Leopard
《Android 之基于Retrofit的网络框架Leopard,下载与断点续传深入分析》
转载请注明来自 傻小孩b_移动开发(http://www.jianshu.com/users/d388bcf9c4d3)喜欢的可以关注我,不定期总结文章!您的支持是我的动力哈!
前言
Leopard 意为猎豹,在所有猫科动物中。猎豹体型最小,速度快、最稳定。这也是笔者想用这个名字命名这个Kit的原因。希望这个Kit能对部分开发者对于网络框架封装的一些思路有所帮助,笔者也在奋斗路上坚持总结进步中,共勉!最后,有任何问题可以提issuse给我,或者直接联系本人(QQ:708854877 傻小孩b),喜欢可以为我点个star,你们的支持是我最大的动力~谢谢!
Leopard导读
- Android 巧妙封装,基于Retrofit+RxJava网络框架“Leopard”---完整浅析
Leopard 下载深入解读
一、基本原理
首先看下整个下载原理图,Leopard下载管理原理图如下:
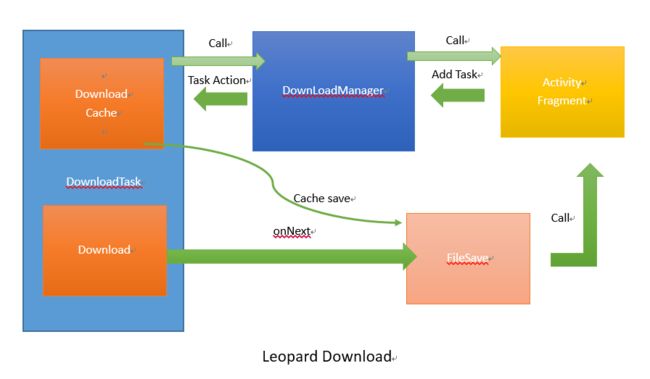
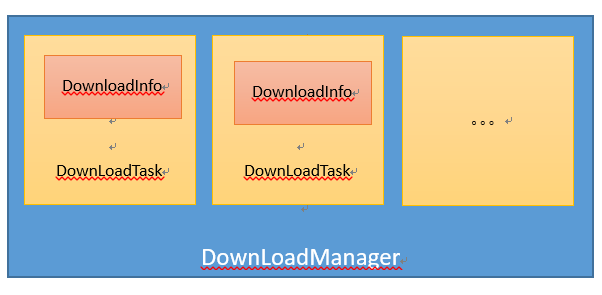
对于Leopard的下载管理,由于底层由RxJava本地线程安全管理。所有的网络操作都存在于IO线程,订阅方则依赖于主线程,用于Layout处理。在下载管理中,所有的下载的操作都依赖于每一个独立的DownLoadTask(这里指下载任务), 并且每个下载Task都依赖被DownLoadManager 所管理控制。其中每个下载的任务实时状态的存在一个model (DownloadInfo)中,依赖图如下:
二、下载进度监听解读分析
一般情况,比较常见的下载进度监听方法:在每次请求下载的时候,将流写入文件的时候,实时将写入的有效长度回调到UI界面,达到监听实时的下载变化。Retrofit底层由OKhttp3支持,比较坑爹没有想外抛出流写入的回调。这时候,我们应该巧妙去重写Okhttp3已经封装好的RsonpseBody,在这底层回调监听,看看Leopard怎么做的。关键代码如下:
**
* Created by Yuan on 2016/8/25.
* Detail 下载响应监听进度
*/
public class DownLoadResponseBody extends ResponseBody {
....
public BufferedSource source() {
if (bufferedSource == null) {
bufferedSource = Okio.buffer(source(mResponseBody.source()));
}
return bufferedSource;
}
public Source source(Source source) {
return new ForwardingSource(source) {
....
@Override
public long read(Buffer sink, long byteCount) throws IOException {
....
try {
bytesRead = super.read(sink, byteCount);
} catch (Exception e){
e.printStackTrace();
}
if (bytesRead != -1) {
} else {
bytesRead = 0;
}
totalLength += bytesRead;
downloadInfo.setProgress(downloadInfo.getProgress() + bytesRead);//实时更新downloadinfo的进度
long progress = downloadInfo.getProgress();
long total = downloadInfo.getFileLength();
postMainThread(progress,total);//这里处理回调
return bytesRead;
}
};
}
}
Okhttp3底层流的读写依赖于Okio,没有接触过的程序猿可以自行谷歌了解~在初始化构建RsponseBody的缓存源的时候调用了okio的buffer方法,这里构造的时候需要传入Source接口,这里由请求响应的ReponseBody提供。真正需要进行流的监听,其实就是对Source接口的read监听。这里ForwardingSource操作类,读者可以自行读下ForwardingSource源码,其实只是个委托操作类而已,真正的执行方,是实现了Source接口的ReponseBody。
三、断点续传解读分析
说到断点续传,我们必须先了解下HTTP协议怎么对断点续传进行处理。首先,不是所有的服务器都支持断点续传,这里可以在客户端通过服务器响应的头信息,例如"Accept-Ranges: none"表示不支持。当然,不是所有服务器在进行断点续传的时候都返回状态码200,有时候可以是206,这个读者自己注意下。
那么怎么指定断点续传位置?
断点续传需要做到三点:1、记录断点位置 2、缓存保存 3、服务器支持。
这里得继续说下HTTP协议,首先我们必须理解Ranges这个属性:表示在客户端请求的时候,指定下载范围,例如
Range: bytes=0-499 下载第0-499字节范围的内容
Range: bytes=500-999 下载第500-999字节范围的内容
Range: bytes=500- 下载第500-总大小字节范围的内容
看看Leopard怎么做的,关键代码:
public class DownLoadFileFactory implements Interceptor {
....
@Override
public Response intercept(Chain chain) throws IOException {
Request request = chain.request().newBuilder().addHeader("RANGE", "bytes=" + downloadInfo.getBreakProgress() + "-").build();
Response originalResponse = chain.proceed(request);
DownLoadResponseBody body = new DownLoadResponseBody(this.downloadInfo ,originalResponse.body(), fileRespondResult);
Response response = originalResponse.newBuilder().body(body).build();
return response;
}
}
Observable.create(new Observable.OnSubscribe() {
@Override
public void call(Subscriber subscriber) {
....
Request request = new Request.Builder().url(downloadInfo.getUrl()).build();
try {
Response response = okHttpClient.newCall(request).execute();
....
downloadInfo.getDownLoadTask().writeCache(response.body().byteStream());
// TODO: 2016/8/31 更新数据库 这里记得做下数据库延时更新
HttpDbUtil.instance.updateState(downloadInfo);
....
} catch (IOException e) {
....
}
}
})
从代码中我们可以观察到,Leopard对下载请求的时候,会通过DownloadInfo实时记录的进度,在向服务器请求的时候加入RANGE的头信息属性,让服务器在指定的范围返回对于的流。并且,当在Rx控制的IO线程中,Leopard在call进行缓存存储,再下载完成的时候在onNext对文件的最终追加合并,达到断点续传的作用。当然在Leopard中,断点续传也需要结合数据库操作,包括下载状态、进度、断点等信息,这个由读者去源码阅读,欢迎交流~
四、DownLoadManager 与DownLoadTask 解读分析
DownLoadManager 顾名思义,Leopard中对所有的下载任务起一个总控制的管理器。DownLoadTask 顾名思义,Leopard中指的是单一下载任务,可提供下载管理(开始、暂停、停止等功能)。
首先我们看下DownLoadTask 关键代码:
private LeopardClient getClient() {
return new LeopardClient.Builder()
.addRxJavaCallAdapterFactory(RxJavaCallAdapterFactory.create())
.addDownLoadFileFactory(DownLoadFileFactory.create(this.fileRespondResult, this.downloadInfo))
.build();
}
以上代码很明显每个Task都有一个独立的LeopardClient,在初始化的时候必须依赖DownLoadFileFactory,同时依然由Rx进行本地线程安全控制。
再其次看看其中一个Task的控制,下载控制
public void download( boolean isRestart) {
....
downloadInfo.setState(DownLoadManager.STATE_DOWNLOADING);//改变状态为下载状态
...
if (isRestart) {//如果是重新开始,则一切从0开始
stop();
resetProgress();
startPoints = 0L;
}
getClient().downLoadFile(this.downloadInfo, this.fileRespondResult, this);
}
Observable.create(new Observable.OnSubscribe() {
@Override
public void call(Subscriber subscriber) {
....
Request request = new Request.Builder().url(downloadInfo.getUrl()).build();
try {
Response response = okHttpClient.newCall(request).execute();
....
downloadInfo.getDownLoadTask().writeCache(response.body().byteStream());
// TODO: 2016/8/31 更新数据库 这里记得做下数据库延时更新
HttpDbUtil.instance.updateState(downloadInfo);
....
} catch (IOException e) {
....
}
}
})
以上代码,刚刚文章前面已经贴过,现在重新贴下。从关键代码,我们可以读出:在Leopard下载任务中,其实也是走了okhttp3底层的异步请求中,关键代码:new Request.Builder().url(downloadInfo.getUrl()).build();在Rx控制的IO线程中进行缓存处理、以及下载任务状态变化。最后则是在主线程更新追加完整的文件。
最后看下DownLoadManager ,其中一个下载任务管理-暂停功能
首先贴下源代码:
public void pauseAllTask(){
for (DownloadInfo downloadInfo : downloadInfosList){
downloadInfo.getDownLoadTask().pause();
}
}
public void pause() {
....
if (this.downloadInfo!=null &&this.downloadInfo.getSubscriber() != null)
this.downloadInfo.getSubscriber().unsubscribe();
....
HttpDbUtil.instance.updateState(downloadInfo);
}
读者在这里应该可以很直接知道Leopard究竟怎么暂停,最新得Retrofit提供了能够直接取消请求的方法 call.cancel();从暂停的角度,某种意义下,是我们本地以及存储了缓存文件后,再下一次继续下载的时候告诉服务器指定那个范围开始下载的意思。因此,在暂停的时候,Leopard是通过取消下载的订阅事件,达到下载暂停的效果。
五、总结
Leopard,当然也存在许多问题,首先感谢读者在github给的star。其实写Leopard的原因是希望能够帮助程序猿们,一起提高编程抽象思维能力。我们当然也不能只是搬运代码的“程序猿”,更重要我们是需要写出更高质量的代码,创造的“程序猿”。
所以,还是共勉,奋斗路上加油~
源码地址:
Android 基于Retrofit+RxJava 封装 Leopard 网络框架
傻小孩b mark共勉,写给在成长路上奋斗的你
喜欢就为我点下喜欢、给我个github的star吧~ 感谢各位读者阅读。