实习的第一个爬虫项目就是爬取中国裁判文书网,在爬这个网站的时候碰到一系列的问题,刚好可以将这些问题统一总结到我搭建的github博客上。
一、数据需求
1.案件相关信息 2.文书内容(为了方便我直接存的html文件)

二、网站分析
“中国裁判文书网”是一个政府网站,所以他符合政府网站的一些缺点,比如网页响应慢,不过有一点没有想到的是这个网站的反爬措施做的还不错,还需要花一番功夫去研究,接下来就开始分析一下这个网站。
1.简单的了解这个网站,我们要爬取这个网站数据有两个思路,一是使用浏览器自动化工具selenium,模拟浏览爬取,二是找到url直接发起请求获取数据。分析网站数据个人觉得第一种方法可以舍弃,抓取效率低,所以就直接使用第二种方法,寻找url。
2.在确定了抓取方法之后,就要开始分析url了,可以使用浏览器的开发者工具也可以使用专门的抓包工具,看个人习惯。很快就可以找到要的url,然后就是分析这个url,然后知道了这个url是post请求,然后又好多需要的参数,接下来就是分析参数了,难点即使分析这些参数了。
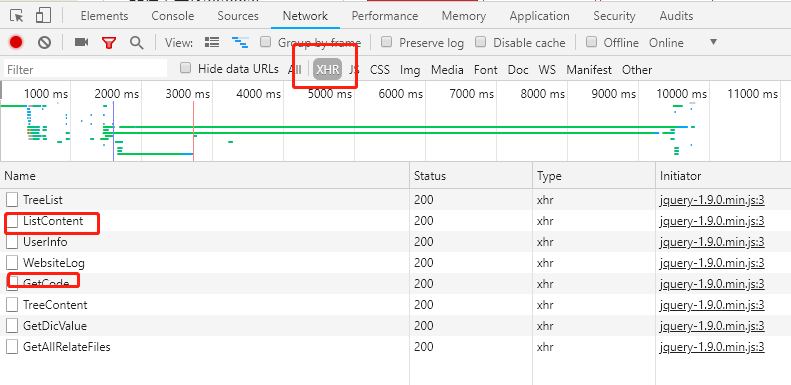
3.分析参数
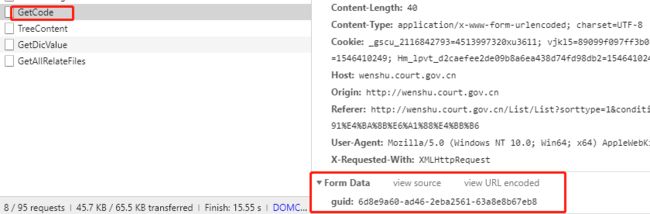
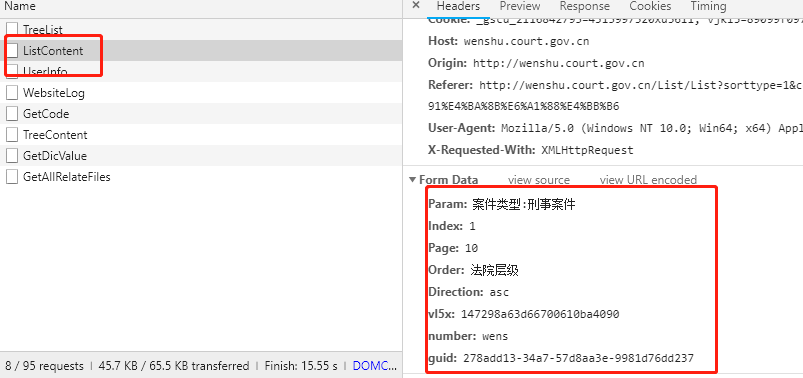
其中的难点参数有这几个:“vl5x”,“number”, “guid”
而其中number是另一个url返回的结果, 就是上面的那个GetCode的那个url,并且也是post请求,参数叫简单就是guid,接下来是要去找这个guid了。
4.寻找这个guid会发现他是由js代码生成出来的,到这里一些新手可能就不会了,先分享一个执行js代码的包,execjs这里你可以浏览官方文档https://pypi.org/project/PyExecJS/
pip install PyExecJS
这里我就直接从网页里将这段代码扒下来了
var createGuid = function () {
return (((1 + Math.random()) * 0x10000) | 0).toString(16).substring(1);
};
guid1 = createGuid() + createGuid() + "-" + createGuid() + "-" + createGuid() + createGuid() + "-" + createGuid() + createGuid() + createGuid();
var guid = function (){
return (createGuid() + createGuid() + "-" + createGuid() + "-" + createGuid() + createGuid() + "-" + createGuid() + createGuid() + createGuid());
}
执行这段技术代码就可以获取到需要的guid。
4.到上一步,就获取到guid,number,就剩一个vl5x了,这是整个爬虫的关键,也是难点, 这个参数搞定了就相当于解决整个完整的1/3了。我们查看源网页,可以发现这个参数是js生成的然后可以进行,不过这段js进行了js混淆,所以看到的都是看不懂的js代码,到这里一下就懵了,去网上搜js反混淆,然后解密出来你会发现有个cookie的东西,把它去掉替换成,具体的Js代码在我的github里面,有兴趣可以看看。
5.到这里相关的参数搞定了,然后就可以获取到数据了。接下来就是依据这些数据来解决文书的获取了,文书的获取可以说是这个网站最难的一步,涉及到js加密解密的相关问题,这里对js熟悉就好分析,不过不怎么熟悉的也可以搞定,只要认真研究一下js,就可以理解。
6.获取文书需要用到之前获取的json串里的'RunEval'和'文书ID',这两个参数是用来获取文书的url的,获取到了url,get请求就可以拿到数据。文书内容是在HTML标签里,可以用正则匹配出来,然后写入到HTML中保存为HTML文件。


对于如何解密文书url,有点复杂,可以花点时间自己研究,也可以直接访问我的github去看源码
三、代码框架
1.没有使用爬虫框架,就是单纯的使用requests库来写的整个爬虫,还有就是结合redis来将爬去的数据缓存,然后再持久化到MySQL。
四、代码实现
代码直接访问github,可以关注一下,以后会分析更新,还有其他技术
五、主要技术
1.原生requests包
2.使用IP代理池,代理IP放于redis中,太阳代理(快代理,讯代理等)
3.使用redis缓存数据
4.使用MySQL进行数据持久化处理
5.使用进程池进行爬虫
六、总结
(1)关于网站:
1.整个网站需要是不是得关注一下,可能会更新反爬,需要找到相应的方法解决问题。
2.网站相应慢,可以不要访问的这么快,给人留条活路,不然网站崩了,就麻烦了。
(2)关于代码:
1.先将爬取的数据放入redis中,在从redis将数据持久化,优化mysql链接过时或者超过最大链接数的问题
2.使用多线程,以及部署多台服务器,解决js解密速度慢,以及网站服务器反应慢的问题,同时在一定程度上控制进程数,防止网站瘫痪
后续内容:
增量更新:
根据时间俩做到增量更新,同时也可以根据时间作为参数来抓取数据,不过好像做多只能拿到2000条数据,暂时还没有其他的增量更新的方法。
关于封IP比较快的问题:
1.网站在访问比较频繁的情况下会出现验证码,这就给人一种IP被封的感觉,所以,只要时不时的输入一下验证码就OK了,当然,有钱的话一直换IP就好了
关于给假数据的问题:
对于假数据,我还没有去研究,不过发现访问不怎么正常就会有假数据,然后还没有发现网站是靠什么给假数据,我暂时的做法就是过滤掉假数据,等有时间在去研究一下,怎么规避这个问题
欢迎关注我的github
去我的博客