作者 | Keunhong Park、Arsalan Mousavian、Yu Xiang、Dieter Fox
译者 | 刘畅
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导读】在本文中,华盛顿大学和英伟达联合提出了一种新的用于未见过目标 6D姿态估计的框架。作者设计了一个端到端的神经网络,该网络使用少量目标的参考视角来重构目标的3D表示。使用学习到的3D表示,网络可以从任意视角对目标进行渲染。使用该神经网络渲染器,我们可以对输入图像的姿势直接进行优化。通过使用大量3D形状训练该网络进行重构和渲染,使该网络可以很好地推广到未见过的目标。作者还为未见的物体姿态估计提供了一个新的数据集-MOPED。并且最后在MOPED以及ModelNet数据集上评估了未见物体姿态估计方法的性能。

论文地址:
https://arxiv.org/abs/1912.00416
目标姿态定义了它在空间中的位置以及方向。一个目标的姿态通常是由3D方向(旋转)和6个自由度(6D)定义的。了解目标的姿态对于涉及与现实世界对象交互的任务是至关重要的。例如,为了使机器人能够操纵目标,它必须能够推理出目标的姿态。在增强现实任务中,6D姿态估计可以实现虚拟交互和对现实目标的重新渲染。
为了估计目标的6D姿态,当前最新的方法需要为每个物体建立一个3D模型。尽管现在的3D重构和扫描技术可以生成目标的3D模型,但它们通常需要耗费大量的精力。很容易看出用这种方法为每个目标都去构建一个3D模型是不太现实的。

此外,现有的姿态估计方法在不同的光照和遮挡下,需要进行大量的训练。对于针对多目标训练一个网络的方法,姿态估计精度会随着目标的增加而显著下降。这是由于目标的外观与姿势变化很大。无论使用单个或多个网络,所有基于模型的方法都需要对训练集中没有的测试目标,进行额外的训练。
在本文中,作者研究了在没有3D模型的情况下,并且在测试时无需为未见目标进行额外训练的情况下,学习用于6D目标姿态估计的3D目标表示问题。本文方法的核心是根据已知的姿态获取目标的一些参考RGB图像,并在内部构建该目标的3D表示。使用内部的3D表示,网络可以渲染目标的任意视角。为了估计目标姿态,网络以梯度下降方式将输入图像与其渲染图像进行比较,以搜索渲染图像与输入图像匹配的最佳姿态。那如何将该网络应用于未见过的目标呢?我们仅需要使用传统方法来收集已经有的姿态视角图。并将这些视角图与相关的姿态一起提供给网络,它不需要花费时间和计算资源进行额外的训练。
为了重构和渲染未曾见过的目标,作者使用ShapeNet数据集(该数据集使用MS-COCO的图像,并在不同光照下进行纹理化)在随机的3D网格上训练。本文的实验表明,该模型可以推广到新的目标类别和实例上。从实际角度看,作者认为在缺少高保真纹理的3D模型情况下,从有限的视角图对未曾见过的目标进行姿态估计是一个十分重要的问题。为此,作者提出了一个新的评估数据集,称为MOPED(Model-free Object Pose Estimation Dataset)。本文的主要贡献如下:
本文提出了一种新的神经网络,该神经网络可以在参考视图数量有限的情况下重构一个新对象的潜在表示,并且可以从任意角度对其进行渲染而无需额外的训练.
本文演示了如何在没有额外训练时,对给定参考视图的未见目标进行姿态估计。
本文介绍了一个数据集MOPED。并提供了在可控环境中拍摄的目标参考图像,以及在不可控环境中拍摄的测试图像。
方法
在方法部分,作者分了两部分来阐述。一个是重构和渲染,一个是目标姿态估计。

上图是本文方法的概况图。整个流程主要有两个组成部分:(1)通过预测每个视图的特征量并将其融合为单个潜在表示来对目标进行建模。(2)对潜在表示进行深度和颜色上的渲染。

本文的建模过程受到了space carving的启发,考虑从多个视图中来获得观察结果,并利用多视图的一致性来构建规范化的表示。但是作者并没有使用光学一致性,而是使用隐藏特征来表示每个视图。上图阐述了每个视图特征的生成过程。

使用通道平均池化可以产生较好的结果,但是本文发现使用RNN可以稍微提高重构的精度,作者在实验章节做了相应的消融实验来验证。具体的融合模块如上图所示。
在目标姿态估计的方法上,作者使用了两个损失函数,一个是标准的L1损失,另一个是作者提出的一种潜在损失,它根据重构网络的结果来评估姿态的合适度。如下公式所示

实验
本文在两个数据集上评估了提出的方法:一个是ModelNet,一个是MOPED。用于评估未见目标的姿态估计精度。
在实验细节方面,训练数据是来自ShapeNet,其中包含了近51300个shapes。采用Blender的UV映射生成了多个UV图。采用Beckmann模型进行渲染,其中渲染的概率是0.5。
网络输入大小是128*128。并对输入的目标进行了“放大”处理,使得每个目标的距离保持一致。在每轮训练中,会采样一个3D模型,然后采样16个随机的参考姿态和16个随机的目标姿态。作者使用Adam优化器,固定学习率为0.001等。
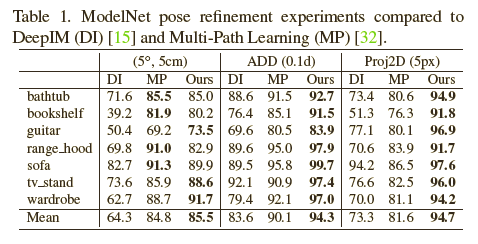
表格1展示了在ModelNet数据集上定量的结果。平均下来,本文的方法是最SOTA的。但是本文在有些目标上的表现却较差,原因之一可能是图像和空间分辨率。我们网络的输入和输出图像分辨率是128*128,立体表示的分辨率是16*16*16。这些可能会影响性能。
另外,本文介绍了MOPED数据集,它包含了11个目标,如下图所示,对于每个目标,作者拍摄了覆盖各个视角的RGB-D视频。

表2展示了在MOPED数据集上的定性比较。需要注意的是,本文的方法并未对测试目标进行额外的训练,而PoseRBPF方法对每个目标都单独训练了一个编码器。本文的方法在ADD和ADD-S两个指标上,都超越了之前的方法。

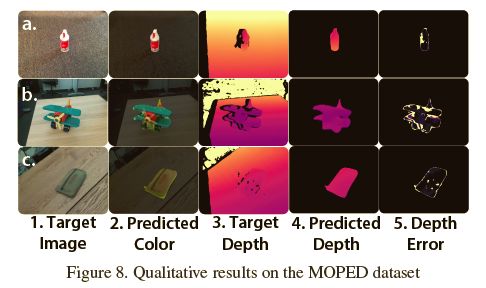
下图展示了对于不同测试图像的姿态估计结果。
作者做了一些消融实验,表格3显示了模型精度会随着参考视图数量的增加而增加。表格4展示了对两个View Fusion变量的量化评估。尽管目标的平均性能非常接近,但是ConvGRU的性能略优于平均池化。

总结
本文提供了一个新的框架,用于从参考视图中学习3D目标表示。本文的网络能够对该表示进行解码,以合成新的视图并估算物体的6D姿态。通过使用上千种3D形状来训练网络,我们的网络学会了在推理过程中重构和估计未见目标的姿态。与当前的6D目标姿态估计方法相比,本文的方法不需使用高质量的3D模型或对每个目标进行额外训练。因此,该方法具有处理大量目标并进行姿势估计的潜力。在未来的工作中,一个方向是可以研究在复杂场景中未见目标的姿态估计,在这些场景中目标可能会相互遮挡。另一个方向是使用网络优化技术来计算姿态估计过程。
(*本文为AI科技大本营编译文章,转载请微信联系 1092722531)