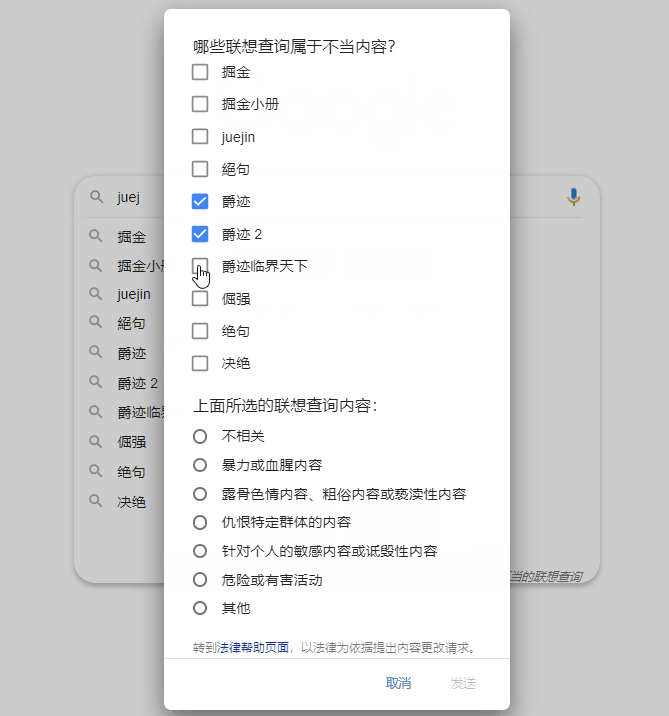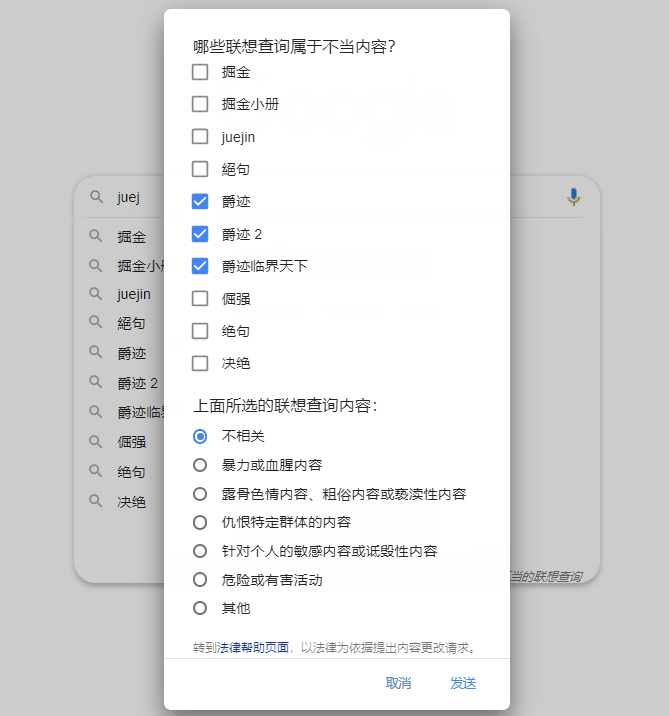
我们作为 Google 搜索的用户,如果认定某条预测违反了相关的搜索自动补全政策,可以进行举报反馈,点击右下角“举报不当的联想查询”并勾选相关选项即可。
如何实现自动补全算法?
目前,Google 官方似乎并没有公开搜索自动补全的算法实现,但是业界在这方面已经有了不少研究。
一个好的自动补全器必须是快速的,并且在用户键入下一个字符后立即更新联想词列表。自动补全器的核心是一个函数,它接受输入的前缀,并搜索以给定前缀开头的词汇或语句列表。通常来说,只需要返回少量的数目即可。
接下来,我们先从一个简单且低效的实现开始,并在此基础上逐步构建更高效的方法。
词汇表实现
一个简单粗暴的实现方式是:顺序查找词汇表,依次检查每个词汇,看它是否以给定的前缀开头。
但是,此方法需要将前缀与每个词汇进行匹配检查,若词汇量较少,这种方式可能勉强行得通。但是,如果词汇量规模较大,效率就太低了。
一个更好的实现方式是:让词汇按字典顺序排序。借助二分搜索算法,可以快速搜索有序词汇表中的前缀。由于二分搜索的每一步都会将搜索的范围减半,因此,总的搜索时间与词汇表中单词数量的对数成正比,即时间复杂度是 O(log N)。二分搜索的性能很好,但有没有更好的实现呢?当然有,往下看。
前缀树实现
通常来说,许多词汇都以相同的前缀开头,比如 need、nested 都以 ne 开头,seed、speed 都以 s 开头。要是为每个单词分别存储公共前缀似乎很浪费。

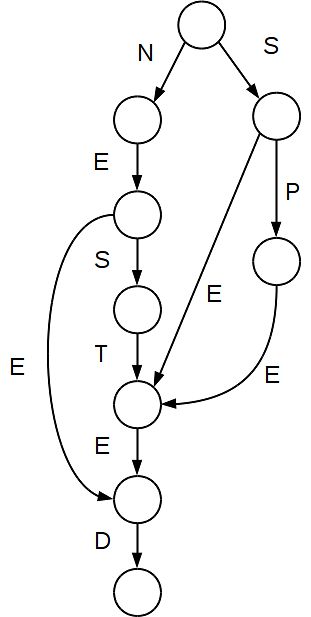
前缀树是一种利用公共前缀来加速补全速度的数据结构。前缀树在节点树种排列一组单词,单词沿着从根节点到叶子节点的路径存储,树的层次对应于前缀的字母位置。
前缀的补全是顺着前缀定义的路径来查找的。例如,在上图的前缀树种,前缀 ne 对应于从子节点取左边缘 N 和唯一边缘 E 的路径。然后可以通过继续遍历从 E 节点可以达到的所有叶节点来生成补全列表。在图中,ne 的补全可以是两个分支:-ed 和 -sted。如果在数中找不到由前缀定义的路径,则说明词汇表中不包含以该前缀开头的单词。
有限状态自动机(DFA)实现
前缀树可以有效处理公共前缀,但是,对于其他共享词部分,仍会分别存储在每个分支中。比如,后缀 ed、ing、tion 在英文单词中特别常见。在上一个例子中,e、d 分别存放在了每一个分支上。
有没有一种方法可以更加节省存储空间呢?有的,那就是 DFA。
在上面的例子中,单词 need、nested、seed 和 speed 仅由 9 个节点组成,而上一张图中的前缀树包含了 17 个节点。
可以看出,最小化前缀树 DFA 可以在很大程度上减少数据结构的大小。即使词汇量很大,最小化 DFA 通常也适合在内存中存储,避免昂贵的磁盘访问是实现快速自动补全的关键。
一些扩展
上面介绍了如何利用合理的数据结构实现基本的自动补全功能。这些数据结构可以通过多种方式进行扩展,从而改善用户体验。
通常,满足特定前缀的词汇可能很多,而用户界面上能够显示的却不多,我们更希望能显示最常搜索或者最有价值的词汇。这通常可以通过为词汇表中的每个单词增加一个代表单词值的权重 weight,并且按照权重高低来排序自动补全列表。
- 对于排序后的词汇表来说,在词汇表每个元素上增加
weight属性并不难; - 对于前缀树来说,将
weight存储在叶子节点中,也是很简单的一个实现; - 对于
DFA来说,则较为复杂。因为一个叶子节点可以通过多条路径到达。一种解决方案是将权重关联到路径而不是叶子节点。
目前有不少开源库都提供了这个功能,比如主流的搜索引擎框架 Elasticsearch、Solr 等,基于此,我们可以实现高效而强大的自动补全功能。
欢迎关注我的公众号“Doocs开源社区”,原创技术文章第一时间推送。
