关系型数据库
关系型数据库依靠着它的ACID特性和强大的SQL语法,目前仍然是各种业务系统的核心存储,很多场景下高性能设计的核心部分就是关系型数据库的高性能设计。数据库厂商(Oracle、DB2、MySQL 等)在优化和提升单个数据库性能方面做了非常多的优化和改进,但是依然跟不上互联网业务的发展,集群已成为趋势。下面会介绍一些高性能数据库集群的设计。
原子性(Atomicity)一致性(Consistency)隔离性(Isolation)持久性(Durability)
读写分离
顾名思义:读写分离就是数据库的读和写分散到不同的节点。
读写分离的基本实现如下:
- 数据库服务器搭建主从集群,一主N从
- 数据库主机负责读写操作,从机只负责读操作
- 数据库主机通过复制将数据同步到从机(主从复制)
- 业务服务器将写操作发给主机,将读操作发给从机
这里使用的是主从集群而不是主备集群,“从”代表“仆从”查询数据时候起到辅助读作用;“备”代表“备份”,备机在查询数据时候往往不承担作用,而一旦主机失效的时候,备机会替补上来,成为主机。
读写分离的实现逻辑并不复杂,但是有两个细节点将引入设计复杂度:主从复制延迟和读写分配机制。
主从复制延迟
主从复制延迟在同机房,一般情况下都在十几到几十毫秒,但是如果有大量数据同步,就可能延迟到1秒~几分钟甚至更久,这样的场景下,主库新写入的数据,访问从库读取是无法读取到最新数据,比如:用户在主库注册了会员,刷新界面登录时候,而又从从库拉取数据,这时候肯定会显示“未注册”,这样的体验想必是非常差。
解决主从复制延迟有几种常见的方法:
- 避免大事务提交(常识)
- 二次读取策略
就是所谓的读库失败再读写库(特定业务场景下有用) - 关键业务指定主库
比如注册登录系统,读写都指定主库,其他业务读写分离,但是这时候要注意防止有人恶意刷爆你的主库
读写分配机制
将数据库读写操作区分开来,读写访问不同的数据库服务器,一般有两种实现方式:程序代码封装和中间件封装
- 程序代码封装,以Python为例
Django:
DATABASE_ROUTERS = [ 'path.to.PrimaryReplicaRouter']
import random
class PrimaryReplicaRouter:
def db_for_read(self, model, **hints):
"""
Reads go to a randomly-chosen replica.
"""
return random.choice(['replica1', 'replica2'])
def db_for_write(self, model, **hints):
"""
Writes always go to primary.
"""
return 'primary'
}
Sqlalchemy:
class RoutingSession(Session):
def get_bind(self, mapper=None, clause=None):
if self._name:
return self.engines[self._name]
# _flushing分离读写
elif self._flushing:
return self.engines[DEFAULT_DB]
else:
return random.choice(self.slave_engines) if self.slave_engines else self.engines[DEFAULT_DB]
def using_bind(self, name):
self._name = name
return self
JAVA:
淘宝的 TDDL(Taobao Distributed Data Layer,外号:头都大了)
https://github.com/alibaba/tb_tddl
代码封装具有以下特点:
- 实现简单
- 不同编程语言、ORM需要自己实现一套
- 故障发生时,需要各个系统更改自己的DB配置
- 中间件封装
这里的中间件特指的是业务代码与数据库中间加的一层,特点如下:
- 能够支持多种编程语言,因为数据库中间件对业务服务器提供的标准的SQL接口
- 数据库中间件需要支持完成的SQL语法和数据库服务器协议
- 所有的业务数据都经过中间件,中间件的性能要求较高
- 数据库主从切换对业务系统无感知
- 实现难度高,代码量大
一般使用现有的成熟方案,如:
MySQL官方推荐的MySQL Router;
一些大厂的开源中间件框架;
也可以直接使用阿里云RDS,开箱即用
分库分表
当数据量达到千万级以上,单台数据库存储能力会成为瓶颈。
具体体现如下:
- 数据量大,读写性能会下降,即使有索引,索引也会变得很大,性能同样下降
- 数据文件越大,数据库备份和恢复需要的时间越长
- DDL耗时很大
这时候就要把单台数据库的量控制一下,把存储分散到多台数据库服务器上,也就是“分库分表”。
把不同的业务放在不同的数据库中,但是这样的操作也就面临着一下几个问题:
- 分库
- 无法join操作
原来一个join的操作就变成了先查出来一个表的id,再去另外一个表里去查询 - 事务问题
原来的一个事务里的操作,此时要重构成逻辑事务,模拟实现事务的功能,达到“同进同退”的效果 - 成本 (机器变多了)
- 分表
分表是比较常见的切分数据策略,即在一个数据库里,把一张大表分为N张小表,切分的策略一般分为垂直切分和水平切分
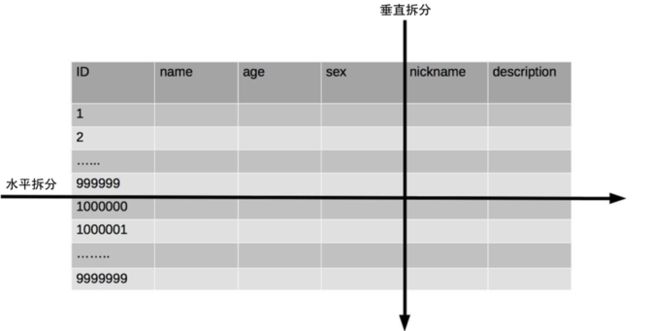 image.png
image.png
- 垂直切分
如上图,对一个表的不同字段进行切分,比如一个社交App,需要做非常频繁的筛选操作,筛选的条件集中在年龄(age)、性别(sex),其他的外号、个人简介等等的多用于展示,这时候可以把age + sex放在一张表用于频繁的筛选过滤,当用户需要查看详情的时候,再去查另外一张表 - 水平切分
水平切分是最常用的一种数据切分方案,根据不同规则,分散到不同的表里面,各个公司的规定不同,一些公司的规定是单表5000w必须做sharding,有的则是2000w、1000w,这个也是根据具体业务而定,但是当表的数据达到千万级别时,作为架构师就要警觉起来了。 - Sharding路由
路由负责把不同的数据应该存放到相应的表中,路由一般尽量满足以下几个标准:- 同一张表能尽最大可能的满足业务需求
跨两张以上Sharding表操作,势必会增加复杂度,也会影响效率,一张表能满足业务需求尽量在一张表里完成,那么,路由策略和ShardingKey的选择就显得很重要了。 - 各个表数据要尽可能的平均
如果路由的策略做的不好,可能会有一张表特别大,读写还是很慢,一张表又特别小,资源浪费
- 同一张表能尽最大可能的满足业务需求
常见的路由姿势有:
范围路由
比如:主键id从0 ~ 1000000放在表1,1000000 ~ 1999999放在表2,这样的方案是比较简单,只需要往后面加表就可以啦,但是各个表的数据有可能不均匀,而且在稍微复杂一点的场景,简单的主键id切分一般不能单表满足业务需求。-
查询切分
将id和库的Mapping记录在一个单独的库中。
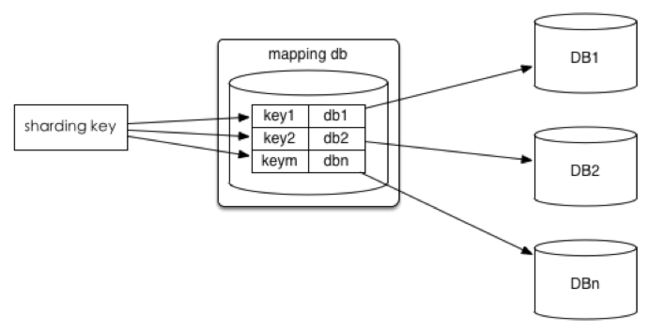 image.png
image.png
优点:id和库的Mapping可以随意更改
缺点:引入新的单点 -
Hash切分
一般采用Mod来切分,下面看一下Mod的策略
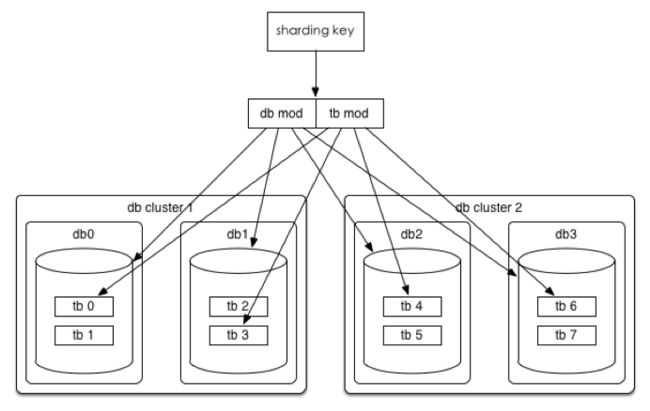 image.png
image.png
数据水平切分后我们希望是一劳永逸或者是易于水平扩展的,所以推荐采用mod 2^n这种一致性Hash。
以统一订单库为例,假如我们分库分表的方案是32*32的,即通过UserId后四位mod 32分到32个库中,同时再将UserId后四位Div 32 Mod 32将每个库分为32个表,共计分为1024张表。线上部署情况为8个集群(主从),每个集群4个库。举个扩展的例子,虽然已经sharding到1024个表里面,但是业务量增长很快,单表仍然很大,这时候,可以直接把基数32变为64,UserId为1和33的人原来是表1里,现在要把数据分配到表1和表33,数据怎么迁移呢?最简单的,把表1复制一份到表33(或者从表1复制指定数据到表33),修改一下路由规则就好了,等到灰度完成,清理一下原来的数据。这个例子是扩展表,扩展库、集群也是一样的道理。关于一致性hash,展开会很多,会后面专门写一篇。
PS:分表以后单表仍然很大,可以试试在业务允许的情况下进行数据归档
水平切分了以后,很多操作会受限:
- join
- count
- order_by
等等
非关系型数据库
NoSQL = Not Only SQL
常见的NoSQL方案分为4类:
- k-v存储:解决关系数据库无法存储数据结构的问题,以Redis为代表。
- 文档数据库:解决关系数据库强schema约束的问题,以MongoDB为代表。
- 列式数据库: 解决关系数据库大数据场景下的I/O问题,以HBase为代表。
“列式数据库”是相对于“行式数据库”的,列式数据库在存储的时候,物理硬盘的一行保存的是逻辑数据的一列,所以列式就具备了一些特点:读取多条逻辑列效率很高;对逻辑上某一列修改,具有原子性和一致性; - 全文搜索引擎:解决关系数据库的全文搜索性能问题,以Elasticsearch和它的“倒排索引”(Inverted index)为代表。
使用NoSQL之前,最先判断的是看业务是否需要严格的遵循ACID,如果需要,那么不建议使用NoSQL
缓存
在RDB前面加一层缓存,可以起到提高查询效率,降低RDB压力的神效,典型的场景有:
- 需要经过复杂运算后得出的数据
- 读多写少的数据
通过把可能重复使用的数据放在内存中,一次生成、多次使用,避免每次使用都去访问存储上系统。
单台Memcache服务器简单的key-value查询能够达到5w~10wQPS
单台Redis服务器查询也能够达到10wQPS,设计良好的缓存一般不会成为瓶颈。
缓存虽然大大减轻了存储系统的压力,但是同时引入了更多的复杂度,下面简述缓存的架构设计要点。
- 缓存穿透
缓存穿透是指缓存没有发挥作用,缓存中没有数据,需要去存储系统中查询,通常情况下有两种情况:
- 存储数据不存在
缓存找不到去存储中拉数据,结果存储中也没有,这样的情况不会太多,但是极端情况下,比如被黑客攻击,大量的请求,透过缓存打到存储上,很可能把存储搞挂掉。
解决办法:很简单,如果查询存储系统的数据没有找到,则直接设置一个默认值,代表存储中没有这个值,当存储中有这个值了,再把缓存更新掉。 - 缓存数据生成耗费大量时间或者资源
存储中其实是有数据的,但是缓存中数据过期了以后,重新从存储生成数据到缓存中,需要较长时间,在这一段时间内,缓存都是失效的。
解决办法:把刷入缓存时间控制在闲时 - 缓存雪崩
缓存雪崩是指当缓存失效(过期)后引起系统性能急剧下降的情况。高并发场景下,缓存过期被清除后,业务系统需要重新生成缓存,所有请求都去生成缓存,这时候性能肯定就比较差了
常见解决办法:- 更新锁机制
对缓存加分布式互斥锁,保证只有一个线程去更新缓存 - 后台更新机制
缓存不是由业务线程来更新,缓存过期时间设置为永久,采用后台线程更新的方式更新,后台更新的策略同时也要考虑几个特殊场景,缓存内存不够时,会“踢掉”一些缓存数据,而这时候后台线程是不知道缓存被“踢掉”了。这时候一般有两种办法:后台线程轮训检查;业务线程发现缓存失效,把缓存生成请求扔到队列里,后台消费生成请求。 - 双key
key1有超时时间,key2没有超时时间,读取不到key1时候,会返回key2的值,同时出发一个事件,更新key1、key2
- 更新锁机制
- 缓存热点
1.避免大KEY
2.突发热点。例如:微博某明星发布微博“xxx,我们恋爱了”,这时候该缓存服务器的压力也会很大。
解决办法就是针对粉丝一百万的明星,增加100个副本,讲请求分散到多个缓存服务器上,减轻缓存热点导致单台缓存服务器的压力。有个需要注意的点是不同的副本过期时间不要设置成一样的,否则缓存同时失效,会引发雪崩。
PS:热点数据存在相当的突发性,临时扩容似乎来不及,那怎么应对突发的类似微博宕机这类的问题呢?限流;容器化+动态化;业务降级,如限制评论
小结
架构设计没必要一上来就搞分库分表、加缓存,因为增加一个新技术的同时,势必会带来新的复杂度,而应遵循架构设计三原则来设计——简单、适用、演化。当接口性能出现瓶颈的时候,最简单的扩容加机器的同时,更需要优化本身的业务代码和SQL语句,这样也容易对自身系统能力有个正确的认识。