关于我的仓库
- 这篇文章是我为面试准备的iOS基础知识学习中的一篇
- 我将准备面试中找到的所有学习资料,写的Demo,写的博客都放在了这个仓库里iOS-Engineer-Interview
- 欢迎star
- 其中的博客在,CSDN都有发布
- 博客中提到的相关的代码Demo可以在仓库里相应的文件夹里找到
前言
- 本文将会探究整个weak实现的流程,并尽可能深挖里面的源码
- weak确实是runtime里的一个难点,主要我目前没有系统学习过C++,数据结构,很多知识都是现查的,本文可能有很多疏漏,请读者斧正
准备工作
- 请准备好750.1版本的objc4源码一份【目前最新的版本】,打开它,找到文章中提到的方法,类型,对象
- 一切请以手中源码为准,不要轻信任何人,任何文章,包括本篇博客
- 文章中的源码都请过了我的删改,建议还是先看看源码
- 源码建议从Apple官方开源网站获取obj4
- 官网上下载下来需要自己配置才能编译运行,如果不想配置,可以在RuntimeSourceCode中clone
数据模型
- 看过我的其他博文的读者应该发现我比较喜欢看源代码方法调用栈,看到某个方法,再去研究其涉及的数据模型
- 但由于weak涉及到的数据模型过多,不一口气讲完很容易搞混,所以在这里我会把所有涉及到的数据模型全部讲清楚,包括里面存什么,以什么方式存等等
- 这样子也方便大家先对weak有个基础的概念,下面看方法调用栈也不至于懵逼
- 如果看下一部分的方法调用栈里对数据模型模糊了,请切回这一部分研究
SideTables()
- SideTables()是一个全局的哈希表,里面存储了sideTable结构体,根据对象的地址可以在sidetables()找到相应的SideTable
- SideTables()的定义:
static StripedMap& SideTables() {
return *reinterpret_cast*>(SideTableBuf);
}
- 可以大致理解为,该方法会返回一个StripedMap类型的数据结构,里面存储的类型是SideTable
StripedMap
template
class StripedMap {
#if TARGET_OS_IPHONE && !TARGET_OS_SIMULATOR
enum { StripeCount = 8 };
#else
enum { StripeCount = 64 };
#endif
struct PaddedT {
T value alignas(CacheLineSize);
//enum { CacheLineSize = 64 };
};
PaddedT array[StripeCount];
//enum { StripeCount = 64 };
static unsigned int indexForPointer(const void *p) {
uintptr_t addr = reinterpret_cast(p);
return ((addr >> 4) ^ (addr >> 9)) % StripeCount;
}
public:
//重载
T& operator[] (const void *p) {
return array[indexForPointer(p)].value;
}
const T& operator[] (const void *p) const {
return const_cast>(this)[p];
}
};
- 这里面其实StripedMap里一共就一个PaddedT类型的数组,大小为StripeCount【64】
- SideTables() 返回的 StripedMap, 是一个 value 为 SideTable 的哈希桶(由于 SideTable 内部又在维护数组, 所以这是一个哈希桶结构), 哈希值由对象的地址计算得出
补充知识:哈希桶
- 哈希桶算法就是链地址解决冲突的方法
- 所谓哈希桶,以SideTables与SideTable的方式来举例的话,就是本来数据数量不多的时候,只要有个SideTables就行,但由于数据数量超过了64【SideTables内部数组的长度】,导致出现了哈希冲突,两个对象都有f(key),需要占用同一个空间
- 哈希桶就是将这个数组的单个空间扩展成一个拉链一样的结构,将指向同一个空间的值存到同一条拉链上
- 这里,SideTable就是一条拉链,一个对象根据其地址在SideTables上找到相应的SideTable,存入其中
- 拉链可以用数组/链表组织数据,Apple使用的是数组
补充知识:模版函数
- 面向对象的继承和多态机制有效提高了程序的可重用性和可扩充性。在程序的可重用性方面,程序员还希望得到更多支持。
- C++ 语言支持模板。有了模板,可以只写一个 Swap 模板,编译器会根据 Swap 模板自动生成多个 Sawp 函数,用以交换不同类型变量的值。
- 这里也就是说,不规定T的数据类型,输入什么,就使用进行运算
补充知识:alignas()
- 指定类型或对象的对齐要求。
- alignas 说明符可应用于变量或非位域类数据成员的声明,或可应用于 class/struct/union 或枚举的定义。它不能应用于函数形参或 catch 子句的异常形参。
- 这种声明所声明的对象或类型的对齐要求,将等于用于该声明的所有 alignas 说明符中最严格(最大)的非零 表达式,除非这会削弱类型的自然对齐。
- 也就是说,它保证了value中的值是与64对齐
补充知识:重载
- C++ 允许在同一作用域中的某个函数和运算符指定多个定义,分别称为函数重载和运算符重载。
- 重载声明是指一个与之前已经在该作用域内声明过的函数或方法具有相同名称的声明,但是它们的参数列表和定义(实现)不相同。
- 当您调用一个重载函数或重载运算符时,编译器通过把您所使用的参数类型与定义中的参数类型进行比较,决定选用最合适的定义。选择最合适的重载函数或重载运算符的过程,称为重载决策。
- 简单来说,这里面
T& operator[] (const void *p) {
return array[indexForPointer(p)].value;
}
- 就等同于把[]运算符重新定义了,其作用现在是array[indexForPointer(p)].value
- 这里提一下这个,因为接下来会用到[]运算符
SideTable
- SideTable的定义一点都不长,却很麻烦
struct SideTable {
spinlock_t slock; //自旋锁
RefcountMap refcnts; //存放引用计数
weak_table_t weak_table; //weak_table是一个哈希
};
- 这里先来看这三兄弟是干什么的
spinlock_t slock【自旋锁】
补充知识:锁
- 锁是操作系统中的一个概念
- 为了保证数据的一致性,在多线程编程中我们会用到锁,使得在某一时间点,只有一个线程进入临界区代码。虽然不同的语言可能会提供不同的锁接口,但是底层调用的都是操作系统的提供的锁,不同的高级语言只是在操作系统的锁机制基础上进行了些封装而已,要真正理解锁,还是得看操作系统是怎么实现锁的。
- 以引用计数举例,由于我们的程序是多线程的,可能在不同的线程都会对某个对象的应用计数操作,导致混乱
- 这里使用锁,当某次访问开始时,锁就被持有,其余访问就不能进行,当访问结束,锁被空出来,才能轮到其他访问去竞争这把锁
补充知识:分离锁&&拆分锁
- 再以我们的SideTables以及SideTable举例,我们使用一把锁,锁住整个SideTables,只要SideTables里某个SideTable里的某个对象的引用计数被访问了,我们就把整个SideTables禁止访问
- 这样显然会导致效率低下
- 分离锁和分拆锁的区别
- 降低锁竞争的另一种方法是降低线程请求锁的频率。分拆锁 (lock splitting) 和分离锁 (lock striping) 是达到此目的两种方式。相互独立的状态变量,应该使用独立的锁进行保护。有时开发人员会错误地使用一个锁保护所有的状态变量。这些技术减小了锁的粒度,实现了更好的可伸缩性。但是,这些锁需要仔细地分配,以降低发生死锁的危险。
- 如果一个锁守护多个相互独立的状态变量,你可能能够通过分拆锁,使每一个锁守护不同的变量,从而改进可伸缩性。通过这样的改变,使每一个锁被请求的频率都变小了。分拆锁对于中等竞争强度的锁,能够有效地把它们大部分转化为非竞争的锁,使性能和可伸缩性都得到提高。
- 分拆锁有时候可以被扩展,分成若干加锁块的集合,并且它们归属于相互独立的对象,这样的情况就是分离锁。
- 继续举例,我们将每个SideTable里的每个对象的引用计数都加一把锁,这就是分拆锁,这样虽然安全,但却是的消耗特别大
- 而我们将给每个SideTable上一把锁,只让某个SideTable不能多次访问,这就是分离锁,根据源码也能看出来,这就是苹果的选择
补充知识:自旋锁
- 自旋锁比较适用于锁使用者保持锁时间比较短的情况。正是由于自旋锁使用者一般保持锁时间非常短,因此选择自旋而不是睡眠是非常必要的,自旋锁的效率远高于互斥锁。信号量和读写信号量适合于保持时间较长的情况,它们会导致调用者睡眠,因此只能在进程上下文使用,而自旋锁适合于保持时间非常短的情况,它可以在任何上下文使用。
- 这是一种不太高级的锁结构,但却很符合我们的需要,因为引用计数的操作是十分频繁的,使用自旋锁,只是让访问者自旋一会,一旦可以访问了,立即访问,增加效率
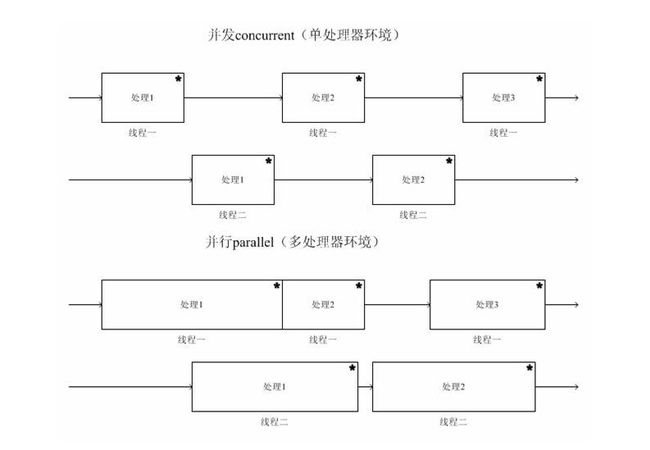
补充知识:并行&&并发
- 多线程的情况下,整个程序是一个并行的状态,导致我们需要使用锁
FC57708B-D697-4FC1-A508-7DAD9609697C
苹果的抉择
- 苹果使用了自旋锁,分离锁,给单个的SideTable上锁
- 保证了安全性的同时有兼具效率
RefcountMap refcnts【存放引用计数】
- 引用计数存在RefcountMap结构里,也就是上文介绍哈希桶的时候提到的拉链
- 这也是个hash结构,根据对象地址存储引用计数
//RefcountMap
typedef objc::DenseMap,size_t,true> RefcountMap;
//DenseMap
template >
class DenseMap
: public DenseMapBase,
KeyT, ValueT, KeyInfoT, ZeroValuesArePurgeable> {
// Lift some types from the dependent base class into this class for
// simplicity of referring to them.
typedef DenseMapBase BaseT;
//ZeroValuesArePurgeable:ZeroValuesArePurgeable 默认值是 false, 但 RefcountMap 指定其初始化为 true. 这个成员标记是否可以使用值为 0 (引用计数为 1) 的桶.
typedef typename BaseT::BucketT BucketT;
friend class DenseMapBase;
BucketT *Buckets;
//Buckets 指针管理一段连续内存空间, 也就是数组, 数组成员是 BucketT 类型的对象桶的 key 为 EmptyKey 时是空桶
//typedef std::pair BucketT;
//桶的数据类型std::pair,将对象地址和对象的引用计数(这里的引用计数类似于 isa, 也是使用其中的几个 bit 来保存引用计数, 留出几个 bit 来做其它标记位)组合成一个数据类型.
unsigned NumEntries;
//NumEntries 记录数组中已使用的非空的桶的个数.
unsigned NumTombstones;
//当一个对象的引用计数为0, 要从桶中取出时, 其所处的位置会被标记为 TombstoneNumTombstones 就是数组中的墓碑的个数. 后面会介绍到墓碑的作用
unsigned NumBuckets;
//NumBuckets 桶的数量, 因为数组中始终都充满桶, 所以可以理解为数组大小.
}
DisguisedPtr
- DisguisedPtr是runtime对于普通对象指针(引用)的一个封装,目的在于隐藏weak_table_t的内部指针。
//苹果的注释:
//DisguisedPtr与指针类型T*类似,除了对存储值进行伪装,以使其不受“leaks”等工具的影响。
//nil被伪装成它自己,所以零填充的内存按预期工作,
//这意味着0x80..00也被伪装成自己,但我们不在乎。
//注意,weak_entry_t不知道这个代码。
template
class DisguisedPtr {
uintptr_t value;
static uintptr_t disguise(T* ptr) {
return -(uintptr_t)ptr;
}
static T* undisguise(uintptr_t val) {
return (T*)-val;
}
public:
DisguisedPtr() { }
DisguisedPtr(T* ptr)
: value(disguise(ptr)) { }
DisguisedPtr(const DisguisedPtr& ptr)
: value(ptr.value) { }
DisguisedPtr& operator = (T* rhs) {
value = disguise(rhs);
return *this;
}
DisguisedPtr& operator = (const DisguisedPtr& rhs) {
value = rhs.value;
return *this;
}
operator T* () const {
return undisguise(value);
}
T* operator -> () const {
return undisguise(value);
}
T& operator * () const {
return *undisguise(value);
}
T& operator [] (size_t i) const {
return undisguise(value)[i];
}
};
- 对于这个我了解的也不是很清楚,大概理解就是通过static uintptr_t disguise(T* ptr) {return -(uintptr_t)ptr;}来实现隐藏
- 我们试着理解Apple注释里说【0x80..00也被伪装成自己】,由于这个数字就是首位是1,该位在有符号的情况下理解为-0,则nil理解为+0【0正1负】,因此这里认为它们被伪装成了自己【还是不太懂啊!!!】
DenseMap
- 当你进入DenseMap定义的时候,抬头看下最上方的文件名,发现已经离开objc4了,进入了一个叫llvm-DenseMap.h的里世界,这里面的代码也是开着全局搜索也搜不到的神仙代码【但很奇怪,这里还是可以编辑】
补充知识:LLVM
- LLVM是构架编译器(compiler)的框架系统,以C++编写而成,用于优化以任意程序语言编写的程序的编译时间(compile-time)、链接时间(link-time)、运行时间(run-time)以及空闲时间(idle-time),对开发者保持开放,并兼容已有脚本。
- LLVM计划启动于2000年,最初由美国UIUC大学的Chris Lattner博士主持开展。2006年Chris Lattner加盟Apple Inc.并致力于LLVM在Apple开发体系中的应用。Apple也是LLVM计划的主要资助者。
- 目前LLVM已经被苹果IOS开发工具、Xilinx Vivado、Facebook、Google等各大公司采用。
- 简单来说,把这里的理解成某个第三方库就行
- 这个DenseMap中的操作我只不讲源码,只分析其流程,感兴趣可以自己深入
哈希实现
这个DenseMap本质上是std::pair
DenseMap同样是个hash结构,下面来分析它的流程【很多参数的解释我都在代码注释里写了】
这里借用下runtime(二) SideTables大神的图解完全讲清楚了问题,厉害
首先我们有一个初始化好的, 大小为 9 的桶数组

1479888-47765d58b3dbe9b8
- 同时有 a b c d e 五个对象要使用桶数组, 这里我们假设五个对象都被哈希算法分配到下标 0 的位置里. a 第一个进入, 但 b c d e 由于下标 0 处已经不是空桶, 则需要进行下一步哈希算法来查找合适的位置, 假设这 4 个对象又恰巧都被分配到了下标为 1 的位置, 但只有 b 可以存入. 假设每一次哈希计算都只给下标增加了 1, 以此类推我们能得到:

1479888-ea61e198d6f13201
- 假设这个时候 c 对象被释放了, 之前提到过这个时候会把对应的位置的 key 设置为 TombstoneKey:

1479888-ad718f8f3272421e
- 接下来就体现了墓碑的作用:
- 如果 c 对象销毁后将下标 2 的桶设置为空桶, 此时为 e 对象增加引用计数, 根据哈希算法查找到下标为 2 的桶时, 就会直接插入, 无法为已经在下标为 4 的桶中的 e 增加引用计数.
- 如果此时初始化了一个新的对象 f, 根据哈希算法查找到下标为 2 的桶时发现桶中放置了墓碑, 此时会记录下来下标 2. 接下来继续哈希算法查找位置, 查找到空桶时, 就证明表中没有对象 f, 此时 f 使用记录好的下标 2 的桶而不是查找到的空桶, 就可以利用到已经释放的位置.
- 对于DenseMap的分析我们就到这
weak_table_t weak_table
/**
* The global weak references table. Stores object ids as keys,
* and weak_entry_t structs as their values.
*/
struct weak_table_t {
weak_entry_t *weak_entries; //连续地址空间的头指针, 数组
//管理所有指向某对象的weak指针,也是一个hash
size_t num_entries; //数组中已占用位置的个数
uintptr_t mask; //数组下标最大值(即数组大小 -1)
uintptr_t max_hash_displacement; //最大哈希偏移值
};
- weak_table并没有直接是个数组存放weak指针,而是使用一个结构体weak_entry_t *weak_entries;去存放weak指针
weak_entry_t *weak_entries【存放weak指针】
struct weak_entry_t {
DisguisedPtr referent; //被指对象的地址。前面循环遍历查找的时候就是判断目标地址是否和他相等。
union {
struct {
weak_referrer_t *referrers; //可变数组,里面保存着所有指向这个对象的弱引用的地址。当这个对象被释放的时候,referrers里的所有指针都会被设置成nil。
//指向 referent 对象的 weak 指针数组
uintptr_t out_of_line_ness : 2; //这里标记是否超过内联边界, 下面会提到
uintptr_t num_refs : PTR_MINUS_2; //数组中已占用的大小
uintptr_t mask; //数组下标最大值(数组大小 - 1)
uintptr_t max_hash_displacement; //最大哈希偏移值
};
struct {
// out_of_line_ness field is low bits of inline_referrers[1]
weak_referrer_t inline_referrers[WEAK_INLINE_COUNT]; //只有4个元素的数组,默认情况下用它来存储弱引用的指针。当大于4个的时候使用referrers来存储指针。
//当指向这个对象的weak指针不超过4个,则直接使用数组inline_referrers,省去hash
};
};
这里有见到了我们的老朋友union,也就提示我们Apple同样是使用过同一段内存去存放不同的信息
这里有两个数组,一个是weak_referrer_t inline_referrers[WEAK_INLINE_COUNT],数组长度只有4,当某个对象的weak指针个数小于四的时候,会存入这个数组,当大于四的时候才会存到referrers当中
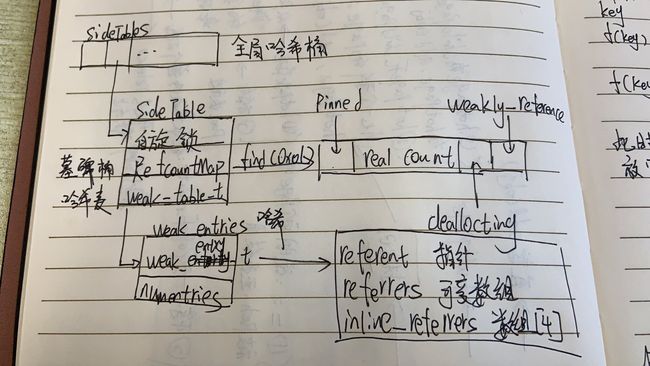
至此,所有的数据模型总结完毕
是不是感觉有点懵?
结构总结
9970D0DFF099F1E7DE96C437DB317714
- 总之只要是数组的基本都是哈希结构
SideTables以及SideTable的关系
- 这里借用下iOS管理对象内存的数据结构以及操作算法--SideTables、RefcountMap、weak_table_t-二大神的比喻
- 假设有80个学生需要咱们安排住宿,同时还要保证学生们的财产安全。应该怎么安排?
- 显然不会给80个学生分别安排80间宿舍,然后给每个宿舍的大门上加一把锁。那样太浪费资源了锁也挺贵的,太多的宿舍维护起来也很费力气。
- 我们一般的做法是把80个学生分配到10间宿舍里,每个宿舍住8个人。假设宿舍号分别是101、102 、... 110。然后再给他们分配床位,01号床、02号床等。然后给每个宿舍配一把锁来保护宿舍内同学的财产安全。为什么不只给整个宿舍楼上一把锁,每次有人进出的时候都把整个宿舍楼锁上?显然这样会造成宿舍楼大门口阻塞。
- OK假如现在有人要找102号宿舍的2号床的人聊天。这个人会怎么做?
1、找到宿舍楼(SideTables)的宿管,跟他说自己要找10202(内存地址当做key)。
2、宿管带着他SideTables[10202]找到了102宿舍SideTable,然后把102的门一锁lock,在他访问102期间不再允许其他访客访问102了。(这样只是阻塞了102的8个兄弟的访问,而不会影响整栋宿舍楼的访问)
3、然后在宿舍里大喊一声:"2号床的兄弟在哪里?"table.refcnts.find(02)你就可以找到2号床的兄弟了。
4、等这个访客离开的时候会把房门的锁打开unlock,这样其他需要访问102的人就可以继续进来访问了。 - SideTables == 宿舍楼;SideTable == 宿舍;RefcountMap里存放着具体的床位
- 苹果之所以需要创造SideTables的Hash冲突是为了把对象放到宿舍里管理,把锁的粒度缩小到一个宿舍SideTable。RefcountMap的工作是在找到宿舍以后帮助大家找到正确的床位的兄弟。
- 讨论完这些问题之后,我们终于可以开始研究weak调用的方法了
weak相关的方法
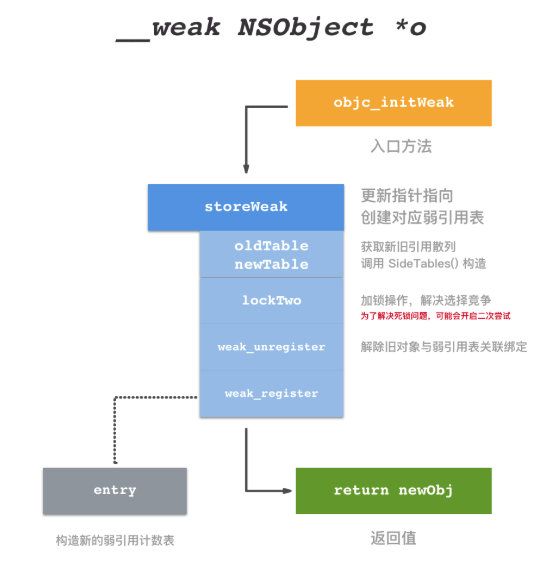
objc_initWeak(id *location, id newObj)
id
objc_initWeak(id *location, id newObj)
{
if (!newObj) {
*location = nil;
return nil;
}
return storeWeak
(location, (objc_object*)newObj);
}
- 该方法中的两个参数location是指weak 指针,newObj 是 weak 指针将要指向的对象
storeWeak(id *location, objc_object *newObj)
id oldObj;
SideTable *oldTable;
SideTable *newTable;
// Clean up old value, if any.
if (haveOld) {
weak_unregister_no_lock(&oldTable->weak_table, oldObj, location);
}
// Assign new value, if any.
if (haveNew) {
newObj = (objc_object *)
weak_register_no_lock(&newTable->weak_table, (id)newObj, location,
crashIfDeallocating);
// weak_register_no_lock returns nil if weak store should be rejected
// Set is-weakly-referenced bit in refcount table.
if (newObj && !newObj->isTaggedPointer()) {
newObj->setWeaklyReferenced_nolock();
}
// Do not set *location anywhere else. That would introduce a race.
*location = (id)newObj;
}
else {
// No new value. The storage is not changed.
}
return (id)newObj;
- 这里要先进行haveOld判断,也就是如果该指针有指向的旧值,先要weak_unregister_no_lock(&oldTable->weak_table, oldObj, location);处理旧值
- 之后在weak_register_no_lock(&newTable->weak_table, (id)newObj, location,crashIfDeallocating);进行赋值操作
weak_unregister_no_lock
//从原有的表中先删除这个 weak 指针注销已注册的弱引用。当引用者的存储即将消失,但引用还没有死。(否则,稍后归零引用将是内存访问错误。)如果引用/引用不是当前活动的弱引用,则不执行任何操作。引用不为零。
void
weak_unregister_no_lock(weak_table_t *weak_table, id referent_id,
id *referrer_id)
{
objc_object *referent = (objc_object *)referent_id; //weak 指针指向的对象
objc_object **referrer = (objc_object **)referrer_id; //referrer_id是 weak 指针, 操作时需要用到这个指针的地址
weak_entry_t *entry;
if (!referent) return;
if ((entry = weak_entry_for_referent(weak_table, referent))) { //查找 referent 对象对应的 entry
remove_referrer(entry, referrer); //从 referent 对应的 entry 中删除地址为 referrer 的 weak 指针
bool empty = true;
if (entry->out_of_line() && entry->num_refs != 0) { //如果 entry 中的数组容量大于 4 并且数组中还有元素
empty = false; //entry 非空
}
else {
for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) {
if (entry->inline_referrers[i]) { //否则循环查找 entry 数组, 如果 4 个位置中有一个非空
empty = false; //entry 非空
break;
}
}
}
if (empty) {
weak_entry_remove(weak_table, entry); //从 weak_table 中移除该条 entry
}
}
}
- 这里先是remove_referrer(entry, referrer);从对应的entry中删除该weak记录
- 之后我们需要判断,还有没有指向这个地址的weak指针了,所以有下面的判空操作,如果这个entry已经没有东西了,将整个删除
weak_entry_for_referent(weak_table_t *weak_table, objc_object *referent)
- 该方法通过对象的地址,获取到该weak_table中的entry【保存着指向某对象的所有weak指针】
static weak_entry_t *
weak_entry_for_referent(weak_table_t *weak_table, objc_object *referent)
{
assert(referent);
weak_entry_t *weak_entries = weak_table->weak_entries;
if (!weak_entries) return nil;
size_t begin = hash_pointer(referent) & weak_table->mask;
size_t index = begin;
size_t hash_displacement = 0;
while (weak_table->weak_entries[index].referent != referent) {
index = (index+1) & weak_table->mask;
if (index == begin) bad_weak_table(weak_table->weak_entries);
hash_displacement++;
if (hash_displacement > weak_table->max_hash_displacement) {
return nil;
}
}
return &weak_table->weak_entries[index];
}
- hash_pointer也是使用指针地址,映射到一个索引。
&weak_table->mask这个操作是?这个mask实际值是表的size-1,而size是2的n次方进行扩张的,所以mask的形式就1111 1111 1111这种,索引和mask位与之后的值必定就落在了[0, size]范围内。也就是说,先是通过hash_pointer对地址进行hash映射,得到下标,接下来通过位遮蔽,保证这个映射是在范围内的,不会超出范围 - index = (index+1) & weak_table->mask;是在遇到哈希冲突的时候,就一直往下找下一个位置
weak_register_no_lock
id
weak_register_no_lock(weak_table_t *weak_table, id referent_id,
id *referrer_id, bool crashIfDeallocating)
{
objc_object *referent = (objc_object *)referent_id;
objc_object **referrer = (objc_object **)referrer_id;
// now remember it and where it is being stored
weak_entry_t *entry; //如果 weak_table 有对应的 entry
if ((entry = weak_entry_for_referent(weak_table, referent))) {
append_referrer(entry, referrer); //将 weak 指针存入对应的 entry 中
}
else {
weak_entry_t new_entry(referent, referrer); //创建新的 entry
weak_grow_maybe(weak_table); //查看是否需要调整 weak_table 中 weak_entries 数组大小
weak_entry_insert(weak_table, &new_entry); //将新的 entry 插入到 weak_table 中
}
return referent_id;
}
- 这里如果该地址有对应的entry,在里面存入指针;如果没有entry,就新建entry,在里面插入weak指针,并插入weak_table
- 下面我们看下append_referrer的实现
static void append_referrer(weak_entry_t *entry, objc_object **new_referrer)
{
if (! entry->out_of_line()) { //如果数组大小没超过 4
// Try to insert inline.
for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) {
if (entry->inline_referrers[i] == nil) { //循环查找数组成员
entry->inline_referrers[i] = new_referrer; //把新的 weak 指针插入到空位置
return;
}
}
//也就是说走到这就是刚好之前有四个引用,现在添加第五个
//数组中的 4 个位置都非空, 就要调整策略使用 referrers 了
//从这里开始, 这一段是把 inline_referrers 数组调整为使用 referrers 的形式
// Couldn't insert inline. Allocate out of line.
weak_referrer_t *new_referrers = (weak_referrer_t *)
calloc(WEAK_INLINE_COUNT, sizeof(weak_referrer_t)); //还是开辟 4 个 weak_referrer_t 大小的空间
// This constructed table is invalid, but grow_refs_and_insert
// will fix it and rehash it.
for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) {
new_referrers[i] = entry->inline_referrers[i]; //将 inline_referrers 中的值赋值给 referrers
}
entry->referrers = new_referrers;
entry->num_refs = WEAK_INLINE_COUNT;
entry->out_of_line_ness = REFERRERS_OUT_OF_LINE;
entry->mask = WEAK_INLINE_COUNT-1;
entry->max_hash_displacement = 0;
}
assert(entry->out_of_line());
if (entry->num_refs >= TABLE_SIZE(entry) * 3/4) {
return grow_refs_and_insert(entry, new_referrer);
}
//开始哈希算法
size_t begin = w_hash_pointer(new_referrer) & (entry->mask);
size_t index = begin; //使用哈希算法计算到一个起始下标
size_t hash_displacement = 0; //哈希偏移次数
while (entry->referrers[index] != nil) { //循环找空位置
hash_displacement++;
index = (index+1) & entry->mask;
if (index == begin) bad_weak_table(entry);
}
//这里记录下移位的最大值, 那么数组里的任何一个数据, 存储时的移位次数都不大于这个值
//可以提升查找时的效率, 如果移位次数超过了这个值都没有找到, 就证明要查找的项不在数组中
if (hash_displacement > entry->max_hash_displacement) {
entry->max_hash_displacement = hash_displacement;
}
weak_referrer_t &ref = entry->referrers[index];
ref = new_referrer;
entry->num_refs++;
}
- 这里首先是要判断关联数组里有没有空位【关联数组没有使用哈希】,如果关联数组有空位的话,直接插入
- 没有空位需要使用且是刚好第五个的情况,需要初始化一个weak_referrer_t,将关联数组里的数据先存进去【也就是说不会两个一起用】
- 接下来通过哈希操作存入
赋值操作
weak_referrer_t &ref = entry->referrers[index];
ref = new_referrer;
entry->num_refs++;
- 这个赋值语句之前一直让我百思不得其解,现在感觉还是C语言学的不到位呀
- 首先,现在的index就是我们正确的插入下标,按照我们正常人明显应该这么写
entry->referrers[index] = new_referrer;
entry->num_refs++;
- 这是Apple偏偏没有这么写,写了上面这三行
- 说来惭愧,我之前都觉得weak_referrer_t &ref = entry->referrers[index];明显是错的,哪有初始化一个地址这个说法的
- 现在我的理解可能依然不太对,我觉得是这样,ref依然是个weak_referrer_t类型的变量,现在通过&取地址符,设置这个变量的地址【这里就觉得很迷了,一个结构体的地址怎么可以变呢?或者理解成ref不是一个实际上的变量,只是一个标志符】
- 现在我们把referrers[index]赋给了这个地址,也就相当于ref现在就是referrers[index]【自己都觉得解释的很不清楚。。。】
- 放一段自己做的实验
#include
using namespace std;
struct Padd {
int a;
float b;
}bucket[10];
int main(int argc, const char * argv[]) {
// insert code here...
std::cout << "Hello, World!\n";
int j = 0;
float k = 16;
for (Padd &i : bucket) {
i.a = j++;
i.b = k++;
}
for (Padd &i : bucket) {
cout << i.a << "XXX" << i.b << endl;
}
Padd *testPadd = (Padd *)malloc(sizeof(Padd));
testPadd->a = 99;
testPadd->b = 109;
Padd &ref = bucket[4];
ref = *testPadd;
printf("%p\n", &bucket[4]);
printf("%p\n", &ref);
for (Padd &i : bucket) {
cout << i.a << "XXX" << i.b << endl;
}
return 0;
}
dealloc后将weak指针置nil【weak_clear_no_lock(weak_table_t *weak_table, id referent_id) 】
void
weak_clear_no_lock(weak_table_t *weak_table, id referent_id)
{
objc_object *referent = (objc_object *)referent_id;
weak_entry_t *entry = weak_entry_for_referent(weak_table, referent);
if (entry == nil) {
return;
}
weak_referrer_t *referrers;
size_t count;
if (entry->out_of_line()) {
referrers = entry->referrers;
count = TABLE_SIZE(entry);
}
else {
referrers = entry->inline_referrers;
count = WEAK_INLINE_COUNT;
}
for (size_t i = 0; i < count; ++i) {
objc_object **referrer = referrers[i];
if (referrer) {
if (*referrer == referent) {
*referrer = nil;
}
}
}
weak_entry_remove(weak_table, entry);
}
- 前面将关联数组和referrers都看作一个数组,获取相应的count,进行nil操作
方法总结
2664540-255e050c9fafa044
后续更新
对于weak对象的访问:objc_loadWeakRetained
- 先回看下《iOS高级编程》中的描述
id __weak obj1 = obj0;
NSLog(@"class = %@",[obj1 class]);
id __weak obj1 = obj0;
id __autoreleasing tmp = obj1;
NSLog(@"class = %@",[tmp class]);//实际访问的是注册到自动释放池的对象
- 现在我们有源码了,可以看看具体是怎么实现的
//实验代码
NSObject *obj0 = [[NSObject alloc] init];
NSObject *obj1 __weak = obj0;
printf("retain count = %ld\n",CFGetRetainCount((__bridge CFTypeRef)(obj0))); //结果为1
printf("retain count = %ld\n",CFGetRetainCount((__bridge CFTypeRef)(obj1))); //断点打在这里 结果为2
- 接着跟着方法调用栈往下走,发现来到objc_loadWeakRetained
id
objc_loadWeakRetained(id *location)
{
id obj;
id result;
Class cls;
SideTable *table;
retry:
// fixme std::atomic this load
obj = *location;
if (!obj) return nil;
if (obj->isTaggedPointer()) return obj;
table = &SideTables()[obj];
table->lock();
if (*location != obj) {
table->unlock();
goto retry;
}
result = obj;
cls = obj->ISA();
if (! cls->hasCustomRR()) {
// Fast case. We know +initialize is complete because
// default-RR can never be set before then.
assert(cls->isInitialized());
if (! obj->rootTryRetain()) { //rootTryRetain执行了retain操作
result = nil;
}
}
table->unlock();
return result;
}
- 这过方法里的 if (! obj->rootTryRetain())这一句调用了retain方法,达到了引用计数+1,防止dealloc的作用
- 接着我们给objc_release方法打上断点,发现这句打印一结束,就会调用release方法【是谁调用的,为什么会调用的,我是一问三不知】
- 也就是说对于weak修饰对象的访问都会调用该方法,进行retain【包括NSObject *obj0 = [[NSObject alloc] init];NSObject *obj1 __weak = obj0;NSObject *obj2 = obj1;中的第三句,也算是访问】
- 因此,书上说的autorelease的方式并不是目前真正的实现方式了
- 我个人认为这种方式还要比autorelease更好理解些
isa_t中存放的引用计数
- isa_t中有这两块内容,uintptr_t has_sidetable_rc【是否使用sidetable来存放引用计数】,uintptr_t extra_rc【引用计数】
- 也就是说对于能存的下的引用计数是通过isa来存储的
- 这里我们可观察下retainCount方法来了解下这两块之间的关系
inline uintptr_t
objc_object::rootRetainCount()
{
if (isTaggedPointer()) return (uintptr_t)this;
sidetable_lock();
isa_t bits = LoadExclusive(&isa.bits);
ClearExclusive(&isa.bits);
if (bits.nonpointer) {
uintptr_t rc = 1 + bits.extra_rc;
if (bits.has_sidetable_rc) {
rc += sidetable_getExtraRC_nolock();
}
sidetable_unlock();
return rc;
}
sidetable_unlock();
return sidetable_retainCount();
}
- 哇,真的是好久没看到这么简单易懂的源码,在经历了各色妖魔鬼怪,现在这种跟幼儿读物一样的源码我们读起来完全跟割黄油一样easy,丝滑✌️
- 也就是说,最后返回的引用计数会是isa中的加上【如果超过限制】,sideTable中的
2019年7.27更新:为什么weak_entries中referrers要使用hash?
- 我们来理一理思路,在weak_entries中,已经有referent存储了被指对象的地址,referrers中存放的是所有指向该对象的weak指针的地址
- 而我们使用了hash的方式存储,我们将weak指针的地址hash出一个index来存放weak指针的地址
- 有没有觉得怪怪的?一般来说我们用key【一般是对象地址】哈希出一个index作为存放地址,存放的是对象本身,也就是value
- 但在这里,等于就是用key存key了。因此我之前以为这里没必要hash,因为假如我们希望查询到该weak指针的地址,我们得拿weak指针的地址去找。。。
- 但其实这里还是因为没有很好的理解他的意义,这张表不是为了查找weak指针的地址而存在的,而是要记录指向某一对象的所有weak指针而存在的,其存在的意义就是在记录上有本身
- 我们查找某一weak指针往往基本上就是为了把记录这个东西
- 在这张表上删除,我们的目的在于记录本身,而不是其value本身,以上。