原文链接:https://medium.com/google-cloud/kubernetes-101-pods-nodes-containers-and-clusters-c1509e409e16
在云技术领域,Kubernetes飞快地成为了配置和管理软件的新标准。然而强大的功能意味着陡峭的学习曲线,学习官方文档对于初学者来说是一项十分艰巨的任务。整个系统由许多不同的部分组成,很难说清楚哪些部分与你的项目相关。这篇文章试图从一个高度概括的视角介绍大部分重要的概念以及它们之间的关系。
首先,我们来看一下硬件是怎样表示的。
硬件
节点
节点是Kubernetes中计算硬件的最小单元,它代表集群中的一台机器。在大多数生产环境中,节点是一个数据中心中的物理机,或者架设在云平台上(例如Google Cloud Platform)的一台虚拟机。但不管怎么样,不要被惯性思维所拘束。理论上来讲,一个节点几乎可以是任何东西。
将一台机器看做一个“节点”可以让我们对这些抽象概念产生新的理解。现在,我们不再考虑任何一台机器的个体特征,而是简单的将每台机器看作一组可以利用的CPU和RAM。这样的话,一个Kubernetes集群中的任意两台机器都可以彼此代替。
集群
尽管单独处理某个节点会十分有效,但这并不是Kubernetes的工作方式。一般我们会把整个集群看作一个整体,而不去单独考虑每个节点的状态。
在Kubernetes中,节点中所包含的资源聚集在一起,共同形成一台更强大的机器。当你把程序部署到集群上时,它会将任务智能地分配到不同的节点上。如果某些节点被添加或者移除,集群会在必要时将任务转移给其它节点。究竟是哪些机器实际在运行代码不会对程序或者程序员产生任何影响,
如果这种像蜂群思维一样的系统让你联想到星际迷航中的Borg,那你就对了:“Borg”是Google的内部项目,是Kubernetes构建的基础。
持久卷
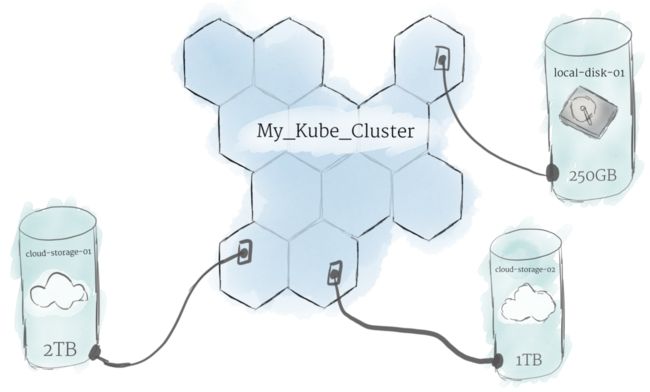
由于运行在集群上的程序不能保证始终运行在一个特定的节点上,所以数据不能存储在文件系统中一个任意的位置上。设想这样的场景,如果一个程序想要稍后把数据存储到某个文件中,但这个文件随即迁移到了一个新的节点上,程序便不能再把数据存储到预想的位置了。基于这种原因,数据无法永久的存储在本地,所以每个节点的本地存储都被视为临时缓存,用来运行程序。
为了可以永久性的存储数据,Kubernetes使用持久卷。虽然所有节点的CPU和RAM都由集群进行有效地集中和管理,但持久性的文件存储并不如此。无论是本地还是云端的驱动都可以依附在集群上作为持久卷使用,我们可以将它们看作插入集群的外部硬件驱动。持久卷提供了一个可以安装在集群上的文件系统,而且它不会与任何特定的节点产生联系。
软件
容器
在Kubernetes上运行的程序都会被打包成Linux容器。容器已经是一个被广泛接受的标准,所以有很多预构建的镜像可以直接在Kubernetes上进行部署。
使用容器进行集装箱化管理可以创建出像Linux一样独立的执行环境。任何程序及其依赖都可以打包到一个文件中,并在云端进行共享。所有人都可以下载这个容器,通过非常简单的配置就可以将它部署到自己的设备上。容器可以通过程序来创建,这就为持续集成与流水线化发布创造了条件。
多个程序可以被添加到同一个容器中,但是一个容器应该尽可能只运行一个进程。让多个容器分别运行多个进程比一个容器同时运行很多个进程要好得多。这样每个容器都更容易被监控,部署更新和诊断错误也将变得更加容易。
Pods

Kubernetes不像你过去用过的其它系统,它不直接运行容器,而是将一个或多个容器打包在一个更高的结构中,这个结构就是pod。同一个pod中的所有容器共享资源和局域网,它们可以像在同一台机器中一样方便地交流,同时也能保持彼此独立。
Pods是Kubernetes中的最小单元。如果你的应用非常受欢迎,以至于一个pod实例无法承载这么大的负荷,这时可以通过配置Kubernetes在集群中为你的pod部署新的副本。即使不是在超负荷的情况下,通常也会在生产环境中同时运行多个pod,来平衡负载量和避免错误的发生。
一个pod可以容纳多个容器,但尽可能不要容纳太多。在按比例增加或减少pod的时候,不会考虑到内部的某个容器,而是会一起进行缩放。这会导致资源的浪费和高昂的成本。为了避免这个问题,应该尽可能让pod保持轻量级,一般来说,一个pod中只运行一个主进程和与之紧密耦合的帮助型容器(这些帮助容器像“助力车的轮子一样”)。
部署
尽管pod是Kubernetes的基本计算单元,但它们并不直接在集群上启动,而是通常由部署控制器进行管理。
部署的主要目的是声明一次性运行pod副本的个数。当一个部署被加到集群中后,它会自动启动相应数量的pod,然后对它们进行监控。如果一个pod消亡了,部署会自动重新创建一个。
通过部署,可以不用手动管理pods。只需要声明一个系统的理想状态,它就会自动进行管理。
Ingress
通过上文所介绍的概念,你可以创建一个包含多个节点的集群,然后在集群上启动部署,实现对pod的管理。现在只剩下最后一个问题:如何让你的应用可以对外通信。
默认情况下,Kubernetes为pod和pod之间,pod和外部环境提供隔离。如果你想要和pod中运行的服务进行通信,你需要开启一个交流通道,即ingress。
有很多种方式为你的集群添加ingress,最常用的方法是添加Ingress controller或者LoadBalancer(负载均衡)。如何在这两种方法中进行选择超出了本文的讨论范围,但在你开始试用Kubernetes之前,需要先解决ingress的问题。
下一步
本文所讨论的概念是简化后的Kubernetes,但它可以帮助你快速开始试用。现在你已经了解了构成系统的组件,是时候用它们来部署一个实际的应用了。你可以通过阅读我的下一篇文章《Kubernetes第110课:第一次部署》来起步。
当你在本地使用Kubernetes时,Minikube会在你的硬盘上创建一个虚拟的集群。如果你想要尝试使用云端服务,可以参考Google Kubernetes Engine提供的一系列新手教程。
如果你刚开始接触容器化和网络基础架构,我建议你熟读“应用的12个要素”。它介绍了一些设计应用过程中的最佳实践方法,帮助你的应用在诸如Kubernetes这样的环境中运行。
最后,如果你想获取更多相似内容,可以在Medium上关注Daniel Sanche或者在Twitter上关注@DanSanche21。