网格简化的算法大致上可以分为下面几种:
Vertex clustering algorithms:顶点聚类算法拥有很高的效率和鲁棒性(Robust),算法的复杂度是线性的。其缺点在于生成网格的质量不是特别令人满意。
Incremental algorithms:增量算法生成的网格质量很高,并且每次迭代的过程中能够使用任意用户定义的标准来进行下次减化网格操作。不过其复杂度较高,为O(n log n),最差复杂度为O(n²)。
Resampling algorithms:重采样算法是最常用的算法。新的采样点被放置在网格曲面上,通过连接这些顶点,能够构建出一个新的网格。使用重采样算法的主要目的是在于,通过重采样我们能够获得想要的网格连接结构。不过其主要的缺点在于,如果采样模式与网格区域没有对齐,那么就会出现走样(Aliasing)。为了避免这个问题,我们需要手动将网格根据其特征将其分割为不同的区域。
Mesh approximation algorithms:网格逼近通过一系列的网格优化策略来最小化某个定义明确的错误量。
Vertex Clustering
Vertex Clustering的的基本思想是:给定一个逼近容忍度遍历ε,然后将物体表面的包围空间划分成一些直径小于ε的小晶胞(Cell)。对于每一个小晶胞(Cell),计算出一个坐标来代表这个小晶胞(Cell)。同一个小晶胞(Cell)内的点、面或者边最终都会最终退化为一个顶点。简单地说就是将一个小晶胞(Cell)内的所有顶点退化为一个顶点。
对于分属两个小晶胞(Cell)的聚类P和Q,如果p和q是最终得到的能够代表P和Q所在小晶胞(Cell)内的顶点,那么p和q是连接的,当且仅当聚类P和Q原来包含的一系列顶点中存在一对相连接的顶点(pi, qj)。
假设原网格是2维流形(2-Manifold),通过Vertex Clustering得到的结果并不一定是2维流形(2-Manifold)。当几个最终退化成为一个点的曲面和圆盘(Disk)不同胚(homeomorphic)的时候,流形的拓扑结构会发生改变。
这既是缺点又是优点,正是因为可以改变模型的拓扑结构,所以Vertex Clustering能够很有效的降低网格的复杂度。举一个例子,如果我应用一个不能改变拓扑结构的简化到一个海绵的模型上,考虑到海绵有很多小洞,如果不改变它的拓扑结构,它的复杂度并不会减少。
Vertex Clustering的计算效率主要由将网格上的顶点映射到一个聚类(Clustering)这个过程决定。如果将空间划分成等大的若干小晶胞(Cell),那么这个过程的复杂度是线性的。然后对于一个小晶胞(Cell),我们用一个顶点来表示它。因为小晶胞(Cell)的数量远远少于顶点数,这个过程耗费的时间远远少于前一个过程。
Vertex Clustering的另一个优点是通过定义一个不同的聚类(Clustering),能够保证逼近的容忍度。
然而实际操作中会发现,实际逼近的偏离度会小于的聚类(Clustering)的半径。考虑一个最终会退化为一个顶点的很大的平面,其逼近的偏离度远远的小于聚类(Clustering)的半径。所以说给定一个错误阈值,往往不能最优地简化复杂度。
不同的Vertex Clustering算法的主要区别是其计算代表小晶胞(Cell)的那个点的方法不同。其中最简单的一种方法就是直接计算小晶胞(Cell)内相关点的平均值。
一个更合理的方法是使用最小二乘逼近的方法去寻找这个点的最优位置。
记小晶胞(Cell)内的某个三角形所在的平面为
其中xi为平面上的某一点,ni为它的法向量。那么任意一点x到该平面的距离的平方为
我们可以把x和n写成其次坐标来简化上面的式子,即x =(x,1),ni = (ni, -d),得到
使用同样的方法计算并累加这个小晶胞(Cell)内所有的三角形,得到(称之为二次误差度量Quadric Error Metric)

通过解下面这个线性方程,我们能够得到x的最优解
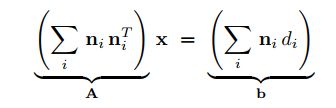
其中矩阵A和向量b,可以从Q中得到

针对不规则的三角剖分网格,我们可以使用三角形的面积最为权重,改写上面的式子为下面的形式
之后使用同样的方法进行计算即可。
Incremental Decimation
Incremental Decimation的主要思想是:通过不断地迭代来逐渐移除掉网格上的顶点。每次迭代时根据指定的标准移除一个顶点,标准可以是二态的(Binary)(即移除或不移除),这时通常需要一个全局的逼近容忍度(Approximation Tolerance)或一些其它的全局量,如三角形的宽高比等;也可以是连续的(Continuous)(移除这个顶点后网格的整体质量),这时我们会考虑如:两个相邻的三角形之间法向量的变化越小越好,各项同性的三角比各项异性的三角形要好。
每一次发生移除操作的时候,曲面某些区域的几何结构就会发生变化,所以我们需要重新的评估当前的曲面,而在整个迭代的过程中这个过程是最耗费时间的。根据给定的标准,我们可以给每一个顶点一个优先级,每次进行移除操作的时候都会选取当前优先级最高的顶点,所以这里使用堆(Heap)来组织这些顶点是比较合适的。
拓扑操作
移除顶点的方法有很多,一个准则就是——越简单越好。即我们使用多个简单操作的组合来代替一些复杂的操作,常用的三种操作如下图所示:

Vertex Removal
假定与被移除相邻的边的数量为k,无论移除顶点和与该顶点相邻的边之后如何去“修复”留下的k边形的“坑”,最终三角形的数量必定为k-2。另外边的数量也一定会是k-3。
Edge Collapse
该操作接受两个相邻的顶点,然后对连接它们的边进行Collapse操作,即我们把这两个顶点移动到一个相同的位置r,这个位置可以选取是自由的(在灰色区域中)。在操作后,与这条边相邻的两个三角形发生退化被移除,另外顶点的数量减少了1,边的数量减少了3。
可以发现Vertex Removal操作需要我们决定k边形“坑”的划分方式,Edge collapse操作需要我们决定新的顶点的位置。因此在执行的它们的时候我们还需要去寻找最优解。
Halfedge Collapse
该操作基于半边数据结构,即对于顶点p和q,边p→q和边p←q是不同的。Halfedge Collapse操作可以看作是Edge Collapse的一种特殊情况——对于边p→q,我们将p和q都移动到点q上。较前两种操作不同,在进行Halfedge Collapse操作的时候,我们并不需要寻找其最优解。这样移除操作和全局优化(待移除点的选取)完全分离,使得算法的实际更加方便。
在进行此操作的时候边p→q需要满足下面两个条件:
如果p和q都是边界上的顶点,那么边p→q也必须位于边界之上。
与点p相邻的顶点的集合和与q相邻的顶点的集合的交集只能是与边p→q相对的两个顶点。
如果不满足上述两个条件,则会分别出现下图的情况

Vertex Contraction
Vertex Contraction与Edge Collapse操作类似,区别是Vertex Contraction操作可以对任意的两个点的进行操作(并不一定是要相邻的两个点)。经过该操作后欧拉示性数(Euler characteristic)将发生变化,并且在选取点r周围的曲面将不再和圆盘(Disk)是同胚的。
Distance Measures
在算法执行的过程,求解距离是必不可少的。直接求解距离是比较耗时的,为了加速运算,下面提出了3种效率比较高的近似算法:
Error Accumulation
Error Accumulation是这3种中最简单的一种方法。当我们每次执行Edge Collapse操作的时候都会移动与对应边相邻的两个三角形的某个顶点的顶点的位置。而新的位置r(这两个顶点移动到的位置)与原来三角形距离就是这个过程中的逼近产生误差的上限。Error Accumulation即通过存储这样每一个三角形的误差,并累加到每一次的简化操作之中。误差既可以使用标量也可以使用矢量,使用矢量的时候方向相反的误差可以相互抵消。
Error Quadrics
Error Accumulation法通过累加与顶点p 相邻的所有三角形来计算某个顶点p的误差矩阵Qp。当顶点p和另一个顶点q通过Collapse操作移动到一个新的顶点r的时候,则有Qr = Qp + Qq,然后使用前面介绍的公式得到方程
通过解该方程就能得到r的最优的位置了。在这里我们使用点到平面的距离来近似点到三角形的距离,这会导致真实的误差偏小;另外新的误差矩阵Qr是通过累加顶点p和顶点q的误差矩阵得到的,这之中会有一部分三角被重复计算,这回导致误差偏大。总的来说,这两者会相互抵消一部分。
另一方面,每一个顶点只需要存储一个4*4的矩阵,误差可以通过计算
得到。因为无论顶点x周围有多少相邻的平面(已经被累加到矩阵Q里),计算所需要的时间都是常数,所以这个方法是这三种中使用最广泛的一种。
Hausdorff Distance
给定集合A和B,对于每一个集合A中的元素a,首先得到元素a到集合B中每一个元素距离的最小值da。集合A中所有元素对应的da的最大值即为集合A到集合B的Hausdorff距离,几位H(A,B),通常H(A,B)≠H(B,A)。

通过计算原模型到简化后模型的Hausdorff距离,我们能够得到逼近误差。为了计算Hausdorff距离,我们会不断地追踪整个简化的过程。每当进行Edge Collapse操作的时候,我们都将被移动的点p和q记录到其周围区域中离它最近的三角形中。这样每一个三角形在任何时刻都记录着原模型中里它最近点的列表。这样我们是需要找到这些列表中的最大值就能够求得Hausdorff距离。
Fairness Criteria
通过前面介绍的不同的距离计算方式,我们能够决定某个顶点能否被移除,而对于可以被移除得顶点,我们还需要额外的标准来为每一个顶点指定一个移除优先级。
一个直接的方法就是利用距离度量的值来对待移除顶点进行排序,即每一次简化操作我们将会移除导致误差增大量最小的顶点。
如果想要生成的网格的三角形更接近等边三角形,那么我可以使用三角形外接圆的半径与三角形最短边的长度的比值来排序。
如果想要更为平滑的网络,我们可以使用法向量在相邻三角形间的变化量的平均值或最大值作为标准来进行排序。
纹理颜色的变化率或者是纹理的边形程度都可以作为排序的标准。
我们称这些排序的标准为Fairness Criteria。通过将Fairness Criteria和其它的模块相互分离,可以极大地提高算法的灵活度。
Shape Approximation

算法的全称是Variational Shape Approximation (VSA) ,VSA产生具有各向异性的网格,并且质量较好。并且VSA不需要输入模型的全局参数化信息和局部的微分量。
假设M是一个三角形网格,我们M划分为k个区域
然后我们定义一个包含有k个“代理(Proxy)平面”的集合
每一个代理平面可以通过平面上的任意一点和它的法向量决定
在VSA中,我们通常使用下面两种方式来衡量代理平面和三角形网格某个区域的距离:
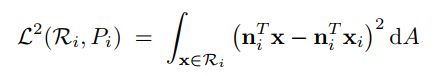

①式的被积函数正好是三角形网格区域Ri上的点x到代理平面Pi的距离的平方。
VSA的主要思想是:给定划分数k和一个距离衡量函数E(①或②),找到一组划分
和一组代理平面
使得下面的全局形变量E取最小值。

最后根据得到的一组代理平面,我们能够得到简化后的模型。
整个算法在两个阶段——几何划分(Geometry Partitioning)和代理平面拟合(Proxy Fitting)之间交替迭代。前者固定代理平面,调整区域划分;后者固定区域划分,调整代理平面。
几何划分(Geometry Partitioning)
在几何划分阶段,代理平面会被固定
区域划分会被修改以最小化全局形变量E。
首先,算法会通过遍历选择区域Ri的每一个三角形并分别计算E(t,Pi)的值,然后找到该值最小的三角形ti。三角形ti(所在的平面)是Ri中与代理平面Pi最为接近的。
对于每一个区域有:
对于三角形ti周围的三角形r,我们以E(r, Pi)为优先级,插入一个优先队列中。
之后,取出队头元素,如果该三角形没有被加入集合Ri则将其加入集合Ri。然后我们选择该三角形周围的三角形并插入优先队列中。算法重复上述过程直到整个队列为空。
算法的伪代码是:

算法初始化的时候会在输入的网格上随机的选择k个三角形,按照
的方式初始化每一个划分区域,然后使用三角形的法向量和其上的任意一点来初始化对应的代理平面。通过上面的算法,每一个划分区域都会慢慢的变大。
代理平面拟合(Proxy Fitting)
在这个阶段中,区域划分R会被固定,代理平面P会被调整以最小化全局形变量E
如果我们使用①式作为距离衡量函数,假设Ri内的三角形上,d1, d2, d3是三角形三个顶点到代理平面Pi = (Xi, Ni)的垂直距离,那么此时①式可以写为
为了使得全局型变量E最小,则调整后的代理平面中,Xi为
Ni为下面的矩阵的最小特征值所对应的特征向量
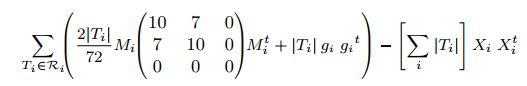
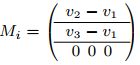
如果我们使用的是②式,假设Ri内的三角形为Ti = (v1, v2, v3),其代理平面为Pi = (Xi, Ni)的垂直距离,那么此时②式可以写为
那么调整后,Ni为(注意单位化)
并且②的最小化与Xi的值无关,Xi通常取取该区域Ri的重心坐标。
提取网格(Mesh Extraction)
得到最优解之后,我们就能从中提取出新的网格结构。首先我们标记出原网格上与三个以上划分区域相邻的顶点,然后将它们投影到每一个代理平面上,然后计算出位置的平均值。这些点被称为是锚点(Anchor Vertex),通过追踪划分区域的边界,我们将这些锚点连接起来,然后再每一个面上进行三角分割操作即可得到结果网格。
Greedy Shape Approximation
Greedy Shape Approximation是上述算法的改进形式,相较于前者它具有以下两个优点:
- 算法能够自然地生成一些列不同逼近程度的网格。
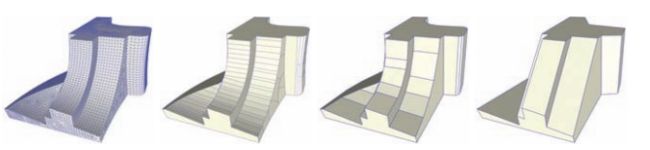
- 输出网格能够避免重影(Fold-Over)和退化的面(Degenerate Face)。
不过由于该算法使用贪心法来最小化下面的全局型变量所以其结果可能会陷入到局部最优解中。
并且该算法还涉及到了德洛内三角剖分的相关计算。
除了区域划分R、代理平面P之外,该算法还用到了一个多边形面的集合F = {f1, ..., fk}。集合F内的元素可以是任意连接的多边形(由外边界和内边界)。
初始化的时候,R的每一个区域都只包含一个三角形
Ri对应的代理平面Pi为
其中xi为三角形ti上的任意一点,ni为三角形的法向量。
F的元素为
由于算法要保证生成的网格没有重影(Fold-Over)和退化的面,所以整个算法要保证:从fi到Pi的映射是单射。
由于算法在运行的任意时刻始终满足上述的单射限制(Injectivity Constraint)条件,在算法执行的任意时候我们都能够提取出正确的网格。
为了在面fi上生成三角剖分,我们先将fi投影到Pi上,然后在Pi上进行三角剖分,然后将三角形重新还原到fi上。
该算法同样是迭代算法,在满足定义的条件之前(误差或者区域数)。每次我们选取两个区域Ri和Rj,让那和将它们合并为一个新的区域
新的区域R' = (x', n')的x', n'是由原区域的对应值以面积为权重加和得到,其中ai是Ri的面积

新的边f'是原来两个面fi和fj相交并去掉公共边之后得到。然后算法检查所有相邻边只有2条的顶点,如果该顶点是内部的顶点则移除它,如果它是边界上的顶点,只有当其到代理平面的距离小于用户定义的阈值的时候才将其移除。
需要注意在进行上述操作,要注意始终满足单射限制(Injectivity Constraint)条件。
为了加速算法,在计算误差的时候我们并不重新计算E(R’, P'),而是使用下面的方式进行近似计算
其中Di是Ri三角形的某个子集,由于包含了更少的三角形,所以计算效率会更高。
最后我们将这两种距离衡量函数合并,得到
总体上看,VSA算法能够通过设定较低的误差阈值得到高质量的网格,但是得到的网格中可能会包含重影(Fold-Over)或者退化的三角形。而改进后的基于贪心的VSA算法能够一些列不同质量的网格,并且不会产生重影(Fold-Over)。由于改进算法是基于贪心的思想,所以可能求解出来的是局部最优解。